Ez a cikk az adatok mikroszolgáltatás-architektúrában történő kezelésének szempontjait ismerteti. Mivel minden mikroszolgáltatás kezeli a saját adatait, az adatintegritás és az adatkonzisztencia kritikus kihívást jelent.
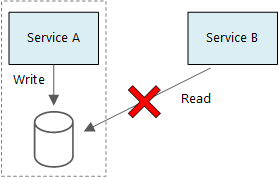
A mikroszolgáltatások egyik alapelve, hogy mindegyik szolgáltatás a saját adatait felügyeli. Két szolgáltatás nem oszthat meg adattárat. Ehelyett minden szolgáltatás a saját privát adattáráért felelős, amelyet más szolgáltatások közvetlenül nem tudnak elérni.
Ennek a szabálynak az az oka, hogy elkerülje a szolgáltatások közötti véletlen összekapcsolást, ami akkor fordulhat elő, ha a szolgáltatások ugyanazokat a mögöttes adatsémákat használják. Ha az adatséma módosul, a módosítást minden olyan szolgáltatásban koordinálni kell, amely az adatbázisra támaszkodik. Az egyes szolgáltatások adattárának elkülönítésével korlátozhatjuk a változás hatókörét, és megőrizhetjük a valóban független üzemelő példányok rugalmasságát. Egy másik ok, hogy minden mikroszolgáltatás saját adatmodellekkel, lekérdezésekkel vagy olvasási/írási mintákkal rendelkezhet. A megosztott adattár használata korlátozza az egyes csapatok azon képességét, hogy optimalizálják az adattárolást az adott szolgáltatáshoz.
Ez a megközelítés természetesen többplatformos adatmegőrzéshez vezet – több adattárolási technológia egyetlen alkalmazáson belül történő használatához. Egy szolgáltatáshoz szükség lehet egy dokumentumadatbázis sémaalapú olvasási képességeire. Egy másiknak szüksége lehet az RDBMS által biztosított hivatkozási integritásra. Minden csapat szabadon választhat a legjobban a szolgáltatásához.
Megjegyzés:
Az azonos fizikaiadatbázis-kiszolgálót megosztó szolgáltatások esetében nem gond. A probléma akkor fordul elő, ha a szolgáltatások ugyanazt a sémát használják, vagy ugyanabban az adatbázistáblákban olvasnak és írnak.
Problémák
Az adatok kezelésének elosztott megközelítéséből adódóan bizonyos kihívások merülnek fel. Először is előfordulhat, hogy az adattárakban redundancia van, és ugyanaz az adatelem több helyen is megjelenik. Előfordulhat például, hogy az adatokat egy tranzakció részeként tárolják, majd máshol tárolják elemzés, jelentéskészítés vagy archiválás céljából. A duplikált vagy particionált adatok adatintegritási és konzisztenciával kapcsolatos problémákhoz vezethetnek. Ha az adatkapcsolatok több szolgáltatásra is kiterjednek, nem használhat hagyományos adatkezelési technikákat a kapcsolatok kényszerítésére.
A hagyományos adatmodellezés az "egy tény egy helyen" szabályt használja. Minden entitás pontosan egyszer jelenik meg a sémában. Más entitások hivatkozhatnak rá, de nem duplikálhatják. A hagyományos megközelítés nyilvánvaló előnye, hogy a frissítések egyetlen helyen történnek, ami elkerüli az adatkonzisztenciával kapcsolatos problémákat. A mikroszolgáltatás-architektúrában figyelembe kell vennie, hogyan propagálja a frissítéseket a szolgáltatások között, és hogyan kezelheti a végleges konzisztenciát, ha az adatok több helyen jelennek meg erős konzisztencia nélkül.
Az adatok kezelésének megközelítései
Nincs olyan megközelítés, amely minden esetben helyes, de íme néhány általános irányelv az adatok mikroszolgáltatás-architektúrában való kezelésére.
Ahol lehetséges, támogassa a végső konzisztenciát. Ismerje meg a rendszerben azokat a helyeket, ahol erős konzisztenciára vagy ACID-tranzakciókra van szükség, valamint azokat a helyeket, ahol a végleges konzisztencia elfogadható.
Ha erős konzisztenciagaranciára van szüksége, egy szolgáltatás egy adott entitás igazságforrását jelentheti, amely egy API-val érhető el. Más szolgáltatások maguk is tárolhatják az adatok saját másolatát vagy az adatok egy részét, amely végül összhangban van a fő adatokkal, de nem tekinthető az igazság forrásának. Képzeljen el például egy e-kereskedelmi rendszert egy ügyfélszolgálattal és egy ajánlási szolgáltatással. Előfordulhat, hogy a javaslati szolgáltatás figyeli a rendelési szolgáltatás eseményeit, de ha egy ügyfél visszatérítést kér, az a rendelési szolgáltatás, nem pedig a javaslati szolgáltatás, amely rendelkezik a teljes tranzakciós előzményekkel.
Tranzakciók esetén használjon olyan mintákat, mint a Scheduler Agent Supervisor és a Compensating Transaction , hogy az adatok több szolgáltatásban konzisztensek maradjanak. Előfordulhat, hogy több szolgáltatásra kiterjedő munkaegység állapotát rögzítő további adatokat kell tárolnia, hogy elkerülje a több szolgáltatás részleges meghibásodását. Ha például egy munkaelemet tartós üzenetsoron tart, miközben többlépéses tranzakció van folyamatban.
Csak azokat az adatokat tárolja, amelyekre egy szolgáltatásnak szüksége van. Előfordulhat, hogy egy szolgáltatásnak csak egy tartományi entitás információinak egy részhalmazára van szüksége. Például a szállítási keret kontextusában tudnunk kell, hogy melyik ügyfél van társítva egy adott kézbesítéshez. Nincs szükségünk azonban az ügyfél számlázási címére – amelyet a fiókok által határolt környezet kezel. Ebben segíthet, ha alaposan átgondolja a tartományt, és DDD-megközelítést használ.
Fontolja meg, hogy a szolgáltatások koherensek és lazán kapcsolódnak-e. Ha két szolgáltatás folyamatosan cseréli az információkat egymással, ami beszédes API-kat eredményez, előfordulhat, hogy át kell újítania a szolgáltatás határait két szolgáltatás egyesítésével vagy a funkciók újrabontásával.
Eseményvezérelt architektúrastílus használata. Ebben az architektúrastílusban a szolgáltatás közzétesz egy eseményt, ha módosulnak a nyilvános modelljei vagy entitásai. Az érdeklődő szolgáltatások feliratkozhatnak ezekre az eseményekre. Egy másik szolgáltatás például az események használatával olyan materializált nézetet hozhat létre az adatokról, amelyek jobban alkalmasak a lekérdezésre.
Az eseményeket birtokoló szolgáltatásnak közzé kell tennie egy sémát, amellyel automatizálható az események szerializálása és deszerializálása, így elkerülhető a közzétevők és az előfizetők közötti szoros kapcsolat. Fontolja meg a JSON-sémát vagy egy olyan keretrendszert, mint a Microsoft Bond, a Protobuf vagy az Avro.
Nagy léptékben az események szűk keresztmetszetté válhatnak a rendszeren, ezért fontolja meg az összesítés vagy a kötegelés használatát a teljes terhelés csökkentése érdekében.
Példa: Adattárak kiválasztása a Drone Delivery alkalmazáshoz
A sorozat korábbi cikkei futó példaként egy drónkézbesítési szolgáltatást tárgyalnak. A forgatókönyvről és a kapcsolódó referencia-megvalósításról itt olvashat bővebben. Ez a példa ideális a repülőgép- és repülőgépipar számára.
Összefoglalva, ez az alkalmazás több mikroszolgáltatást határoz meg a szállítások drónnal történő ütemezéséhez. Amikor egy felhasználó új kézbesítést ütemez, az ügyfélkérés tartalmazza a kézbesítéssel kapcsolatos információkat, például az átvételi és a legördülő helyeket, valamint a csomagot, például a méretet és a súlyt. Ez az információ egy munkaegységet határoz meg.
A különböző háttérszolgáltatások a kérésben szereplő információk különböző részeit érdeklik, és különböző olvasási és írási profilokkal is rendelkeznek.
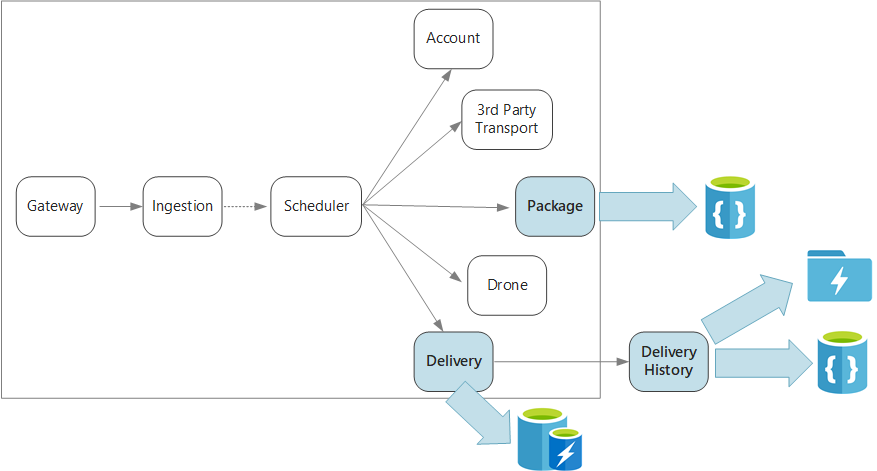
Kézbesítési szolgáltatás
A kézbesítési szolgáltatás minden jelenleg ütemezett vagy folyamatban lévő kézbesítésről tárol adatokat. Figyeli a drónok eseményeit, és nyomon követi a folyamatban lévő szállítások állapotát. Tartományi eseményeket is küld kézbesítési állapotfrissítésekkel.
A felhasználók várhatóan gyakran ellenőrzik a kézbesítés állapotát, amíg a csomagjukra várnak. Ezért a kézbesítési szolgáltatás olyan adattárat igényel, amely az átviteli sebességet (olvasást és írást) helyezi előtérbe a hosszú távú tárolás során. A kézbesítési szolgáltatás nem végez összetett lekérdezéseket vagy elemzéseket, egyszerűen lekéri az adott kézbesítés legújabb állapotát. A kézbesítési szolgáltatás csapata az Azure Cache for Redist választotta a magas olvasási-írási teljesítmény érdekében. A Redisben tárolt információk viszonylag rövid élettartamúak. A kézbesítés befejezése után a Kézbesítési előzmények szolgáltatás a rekordrendszer.
Kézbesítési előzmények szolgáltatás
A Kézbesítési előzmények szolgáltatás figyeli a kézbesítési állapot eseményeit a kézbesítési szolgáltatásból. Ezeket az adatokat hosszú távú tárolóban tárolja. Ehhez az előzményadatokhoz két különböző használati eset van, amelyek eltérő adattárolási követelményekkel rendelkeznek.
Az első forgatókönyv az adatok összesítése adatelemzés céljából az üzlet optimalizálása vagy a szolgáltatás minőségének javítása érdekében. Vegye figyelembe, hogy a Kézbesítési előzmények szolgáltatás nem végzi el az adatok tényleges elemzését. Csak a betöltésért és a tárolásért felelős. Ebben a forgatókönyvben a tárterületet nagy adatkészletek adatelemzésére kell optimalizálni, sémaalapú olvasási megközelítéssel, különböző adatforrások elhelyezéséhez. Az Azure Data Lake Store kiválóan alkalmas erre a forgatókönyvre. A Data Lake Store egy Apache Hadoop fájlrendszer, amely kompatibilis a Hadoop Elosztott fájlrendszerrel (HDFS), és az adatelemzési forgatókönyvek teljesítményére van hangolva.
A másik forgatókönyv az, hogy a felhasználók megtekinthetik a kézbesítés előzményeit a kézbesítés befejezése után. Az Azure Data Lake nincs erre a forgatókönyvre optimalizálva. Az optimális teljesítmény érdekében a Microsoft azt javasolja, hogy idősoros adatokat tároljunk a Data Lake-ben a dátum szerint particionált mappákban. (Lásd: Az Azure Data Lake Store teljesítményének finomhangolása). Ez a struktúra azonban nem optimális az egyes rekordok azonosító szerinti keresése esetén. Ha nem ismeri az időbélyeget is, az azonosító alapján történő kereséshez a teljes gyűjteményt be kell vizsgálnia. Ezért a Kézbesítési előzmények szolgáltatás az előzményadatok egy részét is tárolja az Azure Cosmos DB-ben a gyorsabb keresés érdekében. A rekordoknak nem kell határozatlan ideig az Azure Cosmos DB-ben maradniuk. A régebbi szállítmányok archiválhatók – például egy hónap után. Ezt egy alkalmi kötegfolyamat futtatásával teheti meg. A régebbi adatok archiválása csökkentheti a Cosmos DB költségeit, miközben az adatok továbbra is elérhetők maradnak a Data Lake-ből származó előzményjelentésekhez.
Csomagolási szolgáltatás
A Csomag szolgáltatás az összes csomagra vonatkozó információkat tárolja. A csomag tárolási követelményei a következők:
- Hosszú távú tárolás.
- Nagy mennyiségű csomagot képes kezelni, ami nagy írási teljesítményt igényel.
- Egyszerű lekérdezések támogatása csomagazonosító alapján. Nincs összetett illesztés vagy hivatkozási integritásra vonatkozó követelmény.
Mivel a csomagadatok nem relációsak, a dokumentumorientált adatbázis megfelelő, és az Azure Cosmos DB horizontális gyűjtemények használatával nagy átviteli sebességet érhet el. A Csomagszolgáltatáson dolgozó csapat ismeri a MEAN vermet (MongoDB, Express.js, AngularJS és Node.js), ezért az Azure Cosmos DB-hez készült MongoDB API-t választják. Így kihasználhatják a MongoDB-vel kapcsolatos meglévő tapasztalataikat, miközben kihasználhatják az Azure Cosmos DB előnyeit, amely egy felügyelt Azure-szolgáltatás.
További lépések
Megismerheti azokat a tervezési mintákat, amelyek segíthetnek a mikroszolgáltatás-architektúra néhány gyakori kihívásának megoldásában.