Résoudre les problèmes de service de réplication de base de données dans Configuration Manager
Ce guide aide les administrateurs à diagnostiquer et à résoudre les problèmes du service de réplication de base de données (DRS) dans Configuration Manager.
Version d’origine du produit : Microsoft Endpoint Configuration Manager (Current Branch), Microsoft System Center 2012 R2 Configuration Manager, Microsoft System Center 2012 Configuration Manager
Numéro de la base de connaissances d’origine : 20033
Lorsque vous rencontrez un problème DRS dans Configuration Manager, la phase de début de l’enquête est le point le plus critique. Tout type de modification ou de correction ne doit être effectué qu’après une étude minutieuse et une compréhension du problème en cours.
Prise en main
Commencez par collecter des informations relatives à l’historique du problème. De nombreuses fois, les problèmes DRS peuvent finalement être retracés à une modification récente apportée dans l’environnement. N’oubliez pas que vous ne devez pas vous concentrer uniquement sur Configuration Manager, car les modifications apportées à Windows ou à SQL Server peuvent également entraîner des problèmes drs. Avoir une compréhension claire des changements récents dans l’environnement peut fournir des indices importants sur la source du problème.
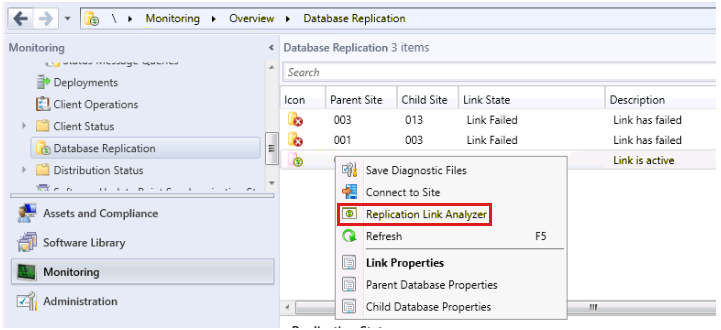
Une fois que vous avez examiné les modifications environnementales et que vous vous êtes assuré que vos mises à jour sont dans l’ordre, l’étape suivante consiste à exécuter le Analyseur de lien de réplication (RLA). Pour lancer RLA, ouvrez l’espace de travail Surveillance et sélectionnez le nœud Réplication de base de données, puis cliquez avec le bouton droit sur le lien qui rencontre un problème et sélectionnez Analyseur de lien de réplication, comme illustré dans l’exemple suivant :
Remarque
RLA s’exécute dans le contexte de celui qui le lance à partir de la console. Assurez-vous donc que le compte que vous utilisez dispose de privilèges d’administration sur les serveurs SQL Server et de site.
RLA case activée les éléments suivants sur les deux sites :
- Le service SMS est en cours d’exécution.
- Le composant Moniteur de configuration de la réplication SMS est en cours d’exécution.
- Les ports requis pour la réplication SQL Server sont activés.
- SQL Server version est prise en charge.
- Le réseau est disponible entre les deux sites.
- Il y a suffisamment d’espace pour la base de données SQL Server.
- SQL Server configuration du service Broker existe.
- SQL Server certificat de service Broker existe.
- Erreurs connues dans SQL Server fichiers journaux.
- Indique si les files d’attente de réplication sont désactivées.
- L’heure est synchronisée.
- La transmission des données est-elle bloquée ?
- Existe-t-il un conflit de clé ?
Si la sécurité au niveau des lignes détecte des problèmes connus, elle vous propose de les résoudre pour vous. Le rapport de sortie RLA est également simple. Il vous indique ce qu’il a vérifié et quelles règles ont été exécutées en plus de savoir si elles ont réussi ou échoué. Voici un exemple :

Obtenir des détails avec SPDiagDRS
Si Analyseur de lien de réplication ne parvenez pas à détecter et à résoudre le problème, exécutez SPDiagDRS et vérifiez s’il peut fournir des indices sur ce qui peut échouer.
Pour exécuter SPDiagDRS, ouvrez SQL Server Management Studio et connectez-vous aux deux serveurs de chaque côté du lien présentant le problème. Sur chaque base de données CM_xxx , exécutez la Exec SPDiagDRS commande .
Voici une répartition des différentes SPDiagDRS sections et quelques endroits courants pour rechercher les problèmes. Une simple recherche de messages d’erreur et de codes trouvés ici vous guide souvent vers la source du problème.

Section 1
SiteStatus : cela nous indique si le site est en cours de réplication ou non. Rien d’autre qu’ACTIVE n’est bon.
CertificateThumbprint : empreinte numérique du certificat utilisé pour l’authentification qui contient la clé publique du site (la base de données locale approuve la base de données distante).

Section 2
IncomingMessageInQueue : indique le backlog entrant d’un site. Si le backlog est élevé en raison du nombre de sites qui lui rendent compte, vous pouvez voir les liens passer à un état détérioré ou en échec, car les synchronisations de pulsations ne sont pas traitées dans le temps.
OutgoingMessageInQueue : indique le backlog qui n’a pas encore été effacé, car nous attendons que les sites reçoivent les messages. Cela fluctue généralement, mais s’il continue de croître, cela peut représenter un problème. Un dépannage supplémentaire doit être effectué pour déterminer quel site n’obtient pas les messages.

Section 3
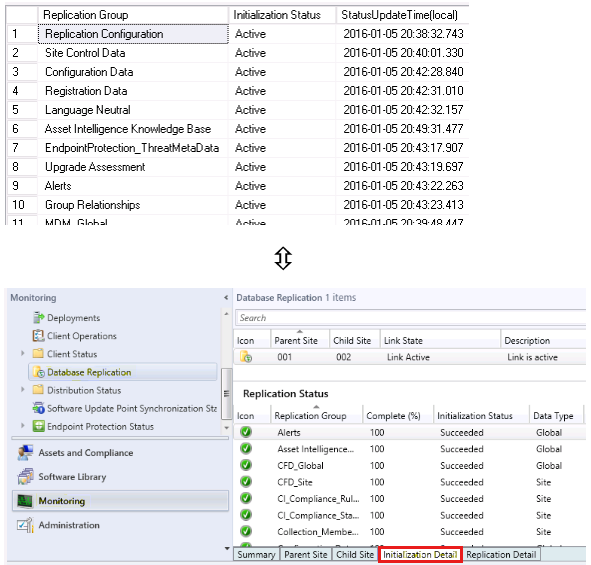
Il s’agit simplement de l’affichage détaillé du détail d’initialisation dans la console.
Section 4
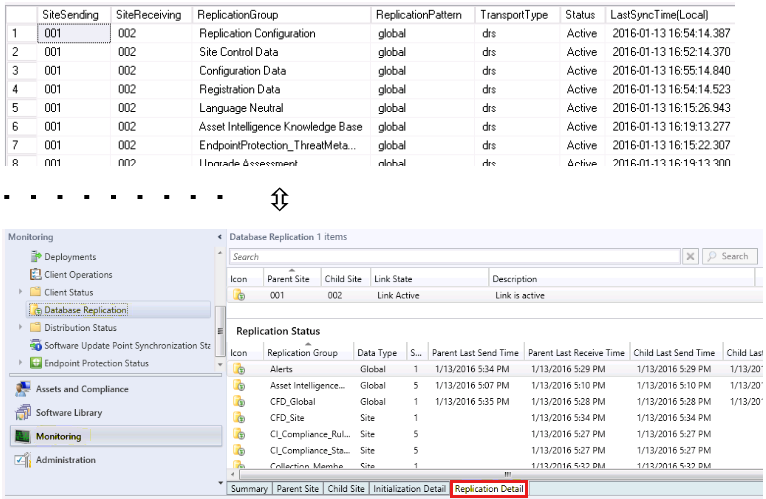
Il s’agit de la vue détaillée des détails de la réplication dans la console. Il fournit plus d’informations sur le flux entre chaque groupe de réplication.
Section 5
Cette section contient des informations importantes et utiles sur les sites auxquels nous nous connectons. Dans cet exemple, nous sommes sur le serveur de site principal 002 et 001 est le site d’administration centrale. Si nous avions un site secondaire sous 002, il serait affiché ici. Sur un site d’administration centrale, tous les sites principaux seraient pris en compte, mais pas les sites secondaires.
Exemple de site principal 002 :

Exemple de site d’administration centrale 001 :

Section 6
Cela fournit des informations générales sur les sites dans la hiérarchie, les SiteServerName noms et DBServer , ainsi que les status et la version. Vous pouvez voir ici qu’un autre site principal (003) s’affiche comme étant en mode maintenance. Sur les systèmes en fonctionnement, la section 6 doit être identique entre le site d’administration centrale et tous les sites principaux de la hiérarchie.

Section 7
Les deux sections du bas contiennent des informations détaillées sur la pulsation ou LastSentStatus pour chaque groupe, ainsi que conversationIDs sur les options de réplication intégrées configurées pour chaque groupe.
Rechercher RCMCtrl.log erreurs
Ensuite, vous voudrez case activée RCMCtrl.log sur chaque site pour les erreurs, car cela fournira souvent des indices précieux concernant la source du problème. Par exemple, vous pouvez constater que la réplication est dans un état Échec pour un site et que la réplication n’a pas eu lieu depuis un certain temps. Dans ce scénario, vous pouvez constater que RCMCtrl.log contient des entrées similaires à ce qui suit :
4/07/2016 1 :25 :36 PM : ReplicationLinkAnalysis Information : 1 : Thread d’analyse de lien de réplication terminé.
4/07/2016 1 :25 :37 PM : Erreur ReplicationLinkAnalysis : 1 : Impossible de trouver SiteCode ou SiteNumber
4/7/2016 1 :25 :37 PM : Erreur ReplicationLinkAnalysis : 1 : Microsoft.ConfigurationManager.ManagedBase.LocalServerDataNotFoundException : Impossible de trouver SiteCode ou SiteNumber
sur Microsoft.ConfigurationManager.ManagedBase.SiteData.Refresh()
sur Microsoft.ConfigurationManager.ReplicationLinkAnalyzer.ReplicationLinkAnalysisEngine.Initialize()
sur Microsoft.ConfigurationManager.ReplicationLinkAnalyzer.ReplicationLinkAnalysisEngine.RunRulesInBackground(Object sender, DoWorkEventArgs e)
sur System.ComponentModel.BackgroundWorker.WorkerThreadStart(Object argument)
Si vous voyez des entrées similaires à celles-ci, assurez-vous que les services SMS Executive et Gestionnaire de composant de site sont en cours d’exécution sur le site en question. Si ce n’est pas le cas, c’est peut-être la raison pour laquelle la réplication est dans un état Échec . S’il n’est pas en cours d’exécution, démarrez les services SMS Executive et/ou Gestionnaire de composant de site manuellement et résolvez les problèmes de démarrage des services s’ils ne parviennent pas à démarrer.
Voici un autre exemple d’erreur que vous pouvez trouver dans RCMCtrl.log :
04/07/2016 12 :33 :34 PM 6352 (0x18D0)CSqlBCP ::ReadRowCount : Can’t open file [F :\Program Files\Microsoft Configuration Manager\inboxes\rcm.box\GUID\INSTALLED_EXECUTABLE_DATA.bcp.rowcount]. SMS_REPLICATION_CONFIGURATION_MONITOR
04/07/2016 12 :33 :34 PM 6352 (0x18D0) CSqlBCP ::D RS_Init_BCPIN : ReadRowCount a échoué. SMS_REPLICATION_CONFIGURATION_MONITOR
04/07/2016 12 :33 :34 PM 6352 (0x18D0)*** DRS_Init_BCPIN() a échoué SMS_REPLICATION_CONFIGURATION_MONITOR
04/07/2016 12 :33 :34 PM 6352 (0x18D0) CBulkInsert ::D RS_Init_BCPIN : Échec du BCP dans SMS_REPLICATION_CONFIGURATION_MONITOR
04/07/2016 12 :33 :34 PM 6352 (0x18D0) BCP dans le résultat est 2147500037. SMS_REPLICATION_CONFIGURATION_MONITOR
04/07/2016 12 :33 :34 PM 6352 (0x18D0) ERREUR : Échec de l’entrée BCP dans pour la table INSTALLED_EXECUTABLE_DATA avec le code d’erreur 2147500037. SMS_REPLICATION_CONFIGURATION_MONITOR
04/07/2016 12 :33 :34 PM 6352 (0x18D0) ERREUR : Échec de l’application de BCP pour tous les articles de la publication Hardware_Inventory_7. SMS_REPLICATION_CONFIGURATION_MONITOR
04/07/2016 12 :33 :34 PM 6352 (0x18D0) Tente de nouveau d’appliquer les fichiers BCP lors de la prochaine exécution.
Ce qui se passe ici, c’est que si le fichier .CAB envoyé à partir du parent a été décompressé par le dépooleur, l’espace sur le lecteur était épuisé, de sorte qu’il n’a pu décompresser que certains fichiers. Si vous affichez despool.log, il y aura une défaillance 2147024784 qui fait référence à un espace disque insuffisant. Pour résoudre ce type de problème, libérez de l’espace disque sur le lecteur.
Rechercher les problèmes BCP
Si vous n’avez toujours pas trouvé la source du problème, il se peut que le processus de réplication ait été interrompu parce que le programme de copie en bloc (BCP) était trop lent.
L’expéditeur est-il limité à ce site et peut-être cela ralentit-il le transfert BCP ?
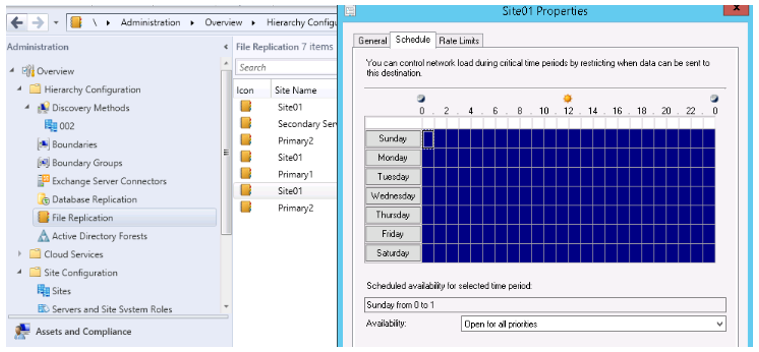
Pour vérifier, ouvrez la console et accédez àVued’ensemble> de l’administration> Réplication du fichier deconfiguration> de la hiérarchie, puis cliquez avec le bouton droit sur le site qui enverrait les données. Vérifiez que la disponibilité de la planification est définie sur Ouvrir pour toutes les priorités et que les limites de débit sont définies sur Illimité pour ce site.
Si tout fonctionne, mais que le jeu de données du processus BCP est volumineux et que l’envoi prend beaucoup de temps, vous pouvez augmenter le nombre de threads de l’expéditeur pour accélérer les choses. Les valeurs par défaut sont répertoriées ci-dessous. Si votre journal de l’expéditeur recommande systématiquement de ne plus disposer de threads ou d’utilisation de 5 ou 5 ou d’utilisation de 3 sur 3, cela indique que vous souhaiterez peut-être augmenter les threads de l’expéditeur.
Remarque
En cas d’augmentation, le paramètre prend effet en temps réel sans redémarrage de quoi que ce soit.
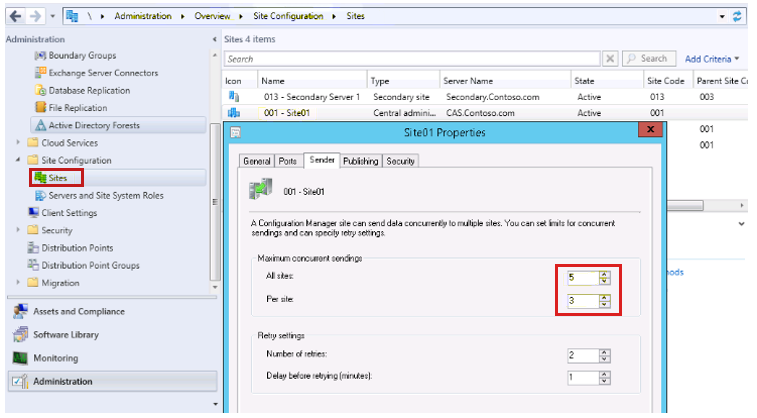
En outre, si vous avez une limite de débit définie sur Limitée aux taux de transfert maximum spécifiés par heure (comme indiqué ci-dessous), Configuration Manager n’utilisera qu’un seul thread d’expéditeur à la fois lors du transfert vers ce site, quel que soit le nombre de threads d’expéditeurs définis. Le paramètre par défaut Illimité lors de l’envoi à cette destination utilise tous les threads d’expéditeur configurés.

Plus d’informations
Pour plus d’informations sur drs, consultez les articles suivants :
- Initialisation DRS en Configuration Manager 2012
- Planification des communications dans Configuration Manage
- Réplication de base de données
Vous pouvez également publier une question dans notre forum de support Configuration Manager.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour