Déployer un cluster Big Data SQL Server en mode Active Directory
Cet article explique comment déployer un cluster Big Data SQL Server en mode Active Directory. Les étapes décrites dans cet article nécessitent l’accès à un domaine Active Directory. Avant de continuer, vous devez satisfaire aux spécifications décrites dans Déployer des clusters Big Data SQL Server en mode Active Directory.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Préparer le déploiement
Pour le déploiement du cluster Big Data avec l’intégration Active Directory, des informations supplémentaires doivent être fournies pour la création des objets liés aux clusters Big Data dans Active Directory.
En utilisant le profil kubeadm-prod (ou openshift-prod à partir de la version CU5), vous disposez automatiquement des espaces réservés aux informations relatives à la sécurité et aux points de terminaison requises pour l’intégration AD.
De plus, vous devez fournir des informations d’identification que les clusters Big Data utiliseront pour créer les objets nécessaires dans AD. Ces informations d’identification sont fournies en tant que variables d’environnement.
Trafic et ports
Vérifiez que les pare-feux ou les applications tierces autorisent les ports requis pour la communication Active Directory.
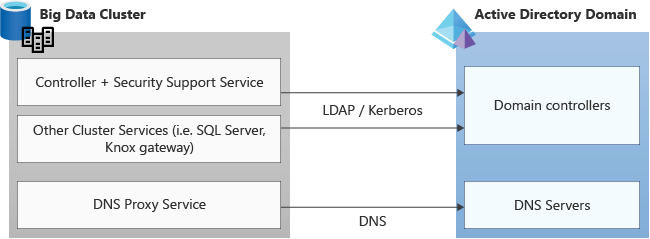
Les requêtes sont effectuées sur ces protocoles vers et depuis les services de cluster Kubernetes vers le domaine Active Directory. elles doivent donc être entrantes et sortantes dans n’importe quel pare-feu ou application tierce écoutant sur les ports requis pour TCP et UDP. Les numéros de port standard que Active Directory utilise :
| Service | Port |
|---|---|
| DNS | 53 |
| LDAP LDAPS |
389 636 |
| Kerberos | 88 |
| Protocole de modification de mot de passe Kerberos/AD | 464 |
| Port de catalogue global via LDAP via LDAPS |
3268 3269 |
Définir des variables d’environnement de sécurité
Les variables d’environnement suivantes fournissent les informations d’identification pour le compte de service de domaine des clusters Big Data, qui seront utilisées pour configurer l’intégration Active Directory. Ce compte est également utilisé par les clusters Big Data pour gérer désormais les objets AD associés.
export DOMAIN_SERVICE_ACCOUNT_USERNAME=<AD principal account name>
export DOMAIN_SERVICE_ACCOUNT_PASSWORD=<AD principal password>
Fournir des paramètres de sécurité et de point de terminaison
Outre les variables d’environnement pour les informations d’identification, vous devez fournir des informations de sécurité et de point de terminaison pour que l’intégration Active Directory fonctionne. Les paramètres nécessaires font automatiquement partie du kubeadm-prod/openshift-prodprofil de déploiement.
L’intégration AD nécessite les paramètres suivants. Ajoutez ces paramètres aux fichiers control.json et bdc.json à l’aide des commandes config replace présentées plus loin dans cet article. Tous les exemples ci-dessous utilisent l’exemple de domaine contoso.local.
security.activeDirectory.ouDistinguishedName: nom unique d’une unité d’organisation (UO) dans laquelle tous les comptes Active Directory créés par le déploiement du cluster seront ajoutés. Si le domaine est appelécontoso.local, le nom unique de l’unité d’organisation est :OU=BDC,DC=contoso,DC=local.security.activeDirectory.dnsIpAddresses: contient la liste des adresses IP des serveurs DNS du domaine.security.activeDirectory.domainControllerFullyQualifiedDns: Liste des noms de domaine complets de contrôleur de domaine. Le nom de domaine complet contient le nom de l’ordinateur/hôte du contrôleur de domaine. Si vous avez plusieurs contrôleurs de domaine, vous pouvez fournir une liste ici. Exemple :HOSTNAME.CONTOSO.LOCAL.Important
Lorsque plusieurs contrôleurs de domaine servent un domaine, utilisez le contrôleur de domaine principal comme première entrée de la liste
domainControllerFullyQualifiedDnsdans la configuration de la sécurité. Pour récupérer le nom du contrôleur de domaine principal, tapeznetdom query fsmodans l’invite de commandes, puis appuyez sur ENTRÉE.security.activeDirectory.realmParamètre facultatif : Dans la majorité des cas, le domaine est égal au nom de domaine. Pour les cas où ils ne sont pas les mêmes, utilisez ce paramètre pour définir le nom du domaine (par exemple,CONTOSO.LOCAL). La valeur fournie pour ce paramètre doit être complète.security.activeDirectory.netbiosDomainNameParamètre facultatif : Il s’agit du nom NetBIOS du domaine AD. Dans la majorité des cas, ce nom correspond à la première étiquette du nom de domaine AD. Pour les cas différents, utilisez ce paramètre pour définir le nom de domaine NETBIOS. Cette valeur ne doit pas contenir de points. Habituellement, ce nom est utilisé pour qualifier les comptes d’utilisateur dans le domaine. Par exemple, CONTOSO\utilisateur où CONTOSO est le nom de domaine NETBIOS.Notes
La prise en charge d’une configuration dans laquelle le nom de domaine Active Directory est différent du nom NetBIOS du domaine Active Directory qui utilise security.activeDirectory.netbiosDomainName est activée depuis SQL Server 2019 CU9.
security.activeDirectory.domainDnsName: nom du domaine DNS qui sera utilisé pour le cluster (par exemple,contoso.local).security.activeDirectory.clusterAdmins: Ce paramètre prend un groupe AD. L’étendue du groupe AD doit être universelle ou globale. Les membres de ce groupe possèdent le rôle de clusterbdcAdmin, ce qui leur donne des autorisations d’administrateur dans le cluster. Ils disposent donc des autorisationssysadmindans SQL Server, des autorisationssuperuserdans HDFS et des autorisations d’administrateurs lorsqu’ils sont connectés au point de terminaison du contrôleur.Important
Créez ce groupe dans AD avant le début du déploiement. Si l’étendue de ce groupe AD est locale au niveau du domaine, le déploiement échoue.
security.activeDirectory.clusterUsers: Liste des groupes Active Directory qui sont des utilisateurs standard (aucune autorisation d’administrateur) dans le cluster Big Data. La liste peut inclure des groupes AD dont l’étendue est universelle ou globale. Il ne peut pas s’agir de groupes locaux au niveau du domaine.
Les groupes AD de cette liste sont associés au rôle de cluster Big Data bdcUser et doivent être autorisés à accéder à SQL Server (cf. Autorisations SQL Server) ou à HDFS (consultez Guide des autorisations HDFS). Lorsqu’ils sont connectés au point de terminaison du contrôleur, ces utilisateurs peuvent seulement lister les points de terminaison disponibles dans le cluster à l’aide de la commande azdata bdc endpoint list.
Pour savoir comment mettre à jour les groupes AD en ce qui concerne ces paramètres, consultez Gérer l’accès au cluster Big Data en mode Active Directory.
Conseil
Pour activer l’expérience de navigation HDFS quand vous vous connectez au maître SQL Server dans Azure Data Studio, un utilisateur disposant du rôle bdcUser doit disposer des autorisations VIEW SERVER STATE, car Azure Data Studio utilise la DMV sys.dm_cluster_endpoints pour obtenir le point de terminaison de passerelle Knox requis pour se connecter à HDFS.
Important
Créez ces groupes dans AD avant le début du déploiement. Si l’étendue de l’un de ces groupes AD est locale au niveau du domaine, le déploiement échoue.
Important
Si vos utilisateurs de domaine présentent de nombreuses appartenances à des groupes, ajustez les valeurs du paramètre de passerelle httpserver.requestHeaderBuffer (valeur par défaut : 8192) et du paramètre HDFS hadoop.security.group.mapping.ldap.search.group.hierarchy.levels (valeur par défaut : 10), à l’aide du fichier de configuration de déploiement bdc.json personnalisé. Cette meilleure pratique vise à éviter les délais de connexion à la passerelle et les réponses HTTP comportant le code d’état 431 (Champs d’en-tête de demande trop volumineux). Voici une section du fichier de configuration montrant comment définir les valeurs de ces paramètres et indiquant les valeurs recommandées pour un nombre élevé d’appartenance à des groupes :
{
...
"spec": {
"resources": {
...
"gateway": {
"spec": {
"replicas": 1,
"endpoints": [{...}],
"settings": {
"gateway-site.gateway.httpserver.requestHeaderBuffer": "65536"
}
}
},
...
},
"services": {
...
"hdfs": {
"resources": [...],
"settings": {
"core-site.hadoop.security.group.mapping.ldap.search.group.hierarchy.levels": "4"
}
},
...
}
}
}
security.activeDirectory.enableAES Optional parameterParamètre facultatif : valeur booléenne indiquant si AES 128 et AES 256 doivent être activés sur les comptes AD générés automatiquement. La valeur par défaut estfalse. Lorsque ce paramètre est défini surtrue, les indicateurs suivants « Ce compte prend en charge le chiffrement AES 128 bits via Kerberos » et « Ce compte prend en charge le chiffrement AES 256 bits via Kerberos » sont vérifiés sur les objets AD générés automatiquement lors du déploiement du cluster Big Data.
Notes
Le paramètre security.activeDirectory.enableAES est disponible à partir des clusters Big Data SQL Server CU13. Si le cluster Big Data est dans une version antérieure à CU13, les étapes suivantes sont requises :
- Exécutez la commande
azdata bdc rotate -n <your-cluster-name>. Cette commande fait pivoter les keytabs, ce qui est nécessaire pour s’assurer que les entrées AES dans les keytabs sont correctes. Pour plus d’informations, consultez azdata bdc. En outre,azdata bdc rotatefait pivoter les mots de passe des objets AD générés automatiquement pendant le déploiement initial dans l’unité d’organisation spécifiée. - Définissez les indicateurs suivants : « Ce compte prend en charge le chiffrement AES 128 bits via Kerberos » et « Ce compte prend en charge le chiffrement AES 256 bits via Kerberos » sur chacun des objets AD générés automatiquement dans l’unité d’organisation que vous avez fournie lors du déploiement initial du cluster Big Data. Pour ce faire, vous pouvez exécuter le script PowerShell
Get-ADUser -Filter * -SearchBase '<OU Path>' | Set-ADUser -replace @{ 'msDS-SupportedEncryptionTypes' = '24' }suivant sur votre contrôleur de domaine. Il définit les champs AES sur chaque compte de l’unité d’organisation spécifiée dans le paramètre<OU Path>.
Important
Créez les groupes fournis pour les paramètres ci-dessous dans AD avant le début du déploiement. Si l’étendue de l’un de ces groupes AD est locale au niveau du domaine, le déploiement échoue.
security.activeDirectory.appOwnersParamètre facultatif : Liste des groupes AD qui sont autorisés à créer, supprimer et exécuter n’importe quelle application. La liste peut inclure des groupes AD dont l’étendue est universelle ou globale. Il ne peut pas s’agir de groupes locaux au niveau du domaine.security.activeDirectory.appReadersParamètre facultatif : liste des groupes AD qui sont autorisés à exécuter n’importe quelle application. La liste peut inclure des groupes AD dont l’étendue est universelle ou globale. Il ne peut pas s’agir de groupes locaux au niveau du domaine.
Le tableau ci-dessous montre le modèle d’autorisation pour la gestion des applications :
| Rôles autorisés | Azure Data CLI (commande azdata) |
|---|---|
| appOwner | azdata app create |
| appOwner | azdata app update |
| appOwner, appReader | azdata app list |
| appOwner, appReader | azdata app describe |
| appOwner | azdata app delete |
| appOwner, appReader | azdata app run |
security.activeDirectory.subdomain: (Paramètre facultatif) Ce paramètre, introduit dans la version SQL Server 2019 CU5, permet de prendre en charge le déploiement de plusieurs clusters Big Data sur le même domaine. À l’aide de ce paramètre, vous pouvez spécifier des noms DNS différents pour tous les clusters Big Data déployés. Si la valeur de ce paramètre n’est pas spécifiée dans la section Active Directory du fichiercontrol.json, c’est par défaut le nom du cluster Big Data (identique au nom de l’espace de noms Kubernetes) qui sera utilisé pour calculer la valeur du paramètre subdomain.Notes
La valeur transmise par le biais du paramètre subdomain ne constitue pas un nouveau domaine AD, mais seulement un domaine DNS utilisé en interne par le cluster Big Data.
Important
À partir de la version SQL Server 2019 CU5, vous devez installer ou mettre à niveau Azure Data CLI (
azdata) vers la dernière version pour tirer parti de ces nouvelles fonctionnalités et déployer plusieurs clusters Big Data dans le même domaine.Pour plus d’informations sur le déploiement de plusieurs clusters Big Data dans le même domaine Active Directory, consultez Concept : Déploiement de clusters Big Data SQL Server en mode Active Directory.
security.activeDirectory.accountPrefix: (Paramètre facultatif) Ce paramètre, introduit dans la version SQL Server 2019 CU5, permet de prendre en charge le déploiement de plusieurs clusters Big Data sur le même domaine. Ce paramètre garantit, pour différents services Clusters Big Data, l’unicité des noms de compte, qui doivent varier d’un cluster à l’autre. La personnalisation du nom de préfixe de compte est facultative. Par défaut, c’est le nom du sous-domaine qui est utilisé comme préfixe de compte. Si ce nom dépasse 12 caractères, le préfixe de compte est constitué des 12 premiers caractères.Notes
Active Directory impose que les noms de compte soient limités à 20 caractères. Le cluster Big Data doit en utiliser 8 pour distinguer les pods et les StatefulSet. ce qui laisse 12 caractères comme limite du préfixe de compte.
Vérifiez l’étendue du groupe AD pour déterminer s’il s’agit d’un groupe local de domaine.
Si vous n’avez pas encore initialisé le fichier de configuration de déploiement, vous pouvez exécuter cette commande pour obtenir une copie de la configuration. Les exemples ci-dessous utilisent le profil kubeadm-prod. Le même principe s’applique à openshift-prod.
azdata bdc config init --source kubeadm-prod --target custom-prod-kubeadm
Pour définir les paramètres ci-dessus dans le fichier control.json, utilisez les commandes Azure Data CLI azdata suivantes. Ces commandes remplacent la configuration et fournissent vos propres valeurs avant le déploiement.
Important
Dans la version SQL Server 2019 CU2, la section de la configuration de la sécurité dans le profil de déploiement a été restructurée : tous les paramètres Active Directory se trouvent maintenant dans le nouveau activeDirectory de l’arborescence JSON sous security dans le fichier control.json.
Notes
En plus de fournir des valeurs distinctes pour le sous-domaine, comme nous l’avons vu dans cette section, vous devez utiliser des numéros de port différents pour les points de terminaison des clusters Big Data en cas de déploiement de plusieurs clusters Big Data dans le même cluster Kubernetes. Ces numéros de port peuvent être configurés au moment du déploiement au moyen de profils de configuration de déploiement.
L’exemple ci-dessous s’applique à SQL Server 2019 CU2. Il montre comment remplacer les valeurs des paramètres Active Directory dans la configuration du déploiement. Les détails du domaine ci-dessous sont des exemples de valeurs.
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.ouDistinguishedName=OU\=bdc\,DC\=contoso\,DC\=local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.dnsIpAddresses=[\"10.100.10.100\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.domainControllerFullyQualifiedDns=[\"HOSTNAME.CONTOSO.LOCAL\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.domainDnsName=contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.clusterAdmins=[\"bdcadminsgroup\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.clusterUsers=[\"bdcusersgroup\"]"
#Example for providing multiple clusterUser groups: [\"bdcusergroup1\",\"bdcusergroup2\"]
Si vous le souhaitez, à partir de la version SQL Server 2019 CU5 uniquement, vous pouvez remplacer la valeur par défaut des paramètres subdomain et accountPrefix.
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.subdomain=[\"bdctest\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.accountPrefix=[\"bdctest\"]"
De la même façon, dans les versions antérieures à SQL Server 2019 CU2, vous pouvez exécuter :
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.ouDistinguishedName=OU\=bdc\,DC\=contoso\,DC\=local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.dnsIpAddresses=[\"10.100.10.100\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.domainControllerFullyQualifiedDns=[\"HOSTNAME.CONTOSO.LOCAL\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.domainDnsName=contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.clusterAdmins=[\"bdcadminsgroup\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.clusterUsers=[\"bdcusersgroup\"]"
#Example for providing multiple clusterUser groups: [\"bdcusergroup1\",\"bdcusergroup2\"]
Outre les informations ci-dessus, vous devez également fournir des noms DNS pour les différents points de terminaison de cluster. Les entrées DNS utilisant les noms DNS que vous avez fournis seront automatiquement créées sur votre serveur DNS lors du déploiement. Vous utiliserez ces noms lors de la connexion aux différents points de terminaison du cluster. Par exemple, si le nom DNS de l’instance maître SQL est mastersql, sachant que le sous-domaine utilise la valeur par défaut du nom de cluster dans control.json, vous utiliserez mastersql.contoso.local,31433 ou mastersql.mssql-cluster.contoso.local,31433 (en fonction des valeurs fournies dans les fichiers de configuration de déploiement pour le nom DNS des points de terminaison) pour vous connecter à l’instance maître à partir des outils.
# DNS names for Big Data Clusters services
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[0].dnsName=<controller DNS name>.contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[1].dnsName=<monitoring services DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.master.spec.endpoints[0].dnsName=<SQL Master Primary DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.master.spec.endpoints[1].dnsName=<SQL Master Secondary DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.gateway.spec.endpoints[0].dnsName=<Gateway (Knox) DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.appproxy.spec.endpoints[0].dnsName=<app proxy DNS name>.<Domain name. e.g. contoso.local>"
Important
Vous pouvez utiliser les noms DNS de point de terminaison de votre choix, à condition qu’ils soient complets et n’entrent pas en conflit entre deux clusters Big Data déployés dans le même domaine. Il est possible d’opter pour la valeur du paramètre subdomain afin d’être sûr que les noms DNS soient différents entre les clusters. Par exemple :
# DNS names for Big Data Clusters services
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[0].dnsName=<controller DNS name>.<subdomain e.g. mssql-cluster>.contoso.local"
Vous trouverez un exemple de script ici pour déployer un cluster Big Data SQL Server sur un cluster Kubernetes à nœud unique (kubeadm) avec l’intégration Active Directory.
Notes
Il peut exister des cas de figure dans lesquels la prise en compte du nouveau paramètre subdomain n’est pas possible, par exemple, si vous devez déployer une version antérieure à CU5 et que vous avez déjà mis à niveau Azure Data CLI (azdata). Même si cette situation est très improbable, vous pouvez définir le paramètre useSubdomain sur false dans la section Active Directory de control.json pour rétablir le comportement d’avant CU5. Voici la commande à exécuter :
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.useSubdomain=false"
Vous devez maintenant avoir défini tous les paramètres requis pour un déploiement des clusters Big Data avec l’intégration Active Directory.
Vous pouvez maintenant déployer le cluster Big Data intégré à Active Directory en utilisant la commande Azure Data CLI (azdata) et le profil de déploiement kubeadm-prod. Pour obtenir une documentation complète sur le déploiement de clusters Big Data, consultez Comment déployer des clusters Big Data SQL Server sur Kubernetes.
Vérifier l’entrée DNS inversée pour le contrôleur de domaine
Assurez-vous qu’il existe une entrée DNS inversée (enregistrement PTR) pour le contrôleur de domaine lui-même, inscrite sur le serveur DNS. Vous pouvez le vérifier en exécutant nslookup de l’adresse IP du contrôleur de domaine pour voir qu’elle peut être résolue en nom de domaine complet du contrôleur de domaine.
Problèmes connus et limitations
Limitations à prendre en compte dans SQL Server 2019 CU5
Actuellement, les tableaux de bord Recherche dans les journaux et Métriques ne prennent pas en charge l’authentification Active Directory. Le nom d’utilisateur et le mot de passe de base définis lors du déploiement peuvent être utilisés pour l’authentification auprès de ces tableaux de bord. Tout autre point de terminaison de cluster prend en charge l’authentification AD.
À l’heure actuelle, le mode AD sécurisé ne fonctionne que sur les environnements de déploiement
kubeadmetopenshift, et non sur AKS ni ARO. Les profils de déploiementkubeadm-prodetopenshift-prodcomprennent les sections de sécurité par défaut.Avant la version SQL Server 2019 CU5, seul un cluster Big Data par domaine (Active Directory) est autorisé. La présence de plusieurs clusters Big Data par domaine est disponible à partir de la version CU5.
Aucun des groupes AD spécifiés dans les configurations de sécurité ne peut être d’une étendue DomainLocal. Vous pouvez vérifier l’étendue d’un groupe AD en suivant ces instructions.
Les comptes AD qui peuvent être utilisés pour se connecter au cluster Big Data sont autorisés à partir du même domaine que celui qui a été configuré pour les clusters Big Data SQL Server. Les connexions à partir d’un autre domaine approuvé ne sont pas prises en charge.
Étapes suivantes
Connecter Clusters Big Data SQL Server : Mode Active Directory
Résolution des problèmes d’intégration Active Directory Clusters Big Data SQL Server
Concept : Déploiement de Clusters Big Data SQL Server en mode Active Directory
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour