Azure HDInsight-fürtök automatikus skálázása
Az Azure HDInsight ingyenes automatikus skálázási funkciója automatikusan növelheti vagy csökkentheti a fürt feldolgozó csomópontjainak számát az ügyfelek által elfogadott fürtmetrikák és skálázási szabályzatok alapján. Az automatikus skálázási funkció úgy működik, hogy a csomópontok számát az előre beállított korlátokon belül skálázza a teljesítménymetrikák vagy a vertikális felskálázási és vertikális leskálázási műveletek meghatározott ütemezése alapján
Működés
Az automatikus skálázási funkció kétféle feltételt használ a skálázási események aktiválásához: a különböző fürtteljesítmény-metrikák küszöbértékei (az úgynevezett terhelésalapú skálázás) és az időalapú eseményindítók (ütemezésalapú skálázás). A terhelésalapú skálázás megváltoztatja a fürt csomópontjainak számát a beállított tartományon belül, hogy biztosítsa az optimális processzorhasználatot, és minimalizálja a futási költségeket. Az ütemezésalapú skálázás a vertikális felskálázási és vertikális leskálázási műveletek ütemezése alapján módosítja a fürt csomópontjainak számát.
Az alábbi videó áttekintést nyújt azokról a kihívásokról, amelyeket az automatikus skálázás megold, és hogyan segíthet a HDInsight költségeinek szabályozásában.
Terhelésalapú vagy ütemezésalapú skálázás kiválasztása
Ütemezésalapú skálázás használható:
- Ha a feladatok várhatóan rögzített ütemezés szerint és kiszámítható ideig futnak, vagy ha a nap meghatározott időszakaiban alacsony használatot vár, például teszt- és fejlesztői környezeteket a munkaidő utáni, a nap végén végzett feladatokban.
Terhelésalapú skálázás használható:
- Amikor a terhelési minták napközben jelentősen és kiszámíthatatlanul ingadoznak. Például az adatfeldolgozás megrendelése véletlenszerű ingadozásokkal a terhelési mintákban különböző tényezők alapján
Fürtmetrikák
Az automatikus skálázás folyamatosan figyeli a fürtöt, és összegyűjti a következő metrikákat:
| Metrika | Leírás |
|---|---|
| Összes függőben lévő CPU | Az összes függőben lévő tároló végrehajtásának megkezdéséhez szükséges magok teljes száma. |
| Teljes függőben lévő memória | Az összes függőben lévő tároló végrehajtásának megkezdéséhez szükséges teljes memória (MB-ban). |
| Teljes ingyenes CPU | Az aktív feldolgozó csomópontok összes nem használt magjának összege. |
| Teljes szabad memória | A nem használt memória (MB-ban) összege az aktív feldolgozó csomópontokon. |
| Használt memória csomópontonként | A munkavégző csomópont terhelése. A feldolgozó csomópont, amelyen 10 GB memóriát használnak, nagyobb terhelés alatt van, mint egy 2 GB memóriával rendelkező feldolgozó. |
| Az alkalmazás főkiszolgálóinak száma csomópontonként | A feldolgozó csomóponton futó Application Master (AM) tárolók száma. A két AM-tárolót üzemeltető feldolgozó csomópont fontosabb, mint a nulla AM tárolókat üzemeltető feldolgozó csomópont. |
A fenti metrikákat 60 másodpercenként ellenőrzi a rendszer. Az automatikus skálázás ezen metrikák alapján vertikális fel- és leskálázási döntéseket hoz.
Terhelésalapú méretezési feltételek
A következő feltételek észlelésekor az automatikus skálázás skálázási kérést ad ki:
| Vertikális felskálázás | Leskálázás |
|---|---|
| A teljes függőben lévő CPU több mint 3–5 percig meghaladja a teljes ingyenes CPU-t. | A függőben lévő processzorok teljes száma kevesebb, mint 3–5 perc alatt. |
| A teljes függőben lévő memória több mint 3–5 perc szabad memória. | A teljes függőben lévő memória kevesebb, mint 3–5 perc szabad memória. |
A vertikális felskálázáshoz az automatikus skálázás felskálázási kérelmet ad ki a szükséges számú csomópont hozzáadásához. A vertikális felskálázás azon alapul, hogy hány új feldolgozó csomópontra van szükség az aktuális processzor- és memóriakövetelmények teljesítéséhez.
A vertikális leskálázás esetén az automatikus skálázás kérést küld bizonyos csomópontok eltávolítására. A leskálázás az Application Master (AM) tárolók csomópontonkénti számán alapul. És az aktuális processzor- és memóriakövetelmények. A szolgáltatás azt is észleli, hogy mely csomópontok legyenek eltávolításra jelölt csomópontok az aktuális feladat végrehajtása alapján. A vertikális leskálázási művelet először leszereli a csomópontokat, majd eltávolítja őket a fürtből.
Az Ambari DB méretezési szempontjai az automatikus skálázáshoz
Javasoljuk, hogy az Ambari DB megfelelően legyen méretezve az automatikus skálázás előnyeinek kihasználásához. Az ügyfeleknek a megfelelő ADATBÁZIS-szintet kell használniuk, és az egyéni Ambari DB-t kell használniuk a nagy méretű fürtökhöz. Olvassa el az Adatbázis és a Headnode méretezési javaslatait.
Fürtkompatibilitás
Fontos
Az Azure HDInsight automatikus skálázási funkciója 2019. november 7. óta általánosan elérhető a Spark- és Hadoop-fürtökhöz, és olyan fejlesztéseket tartalmaz, amelyek a funkció előzetes verziójában nem voltak elérhetők. Ha a 2019. november 7. előtt létrehozott egy Spark-fürtöt, és használni szeretné rajta az automatikus skálázási funkciót, akkor azt az eljárást javasoljuk, hogy hozzon létre egy új fürtöt, és azon engedélyezze az automatikus skálázást.
Az Interaktív lekérdezés automatikus méretezése (LLAP) 2020. augusztus 27-én jelent meg a HDI 4.0 általános elérhetőségéhez. Az automatikus skálázás csak Spark, Hadoop és Interactive Query fürtökön érhető el
Az alábbi táblázat az automatikus skálázási funkcióval kompatibilis fürttípusokat és -verziókat ismerteti.
| Verzió | Spark | Hive | Interaktív lekérdezés | A HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 ESP nélkül | Igen | Igen | Igen* | Nem | Nem |
| HDInsight 4.0 ESP-vel | Igen | Igen | Igen* | Nem | Nem |
| HDInsight 5.0 ESP nélkül | Igen | Igen | Igen* | Nem | Nem |
| HDInsight 5.0 ESP-vel | Igen | Igen | Igen* | Nem | Nem |
* Az interaktív lekérdezésfürtök csak ütemezésalapú skálázásra konfigurálhatók, terhelésalapúak nem.
Első lépések
Fürt létrehozása terhelésalapú automatikus skálázással
Az automatikus skálázási funkció terhelésalapú skálázással való engedélyezéséhez hajtsa végre a következő lépéseket a normál fürtlétrehozási folyamat részeként:
A Konfiguráció + díjszabás lapon jelölje be az Automatikus skálázás engedélyezése jelölőnégyzetet.
Válassza a Terhelésalapú lehetőséget az Automatikus skálázás típus alatt.
Adja meg a következő tulajdonságok kívánt értékeit:
- A feldolgozó csomópont csomópontjainakkezdeti száma.
- Munkavégző csomópontok minimális száma.
- Feldolgozó csomópontok maximális száma.
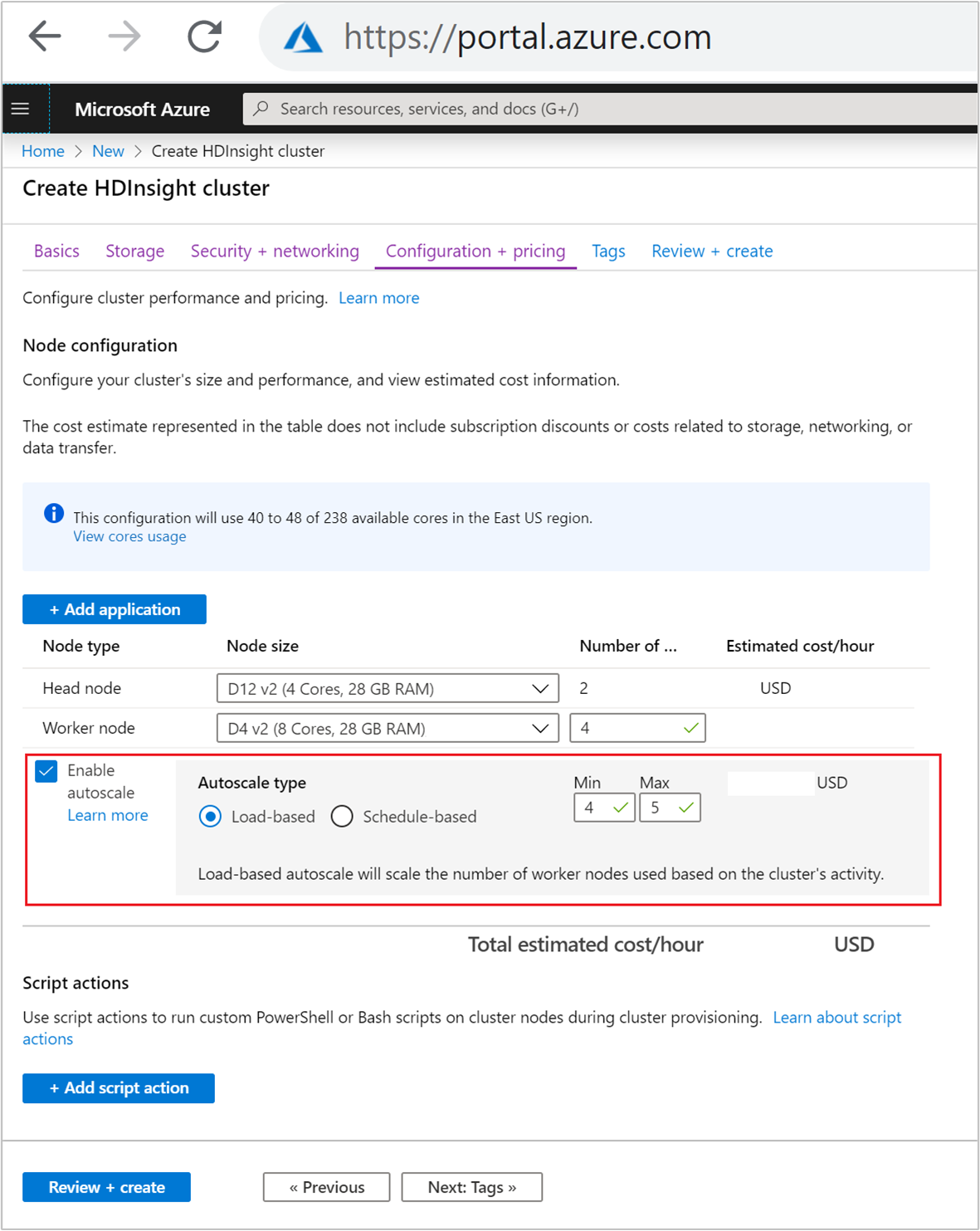
A feldolgozó csomópontok kezdeti számának a minimum és a maximum közé kell esnie, beleértve azokat is. Ez az érték határozza meg a fürt kezdeti méretét a létrehozásakor. A feldolgozó csomópontok minimális számát három vagy többre kell állítani. Ha a fürt három csomópontnál kevesebbre van skálázva, az a nem megfelelő fájlreplikálás miatt csökkentett módban elakadhat. További információ: Elakadás csökkentett módban.
Fürt létrehozása ütemezésalapú automatikus skálázással
Az automatikus skálázási funkció ütemezésalapú skálázással való engedélyezéséhez hajtsa végre a következő lépéseket a normál fürtlétrehozási folyamat részeként:
A Konfiguráció + díjszabás lapon jelölje be az Automatikus skálázás engedélyezése jelölőnégyzetet.
Adja meg a feldolgozó csomópont csomópontjainak számát, amely szabályozza a fürt felskálázásának korlátját.
Válassza az Ütemezés alapú lehetőséget az Automatikus skálázás típus alatt.
Válassza a Konfigurálás lehetőséget az automatikus skálázási konfigurációs ablak megnyitásához.
Jelölje ki az időzónát, majd kattintson a + Feltétel hozzáadása elemre
Válassza ki a hét azon napjait, amelyekre az új feltételnek vonatkoznia kell.
Szerkessze a feltétel érvénybe lépésének időpontját, valamint a fürtöt skálázni kívánt csomópontok számát.
Szükség esetén adjon hozzá további feltételeket.
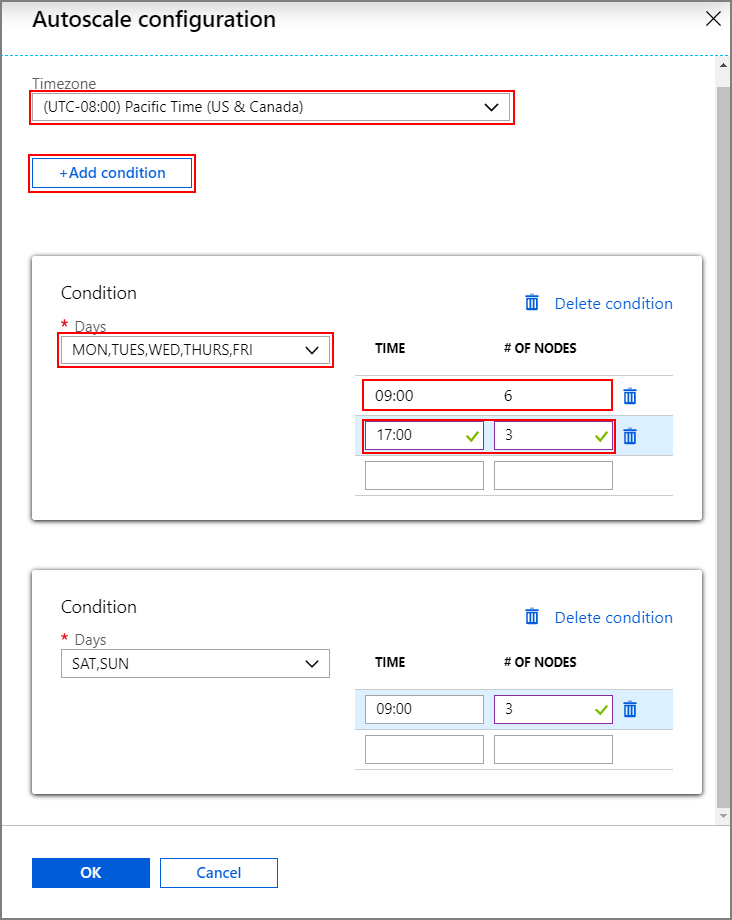
A csomópontok számának 3 és a feltételek hozzáadása előtt megadott feldolgozó csomópontok maximális számának kell lennie.
Végleges létrehozási lépések
A munkavégző csomópontok virtuális géptípusának kiválasztásához válasszon ki egy virtuális gépet a Csomópontméret legördülő listából. Miután kiválasztotta az egyes csomóponttípusokhoz tartozó virtuálisgép-típust, láthatja a teljes fürt becsült költségtartományát. Módosítsa a virtuálisgép-típusokat a költségvetésnek megfelelően.
Az előfizetés minden régióhoz rendelkezik kapacitáskvótát. A fő csomópontok magjainak teljes száma és a maximális feldolgozó csomópontok száma nem haladhatja meg a kapacitáskvótát. Ez a kvóta azonban egy helyreállítható korlát; mindig létrehozhat egy támogatási jegyet, hogy könnyebben növekedjen.
Feljegyzés
Ha túllépi a teljes magkvótakorlátot, hibaüzenet jelenik meg, amely szerint "a maximális csomópont túllépte a régióban elérhető magokat, válasszon másik régiót, vagy lépjen kapcsolatba az ügyfélszolgálattal a kvóta növeléséhez".
További információ a HDInsight-fürtök Azure Portalon történő létrehozásáról: Linux-alapú fürtök létrehozása a HDInsightban az Azure Portal használatával.
Fürt létrehozása Resource Manager-sablonnal
Terhelésalapú automatikus skálázás
HdInsight-fürtöt hozhat létre egy Azure Resource Manager-sablon terhelésalapú automatikus skálázásával, ha hozzáad egy autoscale csomópontot a computeProfileworkernode>szakaszhoz a json-kódrészletben látható tulajdonságokkal.minInstanceCountmaxInstanceCount Egy teljes Resource Manager-sablonért tekintse meg a gyorsútmutató-sablont: Spark-fürt üzembe helyezése terhelésalapú automatikus skálázással engedélyezve.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Ütemezésalapú automatikus skálázás
Létrehozhat egy HDInsight-fürtöt egy Azure Resource Manager-sablon ütemezésalapú automatikus skálázásával, ha hozzáad egy csomópontot autoscale a computeProfile>workernode szakaszhoz. A autoscale csomópont tartalmaz egy olyan csomópontot timezonerecurrence, amely tartalmazza a módosítást, és schedule amely leírja, hogy mikor történik a módosítás. Egy teljes Resource Manager-sablonért lásd : Spark-fürt üzembe helyezése ütemezésalapú automatikus skálázással engedélyezve.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Futó fürt automatikus skálázásának engedélyezése és letiltása
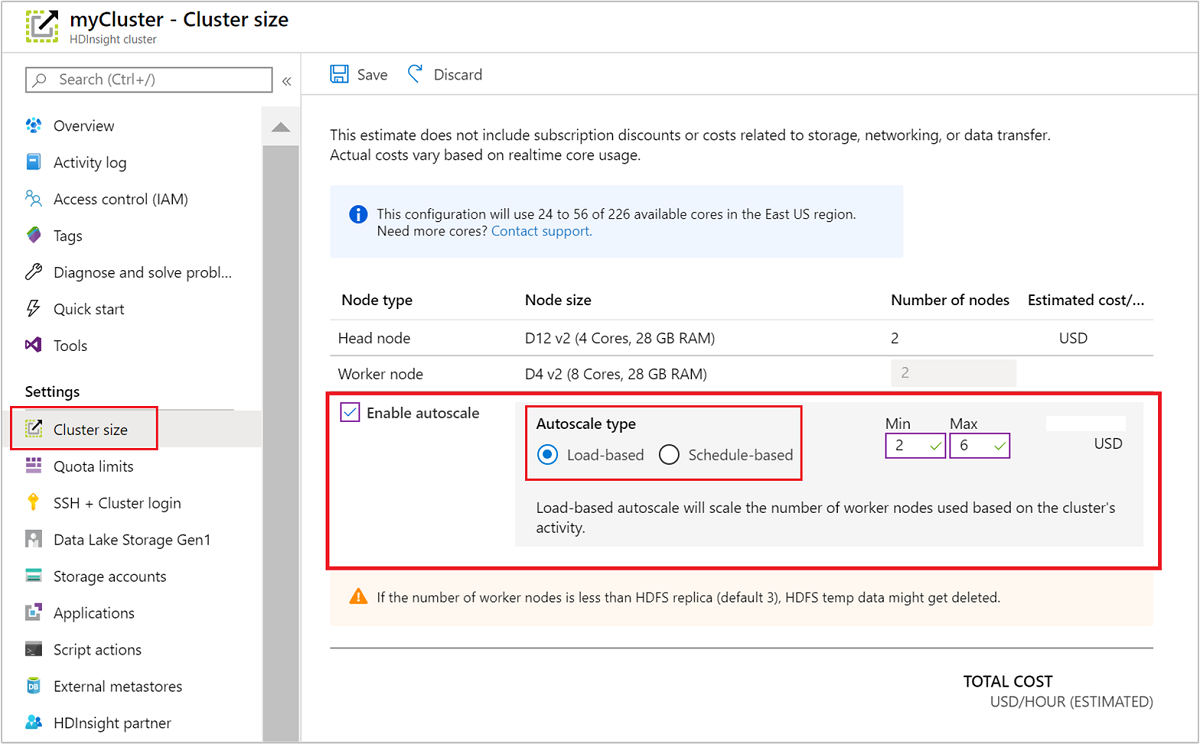
Az Azure Portal használatával
Ha engedélyezni szeretné az automatikus skálázást egy futó fürtön, válassza a fürtméretet a Gépház alatt. Ezután válassza az Automatikus skálázás engedélyezése lehetőséget. Válassza ki a kívánt automatikus skálázási típust, és adja meg a terhelésalapú vagy ütemezésalapú skálázás beállításait. Végül válassza a Mentés lehetőséget.
A REST API használata
Ha engedélyezni vagy letiltani szeretné az automatikus skálázást egy futó fürtön a REST API használatával, küldjön POST-kérést az automatikus skálázási végpontra:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Használja a megfelelő paramétereket a kérelem hasznos adatai között. Az automatikus skálázás engedélyezéséhez az alábbi json hasznos adatok használhatók. A hasznos adatok {autoscale: null} használatával tiltsa le az automatikus skálázást.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Az összes hasznos adatparaméter teljes leírását a terhelésalapú automatikus skálázás engedélyezéséről szóló előző szakaszban találja. Nem ajánlott az automatikus skálázási szolgáltatást kényszerítetten letiltani egy futó fürtön.
Automatikus skálázási tevékenységek figyelése
Fürt állapota
Az Azure Portalon felsorolt fürtállapot segíthet az automatikus skálázási tevékenységek figyelésében.
Az összes látható fürtállapot-üzenet az alábbi listában található.
| Fürt állapota | Leírás |
|---|---|
| Futó | A fürt normálisan működik. Az összes korábbi automatikus skálázási tevékenység sikeresen befejeződött. |
| Frissítés | A fürt automatikus skálázási konfigurációja frissül. |
| HDInsight-konfiguráció | A fürt vertikális felskálázása vagy leskálázása folyamatban van. |
| Frissítési hiba | A HDInsight problémákat találkozott az automatikus skálázási konfiguráció frissítése során. Az ügyfelek dönthetnek úgy, hogy újra megkísérlik a frissítést, vagy letiltják az automatikus skálázást. |
| Hiba | Hiba történt a fürttel, és nem használható. Törölje ezt a fürtöt, és hozzon létre egy újat. |
A fürtben lévő csomópontok aktuális számának megtekintéséhez nyissa meg a fürt Áttekintés lapján található Fürtméret diagramot. Vagy válassza a fürtméretet a Gépház alatt.
Műveletelőzmények
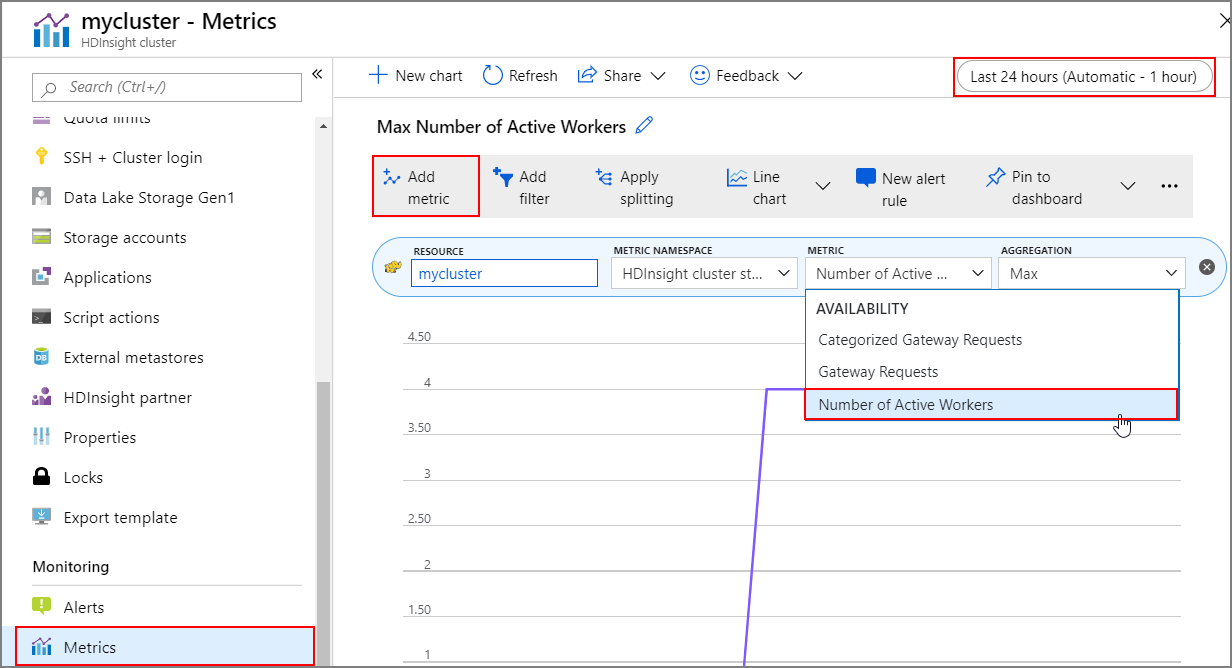
A fürt vertikális fel- és leskálázási előzményeit a fürtmetrikák részeként tekintheti meg. Az elmúlt nap, hét vagy egyéb időszak összes skálázási műveletét is listázhatja.
Válassza a Metrikák lehetőséget a Figyelés csoportban. Ezután válassza a Metrikák és aktív feldolgozók számának hozzáadása lehetőséget a Metrika legördülő listából. Az időtartomány módosításához kattintson a jobb felső sarokban található gombra.
Ajánlott eljárások
Vegye figyelembe a vertikális fel- és leskálázási műveletek késését
Az általános skálázási művelet végrehajtása 10–20 percet is igénybe vehet. Ha testre szabott ütemezést állít be, tervezze meg ezt a késést. Ha például azt szeretné, hogy a fürt mérete 20 legyen 9:00-kor, állítsa az ütemezési eseményindítót egy korábbi időpontra, például 8:30-ra vagy korábbira, hogy a méretezési művelet 9:00-ig befejeződjön.
Felkészülés a leskálázásra
A fürt skálázásának leskálázása során az automatikus skálázás a csomópontokat a célméretnek megfelelően leszereli. Terhelésalapú automatikus skálázás esetén, ha a tevékenységek ezeken a csomópontokon futnak, az automatikus skálázás megvárja, amíg a tevékenységek befejeződnek a Spark- és Hadoop-fürtök esetében. Mivel az egyes feldolgozó csomópontok a HDFS-ben is szolgálnak szerepkört, az ideiglenes adatok a fennmaradó feldolgozó csomópontokra kerülnek át. Győződjön meg arról, hogy elegendő hely van a fennmaradó csomópontokon az összes ideiglenes adat tárolásához.
Feljegyzés
Ütemezésalapú automatikus skálázási leskálázás esetén a kecses leszerelés nem támogatott. Ez feladathibákat okozhat a vertikális leskálázási művelet során, és ajánlott a tervezett feladatütemezési minták alapján megtervezni az ütemezéseket, hogy elegendő időt foglaljanak magukban a folyamatban lévő feladatok befejezéséhez. A feladathibák elkerülése érdekében beállíthatja az ütemezéseket a befejezési idők korábbi terjedelmét tekintve.
Ütemezésalapú automatikus skálázás konfigurálása használati minta alapján
Az ütemezésalapú automatikus skálázás konfigurálásakor ismernie kell a fürt használati mintáját. A Grafana irányítópultja segít megérteni a lekérdezések betöltési és végrehajtási pontjait. Az irányítópultról lekérheti az elérhető végrehajtói pontokat és a teljes végrehajtói pontokat.
Az alábbiakban megadhatja, hogy hány munkavégző csomópontra van szükség. Javasoljuk, hogy adjon további 10%-os puffert a számítási feladat variációjának kezeléséhez.
Használt végrehajtói pontok száma = Összes végrehajtói tárolóhely – Összes rendelkezésre álló végrehajtói tárolóhely.
Szükséges feldolgozó csomópontok száma = Ténylegesen használt végrehajtóhelyek száma / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)
*hive.llap.daemon.num.executors konfigurálható, alapértelmezett értéke 4
*hive.llap.daemon.task.scheduler.wait.queue.size konfigurálható, alapértelmezett értéke 10
Egyéni szkriptműveletek
Az egyéni szkriptműveleteket többnyire a csomópontok (pl. HeadNode/WorkerNodes) testreszabására használják, amelyek lehetővé teszik ügyfeleink számára bizonyos, általuk használt kódtárak és eszközök konfigurálását. Az egyik gyakori használati eset a fürtön futó feladat(ok) bizonyos függőségei lehetnek az ügyfél tulajdonában lévő harmadik féltől származó kódtártól, és a feladat sikeres végrehajtásához elérhetőnek kell lennie a csomópontokon. Az automatikus skálázás esetében jelenleg támogatjuk az egyéni szkriptműveleteket, amelyek megmaradnak, ezért minden alkalommal, amikor az új csomópontokat a vertikális felskálázási művelet részeként hozzáadják a fürthöz, a rendszer végrehajtja ezeket a megmaradó szkriptműveleteket, és közzéteheti, hogy a tárolók vagy feladatok ki lesznek foglalva rajtuk. Bár az egyéni szkriptműveletek segítenek az új csomópontok elindításában, célszerű minimális szinten tartani, mivel az növeli a teljes vertikális felskálázási késést, és hatással lehet az ütemezett feladatokra.
Vegye figyelembe a fürt minimális méretét
Ne skálázza le a fürtöt három csomópontnál kevesebbre. Ha a fürt három csomópontnál kevesebbre van skálázva, az a nem megfelelő fájlreplikálás miatt csökkentett módban elakadhat. További információ: elakadás csökkentett módban.
Microsoft Entra Domain Services & skálázási műveletek
Ha olyan HDInsight-fürtöt használ nagyvállalati biztonsági csomaggal (ESP), amely egy Microsoft Entra Domain Services által felügyelt tartományhoz csatlakozik, javasoljuk, hogy szabályozza a Terhelés szabályozását a Microsoft Entra Domain Servicesen. Összetett címtárstruktúrák hatókörön belüli szinkronizálása esetén javasoljuk, hogy kerülje a skálázási műveletekre gyakorolt hatást.
A Hive-konfiguráció maximális egyidejű lekérdezéseinek beállítása a csúcshasználati forgatókönyvhöz
Az automatikus skálázási események nem módosítják a Hive-konfiguráció maximális egyidejű lekérdezéseinek maximális összegét az Ambariban. Ez azt jelenti, hogy a Hive Server 2 interaktív szolgáltatás bármikor csak a megadott számú egyidejű lekérdezést tudja kezelni, még akkor is, ha az interaktív lekérdezés démonjainak száma a terhelés és az ütemezés alapján fel- és leskálázva van. Az általános javaslat az, hogy a manuális beavatkozás elkerülése érdekében állítsa be ezt a konfigurációt a csúcshasználati forgatókönyvhöz.
Előfordulhat azonban, hogy a Hive Server 2 újraindítási hibája akkor jelentkezik, ha csak néhány feldolgozó csomópont van, és a maximális egyidejű lekérdezések értéke túl magas. Legalább azoknak a feldolgozó csomópontoknak a minimális számára van szüksége, amelyek képesek befogadni a Tez Ams megadott számát (egyenlő a Maximális egyidejű lekérdezések maximális konfigurációval).
Korlátozások
Interaktív lekérdezési démonok száma
Ha automatikusan skálázható interaktív lekérdezési fürtök, az automatikus skálázási fel/le esemény az interaktív lekérdezés démonjainak számát is felfelé/lefelé skálázza az aktív feldolgozó csomópontok számára. A démonok számának változása nem marad meg az num_llap_nodes Ambari konfigurációjában. Ha a Hive-szolgáltatásokat manuálisan újraindítják, az Interaktív lekérdezés démonok száma alaphelyzetbe áll az Ambari konfigurációjának megfelelően.
Ha az Interaktív lekérdezés szolgáltatást manuálisan újraindítják, manuálisan kell módosítania a num_llap_node konfigurációt (a Hive Interaktív lekérdezés démon futtatásához szükséges csomópontok számát) az Advanced hive-interactive-env területen, hogy megfeleljen az aktuális aktív feldolgozó csomópontok számának. Az interaktív lekérdezésfürt csak ütemezésalapú automatikus skálázást támogat
Következő lépések
A fürtök manuális méretezésével kapcsolatos irányelvek a méretezési irányelvekben