Compute
Az Azure Databricks compute az Azure Databricks-munkaterületen elérhető számítási erőforrások kiválasztására utal. A felhasználóknak hozzáférésre van szükségük a számításhoz az adatelemzési, adatelemzési és adatelemzési számítási feladatok, például az éles ETL-folyamatok, a streamelt elemzések, az alkalmi elemzések és a gépi tanulás futtatásához.
A felhasználók csatlakozhatnak a meglévő számításhoz, vagy létrehozhatnak új számítást, ha rendelkeznek a megfelelő engedélyekkel.
A munkaterület Számítási szakaszának használatával megtekintheti azt a számítást, amelyhez hozzáféréssel rendelkezik:
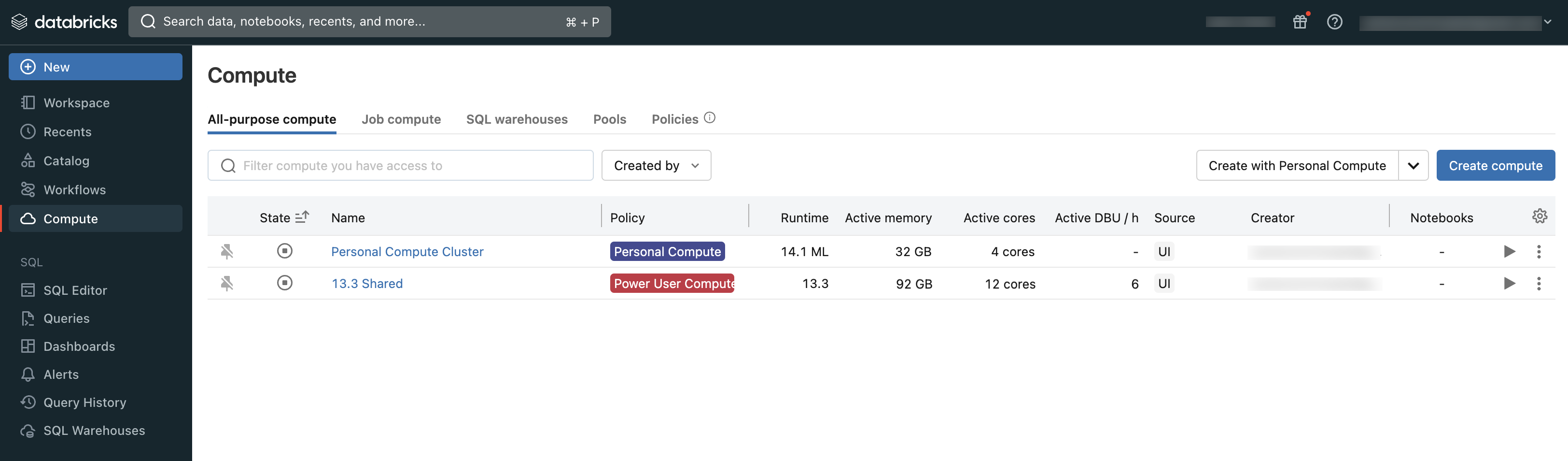
A számítás típusai
Az Azure Databricksben elérhető számítási típusok a következők:
Kiszolgáló nélküli számítás jegyzetfüzetekhez (nyilvános előzetes verzió): Igény szerinti, méretezhető számítás sql- és Python-kód notebookokban való végrehajtásához.
Kiszolgáló nélküli számítás munkafolyamatokhoz (nyilvános előzetes verzió): Igény szerinti, méretezhető számítás a Databricks-feladatok futtatásához infrastruktúra konfigurálása és üzembe helyezése nélkül.
Teljes célú számítás: A jegyzetfüzetekben lévő adatok elemzéséhez használt kiépített számítás. Ezt a számítást a felhasználói felület, a parancssori felület vagy a REST API használatával hozhatja létre, állíthatja le és indíthatja újra.
Feladat számítása: Automatizált feladatok futtatásához használt kiépített számítás. Az Azure Databricks-feladatütemező automatikusan létrehoz egy feladat-számítást, amikor egy feladat új számítási feladat futtatására van konfigurálva. A számítás a feladat befejezésekor leáll. Feladatszámítás nem indítható újra. Lásd: Az Azure Databricks számítási feladatainak használata.
Példánykészletek: Számítás tétlen, használatra kész példányokkal, az indítási és az automatikus skálázási idő csökkentésére. Ezt a számítást a felhasználói felületen, a parancssori felületen vagy a REST API-val hozhatja létre.
Kiszolgáló nélküli SQL-tárolók: Igény szerinti rugalmas számítás, amellyel SQL-parancsokat futtathat adatobjektumokon az SQL-szerkesztőben vagy interaktív jegyzetfüzetekben. SQL-raktárakat a felhasználói felületen, a parancssori felületen vagy a REST API-val hozhat létre.
Klasszikus SQL-tárolók: SQL-parancsok futtatására szolgál adatobjektumokon az SQL-szerkesztőben vagy interaktív jegyzetfüzetekben. SQL-raktárakat a felhasználói felületen, a parancssori felületen vagy a REST API-val hozhat létre.
Az ebben a szakaszban található cikkek bemutatják, hogyan használható számítási erőforrások az Azure Databricks felhasználói felületén. További módszerekért tekintse meg a Databricks parancssori felületét és a Databricks REST API-referenciát.
A Databricks futtatókörnyezete
A Databricks Runtime a számításon futó alapvető összetevők halmaza. A Databricks Runtime egy konfigurálható beállítás a feladatok számításának minden céljára, de automatikusan ki van jelölve az SQL-raktárakban.
Minden Databricks Runtime-verzió olyan frissítéseket tartalmaz, amelyek javítják a big data-elemzések használhatóságát, teljesítményét és biztonságát. A számítási databricks-futtatókörnyezet számos funkciót tartalmaz, többek között a következőket:
- Delta Lake, az Apache Sparkra épülő következő generációs tárolási réteg, amely ACID-tranzakciókat, optimalizált elrendezéseket és indexeket, valamint végrehajtási motorfejlesztéseket biztosít az adatfolyamok létrehozásához. Lásd : Mi az a Delta Lake?.
- Telepített Java-, Scala-, Python- és R-kódtárak.
- Az Ubuntu és a hozzá tartozó rendszerkódtárak.
- GPU-kompatibilis fürtök GPU-kódtárai.
- Azure Databricks-szolgáltatások, amelyek integrálhatók a platform más összetevőivel, például jegyzetfüzetekkel, feladatokkal és fürtkezeléssel.
Az egyes futtatókörnyezeti verziók tartalmával kapcsolatos információkért tekintse meg a kibocsátási megjegyzéseket.
Futtatókörnyezet verziószámozása
A Databricks Runtime-verziók rendszeresen jelennek meg:
- A hosszú távú támogatási verziókat LTS-minősítő (például 3,5 LTS) jelöli. Minden nagyobb kiadáshoz "canonical" funkcióverziót deklarálunk, amelyhez három teljes éves támogatást biztosítunk. További információkért tekintse meg a Databricks futtatókörnyezet támogatási életciklusait .
- A főverziókat a tizedesvesszőt megelőző verziószám növekménye (például 3,5-ről 4,0-ra ugrás). Ezek nagyobb módosítások esetén jelennek meg, amelyek némelyike nem feltétlenül kompatibilis visszafelé.
- A funkcióverziókat a tizedesvesszőt követő verziószám növekménye (például 3,4-ről 3,5-ösre ugrás). Minden nagyobb kiadás több funkciókiadást is tartalmaz. A funkciókiadások mindig kompatibilisek a korábbi kiadásokkal a fő kiadásukon belül.
Mi az a kiszolgáló nélküli számítás?
A kiszolgáló nélküli számítás a következő módokon javítja a termelékenységet, a költséghatékonyságot és a megbízhatóságot:
- Termelékenység: A felhőbeli erőforrásokat az Azure Databricks felügyeli, csökkentve a felügyeleti terheket, és azonnali számítást biztosít a felhasználók termelékenységének növelése érdekében.
- Hatékonyság: A kiszolgáló nélküli számítás gyors indítási és skálázási időt kínál, minimalizálja az üresjárati időt, és biztosítja, hogy csak a használt számításért kell fizetnie.
- Megbízhatóság: A kiszolgáló nélküli számítás, a kapacitáskezelés, a biztonság, a javítás és a frissítés automatikusan történik, ami enyhíti a biztonsági szabályzatokkal és a kapacitáshiánnyal kapcsolatos aggodalmakat.
Mik azok a kiszolgáló nélküli SQL Warehouse-k?
A Databricks SQL optimális árat és teljesítményt nyújt kiszolgáló nélküli SQL-raktárakkal. A kiszolgáló nélküli raktárak fő előnyei a pro és a klasszikus modellekkel szemben:
- Azonnali és rugalmas számítás: Kiküszöböli az infrastruktúra-erőforrásokra való várakozást, és elkerüli az erőforrások túlkiépítését a kihasználtsági csúcsok során. Az intelligens számítási feladatok kezelése dinamikusan kezeli a skálázást. Az intelligens számítási feladatok kezelésével és más kiszolgáló nélküli funkciókkal kapcsolatos további információkért tekintse meg az SQL Warehouse típusait .
- Minimális felügyeleti többletterhelés: A kapacitáskezelést, a javításokat, a frissítéseket és a teljesítményoptimalizálást az Azure Databricks kezeli, leegyszerűsítve a műveleteket, és kiszámítható díjszabást eredményez.
- Alacsonyabb teljes bekerülési költség (TCO): Az erőforrások szükség szerinti automatikus kiépítése és skálázása segít elkerülni a túlkiépítést, és csökkenti az üresjárati időket, ezáltal csökkentve a TCO-t.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: