Professzionális hangbetanítási adatkészlet hozzáadása
Ha készen áll arra, hogy egyéni szöveget hozzon létre a beszédhanghoz az alkalmazás számára, az első lépés a hangfelvételek és a hozzájuk tartozó szkriptek összegyűjtése a hangmodell betanításának megkezdéséhez. A hangminták felvételével kapcsolatos részletekért tekintse meg az oktatóanyagot. A Speech szolgáltatás ezeket az adatokat felhasználva egy egyedi hangszínt hoz létre, amely a felvételek hangjának megfelelően van hangolva. A hang betanítása után megkezdheti a beszéd szintetizálását az alkalmazásokban.
Minden feltöltött adatnak meg kell felelnie a választott adattípus követelményeinek. Fontos, hogy a feltöltés előtt megfelelően formázza az adatokat, ami biztosítja, hogy a Speech szolgáltatás pontosan feldolgozza az adatokat. Az adatok helyes formázásának ellenőrzéséhez tekintse meg a Betanítás adattípusokat.
Feljegyzés
- A standard előfizetés (S0) felhasználói egyszerre öt adatfájlt tölthetnek fel. Ha eléri a korlátot, várjon, amíg legalább az egyik adatfájl importálása befejeződik. Ezután próbálkozzon újra.
- Az előfizetésenként importálható adatfájlok maximális száma 500 .zip fájl a standard előfizetési (S0) felhasználók számára. További részletekért tekintse meg a Speech szolgáltatás kvótáit és korlátait .
Adatok feltöltése
Ha készen áll az adatok feltöltésére, lépjen a Betanítási adatok előkészítése lapra az első betanítási csoport hozzáadásához és az adatok feltöltéséhez. A betanítási csoportok hangszövegek és a hangmodellek betanításához használt leképezési szkriptek. Betanítási csoport használatával rendszerezheti a betanítási adatokat. A szolgáltatás minden betanítási csoportban ellenőrzi az adatok készültségét. Több adatot is importálhat egy betanítási csoportba.
Betanítási adatok feltöltéséhez kövesse az alábbi lépéseket:
- Jelentkezzen be a Speech Studióba.
- Válassza az Egyéni hang> a projekt neve >Betanítási adatok>előkészítése Adatok feltöltése lehetőséget.
- Az Adatok feltöltése varázslóban válasszon egy adattípust, majd válassza a Tovább gombot.
- Válassza ki a helyi fájlokat a számítógépről, vagy adja meg az Azure Blob Storage URL-címét az adatok feltöltéséhez.
- A Cél betanítási csoport megadása csoportban válasszon ki egy meglévő betanítási csoportot, vagy hozzon létre egy újat. Ha létrehozott egy új betanítási csoportot, a folytatás előtt győződjön meg arról, hogy ki van jelölve a legördülő listában.
- Válassza a Tovább lehetőséget.
- Adja meg az adatok nevét és leírását, majd válassza a Tovább gombot.
- Tekintse át a feltöltés részleteit, és válassza a Küldés lehetőséget.
Feljegyzés
A duplikált azonosítók nem fogadhatók el. Az azonos azonosítójú kimondott szövegek el lesznek távolítva.
A rendszer eltávolítja az ismétlődő hangneveket a betanításból. Győződjön meg arról, hogy a kiválasztott adatok nem tartalmazzák ugyanazokat a hangneveket a .zip fájlban vagy több .zip fájlban. Ha a kimondott szövegek azonosítói (hang- vagy szkriptfájlokban) duplikáltak, a rendszer elutasítja őket.
Az adatfájlok automatikusan érvényesítve lesznek a Küldés lehetőség kiválasztásakor. Az adatérvényesítés több ellenőrzést is tartalmaz a hangfájlokon a fájlformátum, a méret és a mintavételezési sebesség ellenőrzéséhez. Ha bármilyen hiba merül fel, javítsa ki őket, és küldje el újra.
Az adatok feltöltése után a betanítási csoport részletes nézetében ellenőrizheti a részleteket. A részletes lapon további információt kaphat a kiejtési problémáról és az egyes adatok zajszintjéről. A mondatszint kiejtési pontszáma 0 és 100 közötti lehet. A 70 alatti pontszám általában beszédhibát vagy szkripteltérést jelez. A 70-nél alacsonyabb összesített pontszámú kimondott szövegeket a rendszer elutasítja. A hangsúlyos hangsúly csökkentheti a kiejtési pontszámot, és hatással lehet a generált digitális hangra.
Online adatproblémák megoldása
A feltöltés után ellenőrizheti a betanítási csoport adatadatait. Mielőtt folytatná a hangmodell betanítását, próbálja meg megoldani az adatproblémákat.
A Speech Studióban kimondott szövegenként azonosíthatja és megoldhatja az adatproblémákat.
A részletek lapon lépjen az Elfogadott adatok vagy az Elutasított adatok lapra. Jelölje ki a módosítani kívánt egyes kimondott szövegeket, majd válassza a Szerkesztés lehetőséget.
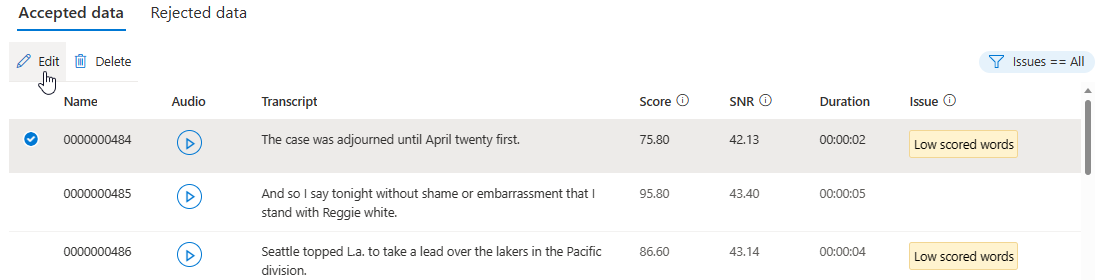
A feltételek alapján kiválaszthatja, hogy mely adatproblémák jelenjenek meg.
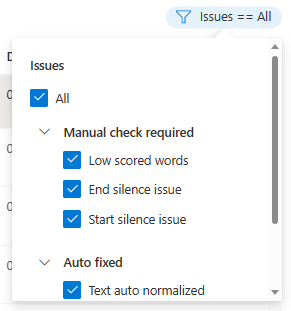
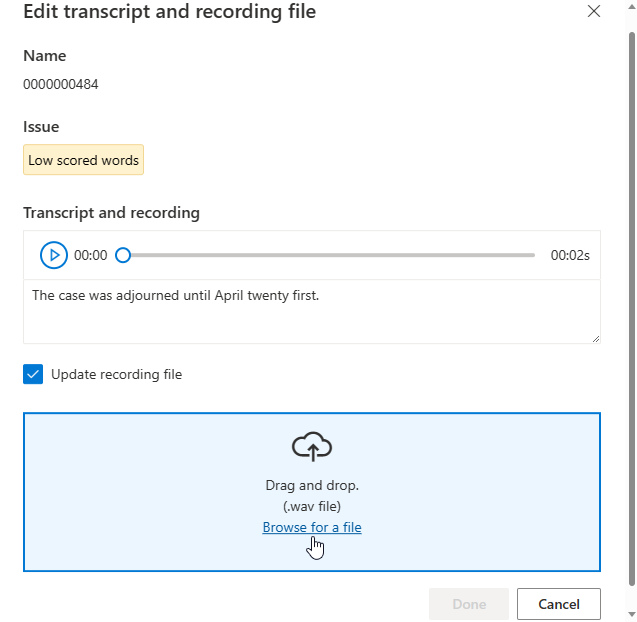
Ekkor megjelenik a Szerkesztés ablak.
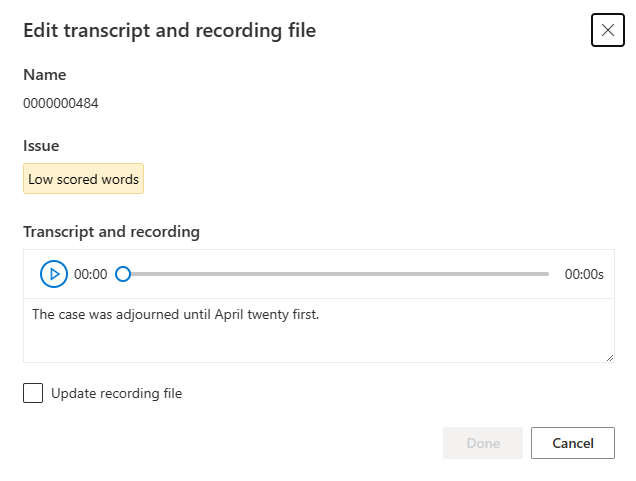
Frissítse az átiratot vagy a felvételfájlt a szerkesztési ablakban található problémaleírásnak megfelelően.
Szerkesztheti az átiratot a szövegmezőben, majd válassza a Kész lehetőséget
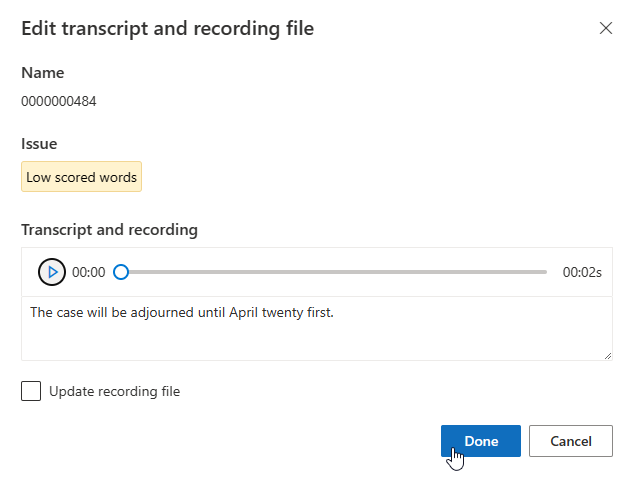
Ha frissítenie kell a felvételfájlt, válassza a Felvétel frissítése lehetőséget, majd töltse fel a rögzített felvételfájlt (.wav).
Miután módosította az adatokat, ellenőriznie kell az adatminőséget az Adatok elemzése gombra kattintva, mielőtt betanításra használták volna ezt az adatkészletet.
Az elemzés befejezése előtt nem választhatja ki ezt a betanítási csoportot a betanítási modellhez.
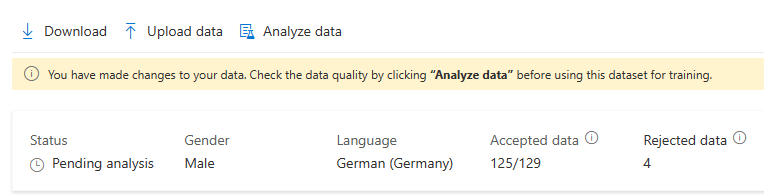
A problémákat tartalmazó kimondott szövegek törléséhez jelölje ki őket, és kattintson a Törlés gombra.
Jellemző adatproblémák
A problémák három típusra vannak osztva. A hibatípusok ellenőrzéséhez tekintse meg az alábbi táblázatokat.
Automatikusan elutasítva
Az ilyen hibákat tartalmazó adatok nem lesznek használatban a betanításhoz. A rendszer figyelmen kívül hagyja a hibákat tartalmazó importált adatokat, ezért nem kell törölnie őket. Ezeket az adathibákat online kijavíthatja, vagy újra feltöltheti a javított adatokat a betanításhoz.
| Kategória | Név | Leírás |
|---|---|---|
| Szkript | Érvénytelen elválasztó | A kimondott szöveg azonosítóját és a szkript tartalmát tabulátor karakterrel kell elválasztani. |
| Szkript | Érvénytelen szkriptazonosító | A szkriptsor azonosítójának numerikusnak kell lennie. |
| Szkript | Duplikált szkript | A szkript tartalmának minden sorának egyedinek kell lennie. A sor duplikálva van a következővel {}: . |
| Szkript | Túl hosszú szkript | A szkriptnek 1000 karakternél rövidebbnek kell lennie. |
| Szkript | Nincs egyező hang | Az egyes kimondott szövegek (a szkriptfájl minden sora) azonosítójának meg kell egyeznie a hangazonosítóval. |
| Szkript | Nincs érvényes szkript | Ebben az adatkészletben nem található érvényes szkript. Javítsa ki a részletes problémalistában megjelenő szkriptsorokat. |
| Hang | Nincs egyező szkript | Nincs olyan hangfájl, amely megegyezik a szkript azonosítójával. A .wav fájlok nevének meg kell egyeznie a szkriptfájl azonosítóival. |
| Hang | Érvénytelen hangformátum | A .wav fájlok hangformátuma érvénytelen. Ellenőrizze a .wav fájlformátumot egy olyan hangeszközzel, mint a SoX. |
| Hang | Alacsony mintavételezési sebesség | A .wav fájlok mintavételezési sebessége nem lehet alacsonyabb 16 KHz-nél. |
| Hang | Túl hosszú hang | A hang időtartama 30 másodpercnél hosszabb. Ossza fel a hosszú hangot több fájlra. Érdemes 15 másodpercnél rövidebbre tenni a kimondott szövegeket. |
| Hang | Nincs érvényes hang | Ebben az adatkészletben nem található érvényes hang. Ellenőrizze a hangadatokat, és töltse fel újra. |
| Eltérés | Alacsony pontszámú kimondott szöveg | A mondatszintű kiejtési pontszám kisebb, mint 70. Tekintse át a szkriptet és a hangtartalmat, hogy biztosan egyezzenek. |
Automatikusan javítva
A következő hibák automatikusan ki lettek javítva, de érdemes áttekinteni és ellenőrizni a javítások helyességét.
| Kategória | Név | Leírás |
|---|---|---|
| Eltérés | Automatikusan rögzített csend | A rendszer 100 ms-nál rövidebb indítási csendet észlel, és automatikusan 100 ms-ra bővítette. Töltse le a normalizált adathalmazt, és tekintse át. |
| Eltérés | Automatikusan rögzített csend | A rendszer azt észleli, hogy a végcsend 100 ms-nál rövidebb, és automatikusan 100 ms-ra lett kiterjesztve. Töltse le a normalizált adathalmazt, és tekintse át. |
| Szkript | Automatikusan normalizált szöveg | A szöveg automatikusan normalizálódik a számjegyek, szimbólumok és rövidítések esetében. Tekintse át a szkriptet és a hangot, és győződjön meg arról, hogy egyeznek. |
Manuális ellenőrzés szükséges
A következő táblázatban felsorolt megoldatlan hibák befolyásolják a betanítás minőségét, de az ilyen hibákat tartalmazó adatok nem lesznek kizárva a betanítás során. A jobb minőségű betanításhoz érdemes manuálisan kijavítani ezeket a hibákat.
| Kategória | Név | Leírás |
|---|---|---|
| Szkript | Nem normalizált szöveg | Ez a szkript szimbólumokat tartalmaz. Normalizálja a szimbólumokat a hangnak megfelelően. Például normalizálja / a perjelet. |
| Szkript | Nincs elég kérdőjel | A teljes kimondott szöveg legalább 10 százalékának kérdőjelnek kell lennie. Ez segít a hangmodellnek megfelelően kifejezni a kérdőjeleket. |
| Szkript | Nincs elég felkiáltójeles kimondott szöveg | A teljes kimondott szöveg legalább 10%-ának felkiáltójeles mondatnak kell lennie. Ez segít a hangmodellnek megfelelően kifejezni az izgatott hangot. |
| Szkript | Nincs érvényes záró írásjel | A sor végén adja hozzá az alábbi lehetőségek egyikét: teljes leállítás (félszélességű "." vagy teljes szélességű "。 '), felkiáltójel (félszélesség '!' vagy teljes szélességű '!' ), vagy kérdőjel ( félszélesség '?' vagy teljes szélességű '?'). |
| Hang | Alacsony mintavételezési arány a neurális hanghoz | Neurális hangok létrehozásához ajánlott, hogy a .wav fájlok mintavételezési sebessége legalább 24 KHz legyen. Ha alacsonyabb, a rendszer automatikusan 24 KHz-re emeli. |
| Térfogat | Túl alacsony a teljes kötet | A kötet nem lehet kisebb , mint -18 dB (a maximális kötet 10 százaléka). A mintarögzítés vagy adatelőkészítés során szabályozza a kötetek átlagos szintjét a megfelelő tartományon belül. |
| Térfogat | Kötet túlcsordult | A rendszer túlcsorduló kötetet észlel az s időpontban {}. Állítsa be a menetíró készüléket, hogy elkerülje a kötet túlcsordulását a csúcsértéken. |
| Térfogat | Elnémítási probléma indítása | Az első 100 ms csend nem tiszta. Csökkentse a rögzítési zajszintet, és hagyja az első 100 ms-t a kezdéskor. |
| Térfogat | Csenddel kapcsolatos probléma megoldása | Az utolsó 100 ms csend nem tiszta. Csökkentse a rögzítési zajszintet, és hagyja csendben az utolsó 100 ms-t. |
| Eltérés | Alacsony pontszámú szavak | Tekintse át a szkriptet és a hangtartalmat, hogy biztosan egyezzenek, és szabályozza a zajszintet. Csökkentse a hosszú hallgatás hosszát, vagy ossza fel a hangot több kimondott szövegre, ha túl hosszú. |
| Eltérés | Elnémítási probléma indítása | Az első szó előtt további hang hallható. Tekintse át a szkriptet és a hangtartalmat, hogy biztosan egyezzenek, szabályozhassa a zajszintet, és hogy az első 100 ms csendben legyen. |
| Eltérés | Csenddel kapcsolatos probléma megoldása | Az utolsó szó után további hang hallható. Tekintse át a szkriptet és a hangtartalmat, hogy biztosan egyezzenek, szabályozhassa a zajszintet, és az utolsó 100 ms csendben legyen. |
| Eltérés | Alacsony jel-zaj arány | A hang SNR szintje alacsonyabb, mint 20 dB. Legalább 35 dB ajánlott. |
| Eltérés | Nincs elérhető pontszám | Nem sikerült felismerni a hang beszédtartalmat. Ellenőrizze a hang és a szkript tartalmát, hogy a hang érvényes-e, és megegyezik-e a szkripttel. |
Következő lépések
A professzionális hang létrehozásához betanítási adatkészletre van szüksége. A betanítási adatkészlet hang- és szkriptfájlokat is tartalmaz. A hangfájlok a szkriptfájlokat olvasó hangtehetség felvételei. A szkriptfájlok a hangfájlok szövegei.
Ebben a cikkben létrehoz egy betanítási csoportot, és lekéri annak erőforrás-azonosítóját. Ezután az erőforrás-azonosító használatával hang- és szkriptfájlokat tölthet fel.
Betanítási csoport létrehozása
Betanítási csoport létrehozásához használja az egyéni hang API TrainingSets_Create műveletét. A kérelem törzsének összeállítása az alábbi utasítások szerint:
- Állítsa be a szükséges
projectIdtulajdonságot. Lásd: projekt létrehozása. - Állítsa be a szükséges tulajdonságot a következőre
voiceKindMale: vagyFemale. A típus később nem módosítható. - Állítsa be a szükséges
localetulajdonságot. Ennek kell lennie a betanítási csoport adatainak területi beállításának. A betanítási csoport területi beállításának meg kell egyeznie a hozzájárulási nyilatkozat területi beállításával. A területi beállítás később nem módosítható. A beszéd területi beállítási listáját itt találja. - Igény szerint állítsa be a
descriptionbetanítási csoport leírásának tulajdonságát. A betanítási csoport leírása később módosítható.
Hozzon létre egy HTTP PUT-kérést az URI használatával az alábbi TrainingSets_Create példában látható módon.
- Cserélje le
YourResourceKeya Speech erőforráskulcsot. - Cserélje le
YourResourceRegiona Speech erőforrásrégióját. - Cserélje le
JessicaTrainingSetIda kívánt betanítási csoportazonosítóra. A kis- és nagybetűk megkülönböztetett azonosítója a betanítási csoport URI-jában lesz használva, és később nem módosítható.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
A válasz törzsének a következő formátumban kell érkeznie:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Betanítási csoport adatainak feltöltése
Hang- és szkriptek betanítási készletének feltöltéséhez használja az egyéni hang API TrainingSets_UploadData műveletét.
Az API meghívása előtt tárolja a rögzítési és szkriptfájlokat az Azure Blobban. Az alábbi példában a fájlok rögzítése *.wav, a https://contoso.blob.core.windows.net/voicecontainer/jessica300/szkriptfájlok *.txt.https://contoso.blob.core.windows.net/voicecontainer/jessica300/
A kérelem törzsének összeállítása az alábbi utasítások szerint:
- Állítsa be a szükséges tulajdonságot a következőre
kindAudioAndScript: . A típus határozza meg a betanítási csoport típusát. - Állítsa be a szükséges
audiostulajdonságot. A tulajdonságonaudiosbelül állítsa be a következő tulajdonságokat:- Állítsa be a szükséges
containerUrltulajdonságot a hangfájlokat tartalmazó Azure Blob Storage-tároló URL-címére. Használjon közös hozzáférésű jogosultságkódokat (SAS) olvasási és listaengedélyekkel rendelkező tárolókhoz . - Állítsa be a szükséges
extensionstulajdonságot a hangfájlok bővítményére. - Ha szeretné, állítsa be a
prefixtulajdonságot a blobnév előtagjának beállítására.
- Állítsa be a szükséges
- Állítsa be a szükséges
scriptstulajdonságot. A tulajdonságonscriptsbelül állítsa be a következő tulajdonságokat:- Állítsa be a szükséges
containerUrltulajdonságot a szkriptfájlokat tartalmazó Azure Blob Storage-tároló URL-címére. Használjon közös hozzáférésű jogosultságkódokat (SAS) olvasási és listaengedélyekkel rendelkező tárolókhoz . - Állítsa be a szükséges
extensionstulajdonságot a szkriptfájlok bővítményére. - Ha szeretné, állítsa be a
prefixtulajdonságot a blobnév előtagjának beállítására.
- Állítsa be a szükséges
Hozzon létre egy HTTP POST-kérést az URI használatával az alábbi TrainingSets_UploadData példában látható módon.
- Cserélje le
YourResourceKeya Speech erőforráskulcsot. - Cserélje le
YourResourceRegiona Speech erőforrásrégióját. - Cserélje le
JessicaTrainingSetId, ha az előző lépésben egy másik betanítási csoportazonosítót adott meg.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
A válaszfejléc tartalmazza a tulajdonságot Operation-Location . Ezzel az URI-val részletes információkat kaphat a TrainingSets_UploadData műveletről. Íme egy példa a válaszfejlécre:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345