Nouveautés de la déduplication des données
S’applique à : Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI versions 21H2 et 20H2
La déduplication des données dans Windows Server a été optimisée pour être hautement performante, flexible et facile à gérer à l’échelle du cloud privé. Pour en savoir plus sur la pile de stockage à définition logicielle dans Windows Server, voir Nouveautés du stockage dans Windows Server.
Windows Server 2022
La déduplication des données n’a pas d’améliorations supplémentaires dans Windows Server 2022.
Windows Server 2019
La déduplication des données présente les améliorations suivantes dans Windows Server 2019 :
| Fonctionnalités | Nouveauté ou mise à jour | Description |
|---|---|---|
| Prise en charge de ReFS | Nouveau | Stockez jusqu’à 10 fois plus de données supplémentaires sur le même volume avec la déduplication et la compression pour le système de fichiers ReFS. (activez Windows Admin Center en un clic.) Le magasin de blocs de taille variable avec compression facultative optimise les taux d’économies, tandis que l’architecture après traitement multithread conserve un impact minimal sur les performances. La déduplication prend en charge des volumes allant jusqu’à 64 téraoctets (To) et déduplique les 4 premiers To de chaque fichier. |
Windows Server 2016
La déduplication des données présente les améliorations suivantes à partir de Windows Server 2016 :
| Fonctionnalités | Nouveauté ou mise à jour | Description |
|---|---|---|
| Prise en charge de volumes importants | Mis à jour | Avant Windows Server 2016, les volumes devaient être dimensionnés de façon spécifique pour l’activité attendue, avec des tailles de volume supérieures à 10 To qui ne convenaient pas à la déduplication. Dans Windows Server 2016, la déduplication des données prend en charge des tailles de volume pouvant atteindre 64 To. |
| Prise en charge de fichiers volumineux) | Mis à jour | Avant Windows Server 2016, les fichiers dont la taille était proche de 1 To ne convenaient pas à la déduplication. Dans Windows Server 2016, les fichiers dont la taille peut atteindre jusqu’à 1 To sont entièrement pris en charge. |
| Prise en charge de Nano Server | Nouveau | La déduplication des données est disponible et entièrement prise en charge dans la nouvelle option de déploiement de Nano Server pour Windows Server 2016. |
| Prise en charge de sauvegarde simplifiée | Nouveau | Windows Server 2012 R2 prenait en charge les applications de sauvegarde virtualisées, telles que Data Protection Manager de Microsoft, via une série d’étapes de configuration manuelles. Dans Windows Server 2016, un nouveau type d’utilisation par défaut (Sauvegarde) a été ajouté pour un déploiement transparent de la déduplication des données pour les applications de sauvegarde virtualisées. |
| Prise en charge de la mise à niveau propagée de système d’exploitation de cluster | Nouveau | La déduplication des données prend entièrement en charge la nouvelle fonctionnalité de mise à niveau propagée de système d’exploitation de cluster de Windows Server 2016. |
Prise en charge de volumes importants
Quels avantages cette modification procure-t-elle ?
Afin d’obtenir des performances optimales de la déduplication des données dans Windows Server 2012 R2, vous devez dimensionner les volumes correctement pour garantir que la tâche d’optimisation peut suivre le taux de modification des données, ou évolution. En règle générale, cela signifie que la déduplication des données est performante uniquement sur les volumes de 10 To au maximum, en fonction des modèles d’écriture de la charge de travail.
À partir de Windows Server 2016, la déduplication des données est hautement performante sur des volumes pouvant atteindre 64 To.
En quoi le fonctionnement est-il différent ?
Dans Windows Server 2012 R2, le pipeline du travail de déduplication des données utilise un seul thread et la file d’attente d’E/S pour chaque volume. Pour garantir que les tâches d’optimisation ne prennent pas de retard, ce qui entraînerait une diminution du cumul des gains du volume, les jeux de données volumineux doivent être divisés en volumes plus petits. La taille de volume appropriée dépend de l’évolution attendue pour ce volume. En moyenne, la valeur maximale est incluse entre 6 et 7 To pour les volumes dont l’évolution est élevée, et entre 9 et 10 To pour les volumes dont l’évolution est faible.
À partir de Windows Server 2016, le pipeline de la tâche de déduplication de données a été repensé pour exécuter plusieurs threads en parallèle en utilisant plusieurs files d’attente d’E/S pour chaque volume. Cela permet des performances qui étaient auparavant impossibles à obtenir, grâce à la répartition des données en plusieurs volumes de taille inférieure. Cette modification est représentée dans l’illustration suivante :
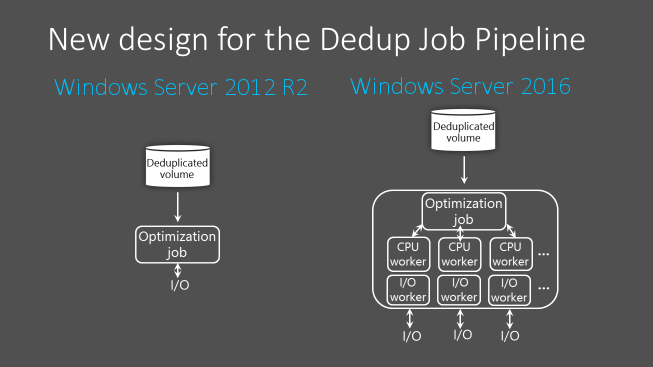
Ces optimisations s’appliquent à tous les travaux de déduplication des données, et non uniquement au travail d’optimisation.
Prise en charge des fichiers volumineux
Quels avantages cette modification procure-t-elle ?
Dans Windows Server 2012 R2, les fichiers très volumineux ne sont pas adaptés à la déduplication des données en raison d’une diminution des performances du pipeline de traitement de la déduplication. Dans Windows Server 2016, la déduplication de fichiers dont la taille peut atteindre 1 To est très performante, permettant aux administrateurs d’appliquer des gains de déduplication à un plus grand nombre de charges de travail. Vous pouvez par exemple dédupliquer des fichiers très volumineux normalement associés aux charges de travail de sauvegarde.
En quoi le fonctionnement est-il différent ?
À partir de Windows Server 2016, la déduplication des données utilise de nouvelles structures de mappage de flux et d’autres améliorations d’implémentation pour augmenter les performances de débit et d’accès de l’optimisation. En outre, le pipeline de traitement de la déduplication peut maintenant reprendre le cours de l’optimisation près un basculement, au lieu de redémarrer. Grâce à ces modifications, la déduplication de fichiers pouvant atteindre 1 To est hautement performante.
Prise en charge de Nano Server
Quels avantages cette modification procure-t-elle ?
Nano Server est une nouvelle option de déploiement sans affichage dans Windows Server 2016, qui présente un encombrement des ressources système très faible, démarre beaucoup plus rapidement et nécessite moins de mises à jour et de redémarrages que l’option de déploiement de Windows Server principal. La déduplication des données est entièrement prise en charge sur Nano Server. Pour plus d’informations sur Nano Server, voir Prise en main de Nano Server.
Configuration simplifiée pour les applications de sauvegarde virtualisées
Quels avantages cette modification procure-t-elle ?
La déduplication des données pour les applications de sauvegarde virtualisées est un scénario pris en charge dans Windows Server 2012 R2, mais il est nécessaire de régler manuellement les paramètres de la déduplication. À partir de Windows Server 2016, la configuration de la déduplication pour les applications de sauvegarde virtualisées est considérablement simplifiée. Cette fonctionnalité utilise une option de type d’utilisation prédéfinie lors de l’activation de la déduplication pour un volume, tout comme les options proposées pour le serveur de fichiers à usage général et l’infrastructure VDI.
Prise en charge de la mise à niveau propagée de système d’exploitation de cluster
Quels avantages cette modification procure-t-elle ?
Les clusters de basculement Windows Server exécutant la déduplication des données peuvent comporter un mélange de nœuds exécutant des versions de Windows Server 2012 R2 et de Windows Server 2016 de la déduplication. Cette amélioration fournit un accès complet aux données à tous les volumes dédupliqués pendant une mise à niveau propagée de cluster, permettant le lancement progressif de la nouvelle version de la déduplication sur un cluster Windows Server 2012 R2 existant sans entraîner de temps d’arrêt pour la mise à niveau de tous les nœuds à la fois.
En quoi le fonctionnement est-il différent ?
Dans les versions précédentes de Windows Server, tous les nœuds du cluster devaient exécuter la même version de Windows Server pour qu’un cluster de basculement Windows Server fonctionne. Depuis Windows Server 2016, la fonctionnalité de mise à niveau propagée de cluster permet à un cluster de s’exécuter en mode mixte. La déduplication prend en charge cette nouvelle configuration de cluster en mode mixte pour activer l’accès complet aux données lors d’une mise à niveau propagée de cluster.