Professzionális hangmodell betanítása
Ebből a cikkből megtudhatja, hogyan taníthat be egyéni neurális hangokat a Speech Studio portálon keresztül.
Fontos
Az egyéni neurális hangképzés jelenleg csak bizonyos régiókban érhető el. Miután a hangmodellt betanított egy támogatott régióban, szükség szerint átmásolhatja azt egy másik régióban található Speech-erőforrásba. További információkért tekintse meg a Speech szolgáltatás táblázatának lábjegyzeteit.
A betanítás időtartama a használt adatok mennyiségétől függően változik. Egy egyéni neurális hang betanítása átlagosan körülbelül 40 számítási órát vesz igénybe. A standard előfizetés (S0) felhasználói egyszerre négy hangot taníthatnak be. Ha eléri a korlátot, várjon, amíg az egyik hangmodell betanítása befejeződik, majd próbálkozzon újra.
Feljegyzés
Bár a betanítási módszerenként szükséges órák teljes száma eltérő, mindegyikre ugyanaz az egységár vonatkozik. További információkért tekintse meg az egyéni neurális képzés díjszabását.
Betanítási módszer kiválasztása
Az adatfájlok ellenőrzése után használja őket az egyéni neurális hangmodell létrehozásához. Egyéni neurális hang létrehozásakor az alábbi módszerek egyikével taníthatja be:
Neurális: Hang létrehozása a betanítási adatok azonos nyelvén.
Neurális – többnyelvű: Olyan hang létrehozása, amely a betanítási adatoktól eltérő nyelvet beszél. A betanítási
zh-CNadatokkal például létrehozhat egy beszédhangoten-US.A betanítási adatok nyelvének és a célnyelvnek egyaránt azoknak a nyelveknek kell lennie, amelyek támogatják a nyelvközi hangképzést . A betanítási adatokat nem kell a célnyelven előkészíteni, de a tesztszkriptnek a célnyelven kell lennie.
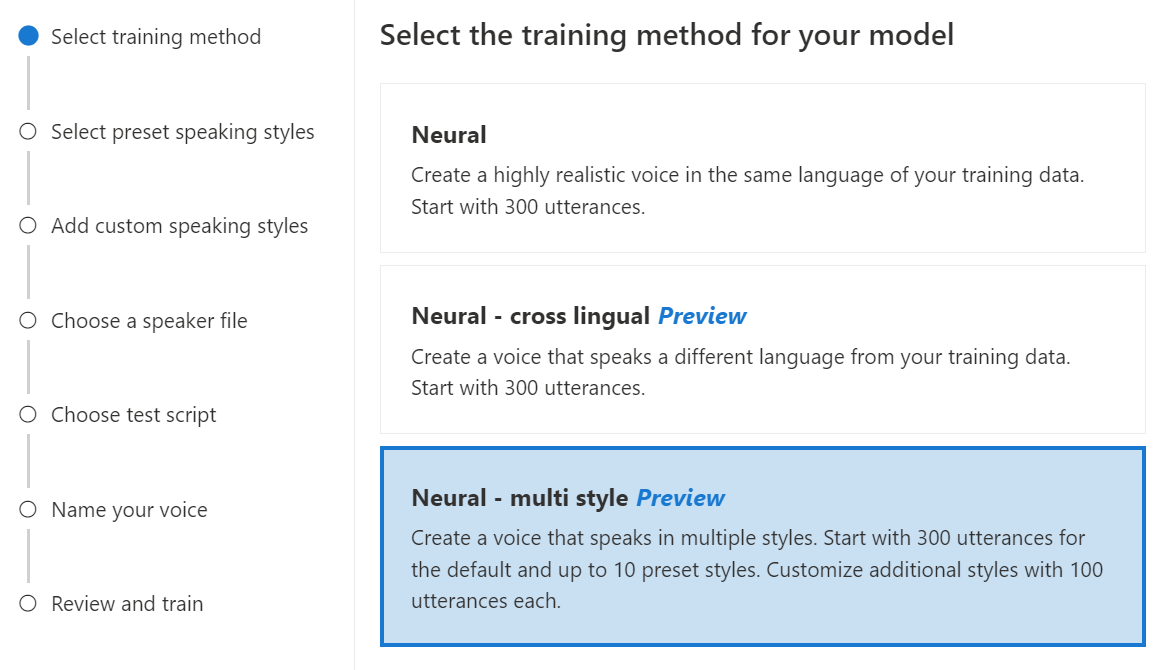
Neurális – több stílus: Egyéni neurális hang létrehozása, amely több stílusban és érzelemben szólal meg, új betanítási adatok hozzáadása nélkül. A több stílusú hang használható videojáték-karakterek, beszélgetési csevegőrobotok, hangoskönyvek, tartalomolvasók és egyebek esetén.
Több stílusú hang létrehozásához elő kell készítenie egy általános betanítási adatokat, legalább 300 kimondott szöveget. Válasszon ki egy vagy több előre beállított beszédstílust. Több egyéni stílust is létrehozhat, ha stílusmintákat biztosít, stílusonként legalább 100 kimondott szövegből, és további betanítási adatokat biztosít ugyanahhoz a hanghoz. A támogatott előre beállított stílusok különböző nyelvektől függően változnak. Különböző nyelveken elérhető előre beállított stílusok megtekintése.
A betanítási adatok nyelvének olyan nyelvnek kell lennie, amelyet az egyéni neurális hang, a többnyelvű vagy a többstílusú betanítás támogat .
Egyéni neurális hangmodell betanítása
Ha egyéni neurális hangot szeretne létrehozni a Speech Studióban, kövesse az alábbi lépéseket az alábbi módszerek egyikéhez:
Jelentkezzen be a Speech Studióba.
Válassza az Egyéni hang<>: A projekt neve>>Betanítási modell>Új modell betanítása.
Válassza a Neurális lehetőséget a modell betanítási módszereként, majd válassza a Tovább lehetőséget. Egy másik betanítási módszer használatához lásd : Neurális – többnyelvű vagy Neurális – többstílusú.
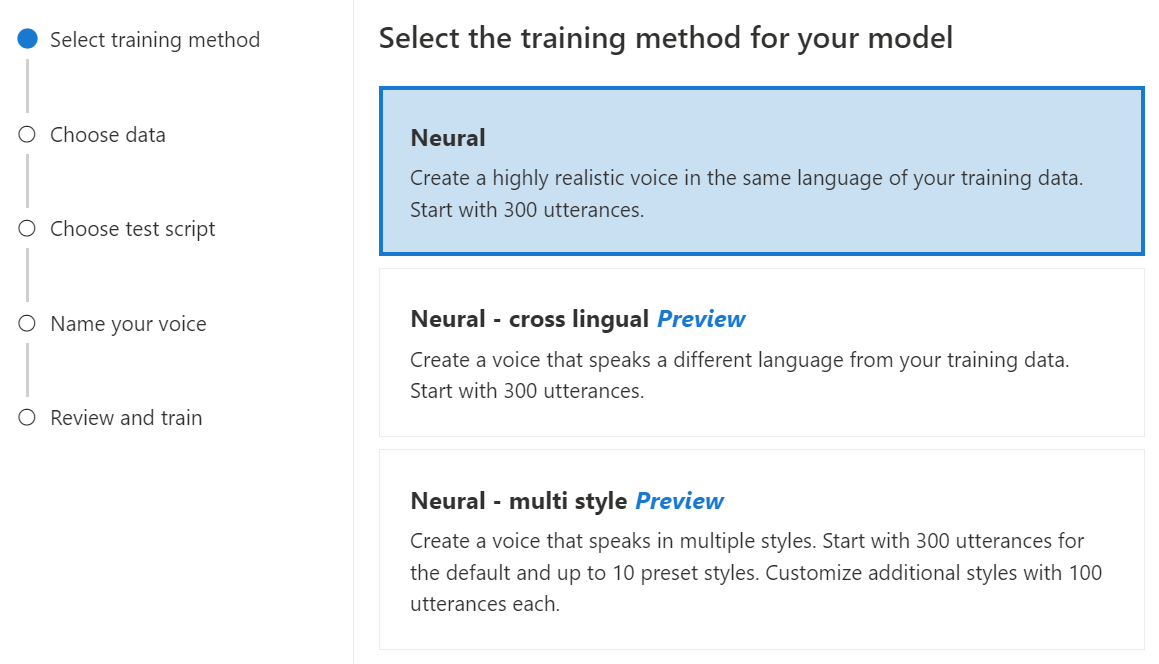
Válassza ki a modell betanítási receptjének egy verzióját. Alapértelmezés szerint a legújabb verzió van kiválasztva. A támogatott funkciók és a betanítási idő verziótól függően változhat. Általában a legújabb verziót javasoljuk. Bizonyos esetekben választhat egy korábbi verziót a betanítási idő csökkentéséhez. A kétnyelvű képzésről és a területi különbségekről további információt a kétnyelvű képzésben talál.
Jelölje ki a betanításhoz használni kívánt adatokat. A rendszer eltávolítja az ismétlődő hangneveket a betanításból. Győződjön meg arról, hogy a kiválasztott adatok nem tartalmazzák ugyanazokat a hangneveket több .zip fájlban.
Csak a sikeresen feldolgozott adathalmazokat választhatja ki a betanításhoz. Ha nem látja a betanítási csoportot a listában, ellenőrizze az adatfeldolgozás állapotát.
Válasszon ki egy előadói fájlt a betanítási adatokban szereplő beszélőnek megfelelő hangtehetség-utasítással.
Válassza a Tovább lehetőséget.
Minden betanítás 100 hangfájlmintát hoz létre automatikusan, hogy segítsen a modell alapértelmezett szkripttel való tesztelésében.
Ha szeretné, választhatja a Saját tesztszkript hozzáadása lehetőséget is, és akár 100 kimondott szöveggel is elláthatja a saját tesztszkriptet a modell további költségek nélküli teszteléséhez. A létrehozott hangfájlok az automatikus tesztszkriptek és az egyéni tesztszkriptek kombinációját képezik. További információ: tesztszkriptkövetelmények.
Adjon meg egy nevet a modell azonosításához. Válasszon nevet körültekintően. Az SDK és az SSML bemenete a beszédszintézis-kérésben a modell nevét használja hangnévként. Csak betűk, számok és írásjelek engedélyezettek. Használjon különböző neveket a különböző neurális hangmodellekhez.
Ha szeretné, írja be a leírást a modell azonosításához. A leírás gyakori használata a modell létrehozásához használt adatok nevének rögzítése.
Válassza a Tovább lehetőséget.
Tekintse át a beállításokat, és válassza ki a jelölőnégyzetet a használati feltételek elfogadásához.
Válassza a Küldés lehetőséget a modell betanításának megkezdéséhez.

Kétnyelvű képzés
Ha a neurális betanítási típust választja, hangokat taníthat be több nyelven való beszédre. zh-TW A zh-CN területi beállítások támogatják a kétnyelvű képzést, hogy a hang kínai és angol nyelven is beszéljen. Részben a betanítási adatoktól függően a szintetizált hang angolul tud beszélni angolul natív ékezettel vagy angolul, ugyanazzal a ékezettel, mint a betanítási adatok.
Feljegyzés
Ha lehetővé szeretné tenni, hogy egy zh-CN hang a területi beállításokban a mintaadatokkal megegyező ékezettel beszéljen angolul, válassza ki Chinese (Mandarin, Simplified), English bilingual a projekt létrehozásakor, vagy adja meg a zh-CN (English bilingual) betanítási csoport adatainak területi beállítását a REST API-val.
Az alábbi táblázat a két területi beállítás közötti különbségeket mutatja be:
| A Speech Studio területi beállítása | REST API területi beállítása | Kétnyelvű támogatás |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Ha a mintaadatok tartalmazzák az angol nyelvet, a szintetizált hang angolul beszél natív ékezettel, a mintaadatokkal azonos ékezet helyett, függetlenül az angol adatok mennyiségétől. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Ha azt szeretné, hogy a szintetizált hang ugyanolyan ékezettel beszéljen angolul, mint a mintaadatok, javasoljuk, hogy a betanítási készletbe több mint 10%-os angol nyelvű adatokat is beleszámítson. Ellenkező esetben előfordulhat, hogy az angol nyelvű akcentus nem ideális. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Ha olyan szintetizált hangot szeretne betanítani, amely képes az angol nyelvet ugyanolyan ékezettel beszélni, mint a mintaadatok, győződjön meg arról, hogy több mint 10%-os angol adatot biztosít a betanítási csoportban. Ellenkező esetben alapértelmezés szerint angol natív ékezetet ad. A 10%-os küszöbérték kiszámítása a sikeres feltöltés után elfogadott adatok alapján történik, nem pedig a feltöltés előtti adatok alapján. Ha egyes feltöltött angol nyelvű adatokat hibák miatt elutasítanak, és nem felelnek meg a 10%-os küszöbértéknek, a szintetizált hang alapértelmezés szerint egy angol natív jelölőszínre kerül. |
Különböző nyelveken elérhető előre beállított stílusok
Az alábbi táblázat összefoglalja a különböző előre beállított stílusokat különböző nyelvek szerint.
| Beszédstílus | Nyelv (területi beállítás) |
|---|---|
| Dühös | Angol (Egyesült Államok) (en-US)Japán (Japán) ( ja-JP) 1Kínai (mandarin, egyszerűsített) ( zh-CN) 1 |
| Nyugodt | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| csevegés | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Vidám | Angol (Egyesült Államok) (en-US)Japán (Japán) ( ja-JP) 1Kínai (mandarin, egyszerűsített) ( zh-CN) 1 |
| Elégedetlen | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Izgatott | Angol (Egyesült Államok) (en-US) |
| Félelmetes | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Barátságos | Angol (Egyesült Államok) (en-US) |
| Reményteljes | Angol (Egyesült Államok) (en-US) |
| szomorú | Angol (Egyesült Államok) (en-US)Japán (Japán) ( ja-JP) 1Kínai (mandarin, egyszerűsített) ( zh-CN) 1 |
| Kiabálás | Angol (Egyesült Államok) (en-US) |
| Súlyos | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Rémült | Angol (Egyesült Államok) (en-US) |
| Barátságtalan | Angol (Egyesült Államok) (en-US) |
| Suttogó | Angol (Egyesült Államok) (en-US) |
1 A neurális hangstílus nyilvános előzetes verzióban érhető el. A nyilvános előzetes verziójú stílusok csak ezekben a szolgáltatási régiókban érhetők el: AZ USA keleti régiója, Nyugat-Európa és Délkelet-Ázsia.
A Modell betanítása tábla egy új bejegyzést jelenít meg, amely megfelel az újonnan létrehozott modellnek. Az állapot az adatok hangmodellté alakításának folyamatát tükrözi az alábbi táblázatban leírtak szerint:
| Állapot | Értelmezés |
|---|---|
| Feldolgozás | A hangmodell létrehozása folyamatban van. |
| Sikeres | A hangmodell létrejött, és üzembe helyezhető. |
| Sikertelen | A hangmodell betanítása sikertelen volt. A hiba oka lehet például a nem látható adatproblémák vagy a hálózati problémák. |
| Visszavont | A hangmodell betanítása megszakadt. |
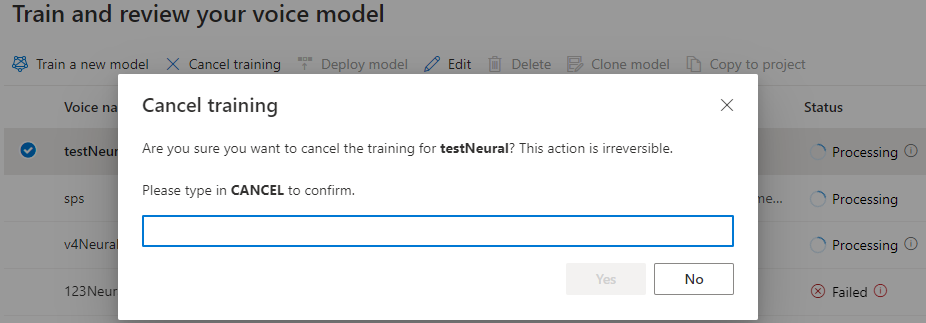
Amíg a modell állapota Feldolgozás, a hangmodell megszakításához válassza a Mégse betanítás lehetőséget. A megszakított képzésért nem számítunk fel díjat.
A modell sikeres betanítása után áttekintheti a modell részleteit, és tesztelheti a hangmodellt.
A Speech Studióban a Hangtartalom létrehozása eszközzel hangokat hozhat létre, és finomhangolhatja az üzembe helyezett hangot. Ha a hangjára is alkalmazható, több stílus közül választhat.
A modell átnevezése
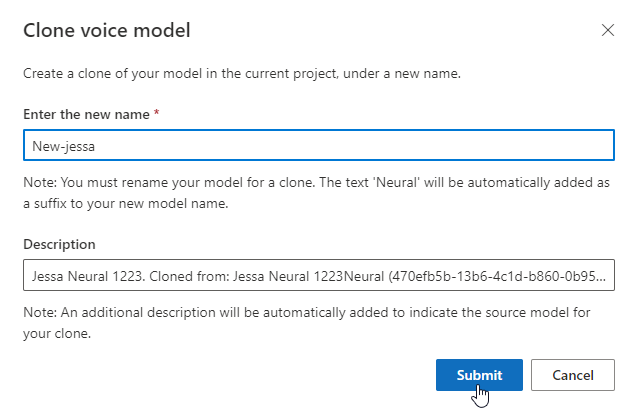
Ha át szeretné nevezni a létrehozott modellt, válassza a Klónozás lehetőséget a modell klónjának létrehozásához az aktuális projektben.

Adja meg az új nevet a Hangmodell klónozása ablakban, majd válassza a Küldés lehetőséget. A rendszer automatikusan hozzáadja a neurális szöveget az új modellnév utótagjaként.
Hangmodell tesztelése
A hangmodell sikeres létrehozása után a létrehozott minta hangfájlokkal tesztelheti azt az üzembe helyezés előtt.
A hang minősége számos tényezőtől függ, például:
- A betanítási adatok mérete.
- A felvétel minősége.
- Az átiratfájl pontossága.
- Milyen jól illeszkedik a betanítási adatokban rögzített hang a tervezett hang személyiségéhez a kívánt használati esethez.
Válassza a DefaultTests (DefaultTests) lehetőséget a Tesztelés területen a minta hangfájlok meghallgatásához. Az alapértelmezett tesztminták 100 minta hangfájlt tartalmaznak, amelyek automatikusan generálódnak a betanítás során a modell teszteléséhez. Az alapértelmezés szerint megadott 100 hangfájl mellett saját tesztszkript-kimondott szövegek is hozzáadódnak a DefaultTests-csoporthoz. Ez a kiegészítés legfeljebb 100 kimondott szöveg. A DefaultTests használatával végzett tesztelésért nem kell fizetnie.

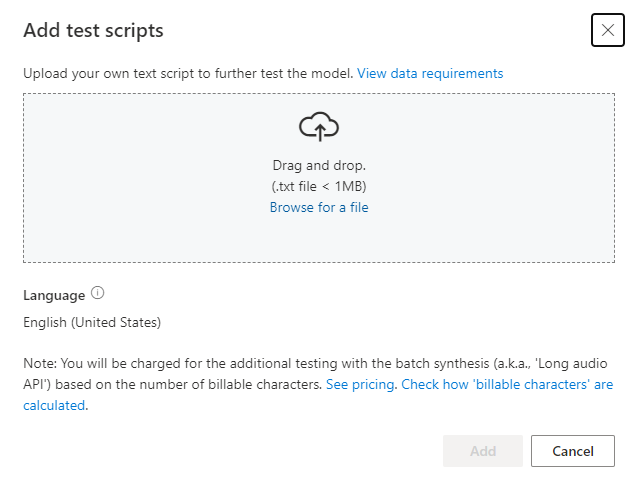
Ha saját tesztszkripteket szeretne feltölteni a modell további teszteléséhez, válassza a Tesztszkriptek hozzáadása lehetőséget a saját tesztszkript feltöltéséhez.

A tesztszkript feltöltése előtt ellenőrizze a tesztszkript követelményeit. A kötegszintézissel végzett extra tesztelésért a számlázható karakterek száma alapján kell fizetnie. Tekintse meg az Azure AI Speech díjszabását.
A Tesztszkriptek hozzáadása csoportban válassza a Tallózás a fájlhoz lehetőséget a saját szkript kiválasztásához, majd a Hozzáadás gombra a feltöltéshez.
Szkriptelési követelmények tesztelése
A tesztszkriptnek 1 MB-nál kisebb .txt fájlnak kell lennie. A támogatott kódolási formátumok közé tartozik az ANSI/ASCII, az UTF-8, az UTF-8-BOM, az UTF-16-LE vagy az UTF-16-BE.
A betanítási átiratfájlokkal ellentétben a tesztszkriptnek ki kell zárnia a kimondott szöveg azonosítóját, amely az egyes kimondott szövegek fájlneve. Ellenkező esetben ezeket az azonosítókat a rendszer elhangozza.
Íme egy példa kimondott szövegekre egy .txt fájlban:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
A kimondott szöveg minden egyes bekezdése külön hanganyagot eredményez. Ha az összes mondatot egyetlen hangba szeretné egyesíteni, egyetlen bekezdést kell létrehoznia.
Feljegyzés
A létrehozott hangfájlok az automatikus tesztszkriptek és az egyéni tesztszkriptek kombinációját képezik.
A hangmodell motorverziójának frissítése
Az Azure szöveg-beszédmotorjai időről időre frissülnek, hogy rögzítsék a nyelv kiejtését meghatározó legújabb nyelvi modellt. A hang betanítása után a legújabb motorverzióra frissítve alkalmazhatja a hangját az új nyelvi modellre.
Ha új motor érhető el, a rendszer kérni fogja a neurális hangmodell frissítését.

Nyissa meg a modell részleteit tartalmazó oldalt, és kövesse a képernyőn megjelenő utasításokat a legújabb motor telepítéséhez.
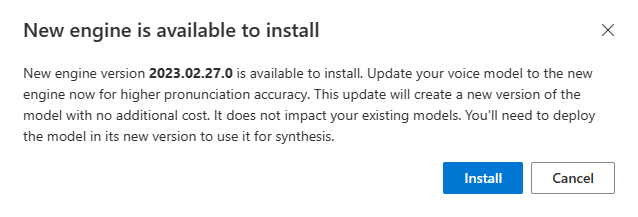
Másik lehetőségként válassza a Legújabb motor telepítése később lehetőséget a modell legújabb motorverzióra való frissítéséhez.
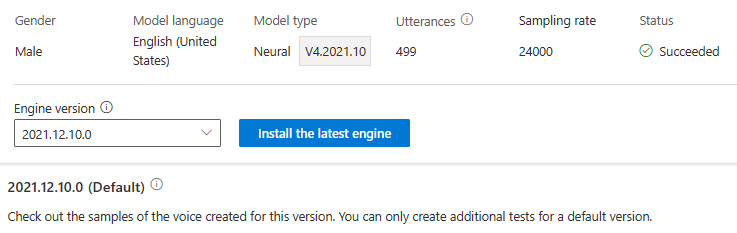
A motorfrissítésért nem kell fizetnie. Az előző verziók továbbra is megmaradnak.
A motorverziók listájából ellenőrizheti a modell összes motorverzióját, vagy eltávolíthat egyet, ha már nincs rá szüksége.
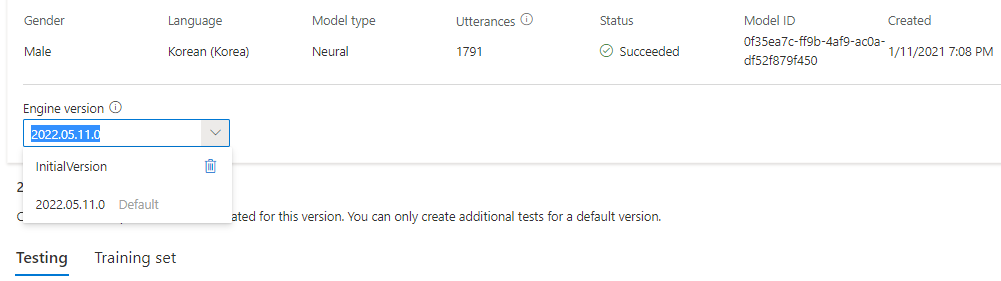
A frissített verzió automatikusan alapértelmezettként van beállítva. Az alapértelmezett verziót azonban módosíthatja úgy, hogy kiválaszt egy verziót a legördülő listából, és kiválasztja a Beállítás alapértelmezettként lehetőséget.
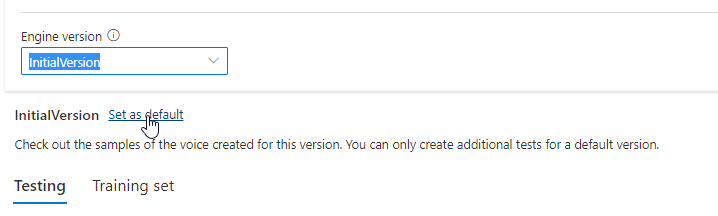

Ha a hangmodell minden motorverzióját tesztelni szeretné, kiválaszthat egy verziót a listából, majd a Tesztelés területen válassza a DefaultTests (Alapértelmezett tesztek) lehetőséget a minta hangfájlok meghallgatásához. Ha saját tesztszkripteket szeretne feltölteni az aktuális motorverzió további teszteléséhez, először győződjön meg arról, hogy a verzió alapértelmezettként van beállítva, majd kövesse a hangmodell tesztelésének lépéseit.
A motor frissítése további költségek nélkül létrehozza a modell új verzióját. Miután frissítette a hangmodell motorverzióját, üzembe kell helyeznie az új verziót egy új végpont létrehozásához. Csak az alapértelmezett verziót helyezheti üzembe.
Miután létrehozott egy új végpontot, át kell vinnie a forgalmat a termék új végpontjához.
Ha többet szeretne megtudni a funkció képességeiről és korlátairól, valamint a modell minőségének javításához ajánlott eljárásról, tekintse meg az egyéni neurális hang használatára vonatkozó jellemzőket és korlátozásokat.
Hangmodell másolása másik projektbe
A hangmodellt átmásolhatja egy másik projektbe ugyanahhoz a régióhoz vagy egy másik régióhoz. Az egyik régióban betanított neurális hangmodellt például átmásolhatja egy másik régió projektbe.
Feljegyzés
Az egyéni neurális hangképzés jelenleg csak bizonyos régiókban érhető el. Ezekről a régiókról más régiókba másolhat neurális hangmodelleket. További információkért tekintse meg az egyéni neurális hang régiókat.
Az egyéni neurális hangmodell másolása egy másik projektbe:
A Modell betanítása lapon válassza ki a másolni kívánt hangmodellt, majd válassza a Másolás projektbe lehetőséget.
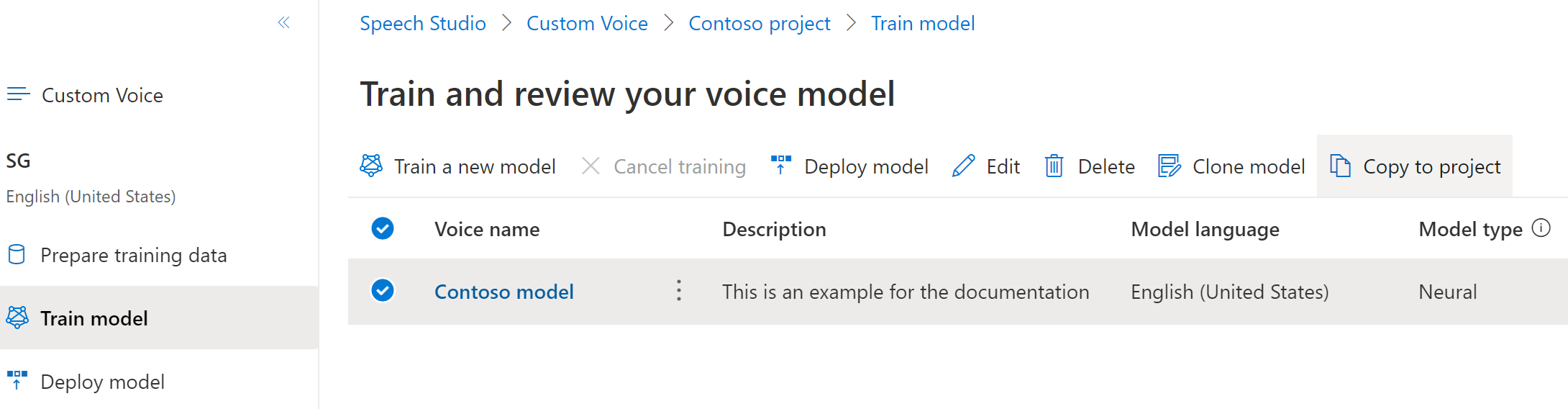
Válassza ki azt a régiót, beszéderőforrást és projektet, ahová a modellt másolni szeretné. A célrégióban beszéderőforrásnak és projektnek kell lennie, ellenkező esetben először létre kell hoznia őket.
Válassza a Küldés lehetőséget a modell másolásához.
A sikeres másoláshoz válassza a Modell megtekintése lehetőséget az értesítési üzenet alatt.
Lépjen arra a projektre, amelybe a modellt másolta a modellpéldány üzembe helyezéséhez.
Következő lépések
Ebben a cikkben megtudhatja, hogyan taníthat be egyéni neurális hangokat az egyéni hang API-n keresztül.
Fontos
Az egyéni neurális hangképzés jelenleg csak bizonyos régiókban érhető el. Miután a hangmodellt betanított egy támogatott régióban, szükség szerint átmásolhatja azt egy másik régióban található Speech-erőforrásba. További információkért tekintse meg a Speech szolgáltatás táblázatának lábjegyzeteit.
A betanítás időtartama a használt adatok mennyiségétől függően változik. Egy egyéni neurális hang betanítása átlagosan körülbelül 40 számítási órát vesz igénybe. A standard előfizetés (S0) felhasználói egyszerre négy hangot taníthatnak be. Ha eléri a korlátot, várjon, amíg az egyik hangmodell betanítása befejeződik, majd próbálkozzon újra.
Feljegyzés
Bár a betanítási módszerenként szükséges órák teljes száma eltérő, mindegyikre ugyanaz az egységár vonatkozik. További információkért tekintse meg az egyéni neurális képzés díjszabását.
Betanítási módszer kiválasztása
Az adatfájlok ellenőrzése után használja őket az egyéni neurális hangmodell létrehozásához. Egyéni neurális hang létrehozásakor az alábbi módszerek egyikével taníthatja be:
Neurális: Hang létrehozása a betanítási adatok azonos nyelvén.
Neurális – többnyelvű: Olyan hang létrehozása, amely a betanítási adatoktól eltérő nyelvet beszél. A betanítási
fr-FRadatokkal például létrehozhat egy beszédhangoten-US.A betanítási adatok nyelvének és a célnyelvnek egyaránt azoknak a nyelveknek kell lennie, amelyek támogatják a nyelvközi hangképzést . A betanítási adatokat nem kell a célnyelven előkészíteni, de a tesztszkriptnek a célnyelven kell lennie.
Neurális – több stílus: Egyéni neurális hang létrehozása, amely több stílusban és érzelemben szólal meg, új betanítási adatok hozzáadása nélkül. A több stílusú hang használható videojáték-karakterek, beszélgetési csevegőrobotok, hangoskönyvek, tartalomolvasók és egyebek esetén.
Több stílusú hang létrehozásához elő kell készítenie egy általános betanítási adatokat, legalább 300 kimondott szöveget. Válasszon ki egy vagy több előre beállított beszédstílust. Több egyéni stílust is létrehozhat, ha stílusmintákat biztosít, stílusonként legalább 100 kimondott szövegből, és további betanítási adatokat biztosít ugyanahhoz a hanghoz. A támogatott előre beállított stílusok különböző nyelvektől függően változnak. Különböző nyelveken elérhető előre beállított stílusok megtekintése.
A betanítási adatok nyelvének olyan nyelvnek kell lennie, amelyet egyéni neurális hang, nyelvközi vagy többstílusos betanítás támogat .
Hangmodell létrehozása
Neurális hang létrehozásához használja az egyéni hang API Models_Create műveletét. A kérelem törzsének összeállítása az alábbi utasítások szerint:
- Állítsa be a szükséges
projectIdtulajdonságot. Lásd: projekt létrehozása. - Állítsa be a szükséges
consentIdtulajdonságot. Lásd: hangtehetség-hozzájárulás hozzáadása. - Állítsa be a szükséges
trainingSetIdtulajdonságot. Lásd: betanítási csoport létrehozása. - Állítsa be a szükséges recepttulajdonságot
kindDefaulta neurális hangképzéshez. A recept típusa jelzi a betanítási módszert, és később nem módosítható. Egy másik betanítási módszer használatához lásd : Neurális – többnyelvű vagy Neurális – többstílusú. A kétnyelvű képzésről és a területi különbségekről további információt a kétnyelvű képzésben talál. - Állítsa be a szükséges
voiceNametulajdonságot. A hang nevének "Neurális" végződésűnek kell lennie, és később nem módosítható. Válasszon nevet körültekintően. A hangnevet az SDK és az SSML bemenet használja a beszédszintézis-kérésben . Csak betűk, számok és írásjelek engedélyezettek. Használjon különböző neveket a különböző neurális hangmodellekhez. - Igény szerint állítsa be a
descriptionhangleírás tulajdonságát. A hang leírása később módosítható.
Hozzon létre egy HTTP PUT-kérést az URI használatával az alábbi Models_Create példában látható módon.
- Cserélje le
YourResourceKeya Speech erőforráskulcsot. - Cserélje le
YourResourceRegiona Speech erőforrásrégióját. - Cserélje le
JessicaModelIda kívánt modellazonosítóra. A kis- és nagybetűk megkülönböztetése a modell URI-jában lesz használva, és később nem módosítható.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview"
A válasz törzsének a következő formátumban kell érkeznie:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Kétnyelvű képzés
Ha a neurális betanítási típust választja, hangokat taníthat be több nyelven való beszédre. zh-TW A zh-CN területi beállítások támogatják a kétnyelvű képzést, hogy a hang kínai és angol nyelven is beszéljen. Részben a betanítási adatoktól függően a szintetizált hang angolul tud beszélni angolul natív ékezettel vagy angolul, ugyanazzal a ékezettel, mint a betanítási adatok.
Feljegyzés
Ha lehetővé szeretné tenni, hogy egy zh-CN hang a területi beállításokban a mintaadatokkal megegyező ékezettel beszéljen angolul, válassza ki Chinese (Mandarin, Simplified), English bilingual a projekt létrehozásakor, vagy adja meg a zh-CN (English bilingual) betanítási csoport adatainak területi beállítását a REST API-val.
Az alábbi táblázat a két területi beállítás közötti különbségeket mutatja be:
| A Speech Studio területi beállítása | REST API területi beállítása | Kétnyelvű támogatás |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Ha a mintaadatok tartalmazzák az angol nyelvet, a szintetizált hang angolul beszél natív ékezettel, a mintaadatokkal azonos ékezet helyett, függetlenül az angol adatok mennyiségétől. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Ha azt szeretné, hogy a szintetizált hang ugyanolyan ékezettel beszéljen angolul, mint a mintaadatok, javasoljuk, hogy a betanítási készletbe több mint 10%-os angol nyelvű adatokat is beleszámítson. Ellenkező esetben előfordulhat, hogy az angol nyelvű akcentus nem ideális. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Ha olyan szintetizált hangot szeretne betanítani, amely képes az angol nyelvet ugyanolyan ékezettel beszélni, mint a mintaadatok, győződjön meg arról, hogy több mint 10%-os angol adatot biztosít a betanítási csoportban. Ellenkező esetben alapértelmezés szerint angol natív ékezetet ad. A 10%-os küszöbérték kiszámítása a sikeres feltöltés után elfogadott adatok alapján történik, nem pedig a feltöltés előtti adatok alapján. Ha egyes feltöltött angol nyelvű adatokat hibák miatt elutasítanak, és nem felelnek meg a 10%-os küszöbértéknek, a szintetizált hang alapértelmezés szerint egy angol natív jelölőszínre kerül. |
Különböző nyelveken elérhető előre beállított stílusok
Az alábbi táblázat összefoglalja a különböző előre beállított stílusokat különböző nyelvek szerint.
| Beszédstílus | Nyelv (területi beállítás) |
|---|---|
| Dühös | Angol (Egyesült Államok) (en-US)Japán (Japán) ( ja-JP) 1Kínai (mandarin, egyszerűsített) ( zh-CN) 1 |
| Nyugodt | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| csevegés | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Vidám | Angol (Egyesült Államok) (en-US)Japán (Japán) ( ja-JP) 1Kínai (mandarin, egyszerűsített) ( zh-CN) 1 |
| Elégedetlen | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Izgatott | Angol (Egyesült Államok) (en-US) |
| Félelmetes | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Barátságos | Angol (Egyesült Államok) (en-US) |
| Reményteljes | Angol (Egyesült Államok) (en-US) |
| szomorú | Angol (Egyesült Államok) (en-US)Japán (Japán) ( ja-JP) 1Kínai (mandarin, egyszerűsített) ( zh-CN) 1 |
| Kiabálás | Angol (Egyesült Államok) (en-US) |
| Súlyos | Kínai (mandarin, egyszerűsített) (zh-CN) 1 |
| Rémült | Angol (Egyesült Államok) (en-US) |
| Barátságtalan | Angol (Egyesült Államok) (en-US) |
| Suttogó | Angol (Egyesült Államok) (en-US) |
1 A neurális hangstílus nyilvános előzetes verzióban érhető el. A nyilvános előzetes verziójú stílusok csak ezekben a szolgáltatási régiókban érhetők el: AZ USA keleti régiója, Nyugat-Európa és Délkelet-Ázsia.
Betanítási állapot lekérése
A hangmodell betanítási állapotának lekéréséhez használja az egyéni hang API Models_Get műveletét. A kérelem URI-jának összeállítása az alábbi utasítások szerint:
Http GET-kérést készíthet az URI használatával az alábbi Models_Get példában látható módon.
- Cserélje le
YourResourceKeya Speech erőforráskulcsot. - Cserélje le
YourResourceRegiona Speech erőforrásrégióját. - Cserélje le
JessicaModelId, ha az előző lépésben egy másik modellazonosítót adott meg.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
A válasz törzsét a következő formátumban kell megkapnia.
Feljegyzés
A recept kind és más tulajdonságok attól függenek, hogyan képezte be a hangot. Ebben a példában a recept típusa Default a neurális hangképzés.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Előfordulhat, hogy néhány percet várnia kell a betanítás befejezése előtt. Végül az állapot vagy a SucceededFailed.