Közösségi használat az Azure Cosmos DB-vel
A KÖVETKEZŐKRE VONATKOZIK: ![]() Nosql
Nosql ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Táblázat
Táblázat
A nagymértékben összekapcsolt társadalomban való élet azt jelenti, hogy az élet egy bizonyos pontján egy közösségi hálózat részévé válik. Közösségi hálózatokkal tarthatja a kapcsolatot barátaival, munkatársaival, családtagjaival, vagy néha megoszthatja szenvedélyét a közös érdeklődésű emberekkel.
Mérnökökként vagy fejlesztőkként felmerülhetett a kérdés, hogy ezek a hálózatok hogyan tárolják és kapcsolják össze az adatokat. Vagy akár arra is megbízták, hogy hozzon létre vagy építsen ki egy új közösségi hálózatot egy adott piaci réshez. Ekkor merül fel a fontos kérdés: Hogyan tárolják ezeket az adatokat?
Tegyük fel, hogy egy új és fényes közösségi hálózatot hoz létre, ahol a felhasználók közzétehetnek cikkeket kapcsolódó médiatartalmakkal, például képekkel, videókkal vagy akár zenékkel. A felhasználók megjegyzéseket fűzhetnek a bejegyzésekhez, és pontokat adhatnak az értékelésekhez. A felhasználók a fő webhely kezdőlapján láthatják és kezelhetik a bejegyzéseket. Ez a módszer elsőre nem hangzik összetettnek, de az egyszerűség kedvéért álljunk meg. (Belevághat a kapcsolatok által érintett egyéni felhasználói hírcsatornákba, de ez túlmutat a cikk célján.)
Hogyan tárolhatja ezeket az adatokat, és hol?
Előfordulhat, hogy rendelkezik tapasztalatokkal az SQL-adatbázisokban, vagy rendelkezik az adatok relációs modellezésének fogalmával. Az alábbiak szerint kezdhet rajzolni:

Tökéletesen normalizált és szép adatstruktúra... ez nem skálázható.
Ne érts félre, egész életemben SQL-adatbázisokkal dolgoztam. Nagyszerűek, de mint minden minta, gyakorlat és szoftverplatform, ez sem tökéletes minden forgatókönyvhöz.
Miért nem az SQL a legjobb választás ebben a forgatókönyvben? Nézzük meg egy bejegyzés struktúráját. Ha meg szeretném jeleníteni a bejegyzést egy webhelyen vagy alkalmazásban, le kell kérdeznem... 8 tábla(!) összekapcsolásával csak egyetlen bejegyzést jeleníthet meg. Most képzeljen el egy olyan bejegyzésfolyamot, amely dinamikusan betöltődik és megjelenik a képernyőn, és láthatja, hogy hová megyek.
Egy hatalmas SQL-példányt elég erővel használhat, hogy több ezer lekérdezést oldjon meg számos illesztéssel a tartalom kiszolgálásához. De miért lenne, ha létezik egyszerűbb megoldás?
A NoSQL út
Ez a cikk bemutatja, hogy költséghatékonyan modellezheti a közösségi platform adatait az Azure NoSQL-adatbázissal , az Azure Cosmos DB-vel . Azt is ismerteti, hogyan használhat más Azure Cosmos DB-funkciókat, például a Gremlin API-t. A NoSQL-megközelítéssel, az adatok tárolásával, JSON formátumban és denormalizálás alkalmazásával a korábban bonyolult bejegyzés egyetlen dokumentummá alakítható:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
Egyetlen lekérdezéssel és illesztés nélkül is be lehet hajtható. Ez a lekérdezés sokkal egyszerű és egyszerű, és költségvetés szempontjából kevesebb erőforrást igényel a jobb eredmény eléréséhez.
Az Azure Cosmos DB gondoskodik arról, hogy az összes tulajdonság indexelve legyen az automatikus indexeléssel. Az automatikus indexelés testre is szabható. A sémamentes megközelítés lehetővé teszi a különböző és dinamikus struktúrákkal rendelkező dokumentumok tárolását. Talán holnap azt szeretné, hogy a bejegyzésekhez kategóriák vagy hashtagek legyenek társítva? Az Azure Cosmos DB az új dokumentumokat a hozzáadott attribútumokkal fogja kezelni anélkül, hogy az általunk igényelt többletmunkát végeznánk.
A bejegyzéshez fűzött megjegyzések más, szülőtulajdonságú bejegyzésként is kezelhetők. (Ez a gyakorlat leegyszerűsíti az objektumleképezést.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
A társas interakciók pedig egy külön objektumon tárolhatók számlálóként:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
A hírcsatornák létrehozása csak olyan dokumentumok létrehozásán múlik, amelyek egy adott relevanciájú sorrendben tárolhatják a bejegyzésazonosítók listáját:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Lehet egy "legújabb" stream, amelynek bejegyzéseit a létrehozás dátuma szerint rendezi. Vagy lehet egy "legforróbb" stream azokkal a bejegyzésekkel, amelyek több kedveléssel rendelkeznek az elmúlt 24 órában. Akár egyéni streamet is implementálhat minden felhasználóhoz olyan logika alapján, mint a követők és az érdeklődési körök. Még mindig a bejegyzések listája lenne. A listák készítésének módjáról van szó, de az olvasási teljesítmény akadálytalan marad. Miután beszerezte az egyik ilyen listát, egyetlen lekérdezést ad ki az Azure Cosmos DB-nek az IN kulcsszó használatával, hogy egyszerre több bejegyzést is lekérjen.
A hírcsatorna-adatfolyamok a Azure-alkalmazás Services háttérfolyamatai, a Webjobs használatával hozhatók létre. A bejegyzés létrehozása után a háttérfeldolgozás az Azure Storage-üzenetsorok és az Azure Webjobs SDK-val aktivált webjobsok használatával aktiválható, és a bejegyzés propagálását saját egyéni logikája alapján implementálhatja streameken belül.
A pontok és kedvelések egy bejegyzésen keresztül késleltetett módon dolgozhatók fel ugyanazzal a technikával, hogy végül konzisztens környezetet hozzanak létre.
A követők trükkösek. Az Azure Cosmos DB-nek van egy dokumentumméretkorlátja, és a nagyméretű dokumentumok olvasása/írása hatással lehet az alkalmazás méretezhetőségére. Ezért a követők tárolására az alábbi struktúrával rendelkező dokumentumként gondolhat:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Ez a struktúra néhány ezer követővel rendelkező felhasználó számára működhet. Ha azonban egyes hírességek csatlakoznak a rangokhoz, ez a megközelítés nagy méretű dokumentumhoz vezet, és végül eléri a dokumentumméret korlátját.
A probléma megoldásához vegyes megközelítést használhat. A Felhasználói statisztikák dokumentum részeként tárolhatja a követők számát:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
A követők tényleges grafikonját az Azure Cosmos DB API for Gremlin használatával tárolhatja, hogy csúcsokat hozzon létre minden felhasználóhoz és élhez, amelyek fenntartják az "A-follows-B" kapcsolatokat. A Gremlin API-val lekérheti egy adott felhasználó követőinek a követőit, és összetettebb lekérdezéseket hozhat létre, hogy közös felhasználókat javasoljon. Ha hozzáadja a diagramhoz azokat a tartalomkategóriákat, amelyeket az emberek kedvelnek vagy élveznek, elkezdhet olyan szolgáltatásokat szőni, amelyek magukban foglalják az intelligens tartalomfelderítést, a követett személyek által követett tartalmakra vonatkozó javaslatot, vagy olyan személyeket keresnek, akikkel sok közös lehet.
A Felhasználói statisztikák dokumentum továbbra is használható kártyák létrehozására a felhasználói felületen vagy a gyorsprofil-előnézetekben.
A "Létra" minta és az adatok duplikálása
Ahogy azt a bejegyzésre hivatkozó JSON-dokumentumban is észrevette, a felhasználónak sok előfordulása van. És helyesen gondolta volna, hogy ezek a duplikációk azt jelentik, hogy a felhasználót leíró információk, tekintettel erre a denormalizálásra, több helyen is jelen lehetnek.
A gyorsabb lekérdezések érdekében adat-duplikációt kell eredményeznie. Ezzel a mellékhatással az a probléma, hogy ha egy felhasználó adatai valamilyen művelettel megváltoznak, meg kell találnia a felhasználó által végzett összes tevékenységet, és frissítenie kell őket. Nem hangzik praktikusnak, ugye?
Ezt úgy fogja megoldani, hogy azonosítja az alkalmazásában az egyes tevékenységekhez megjelenített felhasználó kulcsattribútumait. Ha vizuálisan megjelenít egy bejegyzést az alkalmazásban, és csak az alkotó nevét és képét jeleníti meg, miért tárolja a felhasználó összes adatát a "createdBy" attribútumban? Ha minden megjegyzéshez csak a felhasználó képét jeleníti meg, akkor nincs igazán szüksége a felhasználó többi információjára. Ebben vesz részt valami, amit "Létramintának" nevezek.
Vegyük példaként a felhasználói adatokat:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Ezen információk alapján gyorsan felismerheti, hogy melyik a kritikus információ, és melyik nem, így létrehoz egy "Létrát":

A legkisebb lépést UserChunk-nak nevezzük, amely a felhasználót azonosító és az adatok duplikálásához használt minimális információ. Ha a duplikált adatméretet csak a "megjelenítendő" adatokra csökkenti, csökkentheti a tömeges frissítések lehetőségét.
A középső lépés neve felhasználó. Ez a teljes adat, amelyet a legtöbb teljesítményfüggő lekérdezéshez használunk az Azure Cosmos DB-ben, amely a leginkább elérhető és kritikus. Tartalmazza a UserChunk által képviselt információkat.
A legnagyobb a kiterjesztett felhasználó. Tartalmazza a kritikus felhasználói adatokat és az egyéb adatokat, amelyeket nem kell gyorsan olvasni, vagy amelyek végső használatban vannak, például a bejelentkezési folyamat. Ezek az adatok az Azure Cosmos DB-n kívül, az Azure SQL Database-ben vagy az Azure Storage-táblákban tárolhatók.
Miért osztaná fel a felhasználót, és miért tárolná ezeket az információkat különböző helyeken? Mivel teljesítmény szempontjából minél nagyobb a dokumentumok száma, annál költségesebbek a lekérdezések. A dokumentumok karcsúak maradnak, és a megfelelő információk birtokában elvégezheti a közösségi hálózat teljesítményfüggő lekérdezéseit. Tárolja a többi további információt a végleges forgatókönyvekhez, például a teljes profil-módosításokhoz, a bejelentkezésekhez és az adatbányászathoz a használati elemzésekhez és a Big Data-kezdeményezésekhez. Nem igazán érdekli, hogy az adatbányászati adatgyűjtés lassabb-e, mert az Azure SQL Database-en fut. Aggodalomra ad okot, hogy a felhasználók gyors és vékony felhasználói élményt élveznek. Az Azure Cosmos DB-ben tárolt felhasználók a következő kódhoz hasonlóan néznek ki:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
És egy Post nézne ki:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Ha olyan szerkesztés történik, amely egy adattömb attribútumot érint, könnyen megtalálhatja az érintett dokumentumokat. Csak olyan lekérdezéseket használjon, amelyek az indexelt attribútumokra mutatnak, például SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", majd frissítse az adattömböket.
A keresőmező
A felhasználók szerencsére sok tartalmat hoznak létre. És képesnek kell lennie arra, hogy olyan tartalmakat keressen és keressen, amelyek esetleg nem közvetlenül a tartalomstreamekben találhatók, talán azért, mert nem követi az alkotókat, vagy talán csak azt a régi bejegyzést próbálja megtalálni, amelyet hat hónappal ezelőtt tett.
Mivel az Azure Cosmos DB-t használja, néhány perc alatt egyszerűen implementálhat egy keresőmotort az Azure AI Search használatával anélkül, hogy a keresési folyamaton és a felhasználói felületen kívül bármilyen kódot beírná.
Miért ilyen egyszerű ez a folyamat?
Az Azure AI Search megvalósítja az indexelőknek nevezett háttérfolyamatokat, amelyek összekapcsolják az adattárakat, és automatikusan hozzáadják, frissítik vagy eltávolítják az indexekben lévő objektumokat. Támogatják az Azure SQL Database-indexelőket, az Azure Blobs-indexelőket és szerencsére az Azure Cosmos DB-indexelőket. Az azure Cosmos DB-ről az Azure AI Searchre való áttérés egyszerű. Mindkét technológia JSON formátumban tárolja az információkat, ezért csak létre kell hoznia az indexet, és le kell képeznie az indexelt dokumentumok attribútumait. Ennyi az egész! Az adatok méretétől függően a felhőinfrastruktúra legjobb keresési szolgáltatása perceken belül elérhető lesz az összes tartalom kereséséhez.
Az Azure AI Search szolgáltatással kapcsolatos további információkért tekintse meg a Hitchhiker keresési útmutatóját.
A mögöttes tudás
A napról napra bővülő tartalom tárolása után felmerülhet a gondolat: Mit tehetek a felhasználóimtól származó összes információfolyammal?
A válasz egyszerű: Tegye a munkát, és tanuljon belőle.
De mit tanulhatsz? Néhány egyszerű példa például a hangulatelemzés, a felhasználói beállításokon alapuló tartalomjavaslatok vagy akár egy automatizált con sátormód rator, amely gondoskodik arról, hogy a közösségi hálózat által közzétett tartalom biztonságos legyen a család számára.
Most, hogy bekötöttem, valószínűleg azt fogja hinni, hogy szüksége van néhány phD-ra a matematikai tudományban, hogy kinyerje ezeket a mintákat és információkat egyszerű adatbázisokból és fájlokból, de tévednél.
Az Azure Machine Tanulás egy teljes mértékben felügyelt felhőszolgáltatás, amely lehetővé teszi munkafolyamatok létrehozását algoritmusok használatával egy egyszerű húzási felületen, saját algoritmusok kódolását az R-ben, vagy használhatja a már beépített és használatra kész API-kat, például: Text Analytics, Content Moderator vagy Javaslatok.
Ezen gépi Tanulás forgatókönyvek bármelyikének eléréséhez használhatja az Azure Data Lake-t a különböző forrásokból származó információk betöltéséhez. Az U-SQL használatával is feldolgozhatja az adatokat, és létrehozhat egy kimenetet, amelyet az Azure Machine Tanulás képes feldolgozni.
Egy másik elérhető lehetőség az Azure AI-szolgáltatások használata a felhasználói tartalmak elemzéséhez; nem csak jobban megértheti őket (a Text Analytics API-val írt tartalmak elemzésével), de a nemkívánatos vagy érett tartalmakat is észlelheti, és ennek megfelelően működhet a Computer Vision API-val. Az Azure AI-szolgáltatások számos beépített megoldást tartalmaznak, amelyek nem igényelnek semmilyen gépi Tanulás ismeretet.
Bolygószintű közösségi élmény
Van egy utolsó, de nem utolsósorban fontos cikk, a skálázhatóságot kell kezelnem. Az architektúra tervezésekor minden összetevőnek önállóan kell méreteznie. Végül több adatot kell feldolgoznia, vagy nagyobb földrajzi lefedettségre lesz szüksége. Szerencsére mindkét feladat elérése kulcsrakész élmény az Azure Cosmos DB-vel.
Az Azure Cosmos DB támogatja a beépített dinamikus particionálást. Automatikusan létrehoz partíciókat egy adott partíciókulcs alapján, amely attribútumként van definiálva a dokumentumokban. A megfelelő partíciókulcsot a tervezéskor kell meghatározni. További információ: Particionálás az Azure Cosmos DB-ben.
Közösségi élmény esetén a particionálási stratégiát a lekérdezési és írási módhoz kell igazítania. (Például az ugyanazon a partíción belüli olvasások kívánatosak, és kerülje a "gyakori pontokat", ha írásokat terjeszt több partícióra.) Néhány lehetőség a következők: temporális kulcson alapuló partíciók (nap/hónap/hét), tartalomkategória, földrajzi régió vagy felhasználó szerint. Minden attól függ, hogyan fogja lekérdezni az adatokat, és hogyan jeleníti meg az adatokat a közösségi élményben.
Az Azure Cosmos DB transzparensen futtatja a lekérdezéseket (beleértve az összesítéseket is) az összes partíción, így az adatok növekedésével nem kell semmilyen logikát hozzáadnia.
Idővel idővel növekedni fog a forgalom, és az erőforrás-felhasználás (kérelemegységekben vagy kérelemegységekben mérve) növekedni fog. A felhasználói bázis növekedésével egyre gyakrabban fog olvasni és írni. A felhasználói bázis elkezd további tartalmakat létrehozni és olvasni. Ezért az átviteli sebesség skálázásának képessége létfontosságú. A kérelemegységek növelése egyszerű. Ezt néhány kattintással megteheti az Azure Portalon, vagy parancsokat bocsáthat ki az API-n keresztül.
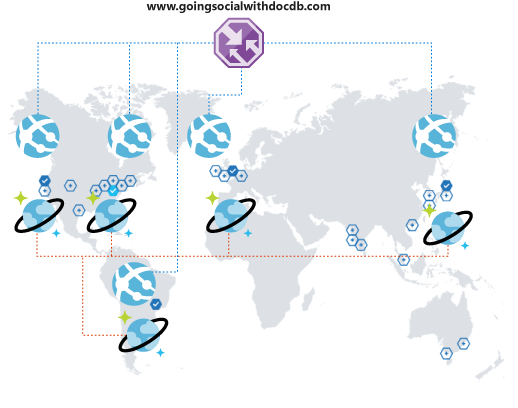
Mi történik, ha a dolgok egyre jobbak lesznek? Tegyük fel, hogy egy másik országból vagy régióból vagy kontinensről származó felhasználók észlelik a platformot, és elkezdik használni. Micsoda meglepetés!
De várjon! Hamarosan rájön, hogy a platformmal kapcsolatos tapasztalataik nem optimálisak. Annyira távol vannak a működési régiótól, hogy a késés szörnyű. Nyilvánvalóan nem akarod, hogy kilépjenek. Ha csak egy egyszerű módja volt annak, hogy kiterjesztse a globális elérés? Van!
Az Azure Cosmos DB lehetővé teszi az adatok globális és transzparens replikálását néhány kattintással, és automatikusan kiválaszthat az ügyfélkód elérhető régiói közül. Ez a folyamat azt is jelenti, hogy több feladatátvételi régióval is rendelkezhet.
Ha globálisan replikálja az adatokat, gondoskodnia kell arról, hogy az ügyfelek kihasználhassák azokat. Ha webes előtérrendszert használ, vagy mobilügyfelektől származó API-kat használ, üzembe helyezheti az Azure Traffic Managert, és klónozhatja a Azure-alkalmazás-szolgáltatást az összes kívánt régióban, egy teljesítménykonfiguráció használatával, amely támogatja a kiterjesztett globális lefedettséget. Amikor az ügyfelek hozzáférnek az előtér- vagy API-khoz, a rendszer átirányítja őket a legközelebbi App Service-hez, amely viszont csatlakozik a helyi Azure Cosmos DB-replikához.
Összefoglalás
Ez a cikk bemutatja, hogyan hozhat létre teljesen közösségi hálózatokat az Azure-ban alacsony költségű szolgáltatásokkal. a "Létra" nevű többrétegű tárolási megoldás és adatterjesztés használatának ösztönzésével biztosítja az eredményeket.
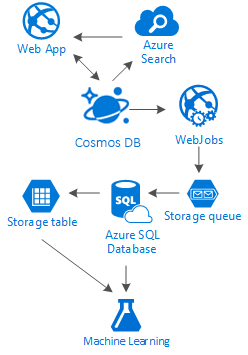
Az igazság az, hogy ilyen helyzetekben nincs ezüstjel. Ez a nagyszerű szolgáltatások kombinációja által létrehozott szinergia, amely lehetővé teszi számunkra, hogy nagyszerű élményeket építsünk ki: az Azure Cosmos DB sebességét és szabadságát, hogy nagyszerű közösségi alkalmazást biztosítsunk, az első osztályú keresési megoldás, például az Azure AI Search mögötti intelligencia, a Azure-alkalmazás Szolgáltatások rugalmassága, hogy ne is nyelvi alkalmazások, hanem hatékony háttérfolyamatok, valamint a bővíthető Azure Storage és az Azure SQL Database tárolók üzemeltetésére szolgáljon. nagy mennyiségű adat és az Azure Machine elemzési ereje Tanulás olyan tudás és intelligencia létrehozására, amely visszajelzést nyújthat a folyamatoknak, és segít nekünk a megfelelő tartalom eljuttatásában a megfelelő felhasználóknak.
További lépések
Az Azure Cosmos DB használati eseteiről további információt az Azure Cosmos DB gyakori használati eseteiben talál.