Diagnostiquer et résoudre la contention de verrouillage tournant dans SQL Server
Cet article fournit des informations détaillées sur la façon d’identifier et de résoudre les problèmes liés à la contention de verrouillage tournant (« spinlock ») dans les applications SQL Server sur des systèmes à haute concurrence.
Remarque
Les recommandations et bonnes pratiques documentées ici sont basées sur une expérience concrète acquise durant le développement et le déploiement de systèmes OLTP réels. Cet article a été initialement publié par l’équipe de conseillers à la clientèle SQL Server (SQLCAT).
Arrière-plan
Par le passé, les ordinateurs Windows Server de base n’utilisaient qu’une ou deux puces microprocesseurs, lesquelles étaient conçues avec un seul processeur ou « cœur ». Des augmentations de la capacité de traitement informatique ont été obtenues à l’aide de processeurs plus rapides, ce qui a permis d’améliorer en grande partie la densité du transistor. Selon la « loi de Moore », la densité des transistors, c’est-à-dire le nombre de transistors pouvant être placés sur un circuit intégré, double tous les deux ans, et ce depuis le développement du premier processeur monopuce universel en 1971. Ces dernières années, l’approche traditionnelle consistant à augmenter la capacité de traitement des ordinateurs avec des processeurs plus rapides a bénéficié de l’apport des ordinateurs multiprocesseurs. À ce stade, l’architecture du processeur Intel Nehalem prend en charge jusqu’à huit cœurs par processeur, qui, lorsqu’elle est utilisée dans un système de huit sockets, peut ensuite être doublée à 128 processeurs logiques à l’aide de la technologie de multithreading simultanée (SMT). Sur les processeurs Intel, SMT est appelé Hyper-Threading. Mais l’augmentation du nombre de processeurs logiques sur les ordinateurs compatibles x86 entraîne une hausse des problèmes de concurrence à mesure que les processeurs logiques se disputent les ressources. Ce guide décrit comment identifier et résoudre les problèmes de contention de ressources particulières observés lors de l’exécution d’applications SQL Server sur des systèmes à haute concurrence avec certaines charges de travail.
Dans cette section, nous analysons les leçons apprises par l’équipe SQLCAT à partir du diagnostic et de la résolution des problèmes de contention de blocage. La contention de verrouillage tournant est un type de problème de concurrence observé dans des charges de travail client réelles sur des systèmes à grande échelle.
Symptômes et causes de la contention de verrouillage tournant
Cette section décrit comment diagnostiquer les problèmes de contention de verrouillage tournant qui nuisent aux performances des applications OLTP sur SQL Server. Le diagnostic et la résolution de ces problèmes sont des sujets avancés qui nécessitent des connaissances sur les outils de débogage et les éléments internes de Windows.
Les verrouillages tournants sont des primitives de synchronisation légères qui permettent de protéger l’accès aux structures de données. Les verrous spinlocks ne sont pas uniques à SQL Server. Le système d’exploitation les utilise quand l’accès à une structure de données n’est nécessaire que pendant une brève période. Si un thread qui tente d’acquérir un verrouillage tournant ne parvient pas à obtenir l’accès, il s’exécute dans une boucle pour vérifier régulièrement si la ressource est disponible au lieu de céder immédiatement le contrôle (« yield »). Après un certain temps, un thread en attente sur un spinlock sera généré avant de pouvoir acquérir la ressource. La cession du contrôle permet à d’autres threads sur le même processeur de s’exécuter. Ce comportement est appelé backoff et est abordé plus en détail plus loin dans cet article.
SQL Server utilise des verrouillages tournants pour protéger l’accès à certaines de ses structures de données internes. De manière similaire aux verrous internes, les verrouillages tournants sont utilisés dans le moteur pour sérialiser l’accès à certaines structures de données. La principale différence entre un verrou et un verrou est le fait que les spinlocks (exécuter une boucle) pendant une période de temps case activée pour la disponibilité d’une structure de données pendant qu’un thread qui tente d’acquérir l’accès à une structure protégée par un verrou génère immédiatement si la ressource n’est pas disponible. La cession du contrôle nécessite le changement de contexte d’un thread du processeur pour qu’un autre thread puisse s’exécuter. Il s’agit d’une opération relativement coûteuse et pour les ressources qui sont conservées pendant une courte durée, il est plus efficace globalement de permettre à un thread d’exécuter dans une boucle régulièrement case activée ing pour la disponibilité de la ressource.
Les ajustements internes apportés au Moteur de base de données introduits dans SQL Server 2022 (16.x) rendent les verrous plus efficaces.
Symptômes
Sur n’importe quel système d’accès concurrentiel élevé occupé, il est normal de voir la contention active sur des structures fréquemment sollicitées protégées par des verrous de spinlocks. La situation ne devient problématique que si la contention introduit une surcharge processeur importante. Les statistiques spinlock sont exposées par la sys.dm_os_spinlock_stats vue de gestion dynamique (DMV) dans SQL Server. Par exemple, cette requête produit la sortie suivante :
Remarque
Vous trouverez plus de détails sur l’interprétation des informations retournées par cette DMV plus loin dans cet article.
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;

Les statistiques exposées par cette requête sont décrites ci-dessous :
| Colonne | Description |
|---|---|
| collisions | Cette valeur est incrémentée chaque fois qu’un thread ne peut pas accéder à une ressource protégée par un verrouillage tournant. |
| spins | Cette valeur est incrémentée chaque fois qu’un thread exécute une boucle dans l’attente de la disponibilité d’un verrouillage tournant. Il s’agit d’une mesure de la quantité de travail qu’un thread effectue pendant qu’il tente d’acquérir une ressource. |
| spins_per_collision | Nombre de spins par collision. |
| sleep time | Cette valeur est liée aux événements de backoff. Toutefois, elle ne s’applique pas aux techniques décrites dans cet article. |
| backoffs | Se produit quand un thread qui « tourne en boucle » pour tenter d’accéder à une ressource protégée détermine qu’il doit autoriser d’autres threads sur le même processeur à s’exécuter. |
Dans le cadre de cette discussion, les statistiques particulièrement intéressantes sont le nombre de « collisions », de « spins » et de « backoffs » qui se produisent au cours d’une période spécifique quand le système est soumis à une charge importante. Quand un thread tente d’accéder à une ressource protégée par un verrouillage tournant, une collision se produit. Le nombre de collisions est alors incrémenté et le thread commence à tourner en boucle pour vérifier périodiquement si la ressource est disponible. Chaque fois que le thread tourne (effectue une boucle), le nombre de spins est incrémenté.
Les spins par collision sont une mesure de la quantité de spins qui se produisent pendant qu’un spinlock est maintenu par un thread et indique le nombre de spins qui se produisent pendant que les threads tiennent le verrou de spin. Par exemple, les petites rotations par collision et le nombre élevé de collisions signifient qu’il y a une petite quantité de spins qui se produisent sous le verrou de spinlock et qu’il y a de nombreux threads qui y sont confrontés. Un grand nombre de spins signifie que le temps passé à tourner en boucle dans le code du verrouillage tournant est relativement long (autrement dit, le code a affaire à un grand nombre d’entrées dans un compartiment de hachage). À mesure que la contention augmente (et, par voie de conséquence, le nombre de collisions), le nombre de spins augmente également.
Les backoffs sont étroitement liés aux spins. Par conception, pour éviter un gaspillage excessif du processeur, les verrous de rotation ne continuent pas indéfiniment à tourner jusqu’à ce qu’ils puissent accéder à une ressource détenue. Pour vous assurer qu’un spinlock n’utilise pas excessivement les ressources du processeur, les blocages de retour ou arrêtent l’épinglage et le « veille ». Un backoff se produit même si le verrouillage ne devient pas propriétaire de la ressource cible. D’autres threads peuvent ainsi être planifiés sur le processeur dans l’espoir d’autoriser l’exécution de tâches plus productives. Le comportement par défaut du moteur est de tourner pendant un intervalle de temps constant avant d’effectuer un backoff. La tentative d’obtention d’un verrouillage tournant nécessite le maintien d’un état de concurrence du cache, ce qui est une opération gourmande en ressources processeur par rapport à une exécution en boucle. Les tentatives d’obtention d’un verrouillage tournant sont donc effectuées avec modération et ne se produisent pas chaque fois qu’un thread s’exécute en boucle. Dans SQL Server, certains types de spinlocks (par exemple : LOCK_HASH) ont été améliorés en utilisant un intervalle d’augmentation exponentielle entre les tentatives d’acquisition du verrouillage (jusqu’à une certaine limite), ce qui réduit souvent l’effet sur les performances du processeur.
Le diagramme suivant fournit une vue conceptuelle de l’algorithme de verrouillage tournant :
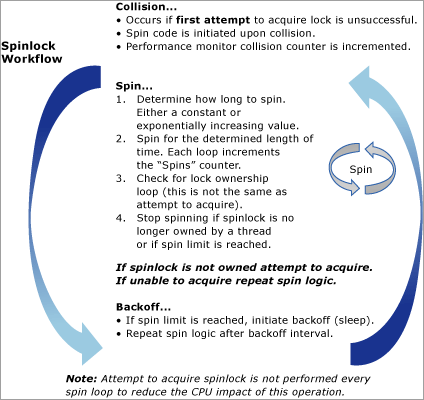
Scénarios classiques
Une contention de verrouillage tournant peut se produire pour diverses raisons qui peuvent n’avoir aucun lien avec les décisions de conception de base de données. Étant donné que les verrous de spinlocks contrôlent l’accès aux structures de données internes, la contention de verrouillage de spinlock n’est pas manifeste de la même façon que la contention de latch de mémoire tampon, qui est directement affectée par les choix de conception de schéma et les modèles d’accès aux données.
Le principal symptôme associé à la contention de verrouillage tournant est une consommation élevée du processeur, celle-ci résultant de la quantité élevée de spins et des nombreux threads tentant d’acquérir le même verrouillage tournant. En général, ce phénomène est observé sur des systèmes avec >=24 cœurs (mais le plus souvent sur des systèmes avec >=32 cœurs). Comme indiqué précédemment, un certain niveau de contention sur les spinlocks est normal pour les systèmes OLTP à forte concurrence avec une charge importante et il y a souvent un grand nombre de spins (milliards/billions) signalés par la sys.dm_os_spinlock_stats DMV sur les systèmes qui ont été exécutés depuis longtemps. Là encore, l’observation d’un nombre élevé de spins pour un type de verrouillage donné n’est pas assez d’informations pour déterminer qu’il y a un impact négatif sur les performances de la charge de travail.
Une combinaison de plusieurs symptômes peut indiquer une contention de verrouillage tournant. Ces symptômes sont les suivants :
Un nombre élevé de spins et de backoffs est observé pour un type de verrouillage tournant particulier.
Le processeur du système fait l’objet d’une utilisation intensive ou de pics de consommation. Dans les scénarios de processeur lourd, vous voyez des attentes de signal élevée sur SOS_SCHEDULER_YIELD (signalées par la vue DMV
sys.dm_os_wait_stats).Le système fait l’objet d’une haute concurrence.
L’utilisation du processeur et le nombre de spins augmentent de manière disproportionnée par rapport au débit.
Important
Même si chacune des conditions précédentes est vraie, il est toujours possible que la cause racine de la consommation élevée du processeur se trouve ailleurs. En fait, dans la grande majorité des cas, l’augmentation de la consommation du processeur est due à des raisons autres que la contention de verrouillage tournant. Voici quelques-unes des causes les plus courantes de la hausse de la consommation du processeur :
Requêtes devenant plus onéreuses au fil du temps en raison de la croissance des données sous-jacentes, d’où la nécessité d’effectuer des lectures logiques supplémentaires des données résidentes en mémoire.
Changements dans les plans de requête aboutissant à une exécution sous-optimale.
Si toutes ces conditions sont vraies, effectuez un examen plus approfondi pour déterminer la présence éventuelle d’une contention de verrouillage tournant.
Un phénomène courant facilement diagnostiqué est une divergence significative entre le débit et l’utilisation du processeur. De nombreuses charges de travail OLTP se caractérisent par une relation entre, d’une part, le rapport débit/nombre d’utilisateurs sur le système et, d’autre part, la consommation du processeur. L’observation conjointe d’un nombre élevé de spins et d’une divergence significative entre la consommation du processeur et le débit peut indiquer que la surcharge du processeur est causée par une contention de verrouillage tournant. Une chose importante à noter ici est qu’il est également courant de voir ce type de divergence sur les systèmes lorsque certaines requêtes deviennent plus coûteuses au fil du temps. Par exemple, des requêtes émises sur des jeux de données qui effectuent un plus grand nombre de lectures logiques au fil du temps peuvent donner lieu à des symptômes similaires.
Il est essentiel d’exclure d’autres causes plus courantes du processeur élevé lors de la résolution de ces types de problèmes.
Exemples
Dans l’exemple suivant, il existe une relation presque linéaire entre la consommation du processeur et le débit, mesurée par les transactions par seconde. Il est normal de voir ici une certaine divergence, car la surcharge est générée au fur et à mesure que toute charge de travail augmente. Comme vous pouvez le voir ici, cette divergence devient importante. Il y a également une baisse rapide du débit une fois que la consommation du processeur atteint 100 %.
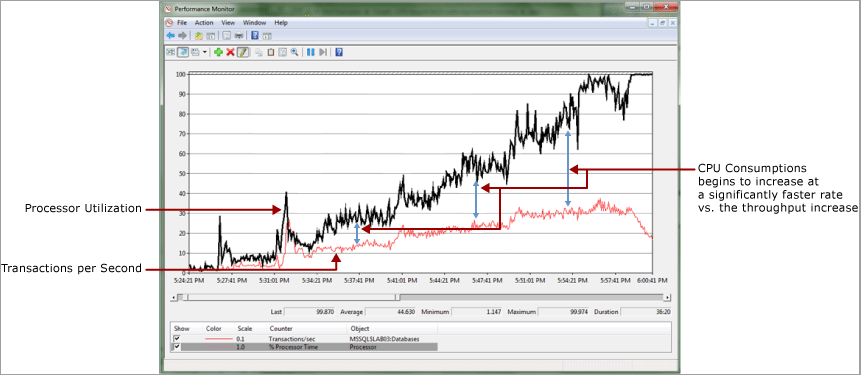
Si nous mesurons le nombre de spins à 3 minutes d’intervalle, nous pouvons voir une augmentation plus exponentielle que linéaire des spins, ce qui indique que la contention de verrouillage tournant peut être problématique.
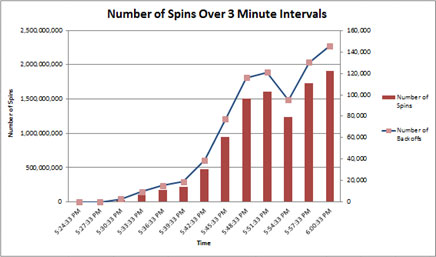
Comme indiqué précédemment, les verrouillages tournants sont les plus fréquents sur des systèmes à haute concurrence soumis à une charge importante.
Voici quelques-uns des scénarios où ce problème est susceptible de se manifester :
Problèmes de résolution de noms causés par l’utilisation de noms d’objets non complets. Pour plus d’informations, consultez Description du blocage SQL Server provoqué par des verrous de compilation. Ce problème spécifique est décrit plus en détail dans cet article.
Contention sur des compartiments de hachage de verrou dans le gestionnaire de verrous pour les charges de travail qui accèdent fréquemment au même verrou (par exemple, un verrou partagé sur une ligne fréquemment lue). Ce type de contention est un verrouillage tournant de type LOCK_HASH. Dans un cas particulier, nous avons constaté que ce problème était dû à des modèles d’accès mal modélisés dans un environnement de test. Dans cet environnement, des threads en quantité supérieure à celle attendue accédaient en permanence à la même ligne en raison d’une mauvaise configuration des paramètres de test.
Taux élevé de transactions DTC en cas de latence élevée entre les coordinateurs de transactions MSDTC. Ce problème spécifique est documenté en détail dans le billet de blog suivant de l’équipe SQLCAT : Resolving DTC Related Waits and Tuning Scalability of DTC.
Diagnostiquer la contention de verrouillage de spinlock
Cette section fournit des informations pour diagnostiquer la contention de verrouillage tournant dans SQL Server. Les principaux outils utilisés pour diagnostiquer la contention de verrouillage tournant sont les suivants :
| Outil | Utilisation |
|---|---|
| Analyseur de performances | Permet de rechercher des conditions d’utilisation élevée du processeur ou une divergence entre le débit et la consommation du processeur. |
sys.dm_os_spinlock stats DMV** |
Permet de rechercher un nombre élevé de spins et d’événements de backoff sur des périodes de temps. |
| Événements étendus SQL Server | Permet de suivre des piles d’appels à la recherche de verrouillages tournants avec un grand nombre de spins. |
| Images mémoire | Dans certains cas, il est utile d’analyser les images mémoire du processus SQL Server avec les outils de débogage Windows. En général, cette analyse est menée en collaboration avec les équipes du support technique de Microsoft SQL Server. |
Le processus technique généralement employé pour diagnostiquer une contention de verrouillage tournant dans SQL Server est le suivant :
Étape 1 : Déterminez qu’il y a des contentions qui peuvent être liées au verrouillage.
Étape 2 : Capturer des statistiques à partir de
sys.dm_ os_spinlock_stats pour trouver le type de spinlock qui rencontre le plus de contention.Étape 3 : Obtenir des symboles de débogage pour sqlservr.exe (sqlservr.pdb) et placer les symboles dans le même répertoire que le fichier .exe du service SQL Server (sqlservr.exe) pour l’instance de SQL Server.\ Pour voir les piles d’appels pour les événements d’annulation, vous devez avoir des symboles pour la version particulière de SQL Server que vous exécutez. Les symboles pour SQL Server sont disponibles sur le serveur de symboles Microsoft. Pour plus d’informations sur le téléchargement de symboles à partir du serveur de symboles Microsoft, consultez Débogage avec des symboles.
Étape 4 : Utilisez les événements étendus SQL Server pour tracer les événements de retour pour les types d’intérêt de spinlock.
Les événements étendus permettent d’effectuer le suivi de l’événement « backoff » et de capturer la pile des appels pour ces opérations les plus répandues en essayant d’obtenir le verrouillage. En analysant la pile des appels, il est possible de déterminer quel type d’opération contribue à la contention d’un verrouillage spécifique.
Procédure pas à pas de diagnostic
La procédure pas à pas suivante vous montre comment utiliser les outils et techniques présentés dans cet article pour diagnostiquer un problème de contention de verrouillage tournant dans un scénario réel. Cette procédure se base sur un engagement client exécutant un test de référence pour simuler environ 6 500 utilisateurs simultanés sur un serveur contenant 8 sockets, 64 cœurs physiques et 1 To de mémoire.
Symptômes
Des pics périodiques sont observés, provoquant une utilisation du processeur proche des 100 %. Une divergence entre le débit et la consommation du processeur est également constatée avant l’apparition du problème. Au moment du pic de consommation du processeur, un modèle composé d’un grand nombre de spins se produisant durant les périodes de forte utilisation du processeur à des intervalles particuliers est établi.
Dans ce cas extrême, la contention est telle qu’elle crée une condition de convoi de verrouillage tournant. Un convoi se produit lorsque les threads n’avancent plus dans la gestion de la charge de travail et qu’ils utilisent à la place toutes les ressources de traitement pour tenter d’accéder au verrou. Le journal de l’Analyseur de performances montre cette divergence entre le débit du journal des transactions et la consommation du processeur, et enfin le pic d’utilisation du processeur.
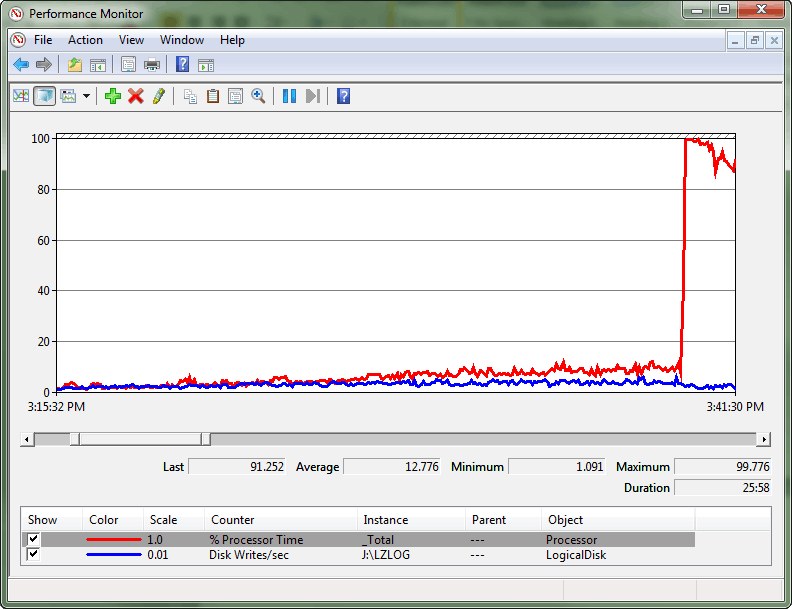
Après avoir interrogé sys.dm_os_spinlock_stats pour déterminer l’existence d’une contention importante sur SOS_CACHESTORE, un script d’événements étendus a été utilisé pour mesurer le nombre d’événements d’interruption pour les types d’intérêt spinlock.
| Nom | Collisions | Spins | Spins par collision | Backoffs |
|---|---|---|---|---|
SOS_CACHESTORE |
14 752 117 | 942 869 471 526 | 63 914 | 67 900 620 |
SOS_SUSPEND_QUEUE |
69 267 367 | 473 760 338 765 | 6 840 | 2 167 281 |
LOCK_HASH |
5 765 761 | 260 885 816 584 | 45 247 | 3 739 208 |
MUTEX |
2 802 773 | 9 767 503 682 | 3 485 | 350 997 |
SOS_SCHEDULER |
1 207 007 | 3 692 845 572 | 3 060 | 109 746 |
La façon la plus simple de quantifier l’impact des spins consiste à examiner le nombre d’événements d’interruption exposés par sys.dm_os_spinlock_stats le même intervalle de 1 minute pour le ou les types de spinlocks avec le plus grand nombre de spins. Cette méthode est idéale pour détecter une contention importante, car elle indique quand les threads arrivent à la limite de spins dans l’attente d’acquérir le verrouillage tournant. Le script suivant illustre une technique avancée qui utilise des événements étendus pour mesurer les événements de backoff associés et identifier les chemins de code spécifiques où se situe la contention.
Pour plus d’informations sur les événements étendus dans SQL Server, consultez Présentation des événements étendus SQL Server.
Script
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
En analysant la sortie, nous pouvons voir les piles d’appels pour les chemins de code les plus courants pour les spins SOS_CACHESTORE. Le script a été exécuté plusieurs fois pendant la période de forte utilisation du processeur pour vérifier la cohérence dans les piles d’appels retournées. Les piles d’appels avec le nombre de compartiments d’emplacements le plus élevé sont courantes entre les deux sorties (35 668 et 8 506). Ces piles d’appels ont un nombre d’emplacements (« slot count ») deux fois supérieur à l’entrée suivante. Cette condition indique un chemin de code digne d’intérêt.
Remarque
Il n’est pas rare de voir les piles d’appels retournées par le script précédent. Lorsque le script s’est exécuté pendant 1 minute, nous avons observé que les piles d’appels avec un nombre d’emplacements de > 1 000 étaient problématiques, mais le nombre d’emplacements de > 10 000 était plus susceptible d’être problématique, car il s’agit d’un nombre d’emplacements plus élevé.
Remarque
La mise en forme de la sortie suivante a été nettoyée pour la rendre plus lisible.
Sortie 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Sortie 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Dans l’exemple précédent, les piles les plus intéressantes ont le nombre d’emplacements le plus élevé (35 668 et 8 506), qui, en fait, ont un nombre d’emplacements >1 000.
À présent, vous vous demandez peut-être ce que vous devez faire de ces informations. En général, une connaissance approfondie du moteur SQL Server est nécessaire pour utiliser les informations de la pile d’appels. À ce stade, le processus de résolution des problèmes entre dans une zone grise. Dans ce cas particulier, en examinant les piles d’appels, nous pouvons voir que le chemin d’accès du code où le problème se produit est lié aux recherches de sécurité et de métadonnées (comme indiqué par les images CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID)de pile suivantes.
En isolation, il est difficile d’utiliser ces informations pour résoudre le problème, mais il nous donne quelques idées où concentrer davantage la résolution des problèmes afin d’isoler davantage le problème.
Étant donné que ce problème semble lié aux chemins de code qui effectuent des contrôles liés à la sécurité, nous décidons d’exécuter un test dans lequel l’utilisateur de l’application se connectant à la base de données se voit accorder des privilèges sysadmin. Bien que cette technique ne soit jamais recommandée dans un environnement de production, elle constitue une étape de dépannage utile dans notre environnement de test. Quand les sessions sont exécutées avec des privilèges élevés (sysadmin), les pics d’utilisation du processeur liés à la contention disparaissent.
Options et solutions de contournement
De toute évidence, le dépannage d’une contention de verrouillage tournant est loin d’être une tâche négligeable. Il n’y a pas de « meilleure approche commune ». La première étape en vue de résoudre des problèmes de performances est d’identifier la cause racine. Commencez par utiliser les techniques et les outils décrits dans cet article pour analyser et comprendre les points de contention liés au verrouillage tournant.
À mesure que de nouvelles versions de SQL Server sont développées, le moteur continue d’améliorer la scalabilité en implémentant du code qui est mieux optimisé pour les systèmes à haute concurrence. SQL Server a ainsi introduit de nombreuses optimisations pour les systèmes à haute concurrence, l’une d’entre elles étant le backoff exponentiel pour les points de contention les plus courants. Des améliorations spécifiques ont été apportées à partir de SQL Server 2012 pour renforcer spécifiquement cette zone particulière en tirant parti des algorithmes de backoff exponentiel pour tous les verrouillages tournants au sein du moteur.
Quand vous concevez des applications haut de gamme nécessitant des performances et une scalabilité extrêmes, pensez à réduire au maximum le chemin de code nécessaire dans SQL Server. Un chemin de code plus court permet de réduire la charge de travail du moteur de base de données et d’éviter naturellement les points de contention. De nombreuses bonnes pratiques ont pour effet secondaire de réduire la quantité de travail du moteur, d’où une optimisation des performances de la charge de travail.
Voici quelques exemples de bonnes pratiques précédemment traitées dans cet article :
Noms complets : les noms qualifiés complets de tous les objets entraînent la suppression de la nécessité pour SQL Server d’exécuter des chemins de code requis pour résoudre les noms. Nous avons également observé des points de contention sur le type de verrouillage tournant SOS_CACHESTORE lors de l’utilisation de noms non complets dans les appels à des procédures stockées. Si vous n’utilisez pas de noms complets, SQL Server doit rechercher le schéma par défaut de l’utilisateur, ce qui se traduit par un chemin de code plus long requis pour exécuter le code SQL.
Requêtes paramétrables : un autre exemple consiste à utiliser des requêtes paramétrables et des appels de procédure stockée pour réduire le travail nécessaire pour générer des plans d’exécution. Vous obtenez là encore un chemin de code plus court pour l’exécution.
LOCK_HASH Contention : la contention sur certaines collisions de compartiments de verrouillage ou de hachage est inévitable dans certains cas. Bien que le moteur SQL Server partitionne la majorité des structures de verrouillage, il arrive encore que l’acquisition d’un verrou entraîne l’accès au même compartiment de hachage. Cela se produit par exemple quand une application accède simultanément à la même ligne (des données de référence) par le biais de plusieurs threads. Ces types de problèmes peuvent être abordés par des techniques qui effectuent un scale-out de ces données de référence dans le schéma de base de données ou utilisent des indicateurs NOLOCK si possible.
La première ligne de défense en matière de réglage des charges de travail SQL Server est de faire appel aux pratiques standard (indexation, optimisation des requêtes, optimisation des E/S, etc.). Toutefois, en plus du réglage standard, une approche importante consiste à suivre des pratiques qui réduisent la quantité de code nécessaire pour effectuer des opérations. Même lorsque les meilleures pratiques sont suivies, il est toujours possible que la contention de blocage se produise sur des systèmes d’accès concurrentiel élevé occupés. L’utilisation des outils et techniques de cet article peut aider à isoler ou à exclure ces types de problèmes et à déterminer quand il est nécessaire d’engager les ressources Microsoft appropriées pour vous aider.
Espérons que ces techniques vous fourniront à la fois une méthodologie utile pour ce type de dépannage et des insights sur certaines des techniques de profilage des performances plus avancées disponibles avec SQL Server.
Annexe : Automatiser la capture de vidage de mémoire
Le script d’événements étendus suivant est utile pour automatiser la collecte des images mémoire quand la contention de verrouillage tournant devient importante. Dans certains cas, des images mémoire sont nécessaires pour effectuer un diagnostic complet du problème ou sont demandées par les équipes du support technique de Microsoft pour procéder à une analyse approfondie. Dans SQL Server 2008, il existe une limite de 16 images dans les piles d’appels capturées par le bucketizer, ce qui peut ne pas être suffisamment profond pour déterminer exactement où dans le moteur à partir duquel la pile d’appels est entrée. Dans SQL Server 2012, le nombre de frames dans les piles d’appels capturées par le bucketizer passe à 32.
Vous pouvez utiliser le script SQL suivant pour automatiser le processus de capture d’images mémoire afin de faciliter l’analyse de la contention de verrouillage tournant :
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
Annexe : Capturer les statistiques de verrouillage au fil du temps
Vous pouvez utiliser le script suivant pour examiner les statistiques d’un verrouillage tournant sur une période de temps spécifique. Chaque fois que vous l’exécutez, il retourne la valeur delta entre les valeurs actuelles et les valeurs précédentes collectées.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;
Étape suivante
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour