Groupes de disponibilité pour SQL Server sur Linux
S’applique à :![]() SQL Server - Linux
SQL Server - Linux
Cet article décrit les caractéristiques des groupes de disponibilité sur les installations de SQL Server basées sur Linux. Il couvre également les différences entre les groupes basés sur des clusters de basculement Linux et Windows Server (WSFC). Consultez la documentation Windows pour connaître les principes de base des groupes, car ils fonctionnent de la même manière sur Windows et Linux, à l’exception de WSFC.
Remarque
Dans les groupes de disponibilité qui n’utilisent pas Windows Server Failover Clustering (WSFC), tels que les groupes de disponibilité avec échelle lecture ou les groupes de disponibilité sur Linux, les colonnes des groupes de disponibilité DMV liés au cluster peuvent afficher des données sur un cluster interne par défaut. Ces colonnes sont destinées à un usage interne uniquement et peuvent être ignorées.
D’un point de vue général, les groupes de disponibilité SQL Server sur Linux sont les mêmes que sur les implémentations basées sur WSFC. Cela signifie que toutes les limitations et fonctionnalités sont les mêmes, à quelques exceptions près. Les principales différences sont les suivantes :
- Microsoft Distributed Transaction Coordinator (DTC) est pris en charge par Linux à partir de SQL Server 2017 CU16. Cependant, DTC n’est pas encore pris en charge par les groupes de disponibilité sur Linux. Si vos applications requièrent l’utilisation de transactions distribuées et ont besoin d'un groupe de disponibilité, déployez SQL Server sur Windows.
- Les déploiements Linux qui nécessitent une haute disponibilité utilisent Pacemaker au lieu de WSFC pour le clustering.
- Contrairement à la plupart des configurations pour les groupes sur Windows, à l’exception du scénario de cluster de groupe de travail, Pacemaker ne requiert jamais Active Directory Domain Services (AD DS).
- La façon de faire basculer un groupe de disponibilité d’un nœud à un autre est différente entre Linux et Windows.
- Certains paramètres tels que
required_synchronized_secondaries_to_commitpeuvent uniquement être modifiés par le biais de Pacemaker sur Linux, alors qu’une installation basée sur WSFC utilise Transact-SQL.
Nombre de réplicas et de nœuds de cluster
Un groupe de disponibilité dans l’édition SQL Server Standard peut avoir deux réplicas au total : un principal et un secondaire qui ne peut être utilisé qu’à des fins de disponibilité. Il ne peut être utilisé pour rien d’autre, comme des requêtes lisibles. Un groupe de disponibilité dans l’édition SQL Server Entreprise peut avoir jusqu’à neuf réplicas au total : un principal et jusqu’à huit secondaires, dont jusqu’à trois (y compris le réplica principal) peuvent être synchrones. Si vous utilisez un cluster sous-jacent, il peut y avoir un maximum de 16 nœuds au total quand Corosync est impliqué. Un groupe de disponibilité peut couvrir au plus 9 des 16 nœuds avec l’édition SQL Server Entreprise, et deux avec l’édition SQL Server Standard.
Une configuration à deux réplicas qui nécessite la possibilité de basculer automatiquement vers un autre réplica requiert l’utilisation d’un réplica utilisé uniquement à des fins de configuration, comme décrit dans Réplica utilisé uniquement à des fins de configuration et quorum. Les réplicas utilisés uniquement à des fins de configuration ont été introduits dans la mise à jour cumulative 1 (CU1) de SQL Server 2017 (14.x). Ce doit être la version minimale déployée pour cette configuration.
Si Pacemaker est utilisé, il doit être correctement configuré de sorte à rester opérationnel. Cela signifie que le quorum et le STONITH doivent être implémentés correctement du point de vue de Pacemaker, en plus de toute exigence de SQL Server, par exemple un réplica utilisé uniquement à des fins de configuration.
Les réplicas secondaires accessibles en lecture sont pris en charge uniquement avec l’édition SQL Server Entreprise.
Type de cluster et mode de basculement
Une des nouveautés de SQL Server 2017 (14.x) est l’introduction d’un type de cluster pour les groupes de disponibilité. Pour Linux, il y a deux valeurs valides : Externe et Aucun. Un type de cluster External signifie que Pacemaker sera utilisé sous le groupe de disponibilité. L’utilisation d’External pour le type de cluster nécessite que le mode de basculement soit défini sur External aussi (une autre nouveauté de SQL Server 2017 (14.x)). Le basculement automatique est pris en charge, mais contrairement à WSFC, le mode de basculement est défini sur External, pas Automatic lorsque Pacemaker est utilisé. Contrairement à WSFC, la partie Pacemaker du groupe de disponibilité est créée après la configuration du groupe de disponibilité.
Un type de cluster None signifie qu’il n’est pas nécessaire que Pacemaker soit configuré ou utilisé par le groupe. Même sur des serveurs où Pacemaker est configuré, si un groupe de disponibilité est configuré avec un type de cluster None, Pacemaker ne voit pas et ne gère pas ce groupe de disponibilité. Le type de cluster None prend en charge uniquement le basculement manuel d’un réplica principal vers un réplica secondaire. Un groupe de disponibilité créé avec None est principalement destiné aux mises à niveau et au scale-out en lecture. Bien qu’il puisse fonctionner dans des scénarios comme la reprise d’activité ou la disponibilité locale où aucun basculement automatique n’est nécessaire, il n’est pas recommandé. L’écouteur est également plus complexe sans Pacemaker.
Le type de cluster est stocké dans la vue de gestion dynamique (DMV) sys.availability_groups de SQL Server, dans les colonnes cluster_type et cluster_type_desc.
required_synchronized_secondaries_to_commit
Une nouveauté de SQL Server 2017 (14.x) est le paramètre required_synchronized_secondaries_to_commit, utilisé par les groupes. Cela indique au groupe de disponibilité le nombre de réplicas secondaires qui doivent être synchronisés avec le réplica principal. Cela permet des opérations telles que le basculement automatique (uniquement lorsqu’il est intégré à Pacemaker avec un type de cluster External) et contrôle le comportement de certains éléments tels que la disponibilité de la base de données principal si le nombre correct de réplicas secondaires est en ligne ou hors connexion. Pour en savoir plus sur ce fonctionnement, consultez Haute disponibilité et protection des données pour les configurations des groupes de disponibilité. La valeur required_synchronized_secondaries_to_commit est définie par défaut et gérée par Pacemaker/SQL Server. Vous pouvez remplacer cette valeur manuellement.
La combinaison de required_synchronized_secondaries_to_commit et du nouveau numéro de séquence (stocké dans sys.availability_groups) informe Pacemaker et SQL Server, par exemple, que le basculement automatique peut survenir. Dans ce cas, un réplica secondaire a le même numéro de séquence que le réplica principal, ce qui signifie qu’il est à jour avec les informations de configuration les plus récentes.
Trois valeurs peuvent être définies pour required_synchronized_secondaries_to_commit : 0, 1 ou 2. Elles contrôlent le comportement de ce qui se produit lorsqu’un réplica devient indisponible. Ces valeurs correspondent au nombre de réplicas secondaires qui doivent être synchronisées avec le réplica principal. Le comportement est le suivant sous Linux :
- 0 - les réplicas secondaires n’ont pas besoin d’être dans un état synchronisé avec le réplica principal. Cependant, si les réplicas secondaires ne sont pas synchronisés, il n’y aura pas de basculement automatique.
- 1 - un réplica secondaire doit être dans un état synchronisé avec le réplica principal ; le basculement automatique est possible. La base de données primaire n’est pas disponible tant qu’un réplica synchrone secondaire n’est pas disponible.
- 2 - deux réplicas secondaires dans une configuration de groupe de disponibilité à trois nœuds ou plus doivent être synchronisés avec le réplica principal. le basculement automatique est possible.
required_synchronized_secondaries_to_commit contrôle non seulement le comportement des basculements avec les réplicas synchrones, mais aussi la perte de données. Avec la valeur 1 ou 2, un réplica secondaire doit toujours être synchronisé, de sorte qu’il y aura toujours une redondance des données. Cela signifie qu’il n’y a aucune perte de données.
Pour modifier la valeur de required_synchronized_secondaries_to_commit, utilisez la syntaxe suivante :
Notes
La modification de la valeur entraîne le redémarrage de la ressource, ce qui signifie une brève interruption. La seule façon d’éviter cela consiste à définir la ressource pour qu’elle ne soit temporairement pas gérée par le cluster.
Red Hat Enterprise Linux (RHEL) et Ubuntu
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
SUSE Linux Enterprise Server (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
où AGResourceName est le nom de la ressource configurée pour le groupe de disponibilité, et Value est 0, 1 ou 2. Pour rétablir la valeur par défaut de l’instance de Pacemaker gérant le paramètre, exécutez la même instruction sans valeur.
Le basculement automatique d’un groupe de disponibilité est possible si les conditions suivantes sont remplies :
- Les réplicas principal et secondaire sont définis sur un déplacement de données synchrone.
- Le réplica secondaire est synchronisé (et non en cours de synchronisation), ce qui signifie que les deux sont au même point de données.
- Le type de cluster est défini sur External. Le basculement automatique n’est pas possible avec un type de cluster None.
- Le
sequence_numberdu réplica secondaire qui devient le réplica principal a le numéro de séquence le plus élevé. En d’autres termes, lesequence_numberdu réplica secondaire correspond à celui du réplica principal d’origine.
Si ces conditions sont remplies et que le serveur qui héberge le réplica principal échoue, le groupe de disponibilité bascule la propriété sur un réplica synchrone. Le comportement des réplicas synchrones (il peut y avoir jusqu’à trois réplicas : un principal et deux secondaires) peut être contrôlé par required_synchronized_secondaries_to_commit. Ceci fonctionne avec des groupes de disponibilité sur Windows et Linux, mais est configuré différemment. Sur Linux, la valeur est configurée automatiquement par le cluster sur la ressource GA elle-même.
Réplica utilisé uniquement à des fins de configuration et quorum
Une autre nouveauté de SQL Server 2017 (14.x) à partir de la CU1 est un réplica utilisé uniquement à des fins de configuration. Comme que Pacemaker est différent de WSFC, en particulier quand il s’agit du quorum et de la nécessité de STONITH, une configuration avec seulement deux nœuds ne va pas fonctionner pour un groupe de disponibilité. Pour une infrastructure de classification des fichiers (ICF), les mécanismes de quorum fournis par Pacemaker peuvent fonctionner, car tous les arbitrages de basculement d’ICF se produisent au niveau de la couche du cluster. Pour un groupe de disponibilité, un arbitrage sous Linux se produit dans SQL Server, où toutes les métadonnées sont stockées. C’est là que le réplica utilisé uniquement à des fins de configuration entre en jeu.
Sans cela, un troisième nœud et au moins un réplica synchronisé seraient requis. Le réplica de configuration uniquement stocke la configuration du groupe de disponibilité dans la base de données master, comme les autres réplicas dans la configuration du groupe de disponibilité. Le réplica de configuration uniquement n’a pas les bases de données utilisateur qui participent au groupe de disponibilité. Les données de configuration sont envoyées de manière synchrone à partir du serveur principal. Ces données de configuration sont ensuite utilisées lors des basculements, qu’elles soient automatiques ou manuelles.
Pour qu’un groupe de disponibilité puisse conserver le quorum et activer les basculements automatiques avec un type de cluster externe, il doit :
- Avoir trois réplicas synchrones (édition SQL Server Entreprise uniquement) ; ou
- Avoir deux réplicas (principal et secondaire) et un réplica de configuration uniquement.
Des basculements manuels peuvent se produire si vous utilisez des types de clusters External ou None pour les configurations de groupe de disponibilité. Bien qu’un réplica de configuration puisse être configuré avec un groupe de disponibilité dont le type de cluster est None, ce n’est pas recommandé, car cela complique le déploiement. Pour ces configurations, modifiez required_synchronized_secondaries_to_commit manuellement pour avoir une valeur au moins égale à 1, de sorte qu’il existe au moins un réplica synchronisé.
Un réplica de configuration peut être hébergé sur toute édition de SQL Server, y compris SQL Server Express. Cela permet de réduire les coûts de licence et de s’assurer du fonctionnement avec les groupes dans l’édition SQL Server Standard. Cela signifie que le troisième serveur nécessaire doit simplement respecter la spécification minimale pour SQL Server, car il ne reçoit pas le trafic des transactions utilisateur pour le groupe de disponibilité.
Lorsqu’un réplica de configuration est utilisé, il a le comportement suivant :
- Par défaut,
required_synchronized_secondaries_to_commitest défini sur 0. Cela peut être modifié manuellement sur 1 si vous le souhaitez. - Si le réplica principal échoue et que
required_synchronized_secondaries_to_commitest égal à 0, le réplica secondaire devient le nouveau réplica principal et est disponible pour la lecture et l’écriture. Si la valeur est 1, le basculement automatique se produit, mais n’accepte pas les nouvelles transactions tant que l’autre réplica n’est pas en ligne. - Si un réplica secondaire échoue et que
required_synchronized_secondaries_to_commita la valeur 0, le réplica principal accepte toujours les transactions, mais si le réplica principal échoue à ce stade, il n’y a pas de protection des données ni de basculement possible (manuel ou automatique), car aucun réplica secondaire n’est disponible. - Si les réplicas de configuration uniquement échouent, le groupe de disponibilité fonctionne normalement, mais aucun basculement automatique n’est possible.
- Si un réplica secondaire synchrone et le réplica de configuration échouent, la base de données primaire ne peut pas accepter de transactions, et il n’y a pas d’endroit où le réplica principal peut basculer.
Dans CU1, il existe un bogue connu dans la journalisation, dans le fichier corosync.log généré via mssql-server-ha. Si un réplica secondaire n’est pas en mesure de devenir le réplica principal en raison du nombre de réplicas disponibles requis, le message actuel indique « Réception attendue de 1 numéros de séquence mais 2 seul reçu. Il n’y a pas assez de réplicas en ligne pour promouvoir le réplica local en toute sécurité.Les nombres doivent être inversés et le message doit plutôt indiquer « Réception attendue de 2 numéros de séquence mais un 1 seul reçu ». Il n’y a pas assez de réplicas en ligne pour promouvoir le réplica local en toute sécurité. »
Groupes de disponibilité multiples
Vous pouvez créer plusieurs groupes de disponibilité par cluster Pacemaker ou ensemble de serveurs. Les ressources système sont la seule limitation. La propriété du groupe de disponibilité est indiquée par le maître. Des groupes différents peuvent appartenir à des nœuds différents ; ils ne doivent pas nécessairement tous être exécutés sur le même nœud.
Emplacement du lecteur et du dossier pour les bases de données
Comme pour les groupes de disponibilité basés sur Windows, la structure de lecteur et des dossiers pour les bases de données utilisateur participant à un groupe de disponibilité doivent être identiques. Par exemple, si les bases de données utilisateur se trouvent sur /var/opt/mssql/userdata sur le serveur A, ce même dossier doit exister sur le serveur B. La seule exception à cela est indiquée dans la section Interopérabilité avec les groupes de disponibilité et les réplicas basés sur Windows.
Écouteur sous Linux
L’écouteur est une fonctionnalité facultative d’un groupe de disponibilité. Il fournit un point d’entrée unique pour toutes les connexions (lecture/écriture sur le réplica principal et/ou lecture seule vers les réplicas secondaires) afin que les applications et les utilisateurs finaux n’aient pas besoin de connaître le serveur qui héberge les données. Dans WSFC, c’est la combinaison d’une ressource de nom de réseau et d’une ressource IP, qui est ensuite inscrite dans AD DS (si nécessaire) et dans le DNS. En association avec la ressource de groupe elle-même, elle fournit cette abstraction. Pour plus d’informations sur les écouteurs, consultez Écouteurs de groupe de disponibilité, connectivité client et basculement d’application.
L’écouteur sous Linux est configuré différemment, mais ses fonctionnalités sont identiques. Il n’existe pas de concept de ressource de nom de réseau dans Pacemaker, et aucun objet n’est créé dans AD DS ; il existe simplement une ressource d’adresse IP créée dans Pacemaker qui peut s’exécuter sur n’importe quel nœud. Une entrée associée à la ressource IP pour l’écouteur dans le DNS avec un « nom convivial » doit être créée. La ressource IP pour l’écouteur sera uniquement active sur le serveur hébergeant le réplica principal pour ce groupe de disponibilité.
Si Pacemaker est utilisé et qu’une ressource d’adresse IP est créée et associée à l’écouteur, il y aura une brève interruption de service lorsque l’adresse IP s’arrêtera sur un serveur et démarrera sur l’autre, qu’il s’agisse d’un basculement automatique ou manuel. Bien que cela fournisse une abstraction via la combinaison d’un seul nom et d’une seule adresse IP, cela ne masque pas la panne. Une application doit être en mesure de gérer la déconnexion en disposant d’une fonctionnalité de détection et de reconnexion.
Toutefois, la combinaison du nom DNS et de l’adresse IP est toujours insuffisante pour fournir toutes les fonctionnalités qu’un écouteur sur WSFC fournit, comme le routage en lecture seule pour les réplicas secondaires. Lors de la configuration d’un groupe de disponibilité, un écouteur doit encore être configuré dans SQL Server. Ceci peut être observé dans l’Assistant et dans la syntaxe Transact-SQL. Il existe deux façons de configurer cela pour que le tout fonctionne de la même façon que sur Windows :
- Pour un groupe de disponibilité avec un type de cluster External, l’adresse IP associée à l’écouteur créé dans SQL Server doit correspondre à l’adresse IP de la ressource créée dans Pacemaker.
- Pour un groupe de disponibilité créé avec un type de cluster None, utilisez l’adresse IP associée au réplica principal.
L’instance associée à l’adresse IP fournie devient alors le coordinateur des événements, tels que les demandes de routage en lecture seule des applications.
Interopérabilité avec les groupes de disponibilité et les réplicas basés sur Windows
Un groupe de disponibilité dont le type de cluster est Externe ou qui est WSFC ne peut pas avoir ses réplicas sur plusieurs plateformes. Cela est valable que le groupe de disponibilité soit l’édition SQL Server Standard ou l’édition SQL Server Entreprise. Cela signifie que dans une configuration de groupe de disponibilité classique avec un cluster sous-jacent, un réplica ne peut pas se trouver sur un WSFC et l’autre sur Linux avec Pacemaker.
Un groupe de disponibilité avec un type de cluster None peut avoir ses réplicas à travers différents systèmes d’exploitation, de sorte qu’il peut y avoir à la fois des réplicas Linux et Windows dans le même groupe de disponibilité. Un exemple est illustré ici où le réplica principal est basé sur Windows, tandis que le réplica secondaire se trouve sur l’une des distributions Linux.
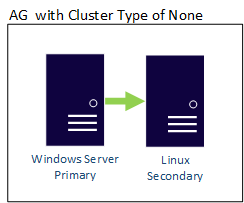
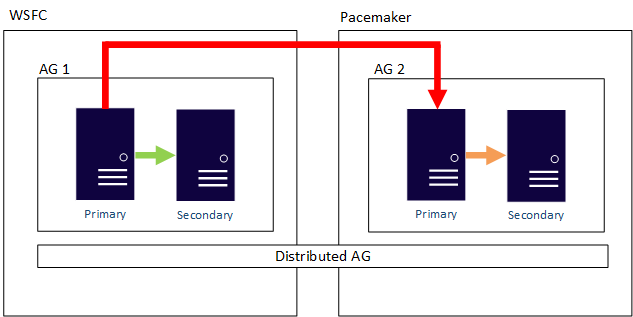
Un groupe de disponibilité distribué peut également franchir les limites entre systèmes d’exploitation. Les groupes sous-jacents sont liés par les règles relatives à la façon dont elles sont configurées. Par exemple, il peut y avoir une configuration de groupe External pour Linux uniquement, mais le groupe de disponibilité auquel ce groupe est joint peut être configuré à l’aide de WSFC. Prenons l’exemple suivant :
Contenu connexe
- Configurer un groupe de disponibilité pour SQL Server sur Linux
- Configurer un groupe de disponibilité d’échelle lecture pour SQL Server sur Linux
- Ajouter une ressource de cluster de groupe de disponibilité sur RHEL
- Ajouter une ressource de cluster de groupe de disponibilité sur SLES
- Ajouter une ressource de cluster de groupe de disponibilité sur Ubuntu
- Configurer un groupe de disponibilité multiplateforme
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour