Kubernetes-alkalmazás fejlesztése az Azure SQL Database-hez
A következőre vonatkozik:![]() Azure SQL Database
Azure SQL Database
Ebben az oktatóanyagban megtudhatja, hogyan fejleszthet modern alkalmazást Python, Docker Containers, Kubernetes és Azure SQL Database használatával.
A modern alkalmazásfejlesztésnek számos kihívása van. Az előtérbeli "verem" kiválasztásától kezdve az adattároláson és a különböző konkurens szabványok feldolgozásán keresztül a legmagasabb szintű biztonság és teljesítmény biztosításán keresztül a fejlesztőknek gondoskodniuk kell arról, hogy az alkalmazás méretezhető és jól teljesít, és több platformon is támogatott legyen. Az utolsó követelmény esetében az alkalmazás tárolótechnológiákba, például a Dockerbe való csatlakoztatása és több tároló üzembe helyezése a Kubernetes platformon most már de rigueur az alkalmazásfejlesztésben.
Ebben a példában a Python, a Docker Containers és a Kubernetes használatával ismerkedünk meg – mind a Microsoft Azure platformon. A Kubernetes használata azt jelenti, hogy rugalmasan használhat helyi környezeteket vagy akár más felhőket is az alkalmazás zökkenőmentes és konzisztens üzembe helyezéséhez, és lehetővé teszi a többfelhős üzembe helyezést a még nagyobb rugalmasság érdekében. A Microsoft Azure SQL Database szolgáltatásalapú, skálázható, rendkívül rugalmas és biztonságos környezethez is használható lesz az adattároláshoz és -feldolgozáshoz. Valójában sok esetben más alkalmazások már gyakran használják a Microsoft Azure SQL Database-t, és ez a mintaalkalmazás használható az adatok további felhasználására és bővítésére.
Ez a példa hatóköre meglehetősen átfogó, de a legegyszerűbb alkalmazást, adatbázist és üzembe helyezést használja a folyamat szemléltetésére. Ezt a mintát sokkal robusztusabbá teheti, még akkor is, ha a legújabb technológiákat használja a visszaadott adatokhoz. Ez egy hasznos tanulási eszköz, amellyel mintát hozhat létre más alkalmazásokhoz.
A Python, a Docker Containers, a Kubernetes és az AdventureWorksLT mintaadatbázis használata gyakorlati példában
Az AdventureWorks (fiktív) vállalat egy olyan adatbázist használ, amely adatokat tárol az értékesítésről és marketingről, a termékekről, az ügyfelekről és a gyártásról. Emellett olyan nézeteket és tárolt eljárásokat is tartalmaz, amelyek összekapcsolják a termékekkel kapcsolatos információkat, például a termék nevét, kategóriáját, árát és rövid leírását.
Az AdventureWorks fejlesztői csapata létre szeretne hozni egy megvalósíthatósági igazolást (PoC), amely adatokat ad vissza az AdventureWorksLT adatbázis nézetéből, és REST API-ként elérhetővé teszi őket. Ezzel a poC-vel a fejlesztői csapat egy méretezhetőbb és többfelhős használatra kész alkalmazást hoz létre az értékesítési csapat számára. A Microsoft Azure platformot választották az üzembe helyezés minden aspektusához. A poC a következő elemeket használja:
- Egy Python-alkalmazás, amely a Flask-csomagot használja a fej nélküli webes üzembe helyezéshez.
- Docker-tárolók kód- és környezetelkülönítéshez, privát beállításjegyzékben tárolva, hogy a teljes vállalat újra felhasználhassa az alkalmazástárolókat a jövőbeli projektekben, így időt és pénzt takaríthat meg.
- A Kubernetes a könnyű üzembe helyezés és a skálázás érdekében, valamint a platformzárolás elkerülése érdekében.
- Microsoft Azure SQL Database méret, teljesítmény, méretezés, automatikus kezelés és biztonsági mentés kiválasztásához a relációs adattárolás és -feldolgozás mellett a legmagasabb biztonsági szinten.
Ebben a cikkben a teljes megvalósíthatósági projekt létrehozásának folyamatát ismertetjük. Az alkalmazás létrehozásának általános lépései a következők:
- Előfeltételek beállítása
- Az alkalmazás létrehozása
- Docker-tároló létrehozása az alkalmazás üzembe helyezéséhez és teszteléséhez
- Azure Container Service (ACS) beállításjegyzék létrehozása és a tároló betöltése az ACS-beállításjegyzékbe
- Az Azure Kubernetes Service (AKS) környezetének létrehozása
- Az alkalmazástároló üzembe helyezése az ACS-beállításjegyzékből az AKS-be
- Az alkalmazás tesztelése
- A fölöslegessé vált elemek eltávolítása
Előfeltételek
Ebben a cikkben számos értéket kell lecserélni. Győződjön meg arról, hogy minden lépésnél következetesen lecseréli ezeket az értékeket. Előfordulhat, hogy meg szeretne nyitni egy szövegszerkesztőt, és be szeretné állítani a megfelelő értékeket a megvalósíthatósági ellenőrzés projekt során:
ReplaceWith_AzureSubscriptionName: Cserélje le ezt az értéket a meglévő Azure-előfizetés nevére.ReplaceWith_PoCResourceGroupName: Cserélje le ezt az értéket a létrehozni kívánt erőforráscsoport nevére.ReplaceWith_AzureSQLDBServerName: Cserélje le ezt az értéket az Azure Portallal létrehozott Azure SQL Database logikai kiszolgáló nevére.ReplaceWith_AzureSQLDBSQLServerLoginName: Cserélje le ezt az értéket az Azure Portalon létrehozott SQL Server-felhasználónév értékére.ReplaceWith_AzureSQLDBSQLServerLoginPassword: Cserélje le ezt az értéket az Azure Portalon létrehozott SQL Server-felhasználói jelszó értékére.ReplaceWith_AzureSQLDBDatabaseName: Cserélje le ezt az értéket az Azure Portallal létrehozott Azure SQL Database nevére.ReplaceWith_AzureContainerRegistryName: Cserélje le ezt az értéket a létrehozni kívánt Azure Container Registry nevére.ReplaceWith_AzureKubernetesServiceName: Cserélje le ezt az értéket a létrehozni kívánt Azure Kubernetes Service nevére.
Az AdventureWorks fejlesztői Windows, Linux és Apple rendszerek kombinációját használják a fejlesztéshez, ezért a Visual Studio Code-ot használják környezetükként, a gitet pedig a forráskövetéshez, mindkettő platformfüggetlenül fut.
A poC esetében a csapatnak a következő előfeltételekre van szüksége:
Python, pip és csomagok – A fejlesztői csapat a Python programozási nyelvet választja szabványként ehhez a webalapú alkalmazáshoz. Jelenleg a 3.9-es verziót használják, de a PoC-hez szükséges csomagokat támogató bármely verzió elfogadható.
- A Python 3.9-es verzióját letöltheti python.org.
A csapat a
pyodbccsomagot adatbázis-hozzáférésre használja.- A pyodbc-csomagot pip parancsokkal telepítheti.
- Szükség lehet a Microsoft ODBC Driver szoftverre is, ha még nincs telepítve.
A csapat a csomagot használja a
ConfigParserkonfigurációs változók vezérléséhez és beállításához.- A configparser-csomagot pip parancsokkal telepítheti.
A csapat a Flask-csomagot használja az alkalmazás webes felületéhez.
- Telepítheti a Flask-kódtár Python-verzióját.
Ezután a csapat telepítette az Azure CLI eszközt, amely könnyen azonosítható szintaxissal
az. Ez a platformfüggetlen eszköz lehetővé teszi a poC parancssori és szkriptelt megközelítését, hogy a módosítások és fejlesztések során megismételhesse a lépéseket.- Letöltheti és telepítheti az Azure CLI-eszközt.
Az Azure CLI beállításával a csapat bejelentkezik az Azure-előfizetésbe, és beállítja a PoC-hoz használt előfizetés nevét. Ezután gondoskodtak arról, hogy az Azure SQL Database-kiszolgáló és az adatbázis elérhető legyen az előfizetés számára:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameA Microsoft Azure-erőforráscsoport egy logikai tároló, amely egy Azure-megoldáshoz kapcsolódó erőforrásokat tartalmaz. Az azonos életciklussal rendelkező erőforrások általában ugyanahhoz az erőforráscsoporthoz lesznek hozzáadva, így könnyen üzembe helyezheti, frissítheti és törölheti őket csoportként. Az erőforráscsoport az erőforrások metaadatait tárolja, és megadhatja az erőforráscsoport helyét.
Az erőforráscsoportok az Azure Portal vagy az Azure CLI használatával hozhatók létre és kezelhetők. Az alkalmazásokhoz kapcsolódó erőforrások csoportosítására és az éles és nem termelési csoportokra, illetve a kívánt egyéb szervezeti struktúra csoportokra oszthatók.

Az alábbi kódrészletben láthatja az
azerőforráscsoport létrehozásához használt parancsot. A mintánkban az Azure eastusrégióját használjuk.az group create --name ReplaceWith_PoCResourceGroupName --location eastusA fejlesztői csapat létrehoz egy Azure SQL Database-adatbázist, amelyen telepítve van a
AdventureWorksLTmintaadatbázis, egy SQL-hitelesítésű bejelentkezés használatával.Az AdventureWorks szabványosított a Microsoft SQL Server relációsadatbázis-kezelési rendszerplatformján, és a fejlesztői csapat a helyi telepítés helyett egy felügyelt szolgáltatást szeretne használni az adatbázishoz. Az Azure SQL Database használatával ez a felügyelt szolgáltatás teljesen kódkompatibilis lehet mindenhol, ahol az SQL Server-motort futtatják: a helyszínen, tárolóban, Linuxon vagy Windowson, vagy akár az eszközök internetes hálózatában (IoT) is.
A létrehozás során az Azure Management Portal használatával beállították az alkalmazás tűzfalát a helyi fejlesztőgépre, és módosították az itt látható alapértelmezett beállítást az összes Azure-szolgáltatás engedélyezéséhez, valamint lekérték a kapcsolati hitelesítő adatokat is.
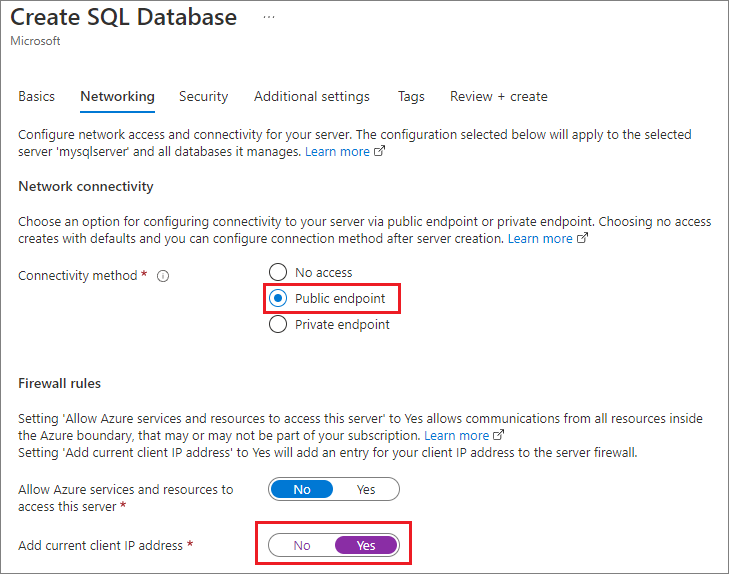
Ezzel a módszerrel az adatbázis egy másik régióban vagy akár egy másik előfizetésben is elérhető lehet.
A csapat beállított egy SQL-hitelesítésű bejelentkezést a teszteléshez, de ezt a döntést biztonsági felülvizsgálatban fogja újra áttekinteni.
A csapat ugyanazt a PoC-erőforráscsoportot használva használta a poC mintaadatbázisát
AdventureWorksLT. Ne aggódjon, az oktatóanyag végén megtisztítjuk az új PoC-erőforráscsoport összes erőforrását.Az Azure SQL Database üzembe helyezéséhez használhatja az Azure Portalt. Az Azure SQL Database létrehozásakor a További beállítások lapon válassza a Meglévő adatok használata lehetőséget, és válassza a Minta lehetőséget.

Végül az új Azure SQL Database Címkék lapján a fejlesztői csapat címkék metaadatait adta meg ehhez az Azure-erőforráshoz, például Tulajdonos vagy ServiceClass vagy WorkloadName.

Az alkalmazás létrehozása
Ezután a fejlesztői csapat létrehozott egy egyszerű Python-alkalmazást, amely kapcsolatot nyit meg az Azure SQL Database-hez, és visszaadja a termékek listáját. Ezt a kódot összetettebb függvények váltják fel, és az alkalmazásmegoldások robusztus, jegyzékalapú megközelítése érdekében a Kubernetes Podokban üzembe helyezett több alkalmazást is tartalmazhatnak éles környezetben.
A csapat létrehozott egy egyszerű szöveges fájlt, amely a kiszolgálókapcsolatok és egyéb információk változóinak tárolására szolgál
.env. Apython-dotenvkódtár használatával ezután elkülöníthetik a változókat a Python Code-tól. Ez egy gyakori módszer a titkos kódok és egyéb információk kódból való kivételével.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseNameFigyelem
Az egyértelműség és az egyszerűség kedvéért ez az alkalmazás egy Pythonból beolvasott konfigurációs fájlt használ. Mivel a kód a tárolóval együtt lesz üzembe helyezve, lehetséges, hogy a kapcsolati információk a tartalomból származnak. Alaposan át kell gondolnia a biztonság, a kapcsolatok és a titkos kódok használatának különböző módszereit, és meg kell határoznia az alkalmazáshoz használni kívánt legjobb szintet és mechanizmust. Mindig válassza ki a legmagasabb szintű biztonságot, és akár több szintet is, hogy az alkalmazás biztonságos legyen. A titkos adatok, például a kapcsolati sztring és hasonlók többféle módon is használhatóak, és az alábbi lista néhány ilyen lehetőséget mutat.
További információ: Azure SQL Database security.
- A Titkos kódok Pythonban való használatának másik módja a python-titkos kódtár használata.
- Tekintse át a Docker biztonsági és titkos kulcsokat.
- Kubernetes-titkos kódok áttekintése.
- A Microsoft Entra (korábbi nevén Azure Active Directory) hitelesítésével kapcsolatos további tudnivalókat is megismerheti.
A csapat ezután megírta a PoC alkalmazást, és meghívta.
app.pyA következő szkript a következő lépéseket hajtja végre:
- Állítsa be a kódtárakat a konfigurációhoz és az alap webes felületekhez.
- Töltse be a változókat a
.envfájlból. - Hozza létre a Flask-RESTful alkalmazást.
- Az Azure SQL Database kapcsolati adatainak lekérése a
config.inifájlértékekkel. - Hozzon létre kapcsolatot az Azure SQL Database-hez a
config.inifájlértékek használatával. - Csatlakozás az Azure SQL Database-be a
pyodbccsomag használatával. - Hozza létre az SQL-lekérdezést az adatbázison való futtatáshoz.
- Hozza létre azt az osztályt, amely az API-ból származó adatok visszaadására szolgál.
- Állítsa az API-végpontot az osztályra
Products. - Végül indítsa el az alkalmazást az alapértelmezett Flask 5000-es porton.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://learn.microsoft.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)Ellenőrizték, hogy az alkalmazás helyileg fut-e, és egy lapot ad vissza.
http://localhost:5000/products
Fontos
Éles alkalmazások létrehozásakor ne használja a rendszergazdai fiókot az adatbázis eléréséhez. További információkért olvassa el , hogyan állíthat be fiókot az alkalmazáshoz. A cikkben szereplő kód egyszerűbb, így gyorsan elkezdheti a Pythont és a Kubernetes-t használó alkalmazásokat az Azure-ban.
Reálisabban használhat egy csak olvasható engedélyekkel rendelkező, tartalmazott adatbázis-felhasználót, vagy egy felhasználó által hozzárendelt felügyelt identitáshoz csatlakoztatott bejelentkezési vagy tárolt adatbázis-felhasználót írásvédett engedélyekkel.
További információkért tekintse át az API Pythonnal és Azure SQL Database-sel való létrehozásának teljes példáját.

Az alkalmazás üzembe helyezése Docker-tárolóban
A tároló egy fenntartott, védett terület egy számítástechnikai rendszerben, amely elkülönítést és beágyazást biztosít. Tároló létrehozásához használjon jegyzékfájlt, amely egyszerűen egy szöveges fájl, amely leírja a tartalmazni kívánt bináris fájlokat és kódot. Tároló futtatókörnyezet (például Docker) használatával létrehozhat egy bináris rendszerképet, amely tartalmazza a futtatni kívánt összes fájlt, és amelyekre hivatkozni szeretne. Innen "futtathatja" a bináris rendszerképet, amelyet tárolónak nevezünk, amelyre úgy hivatkozhat, mintha teljes számítástechnikai rendszer lenne. Ez egy kisebb, egyszerűbb módszer az alkalmazás futtatókörnyezetének és környezetének absztrakciójára, mint egy teljes virtuális gép használata. További információ: Tárolók és Docker.
A csapat egy DockerFile -val (a jegyzékfájllal) kezdte, amely a csapat által használni kívánt elemeket rétegzi. Először egy alapSzintű Python-lemezképet használnak, amelyen már telepítve vannak a pyodbc kódtárak, majd az összes parancsot futtatják, amely ahhoz szükséges, hogy az előző lépésben tartalmazza a programot és a konfigurációs fájlt.
A következő Dockerfile a következő lépéseket tartalmazza:
- Kezdje egy olyan tároló bináris fájllal, amely már rendelkezik Pythonnal, és
pyodbctelepítve van. - Hozzon létre egy munkakönyvtárat az alkalmazáshoz.
- Másolja az összes kódot az aktuális könyvtárból a
WORKDIR. - Telepítse a szükséges kódtárakat.
- A tároló elindítása után futtassa az alkalmazást, és nyissa meg az összes TCP/IP-portot.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
A fájl helyén a csapat egy parancssorba esett a kódolási könyvtárban, és a következő kódot futtatva létrehozta a bináris rendszerképet a jegyzékből, majd egy másik parancsot a tároló elindításához:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
A csapat ismét teszteli a http://localhost:5000/products hivatkozást, hogy a tároló hozzáférhessen az adatbázishoz, és a következő visszatérés jelenik meg:

A rendszerkép üzembe helyezése Docker-beállításjegyzékben
A tároló már működik, de csak a fejlesztő gépén érhető el. A fejlesztői csapat elérhetővé szeretné tenni ezt az alkalmazásképet a vállalat többi tagja számára, majd a Kubernetes számára az éles üzembe helyezéshez.
A Tárolólemezképek tárolóterületét adattárnak nevezzük, és a tárolólemezképek nyilvános és privát adattárai is lehetnek. Az AdvenureWorks valójában nyilvános rendszerképet használt a Python-környezethez a Dockerfile-ban.
A csapat szeretné szabályozni a rendszerképhez való hozzáférést, és ahelyett, hogy a weben helyezné el, úgy döntenek, hogy saját maguk szeretnék üzemeltetni, hanem a Microsoft Azure-ban, ahol teljes mértékben szabályozhatják a biztonságot és a hozzáférést. A Microsoft Azure Container Registryről itt olvashat bővebben.
A parancssorba visszatérve a fejlesztői csapat egy tárolóregisztrációs szolgáltatás hozzáadását, egy felügyeleti fiók engedélyezését, névtelen "lekérések" beállítását használja az CLI a tesztelési fázisban, és beállít egy bejelentkezési környezetet a beállításjegyzékben:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
Ezt a környezetet a rendszer a következő lépésekben fogja használni.
A helyi Docker-rendszerkép címkézése a feltöltés előkészítéséhez
A következő lépés a helyi alkalmazás tárolórendszerképének elküldése az Azure Container Registry (ACR) szolgáltatásnak, hogy az elérhető legyen a felhőben.
- A következő példaszkriptben a csapat a Docker-parancsokkal listázhatja a képeket a gépen.
- A segédprogrammal
az CLIlistázzák a képeket az ACR szolgáltatásban. - A Docker paranccsal "címkézik" a képet az előző lépésben létrehozott ACR célnevével, és beállítanak egy verziószámot a megfelelő DevOpshoz.
- Végül ismét listázzák a helyi rendszerkép adatait, hogy a címke megfelelően legyen alkalmazva.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
A megírt és tesztelt kód, a Dockerfile, a rendszerkép és a tároló futtatása és tesztelése, az ACR szolgáltatás beállítása és az összes alkalmazott címke használatával a csapat feltöltheti a képet az ACR szolgáltatásba.
A docker "push" paranccsal küldik el a fájlt, majd a az CLI segédprogrammal biztosítják a rendszerkép betöltését:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Deploy to Kubernetes
A csapat egyszerűen futtathat tárolókat, és üzembe helyezheti az alkalmazást helyszíni és felhőbeli környezetekben. Szeretnék azonban az alkalmazás több példányát hozzáadni a skálázáshoz és a rendelkezésre álláshoz, más, különböző feladatokat végző tárolókat hozzáadni, valamint monitorozást és rendszerezést hozzáadni a teljes megoldáshoz.
A tárolók egy teljes megoldásba való csoportosítása érdekében a csapat úgy döntött, hogy a Kubernetes-t használja. A Kubernetes a helyszínen és az összes nagyobb felhőplatformon fut. A Microsoft Azure teljes körű felügyelt kubernetes-környezettel rendelkezik, amelyet Azure Kubernetes Service-nek (AKS) hívunk. További információ az AKS-ről az Azure-beli Kubernetes bemutatása című képzési tervvel.
A segédprogram használatával a az CLI csapat hozzáadja az AKS-t a korábban létrehozott erőforráscsoporthoz. Egyetlen az paranccsal a fejlesztői csapat a következő lépéseket hajtja végre:
- Két "csomópont" vagy számítási környezet hozzáadása a rugalmasság érdekében a tesztelési fázisban
- SSH-kulcsok automatikus létrehozása a környezethez való hozzáféréshez
- Csatolja az előző lépésekben létrehozott ACR szolgáltatást, hogy az AKS-fürt megtalálhassa az üzembe helyezéshez használni kívánt lemezképeket
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
A Kubernetes egy parancssori eszközt használ egy úgynevezett fürt kubectleléréséhez és vezérléséhez. A csapat a az CLI segédprogrammal tölti le és telepíti az kubectl eszközt:
az aks install-cli
Mivel jelenleg van kapcsolatuk az AKS-sel, megkérhetik, hogy küldje el az SSH-kulcsokat a segédprogram végrehajtásakor kubectl használandó kapcsolathoz:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
Ezek a kulcsok egy .config nevű fájlban vannak tárolva a felhasználó könyvtárában. Ezzel a biztonsági környezettel a csapat kubectl get nodes a fürt csomópontjait jeleníti meg:
kubectl get nodes
Most a csapat az az CLI eszközzel listázhatja a képeket az ACR szolgáltatásban:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
Most már létrehozhatják a Kubernetes által az üzembe helyezés vezérléséhez használt jegyzékfájlt. Ez egy yaml formátumban tárolt szövegfájl. A fájlban a következő jegyzetekkel ellátott szöveg található flask2sql.yaml :
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCIP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
A flask2sql.yaml fájl definiálása után a csapat üzembe helyezheti az alkalmazást a futó AKS-fürtön. Ez a kubectl apply paranccsal történik, amely mint emlékszik, továbbra is rendelkezik a fürt biztonsági környezetével. Ezután a rendszer elküldi a kubectl get service parancsot, hogy figyelje a fürt felépítését.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
Néhány pillanat múlva a "watch" parancs egy külső IP-címet ad vissza. Ekkor a csapat a CTRL-C billentyűkombinációt lenyomva megszakítja a figyelési parancsot, és rögzíti a terheléselosztó külső IP-címét.
Az alkalmazás tesztelése
Az utolsó lépésben beszerzett IP-cím (végpont) használatával a csapat ellenőrzi, hogy a helyi alkalmazás és a Docker-tároló kimenete megegyezik-e:
A fölöslegessé vált elemek eltávolítása
Az alkalmazás létrehozása, szerkesztése, dokumentálása és tesztelése után a csapat mostantól "lebonthatja" az alkalmazást. Ha mindent egyetlen erőforráscsoportban tart a Microsoft Azure-ban, egyszerűen törölheti a PoC-erőforráscsoportot a az CLI segédprogrammal:
az group delete -n ReplaceWith_PoCResourceGroupName -y
Megjegyzés:
Ha az Azure SQL Database-t egy másik erőforráscsoportban hozta létre, és már nincs rá szüksége, az Azure Portal használatával törölheti.
A PoC-projektet vezető csapattag a Microsoft Windowst használja munkaállomásként, és meg szeretné őrizni a Kubernetes titkos fájlját, de aktív helyként el szeretné távolítani a rendszerből. Egyszerűen átmásolhatják a fájlt egy config.old szövegfájlba, majd törölhetik:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: