Orchestrer l’intégration des données avec les pipelines Azure Synapse
Les pipelines Azure Synapse constituent un service d’ETL et d’intégration de données basé sur le cloud, qui vous permet de créer des workflows orientés données pour l’orchestration des déplacements de données et pour la transformation des données à grande échelle. Avec les pipelines Azure Synapse, vous pouvez créer et planifier des workflows basés sur les données (appelés pipelines) qui ingèrent des données issues de différents magasins de données. Vous pouvez créer des processus ETL complexes ou qui transforment des données visuellement avec des flux de données, ou en utilisant des services comme Azure HDInsight, Azure Databricks et Azure Synapse Analytics.
La plupart des fonctionnalités des pipelines Azure Synapse proviennent des fonctionnalités d’Azure Data Factory et sont communément appelées pipelines. Les pipelines Azure Synapse vous permettent d’intégrer des pipelines de données entre les pools SQL, les pools Spark et SQL Serverless, ce qui permet d’avoir un seul emplacement pour tous vos besoins analytiques.
Comme Azure Data Factory, les pipelines Azure Synapse se composent de quatre composants principaux. Ces composants fonctionnent ensemble et vous dotent de la plateforme sur laquelle composer des flux de travail orientés données constitués d’étapes de déplacement et de transformation des données.
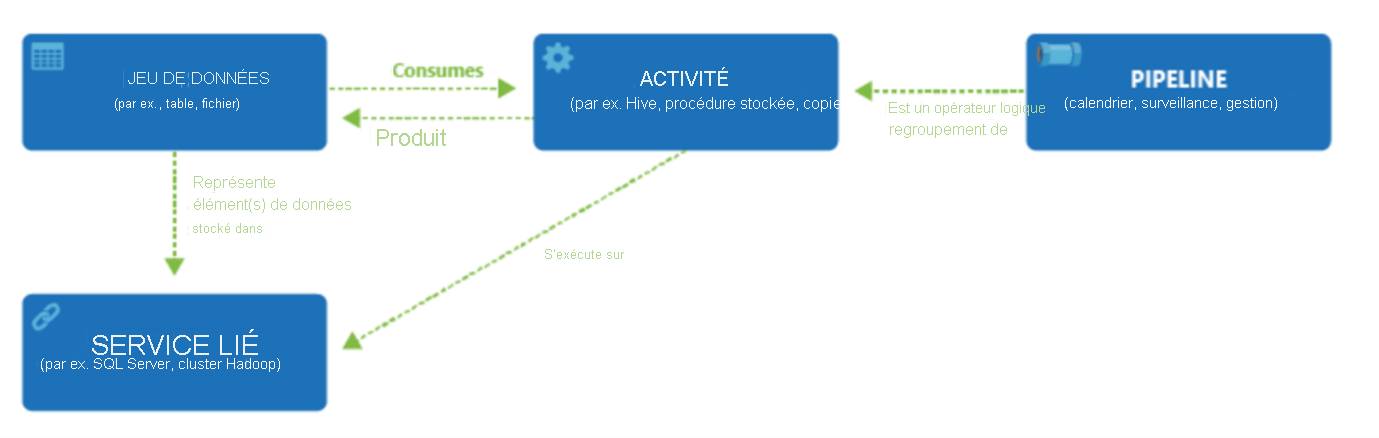
Data Factory prend en charge un large éventail de sources de données auxquelles vous pouvez vous connecter par le biais de la création d’un objet appelé Service lié, ce qui vous permet d’ingérer les données d’une source de données en préparation pour former les données à des fins de transformation et/ou d’analyse. En outre, les services liés peuvent déclencher des services de calcul à la demande. Par exemple, vous avez peut-être besoin de démarrer un cluster HDInsight à la demande afin de traiter simplement des données via une requête Hive. Ainsi, les services liés vous permettent de définir des sources de données ou des ressources de calcul requises pour l’ingestion et la préparation des données.
Une fois le service lié défini, Azure Data Factory est informé des jeux de données qu’il doit utiliser lors de la création d’un objet DataSets. Les jeux de données représentent des structures de données dans le magasin de données qui est référencé par l’objet de service lié. Les jeux de données peuvent également être utilisés par un objet ADF appelé Activité.
Les activités contiennent généralement la logique de transformation ou les commandes d’analyse du travail d’Azure Data Factory. Les activités incluent l’activité de copie, qui peut être utilisée pour ingérer des données provenant de diverses sources de données. Elles peuvent également inclure le flux de données de mappage pour effectuer des transformations de données sans code. Elles peuvent également inclure l’exécution d’une procédure stockée, d’une requête Hive ou d’un script Pig pour transformer les données. Vous pouvez transmettre des données dans un modèle de Machine Learning pour effectuer une analyse. Il n’est pas rare que plusieurs activités aient lieu, pouvant qui peuvent inclure la transformation de données à l’aide d’une procédure stockée SQL, puis effectuer des analyses avec Databricks. Dans ce cas, plusieurs activités peuvent être regroupées de manière logique avec un objet appelé pipeline, et elles peuvent être planifiées pour s’exécuter, ou un déclencheur peut être défini pour déterminer quand une exécution de pipeline doit être lancée. Il existe différents types de déclencheurs pour différents types d’événements.
Le flux de contrôle est une orchestration des activités du pipeline, qui inclut le chaînage des activités en une séquence, la création de branches, la définition de paramètres au niveau du pipeline et la transmission des arguments lors de l’appel du pipeline à la demande ou à partir d’un déclencheur. Cela inclut également la transmission d’états personnalisés et le bouclage des conteneurs, et des itérateurs For-Each.
Les paramètres sont des paires clé-valeur d’une configuration en lecture seule. Les paramètres sont définis dans le pipeline. Les arguments des paramètres définis sont transmis au cours de l’exécution à partir du contexte d’exécution qui a été créé par un déclencheur ou un pipeline qui a été exécuté manuellement. Les activités contenues dans le pipeline utilisent les valeurs des paramètres.
Les pipelines Azure Synapse disposent d’un runtime d’intégration qui leur permettent d’établir un pont entre l’activité et les objets de services liés. Il est référencé par le service lié, et fournit l’environnement Compute dans lequel l’activité s’exécute ou à partir duquel elle est envoyée. De cette façon, l’activité peut être exécutée dans la région la plus proche possible. Il existe trois types de runtimes d’intégration (IR) qui sont l’infrastructure de calcul utilisée par Azure Data Factory et les pipelines Synapse pour fournir des capacités d’intégration de données, y compris Azure et l’auto-hébergement. Azure Data Factory prend en charge les mêmes runtimes d’intégration et, en plus de cela, il prend également en charge le runtime d’intégration Azure-SSIS.
Une fois le travail terminé, vous pouvez utiliser Data Factory pour publier le jeu de données final sur un autre service lié qui peut ensuite être consommé par des technologies telles que Power BI ou Machine Learning.