Bináris fájl
A Databricks Runtime támogatja a bináris fájl adatforrását, amely bináris fájlokat olvas be, és az egyes fájlokat egyetlen rekordmá alakítja, amely tartalmazza a fájl nyers tartalmát és metaadatait. A bináris fájl adatforrása a következő oszlopokkal és esetleg partícióoszlopokkal hoz létre DataFrame-et:
path (StringType): A fájl elérési útja.modificationTime (TimestampType): A fájl módosítási ideje. Egyes Hadoop FileSystem-implementációkban előfordulhat, hogy ez a paraméter nem érhető el, és az érték alapértelmezett értékre van állítva.length (LongType): A fájl hossza bájtban.content (BinaryType): A fájl tartalma.
Bináris fájlok olvasásához adja meg az adatforrást format a következőként binaryFile: .
Képek
A Databricks azt javasolja, hogy a bináris fájl adatforrásával töltsön be képadatokat.
A Databricks display függvény támogatja a bináris adatforrással betöltött képadatok megjelenítését.
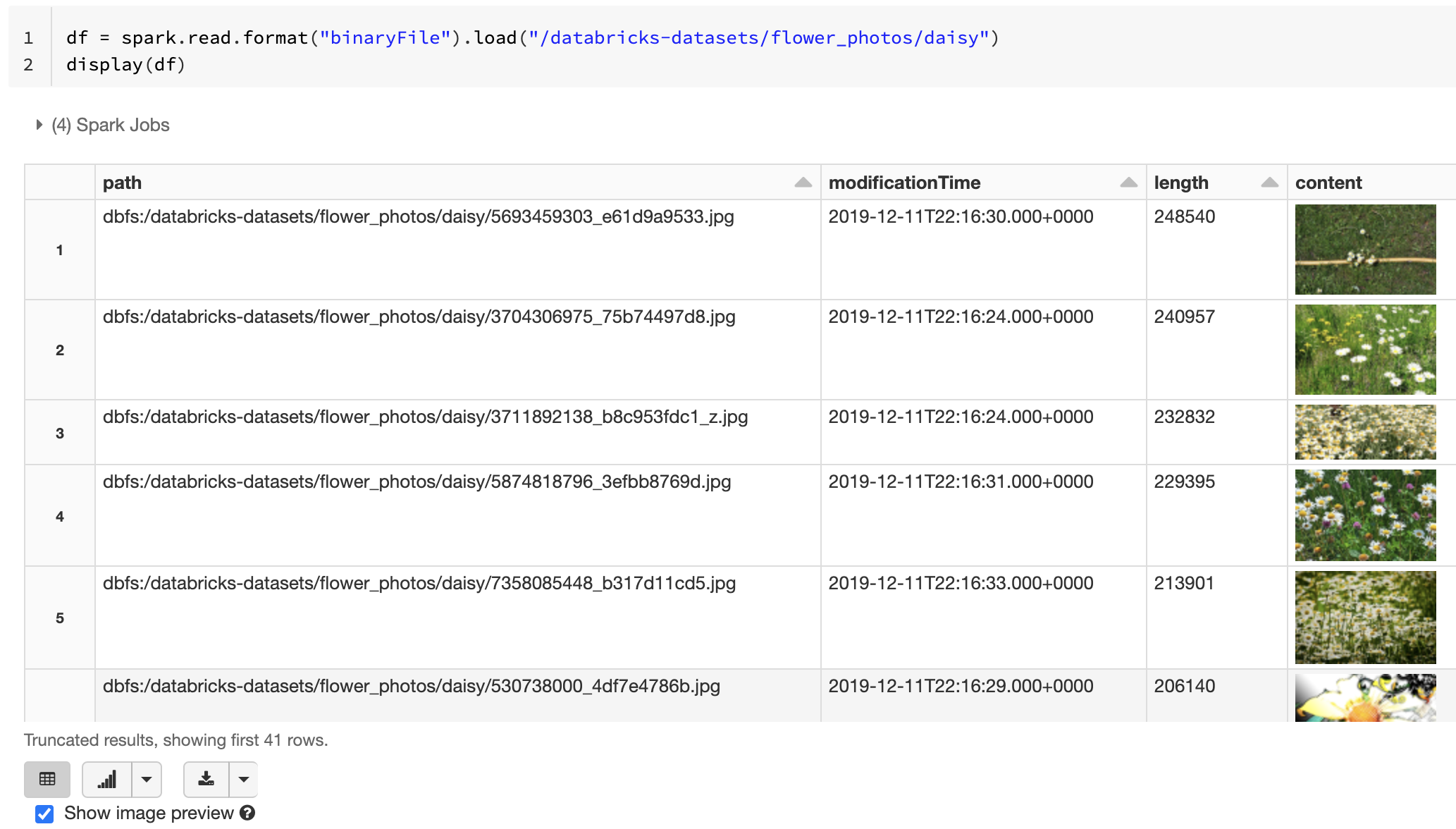
Ha az összes betöltött fájl rendelkezik képkiterjesztéssel rendelkező fájlnévvel, a rendszer automatikusan engedélyezi a kép előnézetét:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
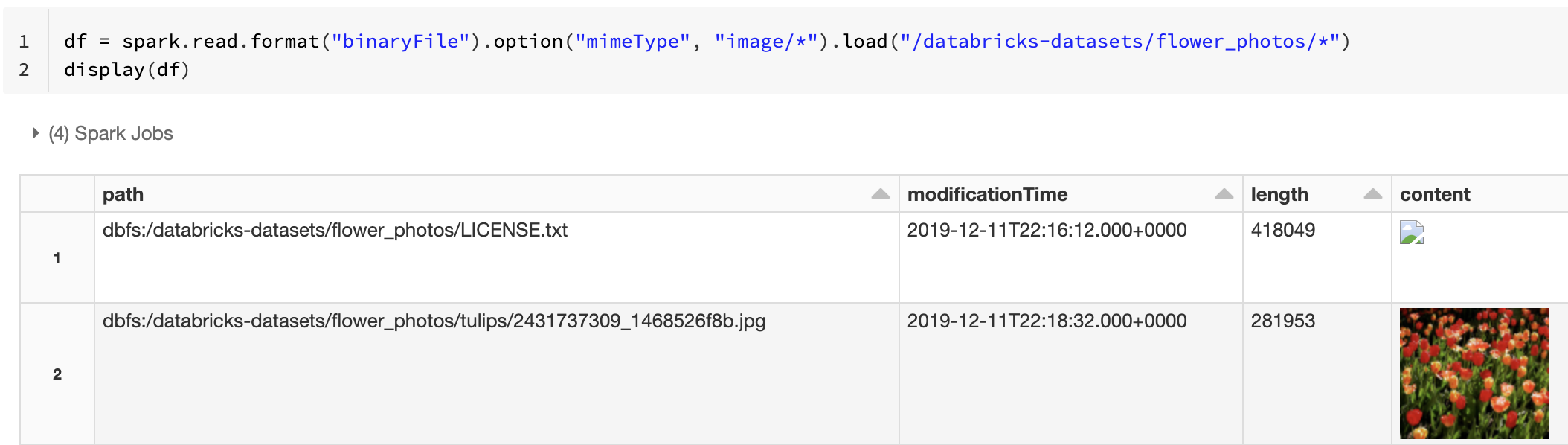
A kép előnézeti funkcióját úgy is kényszerítheti, hogy a mimeType bináris oszlopot sztringértékkel "image/*" adhatja meg. A rendszer a képeket a bináris tartalom formátumadatai alapján dekódolja. A támogatott képtípusok a következőkbmp: , gifjpegés png. A nem támogatott fájlok hibás képikonként jelennek meg.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Lásd : Referenciamegoldás képalkalmazásokhoz az ajánlott munkafolyamathoz a képadatok kezeléséhez.
Beállítások
Ha egy adott lobmintának megfelelő elérési utakkal szeretné betölteni a fájlokat, miközben megtartja a partíciófelderítés viselkedését, használhatja a pathGlobFilter lehetőséget. Az alábbi kód beolvassa az összes JPG-fájlt a bemeneti könyvtárból partíciófelderítéssel:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Ha figyelmen kívül szeretné hagyni a partíciófelderítést, és rekurzív módon keres fájlokat a bemeneti könyvtárban, használja a recursiveFileLookup lehetőséget. Ez a beállítás akkor is megkeresi a beágyazott könyvtárakat, ha a nevük nem követi az olyan partícióelnevezési sémát, mint a date=2019-07-01.
Az alábbi kód az összes JPG-fájlt rekurzívan olvassa be a bemeneti könyvtárból, és figyelmen kívül hagyja a partíciófelderítést:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Hasonló API-k léteznek a Scala, a Java és az R esetében.
Megjegyzés:
Az adatok visszatöltésekor az olvasási teljesítmény javítása érdekében az Azure Databricks azt javasolja, hogy kapcsolja ki a tömörítést a bináris fájlokból betöltött adatok mentésekor:
spark.conf.set("spark.sql.parquet.compression.codec", "uncompressed")
df.write.format("delta").save("<path-to-table>")