Örökölt MLflow-modell kiszolgálása az Azure Databricksben
Fontos
Ez a funkció a nyilvános előzetes verzióban érhető el.
Fontos
- Ez a dokumentáció ki lett állítva, és lehet, hogy nem frissül. A tartalomban említett termékek, szolgáltatások vagy technológiák már nem támogatottak.
- A cikk útmutatása az örökölt MLflow-modell-szolgáltatáshoz tartozik. A Databricks azt javasolja, hogy migrálja a modellkiszolgáló munkafolyamatait a Modellkiszolgálóba a modellvégpont továbbfejlesztett üzembe helyezése és méretezhetősége érdekében. További információ: Az Azure Databricks szolgáltatásmodellje.
Az örökölt MLflow modellkiszolgáló lehetővé teszi, hogy a modellregisztrációs adatbázisból származó gépi tanulási modelleket REST-végpontokként tárolja, amelyek automatikusan frissülnek a modellverziók és azok fázisai alapján. Egy egycsomópontos fürtöt használ, amely a saját fiókja alatt fut a klasszikus számítási síkon belül. Ez a számítási sík magában foglalja a virtuális hálózatot és a hozzá tartozó számítási erőforrásokat, például a jegyzetfüzetekhez és feladatokhoz készült fürtöket, a pro- és klasszikus SQL-raktárakat, valamint a végpontokat kiszolgáló örökölt modellt.
Ha engedélyezi a modell egy adott regisztrált modellhez való kiszolgálását, az Azure Databricks automatikusan létrehoz egy egyedi fürtöt a modellhez, és üzembe helyezi a modell összes nem archivált verzióját az adott fürtön. Az Azure Databricks újraindítja a fürtöt, ha hiba történik, és leállítja a fürtöt, amikor letiltja a modell modellszolgáltatását. A modellkiszolgáló automatikusan szinkronizálódik a Modellregisztrációs adatbázissal, és üzembe helyezi az új regisztrált modellverziókat. Az üzembe helyezett modellverziók standard REST API-kéréssel kérdezhetők le. Az Azure Databricks szabványos hitelesítéssel hitelesíti a modellhez érkező kéréseket.
Bár ez a szolgáltatás előzetes verzióban érhető el, a Databricks javasolja a használatát alacsony átviteli sebességhez és nem kritikus alkalmazásokhoz. A cél átviteli sebessége 200 qps, a cél rendelkezésre állása pedig 99,5%, bár egyikre sem vállalunk garanciát. Emellett kérelemenként 16 MB hasznos adatméret-korlát is rendelkezésre áll.
Minden modellverzió az MLflow-modell üzembe helyezésével van üzembe helyezve, és a függőségei által meghatározott Conda-környezetben fut.
Feljegyzés
- A fürt mindaddig megmarad, amíg a szolgáltatás engedélyezve van, még akkor is, ha nincs aktív modellverzió. A kiszolgálófürt leállításához tiltsa le a modellszolgáltatást a regisztrált modellhez.
- A fürt teljes körű fürtnek minősül, a számítási feladatok teljes körű díjszabása vonatkozik.
- A globális init szkriptek nem a fürtöket kiszolgáló modellen futnak.
Fontos
Az Anaconda Inc. frissítette anaconda.org csatornákra vonatkozó szolgáltatási feltételeit. Az új szolgáltatási feltételek alapján kereskedelmi licencre lehet szükség, ha az Anaconda csomagolására és terjesztésére támaszkodik. További információért tekintse meg az Anaconda Commercial Edition gyakori kérdéseit . Az Anaconda-csatornák használatára a szolgáltatási feltételek vonatkoznak.
Az 1.18-as verzió előtt naplózott MLflow-modellek (Databricks Runtime 8.3 ML vagy korábbi) alapértelmezés szerint függőségként lettek naplózva a conda defaults csatornával (https://repo.anaconda.com/pkgs/). A licencmódosítás miatt a Databricks leállította a csatorna használatát az defaults MLflow 1.18-s vagy újabb verziójával naplózott modellekhez. Az alapértelmezett naplózott csatorna most conda-forgemár a felügyelt https://conda-forge.org/közösségre mutat .
Ha az MLflow 1.18-a előtt naplózott egy modellt anélkül, hogy kizárta volna a defaults csatornát a modell Conda-környezetéből, előfordulhat, hogy a modell függőségben van a defaults nem kívánt csatornától.
Ha manuálisan szeretné ellenőrizni, hogy egy modell rendelkezik-e ezzel a függőséggel, megvizsgálhatja channel a conda.yaml naplózott modellbe csomagolt fájl értékét. Például egy csatornafüggőséggel rendelkező defaults modell conda.yaml a következőképpen nézhet ki:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Mivel a Databricks nem tudja megállapítani, hogy az Anaconda-adattár használata engedélyezett-e a modellek kezeléséhez az Anacondával való kapcsolat alatt, a Databricks nem kényszeríti az ügyfeleket semmilyen módosításra. Ha a Anaconda.com adattár használata a Databricks használatával engedélyezett az Anaconda feltételei szerint, nem kell semmilyen lépést tennie.
Ha módosítani szeretné a modell környezetében használt csatornát, újra regisztrálhatja a modellt a modellregisztrációs adatbázisba egy új conda.yamlbeállításjegyzékben. Ezt úgy teheti meg, hogy megadja a csatornát a conda_env paraméterben log_model().
Az API-val kapcsolatos log_model() további információkért tekintse meg az MLflow dokumentációját a modell által használt ízről, például a scikit-learn log_model.
A fájlokról conda.yaml további információt az MLflow dokumentációjában talál.
Követelmények
- Az örökölt MLflow-modell-szolgáltatás Python MLflow-modellekhez érhető el. A Conda-környezetben minden modellfüggőséget deklarálnia kell. Lásd a naplómodell függőségeit.
- A modellszolgáltatás engedélyezéséhez fürtlétrehozási engedéllyel kell rendelkeznie.
Modellkiszolgáló a Modellregisztrációs adatbázisból
A modellkiszolgáló az Azure Databricksben érhető el a Modellregisztrációs adatbázisból.
Modellkiszolgáló engedélyezése és letiltása
A modell a regisztrált modelloldalról való kiszolgáláshoz engedélyezve van.
Kattintson a Kiszolgálás fülre. Ha a modell még nincs engedélyezve a kiszolgáláshoz, megjelenik a Kiszolgáló engedélyezése gomb.
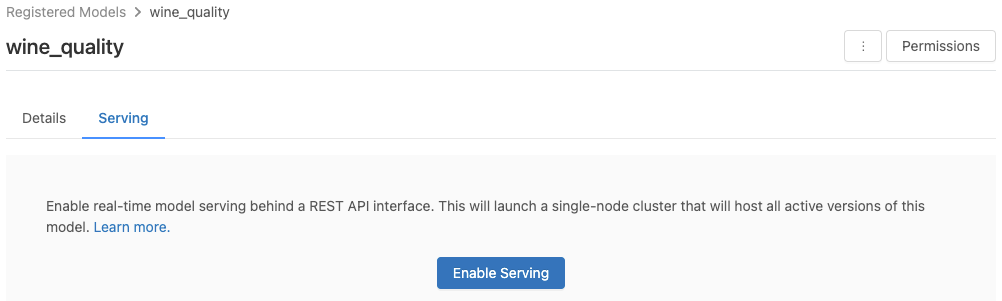
Kattintson a Kiszolgáló engedélyezése gombra. A Kiszolgáló lap a Függő állapot állapottal jelenik meg. Néhány perc múlva az állapot készre változik.
Ha le szeretne tiltani egy modellt a kiszolgáláshoz, kattintson a Leállítás gombra.
Modellkiszolgáló ellenőrzése
A Kiszolgálás lapon elküldhet egy kérést a kiszolgált modellnek, és megtekintheti a választ.
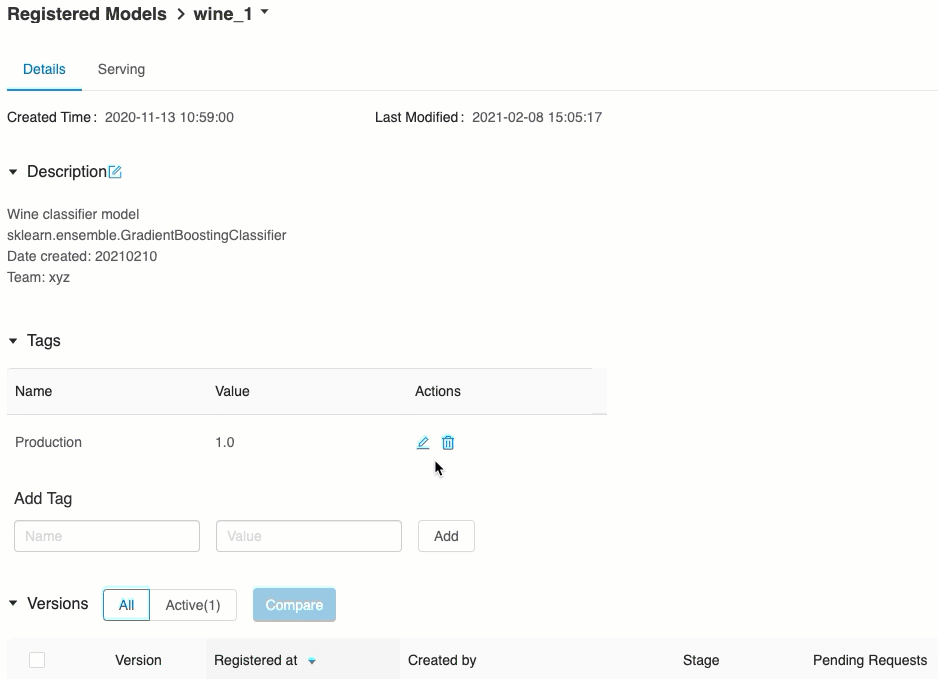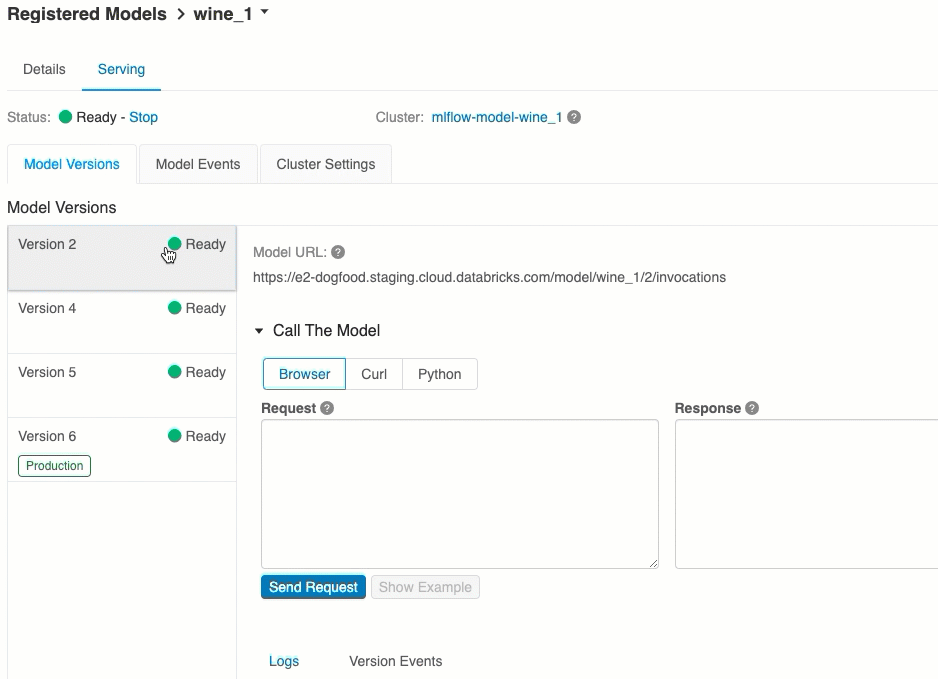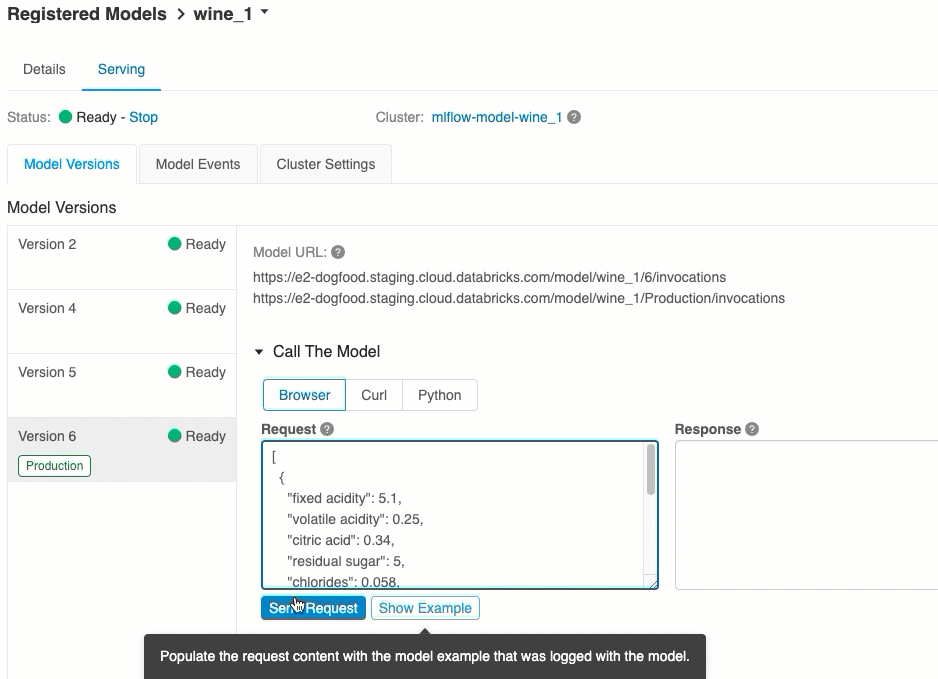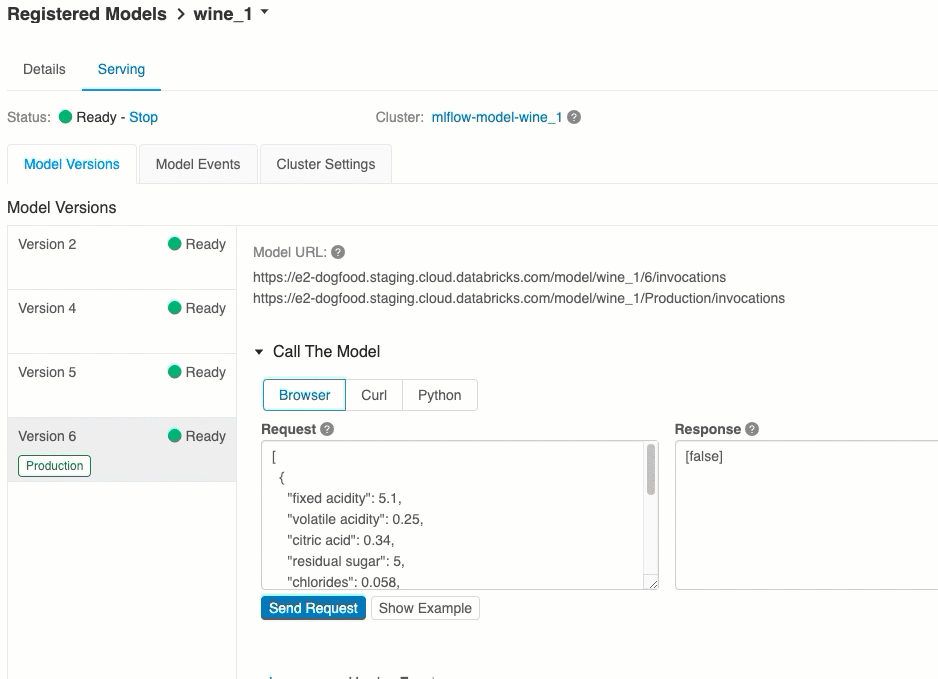
Modellverzió URI-k
Minden üzembe helyezett modellverzióhoz egy vagy több egyedi URI van hozzárendelve. Legalább minden modellverzióhoz az alábbiak szerint létrehozott URI van hozzárendelve:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Ha például egy regisztrált modell iris-classifier1- es verzióját szeretné meghívni, használja ezt az URI-t:
https://<databricks-instance>/model/iris-classifier/1/invocations
A modellverziót a szakasz szerint is meghívhatja. Ha például az 1. verzió az éles fázisban van, akkor az URI-val is pontozhat:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Az elérhető modell URI-k listája a kiszolgálóoldal Modellverziók lapjának tetején jelenik meg.
Kiszolgált verziók kezelése
A rendszer minden aktív (nem archivált) modellverziót üzembe helyez, és az URI-k használatával lekérdezheti őket. Az Azure Databricks automatikusan telepíti az új modellverziókat a regisztrációkor, és automatikusan eltávolítja a régi verziókat az archiválásukkor.
Feljegyzés
Egy regisztrált modell összes telepített verziója ugyanazt a fürtöt használja.
Modellhozzáférés-jogosultságok kezelése
A modell hozzáférési jogosultságai a modellregisztrációs adatbázisból öröklődnek. A szolgáltatás funkció engedélyezéséhez vagy letiltásához "kezelés" engedély szükséges a regisztrált modellen. Az olvasási jogosultsággal rendelkezők bármelyik telepített verziót pontszámmal láthatják el.
Üzembe helyezett modellverziók pontszáma
Egy üzembe helyezett modell pontozásához használhatja a felhasználói felületet, vagy elküldhet egy REST API-kérést a modell URI-jának.
Pontszám a felhasználói felületen keresztül
Ez a modell tesztelésének legegyszerűbb és leggyorsabb módja. Beszúrhatja a modell bemeneti adatait JSON formátumban, és kattintson a Kérés küldése gombra. Ha a modellt egy bemeneti példával naplózták (a fenti ábrán látható módon), kattintson a Példa betöltése gombra a bemeneti példa betöltéséhez.
Pontszám REST API-kéréssel
Pontozási kérést küldhet a REST API-val szabványos Databricks-hitelesítéssel. Az alábbi példák a személyes hozzáférési jogkivonattal történő hitelesítést mutatják be az MLflow 1.x használatával.
Feljegyzés
Ajánlott biztonsági eljárásként, ha automatizált eszközökkel, rendszerekkel, szkriptekkel és alkalmazásokkal hitelesít, a Databricks azt javasolja, hogy munkaterület-felhasználók helyett a szolgáltatásnevekhez tartozó személyes hozzáférési jogkivonatokat használja. A szolgáltatásnevek jogkivonatainak létrehozásáról a szolgáltatásnév jogkivonatainak kezelése című témakörben olvashat.
MODEL_VERSION_URI Egy hasonló https://<databricks-instance>/model/iris-classifier/Production/invocations (a <databricks-instance> Databricks-példány neve) és egy Databricks REST API-jogkivonat neve alapján DATABRICKS_API_TOKENaz alábbi példák bemutatják, hogyan kérdezhet le egy kiszolgált modellt:
Az alábbi példák az MLflow 1.x kóddal létrehozott modellek pontozási formátumát tükrözik. Ha az MLflow 2.0-t szeretné használni, frissítenie kell a kérelem hasznos adatformátumát.
Bash
Kódrészlet adatkeretbemeneteket elfogadó modell lekérdezéséhez.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Kódrészlet a tenzor bemeneteket elfogadó modell lekérdezéséhez. A Tensor-bemeneteket a TensorFlow-kiszolgáló API-dokumentációjában leírtak szerint kell formázni.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
A Power BI Desktopban az alábbi lépések végrehajtásával pontozást végezhet egy adatkészleten:
Nyissa meg a pontozáshoz használni kívánt adathalmazt.
Nyissa meg az Adatok átalakítása elemet.
Kattintson a jobb gombbal a bal oldali panelen, és válassza az Új lekérdezés létrehozása lehetőséget.
Nyissa meg a Speciális szerkesztő megtekintése > elemet.
Cserélje le a lekérdezés törzsét az alábbi kódrészletre a megfelelő és
MODEL_VERSION_URIa .DATABRICKS_API_TOKEN(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionAdja meg a lekérdezést a kívánt modellnévvel.
Nyissa meg az adathalmaz speciális lekérdezésszerkesztőt, és alkalmazza a modellfüggvényt.
Kiszolgált modellek monitorozása
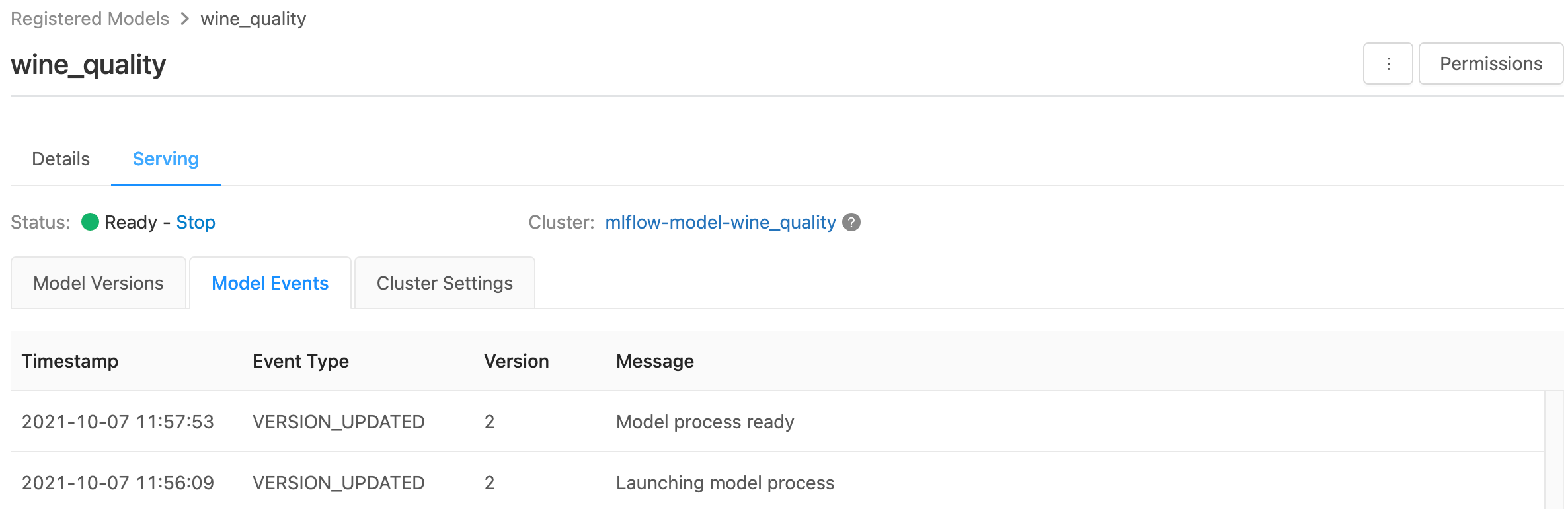
A kiszolgálóoldal megjeleníti a kiszolgálófürt állapotjelzőit, valamint az egyes modellverziókat.
- A kiszolgálófürt állapotának vizsgálatához használja a Modellesemények lapot, amely megjeleníti a modell összes kiszolgálói eseményének listáját.
- Egyetlen modellverzió állapotának vizsgálatához kattintson a Modellverziók fülre, és görgessen a Naplók vagy a Verzióesemények lap megtekintéséhez.
A kiszolgáló fürt testreszabása
A kiszolgálófürt testreszabásához használja a Kiszolgáló lap Fürt Gépház lapfülét.
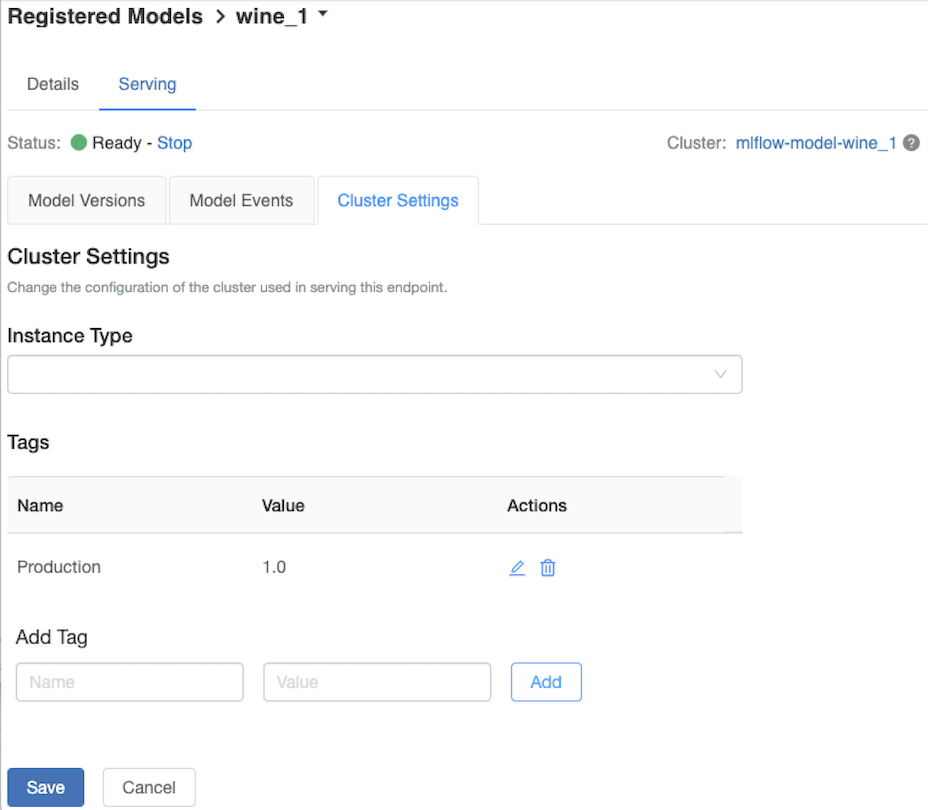
- A kiszolgálófürt memóriaméretének és magjainak számának módosításához válassza ki a kívánt fürtkonfigurációt a Példánytípus legördülő menüben. A Mentés gombra kattintva a meglévő fürt leáll, és létrejön egy új fürt a megadott beállításokkal.
- Címke hozzáadásához írja be a nevet és az értéket a Címke hozzáadása mezőbe, és kattintson a Hozzáadás gombra.
- Meglévő címke szerkesztéséhez vagy törléséhez kattintson a Címkék tábla Műveletek oszlopának egyik ikonjára.
Funkciótár-integráció
Az örökölt modellkiszolgálók automatikusan megkereshetik a közzétett online áruházak funkcióértékeit.
.. Aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Ismert hibák
ResolvePackageNotFound: pyspark=3.1.0
Ez a hiba akkor fordulhat elő, ha egy modell a pyspark Databricks Runtime 8.x használatával van naplózva.
Ha ezt a hibát látja, adja meg a pyspark verziót a modell naplózásakor a conda_env paraméter használatával.
Unrecognized content type parameters: format
Ez a hiba az új MLflow 2.0 pontozó protokollformátum miatt fordulhat elő. Ha ezt a hibát látja, valószínűleg elavult pontozási kérelemformátumot használ. A hiba elhárításához a következőt teheti:
Frissítse a pontozási kérelem formátumát a legújabb protokollra.
Feljegyzés
Az alábbi példák az MLflow 2.0-ban bevezetett pontozási formátumot tükrözik. Ha az MLflow 1.x-et szeretné használni, módosíthatja az
log_model()API-hívásokat úgy, hogy a paraméter tartalmazzaextra_pip_requirementsa kívánt MLflow-verziófüggőséget. Ezzel biztosítja a megfelelő pontozási formátum használatát.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
A pandas adatkeretbemeneteket elfogadó modell lekérdezése.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Lekérdezhet egy tenzor bemeneteket elfogadó modellt. A Tensor-bemeneteket a TensorFlow-kiszolgáló API-dokumentációjában leírtak szerint kell formázni.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
A Power BI Desktopban az alábbi lépések végrehajtásával pontozást végezhet egy adatkészleten:
Nyissa meg a pontozáshoz használni kívánt adathalmazt.
Nyissa meg az Adatok átalakítása elemet.
Kattintson a jobb gombbal a bal oldali panelen, és válassza az Új lekérdezés létrehozása lehetőséget.
Nyissa meg a Speciális szerkesztő megtekintése > elemet.
Cserélje le a lekérdezés törzsét az alábbi kódrészletre a megfelelő és
MODEL_VERSION_URIa .DATABRICKS_API_TOKEN(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionAdja meg a lekérdezést a kívánt modellnévvel.
Nyissa meg az adathalmaz speciális lekérdezésszerkesztőt, és alkalmazza a modellfüggvényt.
Ha a pontozási kérelem az MLflow-ügyfelet használja, például
mlflow.pyfunc.spark_udf()frissítse az MLflow-ügyfelet a 2.0-s vagy újabb verzióra a legújabb formátum használatához. További információ a frissített MLflow-modell pontozási protokolljáról az MLflow 2.0-ban.
A kiszolgáló által elfogadott bemeneti adatformátumokról (például a pandas osztott orientált formátumáról) az MLflow dokumentációjában talál további információt.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: