CREATE TABLE AS SELECT
S’applique à : ![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
CREATE TABLE AS SELECT (CTAS) est l’une des fonctionnalités de T-SQL les plus importantes. Il s’agit d’une opération entièrement parallélisée qui crée une table en fonction de la sortie d’une instruction SELECT. CTAS offre le moyen le plus simple et le plus rapide de créer une copie de table.
Par exemple, CTAS vous permet d’effectuer les opérations suivantes :
- Recréer une table avec une colonne de distribution de hachage différente.
- Recréer une table comme étant répliquée.
- Créer un index columnstore uniquement sur certaines colonnes de la table.
- Interroger ou importer des données externes.
Notes
CTAS s’ajoute aux fonctionnalités de création de table. Ainsi, au lieu de répéter le contenu de la rubrique CREATE TABLE, cette rubrique décrit les différences entre les instructions CTAS et CREATE TABLE. Pour le détail de CREATE TABLE, consultez l’état de CREATE TABLE (Azure Synapse Analytics).
- Cette syntaxe n’est pas prise en charge par le pool SQL serverless dans Azure Synapse Analytics.
- CTAS est pris en charge dans l’entrepôt dans Microsoft Fabric.
![]() Conventions de la syntaxe Transact-SQL
Conventions de la syntaxe Transact-SQL
Syntaxe
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Arguments
Pour plus d’informations, consultez la section Arguments de la rubrique CREATE TABLE.
Options de colonne
column_name [ ,...n ]
Les noms de colonne n’autorisent pas les options de colonne mentionnées dans CREATE TABLE. À la place, vous pouvez fournir une liste facultative d’un ou plusieurs noms de colonne pour la nouvelle table. Les colonnes de la nouvelle table utilisent les noms que vous spécifiez. Quand vous spécifiez des noms de colonne, le nombre de colonnes figurant dans la liste de colonnes doit correspondre au nombre de colonnes figurant dans les résultats de l’instruction select. Si vous ne spécifiez pas de noms de colonnes, la nouvelle table cible utilise ceux qui figurent dans les résultats de l’instruction SELECT.
Vous ne pouvez spécifier aucune autre option de colonne comme les types de données, le classement ou la possibilité de valeur NULL. Chacun de ces attributs est dérivé des résultats de l’instruction SELECT. Cependant, vous pouvez utiliser l’instruction SELECT pour modifier les attributs. Pour obtenir un exemple, consultez Utiliser CTAS pour modifier des attributs de colonne.
Options de distribution de table
Pour savoir comment choisir la colonne de distribution la plus appropriée, consultez la section Options de distribution de table de la rubrique CREATE TABLE. Pour obtenir des recommandations sur la distribution à choisir pour une table en fonction de l’utilisation réelle ou des exemples de requêtes, consultez Distribution Advisor dans Azure Synapse SQL.
DISTRIBUTION = HASH (distribution_column_name) | ROUND_ROBIN | REPLICATE L’instruction CTAS nécessite une option de distribution et n’a pas de valeurs par défaut. Elle se distingue ainsi de CREATE TABLE qui a des valeurs par défaut.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] ) Distribue les lignes en fonction des valeurs de hachage allant jusqu’à huit colonnes, ce qui permet une distribution plus uniforme des données de table de base, et donc une réduction de l’asymétrie des données au fil du temps et une amélioration des performances des requêtes.
Notes
- Pour activer la fonctionnalité, changez le niveau de compatibilité de la base de données à 50 avec cette commande. Pour plus d’informations sur la définition du niveau de compatibilité de la base de données, consultez ALTER DATABASE SCOPED CONFIGURATION. Par exemple :
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - Pour désactiver la fonctionnalité MCD, exécutez cette commande pour changer le niveau de compatibilité de la base de données à AUTO. Par exemple :
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;Les tables MCD existantes sont conservées, mais elles ne sont plus accessibles. Les requêtes sur les tables MCD retournent cette erreur :Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- Pour rétablir l’accès aux tables MCD, réactivez la fonctionnalité.
- Pour charger des données dans une table MCD, utilisez l’instruction CTAS et la source de données doit être des tables SQL Synapse.
- CTAS sur des tables cibles MCD HEAP n’est pas pris en charge. Utilisez au lieu de cela INSERT SELECT comme solution de contournement pour charger des données dans des tables MCD HEAP.
- L’utilisation de SSMS pour générer un script permettant de créer des tables MCD est possible après SSMS version 19.
Pour savoir comment choisir la colonne de distribution la plus appropriée, consultez la section Options de distribution de table de la rubrique CREATE TABLE.
Pour obtenir des suggestions relatives à la meilleure stratégie de distribution à utiliser en fonction de vos charges de travail, consultez Azure Synapse SQL Distribution Advisor (préversion).
Options de partition de table
L’instruction CTAS crée par défaut une table non partitionnée, même si la table source est partitionnée. Pour créer une table partitionnée avec l’instruction CTAS, vous devez spécifier l’option de partition.
Pour plus d’informations, consultez la section Options de partition de table de la rubrique CREATE TABLE.
Instruction SELECT
L’instruction SELECT représente la différence fondamentale entre CTAS et CREATE TABLE.
WITHcommon_table_expression
Spécifie un jeu de résultats nommé temporaire, désigné par le terme d'expression de table commune (CTE, Common Table Expression). Pour plus d’informations, consultez WITH common_table_expression (Transact-SQL).
SELECTselect_criteria
Remplit la nouvelle table avec les résultats d’une instruction SELECT. select_criteria correspond au corps de l’instruction SELECT qui détermine les données qui sont copiées dans la nouvelle table. Pour plus d’informations sur les instructions SELECT, consultez SELECT (Transact-SQL).
Indicateur de requête
Les utilisateurs peuvent définir MAXDOP sur une valeur entière pour contrôler le degré maximal de parallélisme. Quand MAXDOP a la valeur 1, la requête est exécutée par un seul thread.
Autorisations
CTAS exige une autorisation SELECT sur les objets référencés dans select_criteria.
Pour plus d’informations sur les autorisations permettant de créer une table, consultez Autorisations dans la rubrique CREATE TABLE.
Notes
Pour plus d’informations, consultez Remarques d’ordre général dans la rubrique CREATE TABLE.
Limitations et restrictions
Un index Columnstore en cluster ordonné peut être créé sur les colonnes de tout type de données pris en charge dans Azure Synapse Analytics à l’exception des colonnes de type chaîne.
SET ROWCOUNT (Transact-SQL) ne produit aucun effet sur CTAS. Pour obtenir un comportement similaire, utilisez TOP (Transact-SQL).
Pour plus d’informations, consultez Limitations et restrictions dans la rubrique CREATE TABLE.
Comportement du verrouillage
Pour plus d’informations, consultez Comportement de verrouillage dans la rubrique CREATE TABLE.
Performances
Pour une table de hachage distribuée, CTAS vous permet de choisir une colonne de distribution différente pour bénéficier de meilleures performances pour les jointures et les agrégations. Si votre objectif n’est pas de choisir une colonne de distribution différente, vous bénéficierez de meilleures performances avec CTAS si vous spécifiez la même colonne de distribution, car vous éviterez ainsi une redistribution des lignes.
Si vous utilisez CTAS pour créer une table et que les performances ne sont pas un facteur déterminant, vous pouvez spécifier ROUND_ROBIN pour éviter d’avoir à choisir une colonne de distribution.
Pour éviter un déplacement de données dans les requêtes suivantes, vous pouvez spécifier REPLICATE au prix d’un stockage accru pour charger une copie complète de la table sur chaque nœud de calcul.
Exemples de copie d’une table
R. Utiliser CTAS pour copier une table
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
L’une des utilisations les plus courantes de CTAS est peut-être celle qui consiste à créer une copie d’une table dans le but de pouvoir modifier le langage de définition de données (DDL). Si vous avez créé par exemple une table de type ROUND_ROBIN à l’origine et que vous souhaitez désormais la modifier pour la changer en table distribuée sur une colonne, CTAS vous permet de modifier la colonne de distribution. CTAS permet aussi de modifier le partitionnement, l’indexation ou les types de colonnes.
Supposons que vous avez créé cette table en spécifiant HEAP et en utilisant le type de distribution par défaut ROUND_ROBIN.
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Maintenant, vous voulez créer une copie de cette table avec un index cluster columnstore de façon à profiter des performances offertes par les tables cluster columnstore. Vous souhaitez également distribuer cette table sur ProductKey, car vous anticipez des jointures sur cette colonne et vous souhaitez éviter le déplacement de données au cours des jointures sur ProductKey. Enfin, vous souhaitez ajouter le partitionnement sur OrderDateKey pour pouvoir supprimer rapidement les données anciennes en annulant les anciennes partitions. Voici l’instruction CTAS permettant de copier l’ancienne table dans une nouvelle :
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Enfin, vous pouvez renommer vos tables pour spécifier la nouvelle table et supprimer l’ancienne.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Exemples d’options de colonne
B. Utiliser CTAS pour modifier des attributs de colonne
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Cet exemple utilise CTAS pour modifier des types de données, la possibilité de valeur NULL et le classement pour plusieurs colonnes dans la table DimCustomer2.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
En dernier lieu, vous pouvez utiliser RENAME (Transact-SQL) pour permuter les noms de tables. DimCustomer2 devient ainsi la nouvelle table.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Exemples de distribution de table
C. Utiliser CTAS pour modifier la méthode de distribution d’une table
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Cet exemple simple montre comment modifier la méthode de distribution d’une table. Pour détailler la procédure, il transforme une table de hachage distribuée en table round robin (tourniquet), puis reconvertit cette dernière en table de hachage distribuée. La table finale correspond à la table d’origine.
Dans la plupart des cas, il n’est pas nécessaire de transformer une table de hachage distribuée en table round robin. En revanche, vous serez plus souvent amené à transformer une table round robin en table de hachage distribuée. Par exemple, vous pouvez décider dans un premier temps de charger une nouvelle table sous forme de table round robin pour dans un second temps la convertir en table de hachage distribuée pour bénéficier de meilleures performances de jointure.
Cet exemple utilise l’exemple de base de données AdventureWorks. Pour charger la version Azure Synapse Analytics, consultez Démarrage rapide : Créer et interroger un pool SQL dédié (anciennement SQL DW) dans Azure Synapse Analytics à l’aide du portail Azure.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Ensuite, reconvertissez-la en table de hachage distribuée.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. Utiliser CTAS pour convertir une table en table répliquée
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Cet exemple vaut pour la conversion de tables round robin ou de hachage distribuées en table répliquée. Cet exemple précis va encore plus loin que la méthode précédente de modification du type de distribution. DimSalesTerritory étant une dimension et probablement une table de plus petite taille, vous pouvez choisir de la recréer sous forme de table répliquée pour éviter les déplacements des données lors des jointures à d’autres tables.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. Utiliser CTAS pour créer une table avec moins de colonnes
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
L’exemple suivant crée une table distribuée de type round robin nommée myTable (c, ln). La nouvelle table contient seulement deux colonnes. Elle utilise les alias des colonnes dans l’instruction SELECT à la place des noms des colonnes.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Exemples d’indicateurs de requête
F. Utiliser un indicateur de requête avec CREATE TABLE AS SELECT (CTAS)
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Cette requête présente la syntaxe de base pour utiliser un indicateur de jointure de requête avec l’instruction CTAS. Une fois la requête envoyée, Azure Synapse Analytics applique la stratégie de jointure hachée au moment de générer le plan de requête pour chaque distribution individuelle. Pour plus d’informations sur l’indicateur de requête de jointure hachée, consultez Clause OPTION (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Exemples de tables externes
G. Utiliser CTAS pour importer des données à partir du stockage Blob Azure
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Pour importer des données à partir d’une table externe, utilisez CREATE TABLE AS SELECT pour effectuer une sélection dans la table externe. La syntaxe à utiliser pour sélectionner des données dans une table externe à destination de Azure Synapse Analytics est la même que celle permettant de sélectionner des données dans une table normale.
L’exemple suivant définit une table externe sur des données situées dans un compte Stockage Blob Azure. Il utilise ensuite CREATE TABLE AS SELECT pour effectuer une sélection dans la table externe. Les données sont alors importées à partir de fichiers au format texte délimité à partir du Stockage Blob Azure, puis stockées dans une nouvelle table Azure Synapse Analytics.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Utiliser CTAS pour importer des données Hadoop à partir d’une table externe
S’applique à : Analytics Platform System (PDW)
Pour importer des données à partir d’une table externe, utilisez simplement CREATE TABLE AS SELECT pour effectuer une sélection dans la table externe. La syntaxe à utiliser pour sélectionner des données dans une table externe à destination de Analytics Platform System (PDW) est la même que celle permettant de sélectionner des données dans une table normale.
L’exemple suivant définit une table externe sur un cluster Hadoop. Il utilise ensuite CREATE TABLE AS SELECT pour effectuer une sélection dans la table externe. Les données sont alors importées à partir de fichiers délimités par du texte Hadoop, puis stockées dans une nouvelle table Analytics Platform System (PDW).
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Exemples d’utilisation de CTAS pour remplacer du code SQL Server
CTAS permet de pallier l’absence de prise en charge de certaines fonctionnalités. En plus de permettre l’exécution de votre code dans l’entrepôt de données, le fait de réécrire le code existant pour utiliser CTAS aura généralement pour effet d’améliorer les performances. C’est le résultat de sa conception entièrement parallélisée.
Notes
Essayez de penser à CTAS en priorité. Si vous pensez que vous pouvez résoudre un problème avec CTAS, c’est qu’il s’agit généralement de la meilleure façon de l’aborder, même si cela sous-entend d’écrire plus de données.
I. Utiliser CTAS plutôt que SELECT..INTO
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Le code SQL Server utilise généralement SELECT..INTO pour remplir une table avec les résultats d’une instruction SELECT. Voici un exemple d’instruction SQL Server SELECT..INTO.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Cette syntaxe n’est pas prise en charge dans Azure Synapse Analytics et Parallel Data Warehouse. Cet exemple montre comment réécrire l’instruction SELECT..INTO précédente pour en faire une instruction CTAS. Vous pouvez choisir l’une des options DISTRIBUTION décrites dans la syntaxe CTAS. Cet exemple utilise la méthode de distribution ROUND_ROBIN.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Utiliser CTAS pour simplifier les instructions merge
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Les instructions merge peuvent être remplacées, du moins en partie, à l’aide de CTAS. Vous pouvez regrouper INSERT et UPDATE dans une même instruction. Les enregistrements supprimés doivent être fermés dans une deuxième instruction.
Un exemple de UPSERT est donné ci-dessous :
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. déclarer explicitement le type de données et la possibilité de valeur NULL de la sortie
S’applique à : Azure Synapse Analytics et Analytics Platform System (PDW)
Au moment de migrer du code SQL Server vers Azure Synapse Analytics, il se peut que vous rencontriez un modèle de codage de ce type :
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Vous pourriez penser instinctivement que ce code doit être migré vers CTAS, et vous auriez raison. Toutefois, un problème se dissimule derrière ce scénario.
Le code suivant NE produit PAS le même résultat :
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
Notez que la colonne « result » reprend le type de données et la possibilité de valeur NULL de l’expression. Cela peut occasionner de légers écarts dans les valeurs si vous ne faites pas attention.
Faites un essai avec l’exemple suivant :
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
Les valeurs de résultats enregistrées sont différentes. Comme la valeur persistante dans la colonne « result » est utilisée dans d’autres expressions, l’erreur devient plus significative.
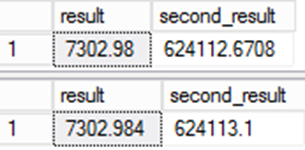
C’est important dans le cas des migrations de données. Bien que la seconde requête soit effectivement plus précise, un problème se pose. Les données sont différentes par rapport au système source, ce qui soulève la question de l’intégrité de la migration. Il s’agit de l’un des rares cas où la « mauvaise » réponse est en fait la bonne réponse !
Cette différence entre les deux résultats est liée à la conversion de type (transtypage) implicite. Dans le premier exemple, la table définit la définition de colonne. Au moment où la ligne est insérée, une conversion de type implicite se produit. Dans le deuxième exemple, il n’y a pas de conversion de type implicite, car l’expression définit le type de données de la colonne. La colonne figurant dans le second exemple a été définie comme une colonne Nullable, ce qui n’est pas son cas dans le premier exemple. Quand la table a été créée dans le premier exemple, la possibilité de valeur NULL dans la colonne était définie explicitement. Dans le deuxième exemple, elle a été laissée dans l’expression ce qui, par défaut, donne une définition NULL.
Pour résoudre ces problèmes, vous devez explicitement définir la conversion de type et la possibilité de valeur Null dans la partie SELECT de l’instruction CTAS. Vous ne pouvez pas définir ces propriétés dans la partie « create table ».
Cet exemple montre comment corriger le code :
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Notez les points suivants dans l’exemple :
- CAST ou CONVERT aurait pu être utilisé.
- ISNULL est utilisé, et non COALESCE, pour forcer la possibilité de valeur NULL.
- ISNULL est la fonction située la plus à l’extérieur.
- La seconde partie de l’instruction ISNULL est une constante :
0.
Notes
Pour que la possibilité de valeur NULL soit correctement définie, il est indispensable d’utiliser ISNULL et non COALESCE. COALESCE n’est pas une fonction déterministe. De ce fait, le résultat de l’expression peut toujours prendre la valeur NULL. La fonction ISNULL est différente. Elle est déterministe. Par conséquent, quand la deuxième partie de la fonction ISNULL est une constante ou un littéral, la valeur obtenue n’est pas NULL.
Ce conseil n’est pas seulement utile pour assurer l’intégrité de vos calculs. Il est aussi important pour le basculement de partition de table. Imaginez que vous avez défini cette table :
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
Or, il s’avère que le champ de valeur est une expression calculée ; il ne fait pas partie des données sources.
Pour créer votre jeu de données partitionné, considérez l’exemple suivant :
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
La requête s’exécuterait parfaitement, mais le problème se manifesterait quand vous tenteriez de procéder au basculement de partition. Les définitions de table ne correspondent pas. Pour que les définitions de table correspondent, le CTAS doit être modifié.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Comme vous pouvez le remarquer, la cohérence des types et le maintien des propriétés de possibilité de valeur NULL au niveau de CTAS constituent une bonne pratique d’ingénierie. Elle vous permet de préserver l’intégrité de vos calculs et garantit aussi la possibilité d’un basculement de partition.
L. Créer un index columnstore cluster ordonné avec MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Étapes suivantes
- CREATE EXTERNAL DATA SOURCE (Transact-SQL)
- CREATE EXTERNAL FILE FORMAT (Transact-SQL)
- CREATE EXTERNAL TABLE (Transact-SQL)
- CREATE EXTERNAL TABLE AS SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP TABLE (Transact-SQL)
- DROP EXTERNAL TABLE (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- ALTER EXTERNAL TABLE (Transact-SQL)
S’applique à :![]() Entrepôt dans Microsoft Fabric
Entrepôt dans Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) est l’une des fonctionnalités de T-SQL les plus importantes. Il s’agit d’une opération entièrement parallélisée qui crée une table en fonction de la sortie d’une instruction SELECT. CTAS offre le moyen le plus simple et le plus rapide de créer une copie de table.
Par exemple, utilisez CTAS dans un entrepôt dans Microsoft Fabric pour :
- Créer une copie d’une table avec certaines colonnes de la table source.
- Créer une table qui est le résultat d’une requête qui joint d’autres tables.
Pour en savoir plus sur l’utilisation de CTAS sur votre entrepôt dans Microsoft Fabric, reportez-vous à Ingérer des données dans votre entrepôt à l’aide de Transact-SQL.
Remarque
CTAS s’ajoute aux fonctionnalités de création de table. Ainsi, au lieu de répéter le contenu de la rubrique CREATE TABLE, cette rubrique décrit les différences entre les instructions CTAS et CREATE TABLE. Pour plus d’informations sur l’instruction CREATE TABLE, consultez CREATE TABLE.
![]() Conventions de la syntaxe Transact-SQL
Conventions de la syntaxe Transact-SQL
Syntaxe
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Arguments
Pour plus d’informations, consultez Arguments dans CREATE TABLE pour Microsoft Fabric.
Options de colonne
column_name [ ,...n ]
Les noms de colonne n’autorisent pas les options de colonne mentionnées dans CREATE TABLE. À la place, vous pouvez fournir une liste facultative d’un ou plusieurs noms de colonne pour la nouvelle table. Les colonnes de la nouvelle table utilisent les noms que vous spécifiez. Quand vous spécifiez des noms de colonne, le nombre de colonnes figurant dans la liste de colonnes doit correspondre au nombre de colonnes figurant dans les résultats de l’instruction select. Si vous ne spécifiez pas de noms de colonnes, la nouvelle table cible utilise ceux qui figurent dans les résultats de l’instruction SELECT.
Vous ne pouvez spécifier aucune autre option de colonne comme les types de données, le classement ou la possibilité de valeur NULL. Chacun de ces attributs est dérivé des résultats de l’instruction SELECT. Cependant, vous pouvez utiliser l’instruction SELECT pour modifier les attributs.
Instruction SELECT
L’instruction SELECT représente la différence fondamentale entre CTAS et CREATE TABLE.
SELECTselect_criteria
Remplit la nouvelle table avec les résultats d’une instruction SELECT. select_criteria correspond au corps de l’instruction SELECT qui détermine les données qui sont copiées dans la nouvelle table. Pour plus d’informations sur les instructions SELECT, consultez SELECT (Transact-SQL).
Remarque
Dans Microsoft Fabric, l’utilisation de variables dans CTAS n’est pas autorisée.
Autorisations
CTAS exige une autorisation SELECT sur les objets référencés dans select_criteria.
Pour plus d’informations sur les autorisations permettant de créer une table, consultez Autorisations dans la rubrique CREATE TABLE.
Notes
Pour plus d’informations, consultez Remarques d’ordre général dans la rubrique CREATE TABLE.
Limitations et restrictions
SET ROWCOUNT (Transact-SQL) ne produit aucun effet sur CTAS. Pour obtenir un comportement similaire, utilisez TOP (Transact-SQL).
Pour plus d’informations, consultez Limitations et restrictions dans la rubrique CREATE TABLE.
Comportement du verrouillage
Pour plus d’informations, consultez Comportement de verrouillage dans la rubrique CREATE TABLE.
Exemples de copie d’une table
Pour en savoir plus sur l’utilisation de CTAS sur votre entrepôt dans Microsoft Fabric, reportez-vous à Ingérer des données dans votre entrepôt à l’aide de Transact-SQL.
A. Utiliser CTAS pour modifier des attributs de colonne
Cet exemple utilise CTAS pour modifier des types de données et la possibilité de valeur NULL pour plusieurs colonnes dans la table DimCustomer2.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Utiliser CTAS pour créer une table avec moins de colonnes
L’exemple suivant crée une table nommée myTable (c, ln). La nouvelle table contient seulement deux colonnes. Elle utilise les alias des colonnes dans l’instruction SELECT à la place des noms des colonnes.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Utiliser CTAS plutôt que SELECT..INTO
Le code SQL Server utilise généralement SELECT..INTO pour remplir une table avec les résultats d’une instruction SELECT. Voici un exemple d’instruction SQL Server SELECT..INTO.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
Cet exemple montre comment réécrire l’instruction SELECT..INTO précédente pour en faire une instruction CTAS.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. Utiliser CTAS pour simplifier les instructions merge
Les instructions merge peuvent être remplacées, du moins en partie, à l’aide de CTAS. Vous pouvez regrouper INSERT et UPDATE dans une même instruction. Les enregistrements supprimés doivent être fermés dans une deuxième instruction.
Un exemple de UPSERT est donné ci-dessous :
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour