Foglalt adatbázissal kapcsolatos kizárási minták
A feldolgozás adatbázis-kiszolgálóra való kiszervezése azt okozhatja, hogy jelentős mennyiségű időt kell kód futtatására fordítani az adatok tárolására és lekérésére vonatkozó kérések megválaszolása helyett.
A probléma leírása
Számos adatbázisrendszer képes kódok futtatására. Ilyenek például a tárolt eljárások és az eseményindítók. Gyakran hatékonyabb ezt a feldolgozást az adatokhoz közel elvégezni ahelyett, hogy az adatokat egy ügyfélalkalmazásba továbbítanánk feldolgozás céljából. Ezen funkciók túlzott mértékű használata azonban csökkentheti a teljesítményt több okból is:
- Előfordulhat, hogy az adatbázis túl sok időt tölt a feldolgozással az új ügyfélkérések elfogadása és az adatok lekérése helyett.
- Az adatbázisok általában megosztott erőforrások, így magas kihasználtság esetén szűk keresztmetszet jöhet létre.
- Forgalmi díjas adattárak esetén a futtatókörnyezet költségei jelentősen megnövekedhetnek. Ez különösen igaz a felügyelt adatbázisokra. Például az Azure SQL Database Database Transaction Unit (DTU) egységek alapján számláz.
- Az adatbázisok vertikális felskálázási kapacitása véges, a horizontális felskálázás pedig nem egyértelmű. Emiatt érdemes lehet a feldolgozást áthelyezni egy olyan számítási erőforrásra, amelyet könnyű horizontálisan felskálázni, például egy virtuális gépre vagy egy App Service-alkalmazásra.
A kizárási minta jellemzően az alábbi okokból következhet be:
- Az adatbázis szolgáltatásnak minősül, nem adattárnak. Előfordulhat, hogy egy alkalmazás az adatbázist használja adatok formázásához (például XML formátumúra konvertálásához), sztringadatok módosításához vagy összetett számítások végrehajtásához.
- A fejlesztők olyan lekérdezéseket próbálnak írni, amelyek eredményei közvetlenül a felhasználók számára jelennek meg. Például lehet, hogy egy lekérdezés mezőket kombinál, vagy területi beállítás szerint formáz dátumokat, időpontokat és pénznemet.
- A fejlesztők megpróbálják kijavítani a Felesleges beolvasások kizárási mintát számítások az adatbázis számára való elküldésével.
- A tárolt eljárásokat tárolják az üzleti logikát, talán azért, mert könnyebb őket karbantartani és frissíteni.
A következő példa lekérdezi a 20 legértékesebb rendelést egy megadott értékesítési területre vonatkozóan, és az eredményeket XML-fájlként formázza. A példa Transact-SQL függvényeket használ az adatok elemzéséhez és az eredmények XML formátumúra konvertálásához. A teljes kódmintát itt találja.
SELECT TOP 20
soh.[SalesOrderNumber] AS '@OrderNumber',
soh.[Status] AS '@Status',
soh.[ShipDate] AS '@ShipDate',
YEAR(soh.[OrderDate]) AS '@OrderDateYear',
MONTH(soh.[OrderDate]) AS '@OrderDateMonth',
soh.[DueDate] AS '@DueDate',
FORMAT(ROUND(soh.[SubTotal],2),'C')
AS '@SubTotal',
FORMAT(ROUND(soh.[TaxAmt],2),'C')
AS '@TaxAmt',
FORMAT(ROUND(soh.[TotalDue],2),'C')
AS '@TotalDue',
CASE WHEN soh.[TotalDue] > 5000 THEN 'Y' ELSE 'N' END
AS '@ReviewRequired',
(
SELECT
c.[AccountNumber] AS '@AccountNumber',
UPPER(LTRIM(RTRIM(REPLACE(
CONCAT( p.[Title], ' ', p.[FirstName], ' ', p.[MiddleName], ' ', p.[LastName], ' ', p.[Suffix]),
' ', ' ')))) AS '@FullName'
FROM [Sales].[Customer] c
INNER JOIN [Person].[Person] p
ON c.[PersonID] = p.[BusinessEntityID]
WHERE c.[CustomerID] = soh.[CustomerID]
FOR XML PATH ('Customer'), TYPE
),
(
SELECT
sod.[OrderQty] AS '@Quantity',
FORMAT(sod.[UnitPrice],'C')
AS '@UnitPrice',
FORMAT(ROUND(sod.[LineTotal],2),'C')
AS '@LineTotal',
sod.[ProductID] AS '@ProductId',
CASE WHEN (sod.[ProductID] >= 710) AND (sod.[ProductID] <= 720) AND (sod.[OrderQty] >= 5) THEN 'Y' ELSE 'N' END
AS '@InventoryCheckRequired'
FROM [Sales].[SalesOrderDetail] sod
WHERE sod.[SalesOrderID] = soh.[SalesOrderID]
ORDER BY sod.[SalesOrderDetailID]
FOR XML PATH ('LineItem'), TYPE, ROOT('OrderLineItems')
)
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC
FOR XML PATH ('Order'), ROOT('Orders')
Természetesen ez egy összetett lekérdezés. Ahogyan azt a későbbiekben látni fogjuk, a lekérdezés jelentős mértékű feldolgozási erőforrást használ az adatbázis-kiszolgálón.
A probléma megoldása
Helyezze át a feldolgozást az adatbázis-kiszolgálóról más alkalmazásrétegekbe. Ideális esetben érdemes az adatbázist arra korlátozni, hogy adatelérési műveleteket végezzen azon képességekkel, amelyekre optimalizálva lett, ilyen például az RDBMS-be való aggregáció.
Például az előző Transact-SQL kód lecserélhető egy utasításra, amely egyszerűen lekéri a feldolgozandó adatokat.
SELECT
soh.[SalesOrderNumber] AS [OrderNumber],
soh.[Status] AS [Status],
soh.[OrderDate] AS [OrderDate],
soh.[DueDate] AS [DueDate],
soh.[ShipDate] AS [ShipDate],
soh.[SubTotal] AS [SubTotal],
soh.[TaxAmt] AS [TaxAmt],
soh.[TotalDue] AS [TotalDue],
c.[AccountNumber] AS [AccountNumber],
p.[Title] AS [CustomerTitle],
p.[FirstName] AS [CustomerFirstName],
p.[MiddleName] AS [CustomerMiddleName],
p.[LastName] AS [CustomerLastName],
p.[Suffix] AS [CustomerSuffix],
sod.[OrderQty] AS [Quantity],
sod.[UnitPrice] AS [UnitPrice],
sod.[LineTotal] AS [LineTotal],
sod.[ProductID] AS [ProductId]
FROM [Sales].[SalesOrderHeader] soh
INNER JOIN [Sales].[Customer] c ON soh.[CustomerID] = c.[CustomerID]
INNER JOIN [Person].[Person] p ON c.[PersonID] = p.[BusinessEntityID]
INNER JOIN [Sales].[SalesOrderDetail] sod ON soh.[SalesOrderID] = sod.[SalesOrderID]
WHERE soh.[TerritoryId] = @TerritoryId
AND soh.[SalesOrderId] IN (
SELECT TOP 20 SalesOrderId
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC)
ORDER BY soh.[TotalDue] DESC, sod.[SalesOrderDetailID]
Az alkalmazás ezután a .NET-keretrendszerbeli System.Xml.Linq API-k használatával formázza az eredményeket XML-ként.
// Create a new SqlCommand to run the Transact-SQL query
using (var command = new SqlCommand(...))
{
command.Parameters.AddWithValue("@TerritoryId", id);
// Run the query and create the initial XML document
using (var reader = await command.ExecuteReaderAsync())
{
var lastOrderNumber = string.Empty;
var doc = new XDocument();
var orders = new XElement("Orders");
doc.Add(orders);
XElement lineItems = null;
// Fetch each row in turn, format the results as XML, and add them to the XML document
while (await reader.ReadAsync())
{
var orderNumber = reader["OrderNumber"].ToString();
if (orderNumber != lastOrderNumber)
{
lastOrderNumber = orderNumber;
var order = new XElement("Order");
orders.Add(order);
var customer = new XElement("Customer");
lineItems = new XElement("OrderLineItems");
order.Add(customer, lineItems);
var orderDate = (DateTime)reader["OrderDate"];
var totalDue = (Decimal)reader["TotalDue"];
var reviewRequired = totalDue > 5000 ? 'Y' : 'N';
order.Add(
new XAttribute("OrderNumber", orderNumber),
new XAttribute("Status", reader["Status"]),
new XAttribute("ShipDate", reader["ShipDate"]),
... // More attributes, not shown.
var fullName = string.Join(" ",
reader["CustomerTitle"],
reader["CustomerFirstName"],
reader["CustomerMiddleName"],
reader["CustomerLastName"],
reader["CustomerSuffix"]
)
.Replace(" ", " ") //remove double spaces
.Trim()
.ToUpper();
customer.Add(
new XAttribute("AccountNumber", reader["AccountNumber"]),
new XAttribute("FullName", fullName));
}
var productId = (int)reader["ProductID"];
var quantity = (short)reader["Quantity"];
var inventoryCheckRequired = (productId >= 710 && productId <= 720 && quantity >= 5) ? 'Y' : 'N';
lineItems.Add(
new XElement("LineItem",
new XAttribute("Quantity", quantity),
new XAttribute("UnitPrice", ((Decimal)reader["UnitPrice"]).ToString("C")),
new XAttribute("LineTotal", RoundAndFormat(reader["LineTotal"])),
new XAttribute("ProductId", productId),
new XAttribute("InventoryCheckRequired", inventoryCheckRequired)
));
}
// Match the exact formatting of the XML returned from SQL
var xml = doc
.ToString(SaveOptions.DisableFormatting)
.Replace(" />", "/>");
}
}
Megjegyzés:
Ez a kód viszonylag összetett. Új alkalmazáshoz érdemes lehet egy szerializációs kódtárat használni. Azonban itt azt a feltételezzük, hogy a fejlesztőcsapat egy meglévő alkalmazást tervez újra, így a metódusnak az eredeti kóddal megegyező formátumban kell visszaadnia az eredményeket.
Considerations
Számos adatbázisrendszer nagy mértékben optimalizálva van bizonyos típusú adatfeldolgozások elvégzésére, például nagy méretű adatkészletekből aggregált értékek kiszámítására. Ezeket a feldolgozástípusokat ne helyezze át máshová az adatbázisból.
Ne helyezze át a feldolgozási folyamatokat, ha emiatt az adatbázis hálózati adatátvitele nagy mértékben megnövekszik. Tekintse meg a Felesleges beolvasások kizárási mintát.
Ha a feldolgozást egy alkalmazásrétegbe helyezi át, akkor lehet, hogy azt a réteget horizontálisan fel kell skálázni, hogy kezelni tudja a további munkamennyiséget.
A probléma észlelése
Foglalt adatbázist jelez többek között az adatbázist elérő műveletek átviteli sebességének és válaszidejének aránytalan romlása.
A következő lépések végrehajtásával azonosíthatja a problémát:
A teljesítménymonitorozás révén határozza meg, hogy az éles rendszer mennyi időt fordít az adatbázis-tevékenységek elvégzésére.
Vizsgálja meg az adatbázis által ezen idő alatt elvégzett feladatokat.
Ha arra gyanakszik, hogy bizonyos műveletek túl sok adatbázis-tevékenységet okoznak, végezzen terhelési teszteket ellenőrzött környezetben. Minden tesztben futtasson gyanús műveleteket változó felhasználói terheléssel. A terhelési tesztekből származó telemetria megvizsgálásával elemezze az adatbázis használatát.
Ha az adatbázis-tevékenység jelentős mennyiségű adatfeldolgozást, de kevés adatforgalmat jelez, tekintse át a forráskódot, és döntse el, hogy nem lenne-e jobb a feldolgozást máshol végezni.
Ha az adatbázis-tevékenység mennyisége alacsony, vagy a válaszidők viszonylag rövidek, akkor valószínűleg nincs foglalt adatbázis típusú teljesítményprobléma.
Diagnosztikai példa
Az alábbi szakaszokban ezeket a lépéseket hajtjuk végre a fentebb leírt mintaalkalmazáson.
Az adatbázis-tevékenység mértékének monitorozása
A következő diagram bemutatja egy mintaalkalmazás terhelési tesztjének eredményeit. A teszt lépéses terhelést használt legfeljebb 50 egyidejű felhasználóval. A kérések mennyisége hamar eléri a korlátot, és azon a szinten marad, miközben az átlagos válaszidő folyamatosan nő. A két metrika logaritmikus skálán jelenik meg.

Ezen a vonaldiagramon a felhasználói terhelés, a másodpercenkénti kérésszám és az átlagos válaszidő látható. A diagramon látható, hogy a terhelés növekedésével a válaszidő is nő.
A következő grafikon a processzorkihasználtságot és a DTU-k számát mutatja a szolgáltatási kvóta százalékában. A DTU-kkal mérhető, hogy az adatbázis mennyi feldolgozást végez. A grafikonon látható, hogy a processzor és a DTU-k kihasználtsága egyaránt gyorsan elérte a 100%-ot.
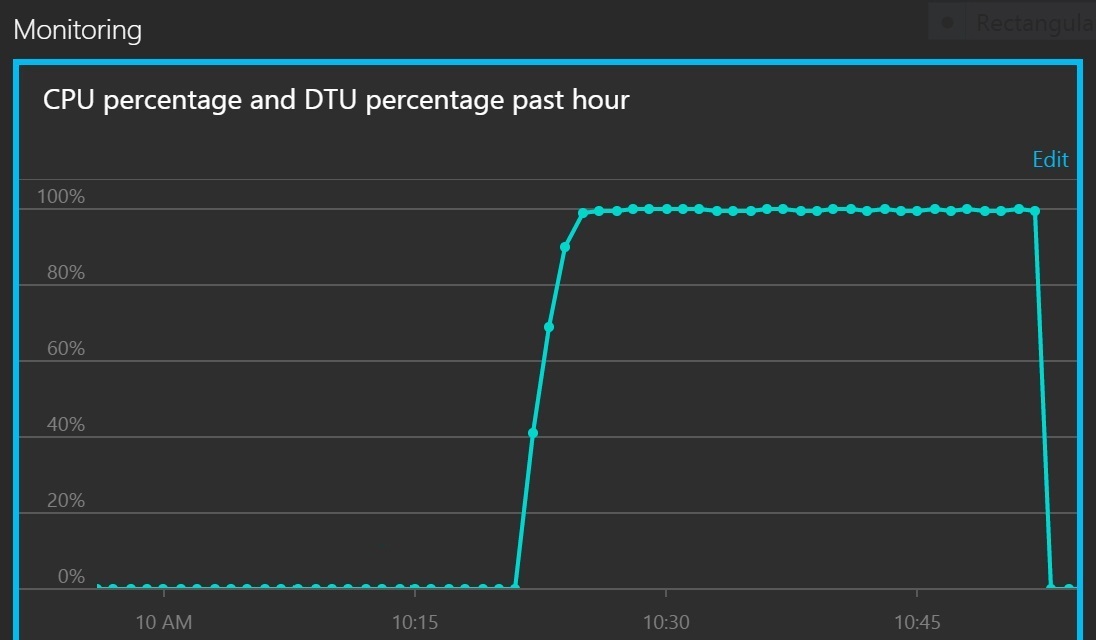
Ezen a vonaldiagramon a processzor- és a DTU-kihasználtság látható az idő függvényében. A diagramon látható, hogy mindkét mutató gyorsan eléri a 100%-os értéket.
Az adatbázis által elvégzett feladatok vizsgálata
Előfordulhat, hogy az adatbázis valódi adathozzáférési műveleteket végez, nem feldolgozást, ezért fontos megismerni az adatbázis foglalt állapota mellett futó SQL-utasításokat. A rendszer monitorozásával rögzítse az SQL forgalmi adatokat, és vesse össze az SQL-műveleteket az alkalmazáskérésekkel.
Ha az adatbázis műveletei tisztán adathozzáférési műveletek nagy mennyiségű feldolgozás nélkül, akkor a probléma okai felesleges beolvasások lehetnek.
A megoldás megvalósítása és az eredmény ellenőrzése
A következő grafikonon egy, a frissített kóddal végzett terhelési teszt látható. Az átviteli sebesség jóval magasabb, másodpercenként több mint 400 kérés a korábbi 12-vel szemben. Az átlagos válaszidő szintén sokkal alacsonyabb, alig több mint 0,1 másodperc a korábbi 4 másodperchez képest.
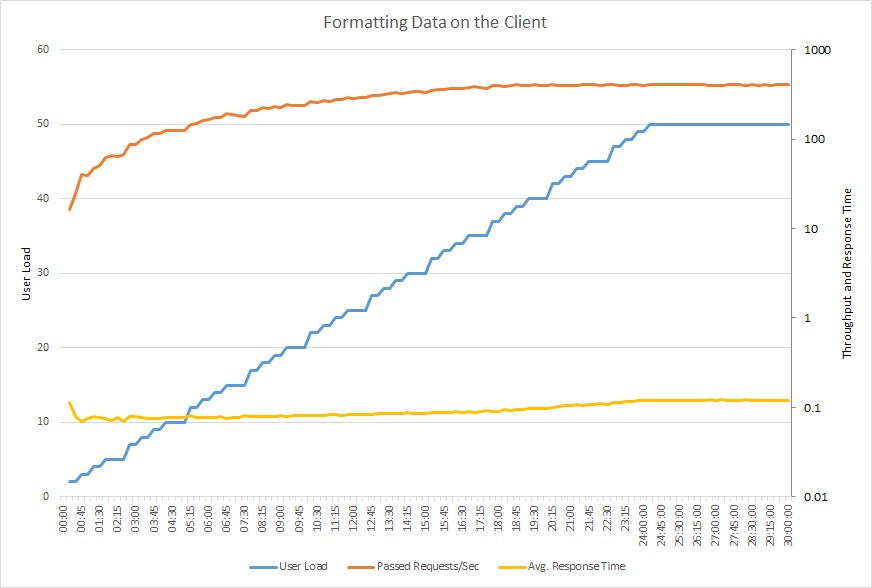
Ezen a vonaldiagramon a felhasználói terhelés, a másodpercenkénti kérésszám és az átlagos válaszidő látható. A diagramon látható, hogy a válaszidő nagyjából állandó marad a terhelési teszt során.
A processzor- és DTU-kihasználtság azt mutatja, hogy a rendszer hosszabb idő alatt érte el a telítettséget a megnövelt adatátviteli sebesség ellenére is.
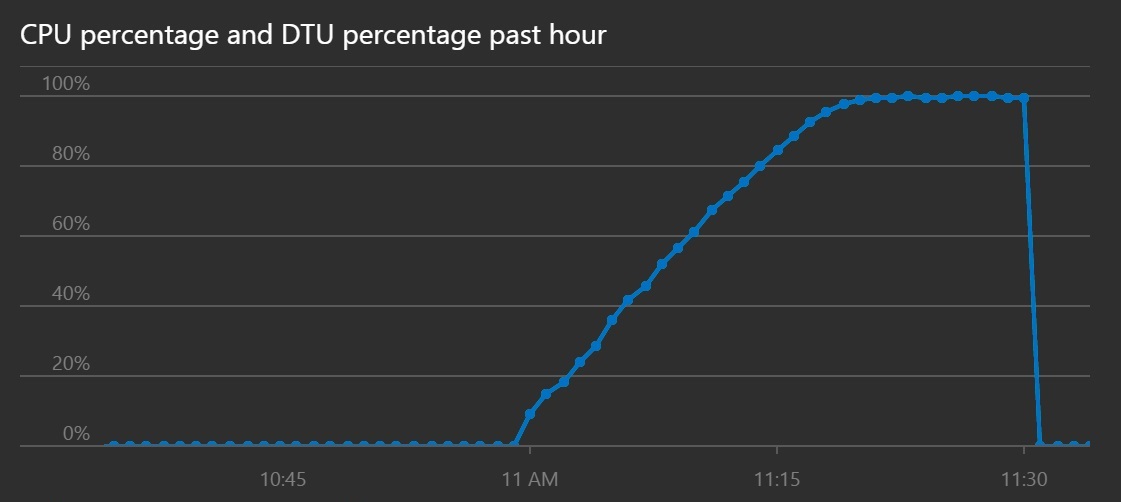
Ezen a vonaldiagramon a processzor- és a DTU-kihasználtság látható az idő függvényében. A diagramon látható, hogy a processzor- és a DTU-kihasználtság a korábbinál lassabban éri el a 100%-ot.
Kapcsolódó erőforrások
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: