Ez a cikk az adattárházprojektek alternatív megközelítését ismerteti, amelyet feltáró adatelemzésnek (EDA) nevezünk. Ez a megközelítés csökkentheti a kinyerési, átalakítási, betöltési (ETL-) műveletek kihívásait. Először az üzleti elemzések létrehozására összpontosít, majd a modellezési és ETL-feladatok megoldására vált.
Felépítés

Töltse le az architektúra Visio-fájlját.
Az EDA esetében csak a diagram jobb oldalával foglalkozik. Az Azure Synapse SQL kiszolgáló nélküli számítási motorként szolgál a data lake-fájlokon keresztül.
Az EDA végrehajtásához:
- A T-SQL-lekérdezések közvetlenül az Azure Synapse SQL kiszolgáló nélküli vagy az Azure Synapse Sparkban futnak.
- A lekérdezések grafikus lekérdezési eszközből, például a Power BI-ból vagy az Azure Data Studióból futnak.
Javasoljuk, hogy az összes lakehouse-adatot a Parquet vagy a Delta használatával őrizze meg.
A diagram bal oldalát (adatbetöltést) bármilyen kinyerési, betöltési, átalakítási (ELT) eszközzel implementálhatja. Nincs hatása az EDA-ra.
Összetevők
Az Azure Synapse Analytics egyesíti az adatintegrációt, a vállalati adattárházat és a big data-elemzést a lakehouse-adatokon keresztül. Ebben a megoldásban:
- Az Azure Synapse-munkaterület elősegíti az adatmérnökök, adattudósok, adatelemzők és üzletiintelligencia-szakemberek együttműködését az EDA-feladatokhoz.
- Az Azure Synapse kiszolgáló nélküli SQL-készletei strukturálatlan és félig strukturált adatokat elemeznek az Azure Data Lake Storage-ban standard T-SQL használatával.
- Az Azure Synapse kiszolgáló nélküli Apache Spark-készletek kódelső feltárásokat végeznek a Data Lake Storage-ban olyan Spark-nyelvek használatával, mint a Spark SQL, a PySpark és a Scala.
Az Azure Data Lake Storage olyan adatokat biztosít, amelyeket aztán az Azure Synapse kiszolgáló nélküli SQL-készletei elemeznek.
Az Azure Machine Tanulás adatokat biztosít az Azure Synapse Sparknak.
Ebben a megoldásban a Power BI használatával kérdezhetők le adatok az EDA végrehajtásához.
Alternatívák
A Synapse SQL kiszolgáló nélküli készleteit lecserélheti vagy kiegészítheti az Azure Databricks szolgáltatással.
Ahelyett, hogy kiszolgáló nélküli Synapse SQL-készletekkel rendelkező lakehouse-modellt használ, az Azure Synapse dedikált SQL-készleteivel vállalati adatokat tárolhat. Tekintse át a jelen cikkben szereplő használati eseteket és szempontokat, valamint a kapcsolódó erőforrásokat annak eldöntéséhez, hogy melyik technológiát használja.
Forgatókönyv részletei
Ez a megoldás az adattárház-projektek EDA-megközelítésének implementálását mutatja be. Ez a megközelítés csökkentheti az ETL-műveletek kihívásait. Először az üzleti elemzések létrehozására összpontosít, majd a modellezési és ETL-feladatok megoldására vált.
Lehetséges használati esetek
Egyéb forgatókönyvek, amelyek kihasználhatják ezt az elemzési mintát:
Prescriptive analytics. Tegyen fel kérdéseket az adataival kapcsolatban, például a Következő legjobb művelet, vagy mi a következő lépés? Adatvezéreltebb és kevésbé zsigerelt adatok használata. Előfordulhat, hogy az adatok strukturálatlanok, és számos különböző minőségű külső forrásból származnak. Érdemes lehet a lehető leggyorsabban használni az adatokat az üzleti stratégia kiértékeléséhez anélkül, hogy ténylegesen betöltené az adatokat egy adattárházba. A kérdések megválaszolása után megsemmisítheti az adatokat.
Önkiszolgáló ETL. Végezze el az ETL/ELT ETL-t az adat-tesztkörnyezeti (EDA) tevékenységek végrehajtásakor. Alakítsa át az adatokat, és tegye értékessé. Ezzel javíthatja az ETL-fejlesztők skáláját.
Tudnivalók a feltáró adatelemzésről
Mielőtt részletesebben megvizsgálnánk az EDA működését, érdemes összefoglalni az adattárházprojektek hagyományos megközelítését. A hagyományos megközelítés így néz ki:
Követelmények összegyűjtése. Az adatokkal kapcsolatos teendők dokumentálása.
Adatmodellezés. Határozza meg, hogyan modellezheti a numerikus és attribútumadatokat tény- és dimenziótáblákba. Ezt a lépést hagyományosan az új adatok beszerzése előtt kell elvégeznie.
ETL. Szerezze be az adatokat, és masszírozza be az adattárház adatmodellbe.
Ezek a lépések hetekig vagy akár hónapokig is eltarthatnak. Csak ezután kezdheti meg az adatok lekérdezését és az üzleti probléma megoldását. A felhasználó csak a jelentések létrehozása után látja az értéket. A megoldásarchitektúra általában a következőképpen néz ki:
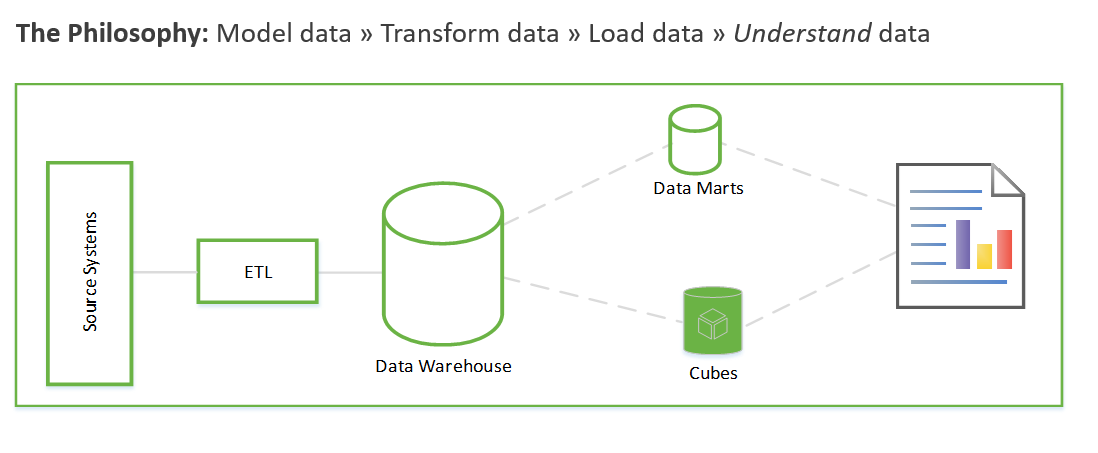
Ezt egy másik módon teheti meg, amely először az üzleti elemzések létrehozására összpontosít, majd a modellezési és ETL-feladatok megoldásához fordul. A folyamat hasonló az adatelemzési folyamatokhoz. A következőhöz hasonlóan néz ki:
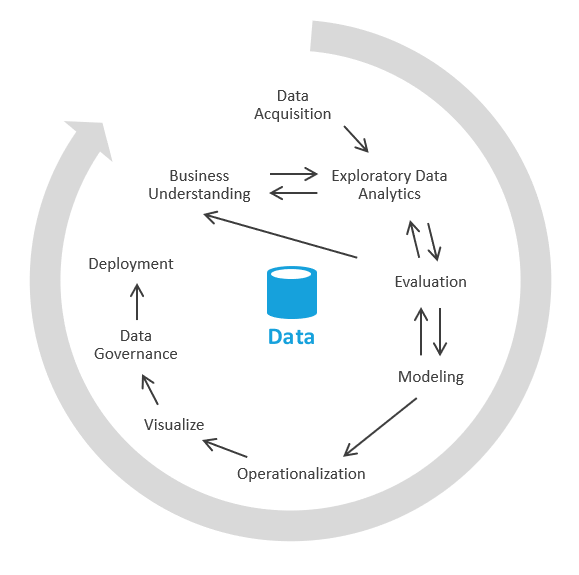
Az iparágban ezt a folyamatot EDA-nak vagy feltáró adatelemzésnek nevezzük.
Here are the steps:
Adatgyűjtés. Először meg kell határoznia, hogy milyen adatforrásokat kell beemésztnie a data lake-be / tesztkörnyezetbe. Ezután ezeket az adatokat be kell vinnie a tó célzónába. Az Azure olyan eszközöket biztosít, mint az Azure Data Factory és az Azure Logic Apps, amelyek gyorsan betölthetik az adatokat.
Adat-tesztkörnyezet. Kezdetben egy üzleti elemző és egy mérnök, aki az Azure Synapse Analytics kiszolgáló nélküli vagy alapszintű SQL használatával végzett feltáróadat-elemzésben jártas. Ebben a fázisban az új adatok használatával próbálják feltárni az üzleti megállapításokat . Az EDA iteratív folyamat. Előfordulhat, hogy több adatot kell betöltenie, beszélnie kell a kkv-kkal, további kérdéseket kell feltennie, vagy vizualizációkat kell létrehoznia.
Kiértékelés. Miután megtalálta az üzleti megállapításokat, ki kell értékelnie, hogy mit kell tennie az adatokkal. Előfordulhat, hogy meg szeretné őrizni az adatokat az adattárházban (ezért a modellezési fázisra kell lépnie). Más esetekben dönthet úgy, hogy megtartja az adatokat a data lake/lakehouse-ban, és prediktív elemzésre (gépi tanulási algoritmusokra) használja. Más esetekben dönthet úgy, hogy az új megállapításokkal újra kitölti a rekordrendszereket. Ezek alapján a döntések alapján jobban megértheti, hogy mit kell tennie. Előfordulhat, hogy nem kell elvégeznie az ETL-t.
Ezek a módszerek képezik a valódi önkiszolgáló elemzések alapját. A data lake és egy olyan lekérdezési eszköz, mint az Azure Synapse kiszolgáló nélküli, amely ismeri a data lake-lekérdezési mintákat, az adategységeket olyan üzletemberek kezébe helyezheti, akik megértik az SQL egy modicumát. Ezzel a módszerrel radikálisan lerövidítheti az idő–érték arányt, és eltávolíthatja a vállalati adatkezdeményekhez kapcsolódó kockázat egy részét.
Considerations
Ezek a szempontok implementálják az Azure Well-Architected Framework alappilléreit, amely a számítási feladatok minőségének javítására használható vezérelvek halmaza. További információ: Microsoft Azure Well-Architected Framework.
Elérhetőség
Az Azure Synapse SQL kiszolgáló nélküli készletei szolgáltatásként nyújtott platform (PaaS) funkció, amely megfelel a magas rendelkezésre állási (HA) és vészhelyreállítási (DR) követelményeknek.
A kiszolgáló nélküli készletek igény szerint érhetők el. Nem igényelnek fel- és leskálázást, be- vagy ki- vagy felskálázást, illetve semmilyen adminisztrációt. Lekérdezésenkénti fizetéses modellt használnak, így nincs kihasználatlan kapacitás. A kiszolgáló nélküli készletek ideálisak a következőkhöz:
- Alkalmi adatelemzési kutatások a T-SQL-ben.
- Az adattárház-entitások korai prototípus-készítése.
- Olyan nézetek meghatározása, amelyeket a felhasználók használhatnak például a Power BI-ban olyan forgatókönyvekhez, amelyek képesek elviselni a teljesítménybeli késést.
- Feltáró adatelemzés.
Operations
A Synapse SQL kiszolgáló nélküli használata szabványos T-SQL-t használ lekérdezésekhez és műveletekhez. T-SQL-eszközként használhatja a Synapse-munkaterület felhasználói felületét, az Azure Data Studiót vagy az SQL Server Management Studiót.
Költségoptimalizálás
A költségoptimalizálás a szükségtelen kiadások csökkentésének és a működési hatékonyság javításának módjairól szól. További információ: A költségoptimalizálási pillér áttekintése.
A Data Lake Storage díjszabása a tárolt adatok mennyiségétől és az adatok használatának gyakoriságától függ. A minta díjszabása egy TB tárolt adatot tartalmaz, további tranzakciós feltételezésekkel. Az egyetlen TB a data lake méretére vonatkozik, nem az eredeti örökölt adatbázis méretére.
Az Azure Synapse Spark-készlet a csomópont méretére, a példányok számára és az üzemidőre alapozza a díjszabást. A példa egy kis számítási csomópontot feltételez, amelynek kihasználtsága heti öt óra és havonta 40 óra között van.
Az Azure Synapse kiszolgáló nélküli SQL-készlete a feldolgozott adatok TB-jeire alapozza a díjszabást. A minta havi 50 TB-ot feltételez. Ez az ábra a data lake méretére vonatkozik, nem az eredeti örökölt adatbázis méretére.
Közreműködők
Ezt a cikket a Microsoft frissíti és karbantartja. Eredetileg a következő közreműködők írták.
Fő szerzők:
- Dave Wentzel | Fő MTC műszaki tervező
További lépések
- adatmérnök képzési tervek
- Oktatóanyag: Az Azure Synapse Analytics használatának első lépései
- Egyetlen adatbázis létrehozása – Azure SQL Database
- Azure Synapse SQL-architektúra
- Tárfiók létrehozása az Azure Data Lake Storage-hoz
- Azure Event Hubs – Rövid útmutató – Eseményközpont létrehozása az Azure Portal használatával
- Rövid útmutató – Stream Analytics-feladat létrehozása az Azure Portal használatával
- Rövid útmutató: Az Azure Machine Tanulás használatának első lépései