Rövid útmutató: Az Azure Machine Tanulás használatának első lépései
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azure-ai-ml v2 (aktuális)
Python SDK azure-ai-ml v2 (aktuális)
Ez az oktatóanyag bemutatja az Azure Machine Tanulás szolgáltatás néhány leggyakrabban használt funkcióját. Ebben létrehoz, regisztrál és üzembe helyez egy modellt. Ez az oktatóanyag segítséget nyújt az Azure Machine Tanulás alapfogalmainak és a leggyakoribb használatuknak a megismerésében.
Megtudhatja, hogyan futtathat egy betanítási feladatot egy méretezhető számítási erőforráson, majd hogyan helyezheti üzembe, és végül tesztelheti az üzembe helyezést.
Létre fog hozni egy betanítási szkriptet az adatelőkészítés, a betanítás és a modell regisztrálásához. A modell betanítása után üzembe helyezi azt végpontként, majd meghívja a végpontot a következtetéshez.
A lépések a következők:
- Fogópont beállítása az Azure Machine Tanulás-munkaterületen
- Betanítási szkript létrehozása
- Méretezhető számítási erőforrás, számítási fürt létrehozása
- Hozzon létre és futtasson egy parancsfeladatot, amely futtatja a betanítási szkriptet a számítási fürtön, a megfelelő feladatkörnyezettel konfigurálva
- A betanítási szkript kimenetének megtekintése
- Az újonnan betanított modell üzembe helyezése végpontként
- Az Azure Machine Tanulás végpontjának meghívása a következtetéshez
Ebben a videóban áttekintheti a rövid útmutató lépéseit.
Előfeltételek
-
Az Azure Machine Tanulás használatához először munkaterületre lesz szüksége. Ha nem rendelkezik ilyen erőforrással, végezze el a munkaterület létrehozásához szükséges erőforrások létrehozását, és tudjon meg többet a használatáról.
-
Jelentkezzen be a stúdióba , és válassza ki a munkaterületet, ha még nincs megnyitva.
-
Jegyzetfüzet megnyitása vagy létrehozása a munkaterületen:
- Hozzon létre egy új jegyzetfüzetet, ha kódot szeretne másolni/beilleszteni a cellákba.
- Vagy nyissa meg az oktatóanyagokat/get-started-notebooks/quickstart.ipynb fájlt a Studio Minták szakaszából. Ezután válassza a Klónozás lehetőséget a jegyzetfüzet fájlokhoz való hozzáadásához. (Lásd a minták helyét.)
A kernel beállítása
A megnyitott jegyzetfüzet fölötti felső sávon hozzon létre egy számítási példányt, ha még nem rendelkezik ilyenrel.

Ha a számítási példány le van állítva, válassza a Számítás indítása lehetőséget, és várja meg, amíg fut.

Győződjön meg arról, hogy a jobb felső sarokban található kernel az
Python 3.10 - SDK v2. Ha nem, a legördülő menüben válassza ki ezt a kernelt.
Ha megjelenik egy szalagcím, amely azt jelzi, hogy hitelesíteni kell, válassza a Hitelesítés lehetőséget.



Fontos
Az oktatóanyag többi része az oktatóanyag-jegyzetfüzet celláit tartalmazza. Másolja vagy illessze be őket az új jegyzetfüzetbe, vagy váltson most a jegyzetfüzetre, ha klónozta.
Leíró létrehozása munkaterületre
Mielőtt belemerülnénk a kódba, szüksége lesz egy módszerre a munkaterületre való hivatkozáshoz. A munkaterület az Azure Machine Learning legfelső szintű erőforrása, amely egy központi helyet biztosít az Azure Machine Learning használata során létrehozott összetevőkkel való munkához.
Létre fog hozni ml_client egy leírót a munkaterületen. Ezután ml_client erőforrásokat és feladatokat fog kezelni.
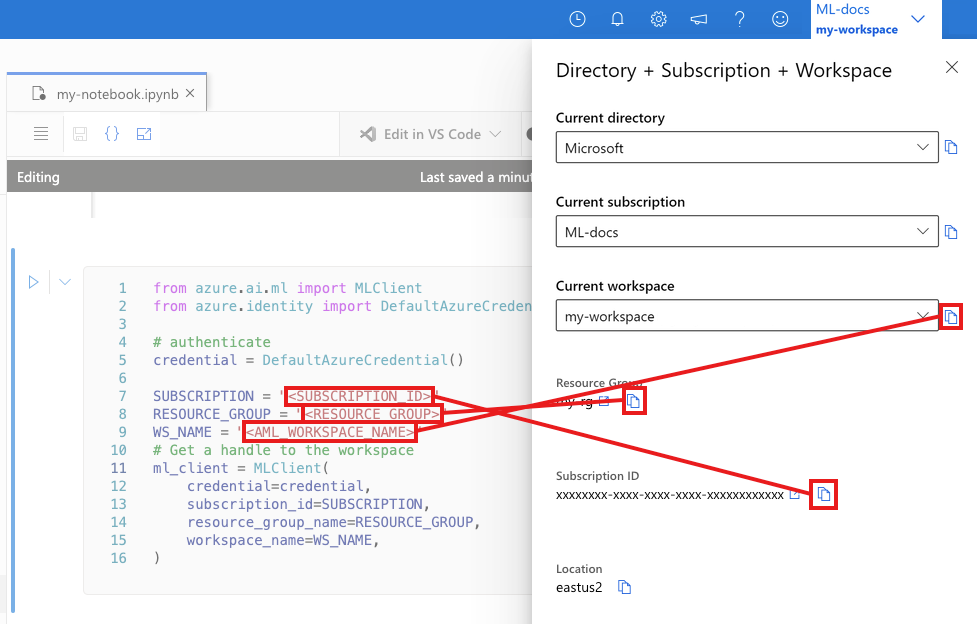
A következő cellában adja meg az előfizetés azonosítóját, az erőforráscsoport nevét és a munkaterület nevét. Az alábbi értékek megkeresése:
- A jobb felső Azure Machine Tanulás studio eszköztáron válassza ki a munkaterület nevét.
- Másolja a munkaterület, az erőforráscsoport és az előfizetés azonosítójának értékét a kódba.
- Ki kell másolnia egy értéket, be kell zárnia a területet és be kell illesztenie, majd vissza kell térnie a következőhöz.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Feljegyzés
Az MLClient létrehozása nem fog csatlakozni a munkaterülethez. Az ügyfél inicializálása lusta, az első alkalommal várakozik, amikor hívást kell kezdeményeznie (ez a következő kódcellában történik).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Betanítási szkript létrehozása
Először hozzuk létre a betanítási szkriptet – a main.py Python-fájlt.
Először hozzon létre egy forrásmappát a szkripthez:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Ez a szkript kezeli az adatok előfeldolgozását, a tesztelési és betanítási adatokra való felosztását. Ezután ezeket az adatokat felhasználja egy faalapú modell betanítása és a kimeneti modell visszaadása érdekében.
Az MLFlow használatával naplózza a paramétereket és a metrikákat a folyamat futtatása során.
Az alábbi cella az IPython magic használatával írja be a betanítási szkriptet az imént létrehozott könyvtárba.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Ahogy ebben a szkriptben látható, a modell betanítása után a rendszer menti és regisztrálja a modellfájlt a munkaterületen. Most már használhatja a regisztrált modellt a végpontok következtetéséhez.
Előfordulhat, hogy a Frissítés lehetőséget kell választania az új mappa és szkript megtekintéséhez a Fájlok mappában.
A parancs konfigurálása
Most, hogy rendelkezik egy szkripttel, amely képes végrehajtani a kívánt feladatokat, és egy számítási fürttel futtatja a szkriptet, egy általános célú parancsot fog használni, amely parancssori műveleteket futtathat. Ez a parancssori művelet közvetlenül meghívhatja a rendszerparancsokat, vagy szkriptet futtathat.
Itt bemeneti változókat fog létrehozni a bemeneti adatok, a felosztási arány, a tanulási sebesség és a regisztrált modellnév megadásához. A parancsszkript a következő lesz:
- Olyan környezetet használjon, amely meghatározza a betanítási szkripthez szükséges szoftver- és futtatókörnyezeti kódtárakat. Az Azure Machine Tanulás számos válogatott vagy kész környezetet biztosít, amelyek hasznosak a gyakori betanítási és következtetési forgatókönyvekhez. Itt az egyik ilyen környezetet fogja használni. Az oktatóanyagban: Modell betanítása az Azure Machine Tanulás-ban, megtudhatja, hogyan hozhat létre egyéni környezetet.
- Konfigurálja magát a parancssori műveletet –
python main.pyebben az esetben. A bemenetek/kimenetek a jelölésen keresztül érhetők el a${{ ... }}parancsban. - Ebben a mintában egy internetes fájlból férünk hozzá az adatokhoz.
- Mivel nincs megadva számítási erőforrás, a szkript egy automatikusan létrehozott kiszolgáló nélküli számítási fürtön fog futni.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="credit_default_prediction",
)
Feladat küldése
Itt az ideje, hogy elküldje a feladatot az Azure Machine Tanulás futtatásához. Ezúttal a következőt ml_clientfogja használnicreate_or_update: .
ml_client.create_or_update(job)
Feladat kimenetének megtekintése és várakozás a feladat befejezésére
Tekintse meg a feladatot az Azure Machine Tanulás Studióban az előző cella kimenetében található hivatkozás kiválasztásával.
A feladat kimenete így fog kinézni az Azure Machine Tanulás studióban. A különböző részletek, például metrikák, kimenetek stb. megismeréséhez tekintse meg a lapokat. Miután végzett, a feladat betanítás eredményeként regisztrál egy modellt a munkaterületen.

Fontos
Várjon, amíg a feladat állapota befejeződik, mielőtt visszatér ehhez a jegyzetfüzethez a folytatáshoz. A feladat futtatása 2–3 percet vesz igénybe. Ha a számítási fürt nullára van skálázva, és az egyéni környezet még mindig épül, több időt is igénybe vehet (akár 10 perc is).
A modell üzembe helyezése online végpontként
Most helyezze üzembe a gépi tanulási modellt webszolgáltatásként az Azure-felhőben, egy online endpoint.
Gépi tanulási szolgáltatás üzembe helyezéséhez a regisztrált modellt fogja használni.
Új online végpont létrehozása
Most, hogy rendelkezik egy regisztrált modellel, ideje létrehoznia az online végpontot. A végpont nevének egyedinek kell lennie a teljes Azure-régióban. Ebben az oktatóanyagban egy egyedi nevet fog létrehozni a következő használatával UUID: .
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Hozza létre a végpontot:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Feljegyzés
Várja meg, hogy a végpont létrehozása néhány percet vesz igénybe.
A végpont létrehozása után az alábbiak szerint kérdezheti le:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
A modell üzembe helyezése a végponton
A végpont létrehozása után helyezze üzembe a modellt a belépési szkripttel. Minden végpont több üzembe helyezéssel is rendelkezhet. Ezekre az üzemelő példányokra vonatkozó közvetlen forgalom szabályokkal adható meg. Itt egyetlen üzembe helyezést fog létrehozni, amely a bejövő forgalom 100%-át kezeli. Színnevet választottunk az üzembe helyezéshez, például kék, zöld, piros üzembe helyezéseket, amelyek tetszőlegesek.
A regisztrált modell legújabb verziójának azonosításához tekintse meg az Azure Machine Tanulás Studio Modellek lapját. Másik lehetőségként az alábbi kód lekéri a használni kívánt legújabb verziószámot.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Telepítse a modell legújabb verzióját.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Feljegyzés
Az üzembe helyezés várhatóan körülbelül 6–8 percet vesz igénybe.
Az üzembe helyezés befejezése után készen áll a tesztelésre.
Tesztelés minta lekérdezéssel
Miután üzembe helyezte a modellt a végponton, következtetést futtathat vele.
Hozzon létre egy mintakérelemfájlt a pontszámszkript futtatási metódusában várt terv alapján.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Az erőforrások eltávolítása
Ha nem használja a végpontot, törölje az erőforrás használatának leállításához. A törlés előtt győződjön meg arról, hogy más üzemelő példányok nem használnak végpontot.
Feljegyzés
A teljes törlés várhatóan körülbelül 20 percet vesz igénybe.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Számítási példány leállítása
Ha most nem fogja használni, állítsa le a számítási példányt:
- A stúdió bal oldali navigációs területén válassza a Számítás lehetőséget.
- A felső lapokban válassza a Számítási példányok lehetőséget
- Válassza ki a számítási példányt a listában.
- A felső eszköztáron válassza a Leállítás lehetőséget.
Az összes erőforrás törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine-Tanulás oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portalon válassza az Erőforráscsoportok lehetőséget a bal szélen.
A listából válassza ki a létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
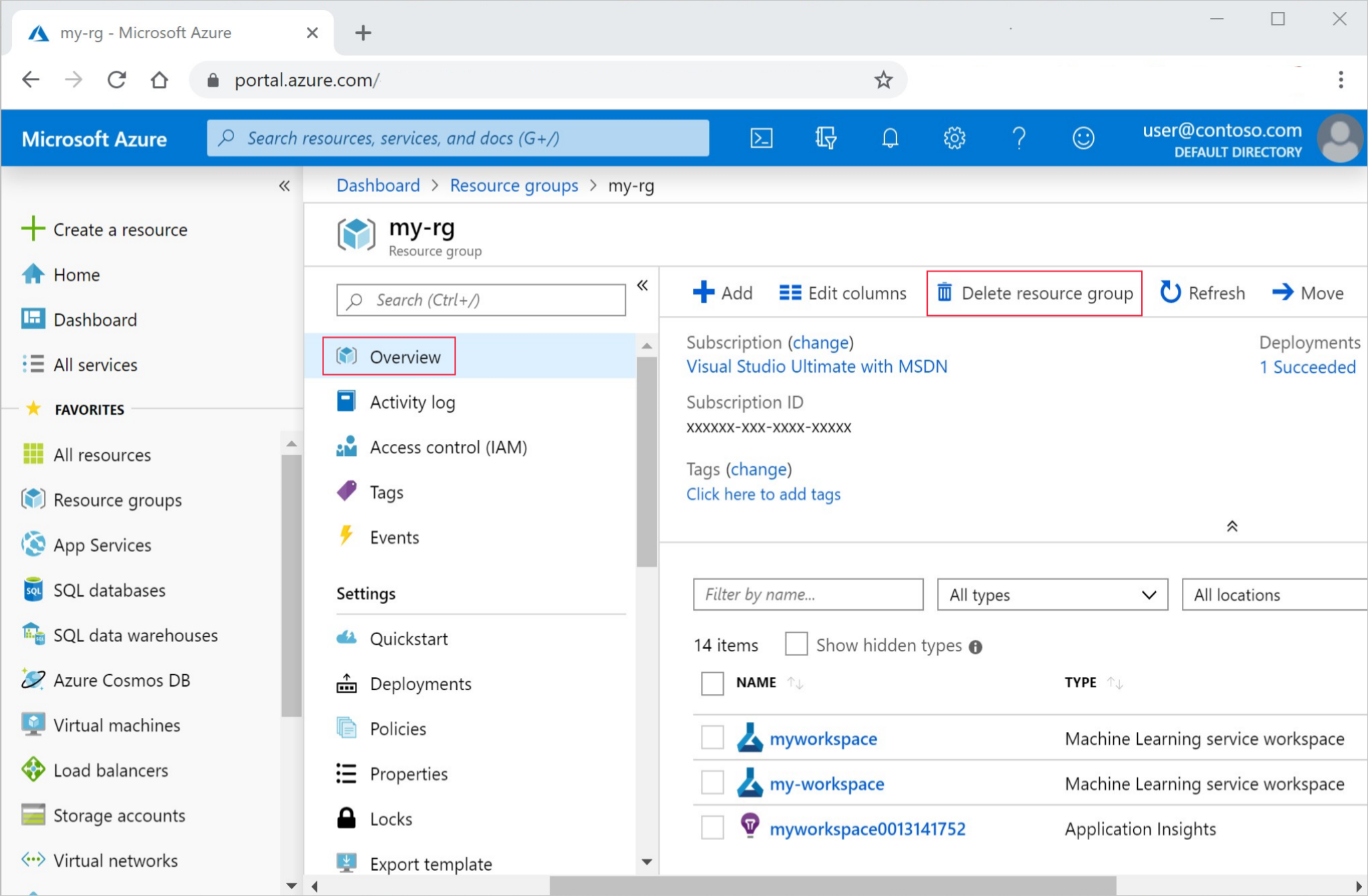
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Következő lépések
Most, hogy megismerkedett a modell betanításának és üzembe helyezésének folyamatával, az alábbi oktatóanyagokban többet tudhat meg a folyamatról:
| Oktatóanyag | Leírás |
|---|---|
| Adatok feltöltése, elérése és feltárása az Azure Machine Tanulás | Nagy méretű adatok tárolása a felhőben, és lekérése jegyzetfüzetekből és szkriptekből |
| Modellfejlesztés felhőbeli munkaállomáson | Gépi tanulási modellek prototípus-készítése és fejlesztése |
| Modell betanítása az Azure Machine Tanulás | Ismerkedés a modell betanításának részleteivel |
| Modell üzembe helyezése online végpontként | Ismerkedés a modell üzembe helyezésének részleteivel |
| Éles gépi tanulási folyamatok létrehozása | Teljes gépi tanulási feladat felosztása többhelyes munkafolyamatra. |