Découvrir Spark
Pour mieux comprendre comment traiter et analyser des données avec Apache Spark dans Azure Databricks, il est important de comprendre l’architecture sous-jacente.
Vue d’ensemble
Globalement parlant, le service Azure Databricks démarre et gère les clusters Apache Spark au sein de votre abonnement Azure. Les clusters Apache Spark sont des groupes d’ordinateurs qui sont traités comme un seul ordinateur et gèrent l’exécution des commandes émises à partir des notebooks. Les clusters permettent de traiter des données sur plusieurs ordinateurs pour améliorer la mise à l’échelle et les performances. Ils se composent de nœuds Spark Driver et Worker. Le nœud driver envoie un travail aux nœuds worker et leur demande d’extraire des données d’une source de données spécifiée.
Dans Databricks, l’interface du notebook est généralement le programme Driver. Ce programme contient la boucle principale du programme et crée des jeux de données distribués sur le cluster, puis applique des opérations à ces jeux de données. Les programmes Driver accèdent à Apache Spark via un objet SparkSession, quel que soit l’emplacement de déploiement.

Microsoft Azure gère le cluster et le met automatiquement à l’échelle selon les besoins, c’est-à-dire en fonction de votre utilisation et du paramètre utilisé lors de la configuration du cluster. L’arrêt automatique peut également être activé, ce qui permet à Azure de mettre fin au cluster après un certain nombre de minutes d’inactivité.
Tâches Spark en détail
Les travaux soumis au cluster sont divisés en autant de travaux indépendants que nécessaire. C’est ainsi qu’un travail est réparti entre les nœuds du cluster. Les travaux sont sous-divisés en tâches. L’entrée d’un travail est partitionnée en une ou plusieurs partitions. Ces partitions représentent l’unité de travail de chaque emplacement. Entre les tâches, il peut être nécessaire de réorganiser et de partager les partitions sur le réseau.
Le secret des hautes performances de Spark réside dans son parallélisme. La mise à l’échelle verticale (en ajoutant des ressources à un seul ordinateur) est limitée à une quantité finie de RAM, de threads et de vitesses processeur, tandis que les clusters sont mis à l’échelle horizontalement en ajoutant de nouveaux nœuds au cluster selon les besoins.
Spark parallélise les travaux à deux niveaux :
- Le premier niveau de parallélisation est l’exécuteur : une machine virtuelle Java (JVM) s’exécutant sur un nœud worker, en général, une seule instance par nœud.
- Le deuxième niveau de parallélisation est l’emplacement : le nombre d’emplacements est déterminé par le nombre de cœurs et de processeurs de chaque nœud.
- Chaque exécuteur a plusieurs emplacements auxquels des tâches parallélisées peuvent être assignées.
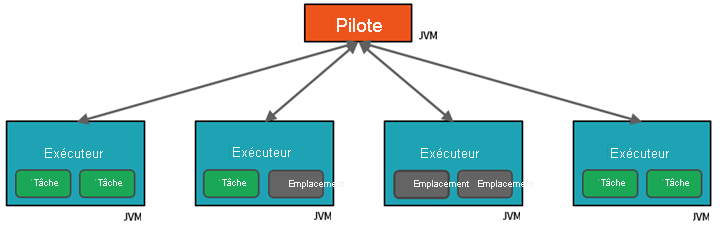
La machine virtuelle Java est naturellement multithread, mais une seule machine virtuelle Java, telle que celle qui coordonne le travail sur le driver, a une limite supérieure finie. En divisant le travail en tâches, le driver peut affecter des unités de travail à des *emplacements dans les exécuteurs sur les nœuds worker pour une exécution parallèle. De plus, le Driver détermine comment partitionner les données afin de pouvoir les distribuer en vue d’un traitement parallèle. Par conséquent, le driver affecte une partition de données à chaque tâche afin que chacune d’elles sache quelle donnée traiter. Une fois démarrée, chaque tâche récupère la partition de données qui lui est attribuée.
Tâches et phases
En fonction du travail en cours, plusieurs travaux parallélisés peuvent être nécessaires. Chaque travail est divisé en phases. Une analogie utile consiste à imaginer que le travail est de construire une maison :
- La première étape consiste à poser les fondations.
- La seconde étape consiste à ériger les murs.
- La troisième phase consiste à ajouter le toit.
Tenter d’effectuer l’une de ces phases dans le désordre n’a aucun sens, et peut tout simplement être impossible. De même, Spark divise chaque travail en phases pour garantir que tout est fait dans le bon ordre.