Explorer le traitement de données analytiques
Le traitement de données analytiques utilise généralement des systèmes en lecture seule (ou essentiellement en lecture) Qui stockent de vastes volumes de données historiques ou de mesures commerciales. L’analyse peut être basée sur un instantané des données à un moment donné ou une série d’instantanés.
Les détails spécifiques d’un système de traitement analytique peuvent varier entre les solutions, mais une architecture courante pour l’analytique à l’échelle de l’entreprise ressemble à ceci :
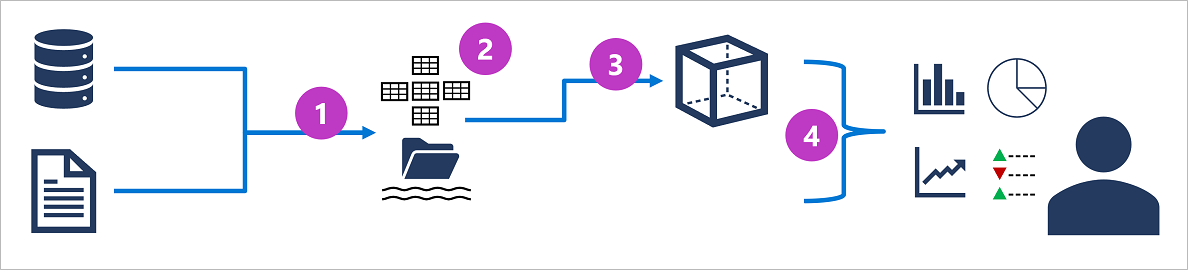
- Les données opérationnelles sont extraites, transformées et chargées (ETL) dans un lac de données pour analyse.
- Les données sont chargées dans un schéma de tables – généralement dans un data lakehouse basé sur Spark avec des abstractions tabulaires sur les fichiers dans le lac de données, ou un data warehouse avec un moteur SQL entièrement relationnel.
- Les données de l’entrepôt de données peuvent être agrégées et chargées dans un modèle de traitement analytique en ligne (OLAP) ou un cube. Les valeurs numériques agrégées (mesures) des tables de faits sont calculées pour les intersections des dimensions des tables de dimension. Par exemple, le total d’un chiffre d’affaires peut être calculé par date, client et produit.
- Les données du modèle de lac de données, d’entrepôt de données et analytique peuvent être interrogées pour produire des rapports, des visualisations et des tableaux de bord.
Les lacs de données sont courants dans les scénarios de traitement analytique de données à grande échelle, où un grand volume de données basées sur des fichiers doit être collecté et analysé.
Les entrepôts de données sont un moyen établi de stocker des données dans un schéma relationnel qui est optimisé pour les opérations de lecture, principalement des requêtes pour prendre en charge la création de rapports et la visualisation de données. Les data lakehouses sont une innovation plus récente qui combine le stockage flexible et évolutif d'un lac de données avec la sémantique d'interrogation relationnelle d'un entrepôt de données. Le schéma des tables peut nécessiter une certaine dénormalisation des données dans une source de données OLTP (en introduisant une certaine duplication pour accélérer les requêtes).
Un modèle OLAP est un type agrégé de stockage de données qui est optimisé pour les charges de travail analytiques. Les agrégations de données sont dans des dimensions à différents niveaux, vous permettant de monter/descendre dans la hiérarchie pour afficher des agrégations à plusieurs niveaux hiérarchiques, par exemple, pour rechercher le total des ventes par région, par ville ou pour une adresse individuelle. Étant donné que les données OLAP sont pré-agrégées, les requêtes pour retourner les résumés qu’elles contiennent peuvent être exécutées rapidement.
Les différents types d’utilisateur peuvent effectuer des tâches analytiques de données à différentes étapes de l’architecture globale. Par exemple :
- Les scientifiques des données peuvent travailler directement avec les fichiers de données d’un lac de données pour explorer et modéliser les données.
- Les analystes Données peuvent interroger des tables directement dans l’entrepôt de données afin de produire des rapports et des visualisations complexes.
- Les utilisateurs professionnels peuvent consommer des données pré-agrégées dans un modèle analytique sous forme de rapports ou de tableaux de bord.