Modell testreszabása (4.0-s verzió – előzetes verzió)
A modell testreszabása lehetővé teszi egy speciális képelemzési modell betanítása saját használati esethez. Az egyéni modellek képbesorolást (a teljes képre vonatkozó címkéket) vagy objektumészlelést végezhetnek (a címkék a kép adott területeire vonatkoznak). Az egyéni modell létrehozása és betanítása után a Vision-erőforráshoz tartozik, és az Analyze Image API használatával hívhatja meg.
A modell testreszabásának gyors és egyszerű implementálása egy rövid útmutatót követve:
Fontos
Egyéni modellt a Custom Vision szolgáltatással vagy a Képelemzés 4.0 szolgáltatással taníthat be a modell testreszabásával. Az alábbi táblázat a két szolgáltatást hasonlítja össze.
| Területeken | Custom Vision szolgáltatás | Image Analysis 4.0 szolgáltatás | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tevékenységek | Képbesorolási objektumészlelés |
Képbesorolási objektumészlelés |
||||||||||||||||||||||||||||||||||||
| Alapmodell | CNN | Transzformátormodell | ||||||||||||||||||||||||||||||||||||
| Címkézés | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Webportál | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Kódtárak | REST, SDK | REST, Python-minta | ||||||||||||||||||||||||||||||||||||
| Minimális betanítási adatok | 15 kép kategóriánként | 2-5 kép kategóriánként | ||||||||||||||||||||||||||||||||||||
| Adattárolás betanítása | Feltöltve a szolgáltatásba | Az ügyfél Blob Storage-fiókja | ||||||||||||||||||||||||||||||||||||
| Modell hosztolása | Felhő és peremhálózat | Csak felhőalapú üzemeltetés, peremhálózati tároló üzemeltetése | ||||||||||||||||||||||||||||||||||||
| AI-minőség |
|
|
||||||||||||||||||||||||||||||||||||
| Árképzés | A Custom Vision díjszabása | Képelemzés díjszabása |
Forgatókönyv-összetevők
A modell testreszabási rendszerének fő összetevői a betanítási képek, a COCO-fájl, az adathalmaz-objektum és a modellobjektum.
Betanítási képek
A betanítási képeknek több példát kell tartalmazniuk az észlelni kívánt címkékre. Emellett érdemes néhány további képet is összegyűjteni, hogy tesztelje a modellt a betanítása után. A rendszerképeket egy Azure Storage-tárolóban kell tárolni, hogy elérhető legyen a modell számára.
A modell hatékony betanítása érdekében használjon vizuális változatosságú képeket. Válassza ki a következőtől eltérő képeket:
- kamera szöge
- Világítás
- Háttér
- vizuális stílus
- egyéni/csoportosított tárgy(ok)
- Méret
- típus
Emellett győződjön meg arról, hogy az összes betanítási rendszerkép megfelel a következő feltételeknek:
- A képet JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF vagy MPO formátumban kell bemutatni.
- A kép fájlméretének 20 megabájtnál (MB) kisebbnek kell lennie.
- A kép méretének 50 x 50 képpontnál nagyobbnak és 16 000 x 16 000 képpontnál kisebbnek kell lennie.
COCO-fájl
A COCO-fájl az összes betanítási lemezképre hivatkozik, és társítja őket a címkézési adataikkal. Objektumészlelés esetén az egyes képeken az egyes címkék határolókeret-koordinátáit adta meg. Ennek a fájlnak COCO formátumban kell lennie, amely egy adott JSON-fájltípus. A COCO-fájlt ugyanabban az Azure Storage-tárolóban kell tárolni, mint a betanítási rendszerképeket.
Tipp.
Tudnivalók a COCO-fájlokról
A COCO-fájlok meghatározott kötelező mezőkkel rendelkező JSON-fájlok: "images", "annotations"és "categories". A COCO-mintafájl így fog kinézni:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO-fájlmezőre vonatkozó referencia
Ha saját COCO-fájlt hoz létre az alapoktól, győződjön meg arról, hogy az összes szükséges mező a megfelelő részletekkel van kitöltve. Az alábbi táblázatok egy COCO-fájl minden mezőjét ismertetik:
"képek"
| Kulcs | Típus | Leírás | Kötelező? |
|---|---|---|---|
id |
egész szám | Egyedi képazonosító, 1-től kezdve | Igen |
width |
egész szám | A kép szélessége képpontban | Igen |
height |
egész szám | A kép magassága képpontban | Igen |
file_name |
húr | A kép egyedi neve | Igen |
absolute_url vagy coco_url |
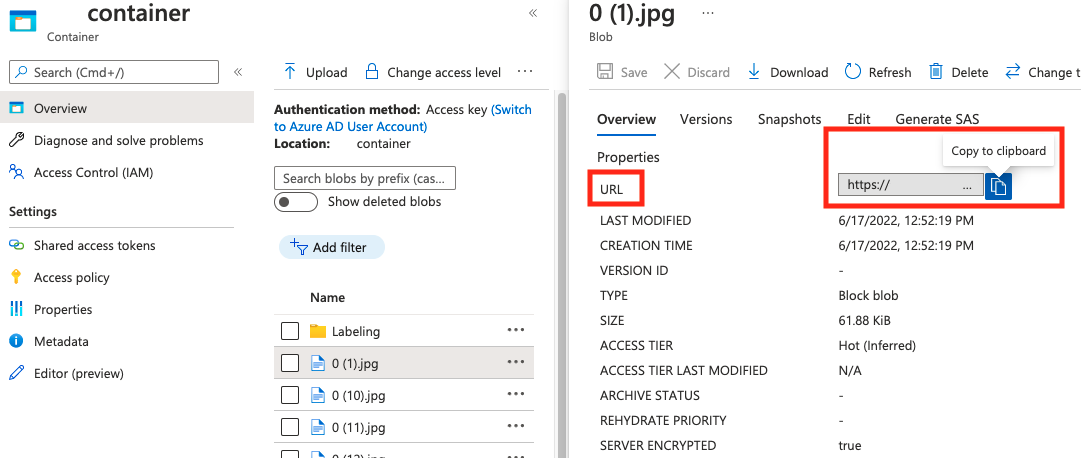
húr | A kép elérési útja egy blobtárolóban lévő blob abszolút URI-jaként. A Vision-erőforrásnak engedéllyel kell rendelkeznie a széljegyzetfájlok és az összes hivatkozott képfájl olvasásához. | Igen |
Az érték absolute_url a blobtároló tulajdonságaiban található:
"széljegyzetek"
| Kulcs | Típus | Leírás | Kötelező? |
|---|---|---|---|
id |
egész szám | A széljegyzet azonosítója | Igen |
category_id |
egész szám | A szakaszban meghatározott categories kategória azonosítója |
Igen |
image_id |
egész szám | A kép azonosítója | Igen |
area |
egész szám | "Szélesség" x "Magasság" értéke (a ) harmadik és negyedik értéke bbox |
Nem |
bbox |
list[float] | A határolókeret (0–1) relatív koordinátái a "Bal", "Felső", "Szélesség", "Magasság" sorrendben | Igen |
"kategóriák"
| Kulcs | Típus | Leírás | Kötelező? |
|---|---|---|---|
id |
egész szám | Egyedi azonosító minden kategóriához (címkeosztályhoz). Ezeknek szerepelniük kell a annotations szakaszban. |
Igen |
name |
húr | A kategória neve (címkeosztály) | Igen |
COCO-fájl ellenőrzése
A Python-mintakód segítségével ellenőrizheti a COCO-fájlok formátumát.
Adathalmaz-objektum
Az Adathalmaz-objektum a társításfájlra hivatkozó képelemzési szolgáltatás által tárolt adatstruktúra. A modell létrehozása és betanítása előtt létre kell hoznia egy Adathalmaz-objektumot .
Modellobjektum
A Modell objektum egy egyéni modellt képviselő adatstruktúra, amelyet a Képelemzési szolgáltatás tárol. Az első betanítás elvégzéséhez társítani kell egy adatkészlettel . A betanítás után lekérdezheti a modellt az Analyze Image API-hívás lekérdezési paraméterében model-namea nevének megadásával.
Kvótakorlátok
Az alábbi táblázat az egyéni modellprojektek méretezési korlátait ismerteti.
| Kategória | Általános képosztályozó | Általános objektumérzékelő |
|---|---|---|
| Maximális # betanítási órák | 288 (12 nap) | 288 (12 nap) |
| Max # betanítási képek | 1,000,000 | 200,000 |
| Maximális # kiértékelési képek | 100 000 | 100 000 |
| Min # betanítási képek kategóriánként | 2 | 2 |
| Maximális # címkék képenként | többosztályos: 1 | N.a. |
| Maximális # régiók képenként | N.a. | 1000 |
| Maximális # kategóriák | 2500 | 1000 |
| Minimális # kategóriák | 2 | 0 |
| Maximális képméret (betanítás) | 20 MB | 20 MB |
| Maximális képméret (előrejelzés) | Szinkronizálás: 6 MB, Köteg: 20 MB | Szinkronizálás: 6 MB, Köteg: 20 MB |
| Maximális képszélesség/magasság (Betanítás) | 10,240 | 10,240 |
| Minimális képszélesség/magasság (előrejelzés) | 50 | 50 |
| Elérhető régiók | USA 2. nyugati régiója, USA keleti régiója, Nyugat-Európa | USA 2. nyugati régiója, USA keleti régiója, Nyugat-Európa |
| Elfogadott képtípusok | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Gyakori kérdések
Miért hiúsul meg a COCO-fájl importálása a Blob Storage-ból való importáláskor?
A Microsoft jelenleg egy olyan problémával foglalkozik, amely miatt a COCO-fájlok importálása nagy adathalmazokkal meghiúsul, amikor a Vision Studióban kezdeményezik. A nagy adathalmazok betanítása érdekében javasoljuk, hogy inkább a REST API-t használja.
Miért tart a betanítás hosszabb vagy rövidebb a megadott költségvetésnél?
A megadott betanítási költségkeret a kalibrált számítási idő, nem pedig a fali óra. A különbség néhány gyakori oka a következők:
A megadott költségvetésnél hosszabb:
- A képelemzés nagy betanítási forgalmat tapasztal, és a GPU-erőforrások szűkösek lehetnek. Előfordulhat, hogy a feladat várakozik az üzenetsorban, vagy a betanítás során várakoztatva lesz.
- A háttérrendszer betanítási folyamata váratlan hibákba ütközött, ami újrapróbálkozási logikát eredményezett. A sikertelen futtatások nem használják fel a költségvetést, de ez általában hosszabb betanítási időt eredményezhet.
- Az adatok a Vision-erőforrástól eltérő régióban lesznek tárolva, ami hosszabb adatátviteli időt eredményez.
Rövidebb, mint a megadott költségvetés: Az alábbi tényezők felgyorsítják a betanítást, ha több költségkeretet használnak egy bizonyos falióra-időpontban.
- A képelemzés néha az adatoktól függően több GPU-val is be van edve.
- A képelemzés néha egyszerre több GPU-n is több feltárási próbát képez ki.
- A képelemzés néha premier (gyorsabb) GPU-termékváltozatokat használ a betanuláshoz.
Miért hiúsul meg a betanítás, és mit kell tennem?
A betanítás sikertelenségének néhány gyakori oka a következő:
diverged: A betanítás nem tud értelmes dolgokat tanulni az adataiból. Néhány gyakori ok:- Az adatok nem elegendőek: további adatok megadása segíthet.
- Az adatok rossz minőségűek: ellenőrizze, hogy a képek felbontása alacsony-e, szélsőséges méretarányok vannak-e, vagy hogy helytelenek-e a széljegyzetek.
notEnoughBudget: A megadott költségvetés nem elegendő a betanításra használt adathalmaz és modelltípus méretéhez. Adjon meg nagyobb költségvetést.datasetCorrupt: Ez általában azt jelenti, hogy a megadott képek nem érhetők el, vagy a széljegyzetfájl nem megfelelő formátumú.datasetNotFound: az adatkészlet nem találhatóunknown: Ez lehet egy háttérbeli probléma. Lépjen kapcsolatba a vizsgálat támogatásával.
Milyen metrikákat használ a modellek kiértékeléséhez?
A rendszer a következő metrikákat használja:
- Képbesorolás: Átlagos pontosság, 1. pontosság, 5. pontosság
- Objektumészlelés: Átlagos pontosság @ 30, Átlag pontosság átlaga @ 50, Átlagos átlag pontosság @ 75
Miért nem sikerül az adathalmaz regisztrációja?
Az API-válaszoknak elég informatívnak kell lenniük. Ezek a következők:
DatasetAlreadyExists: Létezik egy azonos nevű adatkészletDatasetInvalidAnnotationUri: "Érvénytelen URI-t adtak meg a széljegyzet URI-k között az adathalmaz-regisztrációs időpontban.
Hány kép szükséges az ésszerű/jó/legjobb modellminőséghez?
Bár a Firenze-modellek nagy néhány lövéses képességgel rendelkeznek (a modell teljesítménye korlátozott adathozzáérhetővé tétel mellett érhető el), általában több adat teszi jobbá és robusztusabbá a betanított modellt. Egyes forgatókönyvek kevés adatot igényelnek (például egy alma banánnal való besorolását), míg másoknak többre van szükségük (például 200 rovar észlelésére egy esőerdőben). Ez megnehezíti egyetlen javaslat ajánlását.
Ha az adatcímkézés költségvetése korlátozott, az ajánlott munkafolyamat az alábbi lépések megismétlése:
Képek összegyűjtése
Nosztályonként, aholNkönnyen gyűjthet képeket (példáulN=3)Modell betanítása és tesztelése a kiértékelési csoportban.
Ha a modell teljesítménye:
- Elég jó (a teljesítmény jobb, mint a várt vagy a korábbi kísérlethez közeli teljesítmény kevesebb összegyűjtött adattal): Itt állj le, és használd ezt a modellt.
- Nem jó (a teljesítmény még mindig az elvárás alatt van, vagy jobb, mint az előző kísérlet, és kevesebb adatot gyűjtöttek be ésszerű árréssel):
- Gyűjtsön össze további képeket minden osztályhoz – egy könnyen gyűjthető számot –, és térjen vissza a 2. lépéshez.
- Ha azt tapasztalja, hogy néhány iteráció után a teljesítmény nem javul tovább, az a következő lehet:
- ez a probléma nincs jól definiálva, vagy túl nehéz. Lépjen kapcsolatba velünk az eseti elemzéshez.
- a betanítási adatok gyenge minőségűek lehetnek: ellenőrizze, hogy nincsenek-e hibás széljegyzetek vagy nagyon alacsony képpontos képek.
Mennyi betanítási költségvetést kell megadnom?
Meg kell adnia a költségkeret felső határát, amelyet fel szeretne használni. Az Image Analysis egy AutoML-rendszert használ a háttérrendszerében, hogy kipróbáljon különböző modelleket és betanítási recepteket, hogy megtalálja a használati esethez legmegfelelőbb modellt. Minél több költségvetést kap, annál nagyobb az esélye, hogy jobb modellt találjon.
Az AutoML-rendszer automatikusan leáll, ha arra a következtetésre jut, hogy nincs szükség további próbálkozásra, még akkor sem, ha még mindig van költségvetés. Így nem mindig kimeríti a megadott költségvetést. Garantáltan nem kell fizetnie a megadott költségvetésért.
Szabályozhatom a hiperparamétereket, vagy használhatom a saját modelleimet a betanítás során?
Nem, a Képelemzési modell testreszabási szolgáltatása egy alacsony kódszámú AutoML betanítási rendszert használ, amely kezeli a hiperparaméteres keresést és az alapmodell kiválasztását a háttérrendszerben.
Exportálhatom a modellt a betanítás után?
Az előrejelzési API csak a felhőszolgáltatáson keresztül támogatott.
Miért hiúsul meg a kiértékelés az objektumészlelési modellemen?
Az alábbiakban a lehetséges okok szerepelnek:
internalServerError: Ismeretlen hiba történt. Próbálkozzon újra később.modelNotFound: A megadott modell nem található.datasetNotFound: A megadott adatkészlet nem található.datasetAnnotationsInvalid: Hiba történt a tesztadatkészlethez társított alapigaz széljegyzetek letöltése vagy elemzése során.datasetEmpty: A tesztadatkészlet nem tartalmazott "alapigazság" széljegyzeteket.
Mi az egyéni modellekkel kapcsolatos előrejelzések várható késése?
Nem javasoljuk, hogy egyéni modelleket használjon üzleti szempontból kritikus környezetekhez a lehetséges nagy késés miatt. Amikor az ügyfelek egyéni modelleket tanítanak be a Vision Studióban, ezek az egyéni modellek ahhoz az Azure AI Vision-erőforráshoz tartoznak, amelybe betanították őket, és az ügyfél az Analyze Image API használatával tud hívásokat kezdeményezni ezekhez a modellekhez. Amikor ilyen hívásokat kezdeményeznek, az egyéni modell betöltődik a memóriába, és inicializálódik az előrejelzési infrastruktúra. Bár ez történik, az ügyfelek a vártnál hosszabb késést tapasztalhatnak az előrejelzési eredmények fogadásához.
Adatvédelem és biztonság
Az Azure AI-szolgáltatásokhoz hasonlóan az Image Analysis-modell testreszabását használó fejlesztőknek is tisztában kell lenniük a Microsoft ügyféladatokra vonatkozó szabályzataival. További információért tekintse meg az Azure AI-szolgáltatások oldalát a Microsoft Adatvédelmi központban.