A Spark > Hive Tools for Visual Studio Code használata
Megtudhatja, hogyan használhatja az Apache Spark & Hive Tools for Visual Studio Code-ot. Az eszközökkel Apache Hive batch-feladatokat, interaktív Hive-lekérdezéseket és PySpark-szkripteket hozhat létre és küldhet el az Apache Sparkhoz. Először bemutatjuk, hogyan telepítheti a Spark > Hive Toolst a Visual Studio Code-ban. Ezután bemutatjuk, hogyan küldhet be feladatokat a Spark > Hive Toolsnak.
A Spark > Hive Tools telepíthető a Visual Studio Code által támogatott platformokra. Vegye figyelembe a különböző platformok következő előfeltételeit.
Előfeltételek
A cikk lépéseinek elvégzéséhez a következő elemek szükségesek:
- Egy Azure-beli HDInsight-fürt. Fürt létrehozásához tekintse meg a HDInsight használatának első lépéseit. Vagy használjon Egy Apache Livy-végpontot támogató Spark- és Hive-fürtöt.
- Visual Studio Code.
- Mono. A Mono csak Linuxhoz és macOS-hez szükséges.
- PySpark interaktív környezet a Visual Studio Code-hoz.
- Egy helyi könyvtár. Ez a cikk a C:\HD\HDexample parancsot használja.
Spark > Hive-eszközök telepítése
Az előfeltételek teljesítése után az alábbi lépések végrehajtásával telepítheti a Spark > Hive Tools for Visual Studio Code-ot:
Nyissa meg a Visual Studio Code-ot.
A menüsávon navigáljon a Bővítmények megtekintése elemre>.
A keresőmezőbe írja be a Spark &Hive nevet.
Válassza a Spark > Hive Tools lehetőséget a keresési eredmények közül, majd válassza a Telepítés lehetőséget:
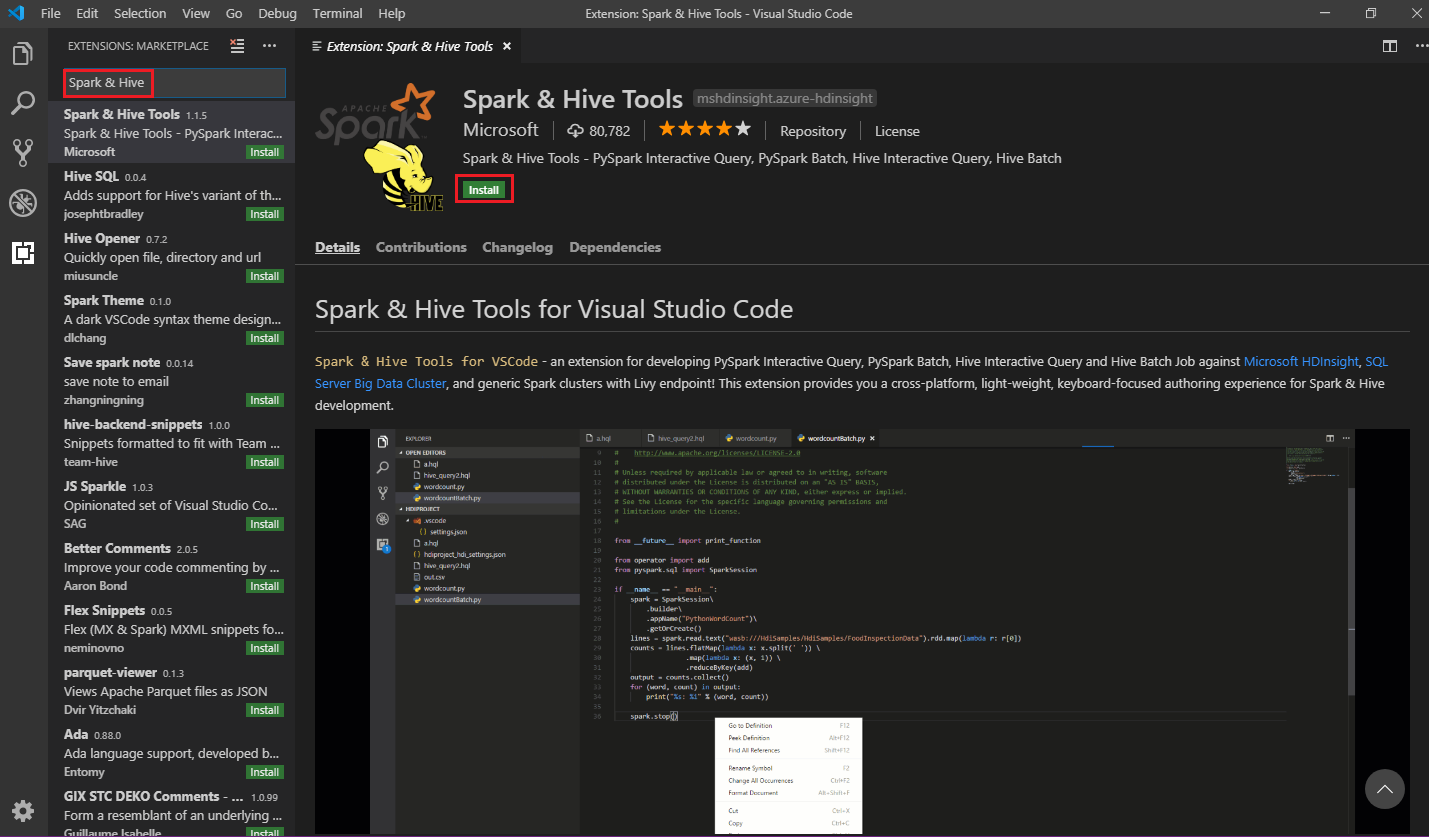
Szükség esetén válassza az Újratöltés lehetőséget.
Munkahelyi mappa megnyitása
Ha meg szeretne nyitni egy munkahelyi mappát, és létre szeretne hozni egy fájlt a Visual Studio Code-ban, kövesse az alábbi lépéseket:
A menüsávon navigáljon a Fájl>megnyitása mappához...>C:\HD\HDexample, majd válassza a Mappa kiválasztása gombot. A mappa a bal oldali Explorer nézetben jelenik meg.
Explorer nézetben válassza a HDexample mappát, majd válassza az Új fájl ikont a munkahelyi mappa mellett:
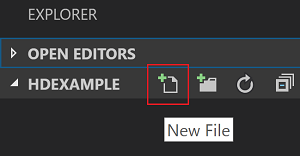
Nevezze el az új fájlt a
.hql(Hive-lekérdezések) vagy a.py(Spark-szkript) fájlkiterjesztés használatával. Ez a példa a HelloWorld.hql-t használja.
Az Azure-környezet beállítása
A nemzeti felhőfelhasználók esetében kövesse az alábbi lépéseket az Azure-környezet beállításához, majd az Azure: Bejelentkezés paranccsal jelentkezzen be az Azure-ba:
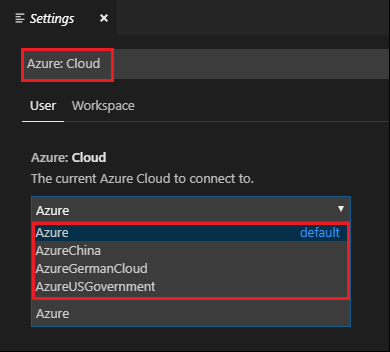
Lépjen a Fájlbeállítások>> Gépház elemre.
Keressen a következő sztringre: Azure: Cloud.
Válassza ki az országos felhőt a listából:
Kapcsolódás Azure-fiókhoz
Mielőtt szkripteket küldhet a fürtökre a Visual Studio Code-ból, a felhasználó bejelentkezhet az Azure-előfizetésbe, vagy összekapcsolhat egy HDInsight-fürtöt. A HDInsight-fürthöz való csatlakozáshoz használja az ESP-fürt Ambari-felhasználónevét/jelszavát vagy tartományhoz csatlakoztatott hitelesítő adatait. Az Azure-hoz való csatlakozáshoz kövesse az alábbi lépéseket:
A menüsávon navigáljon a Parancskatalógus megtekintése>..., majd írja be az Azure-t: Bejelentkezés:

Az Azure-ba való bejelentkezéshez kövesse a bejelentkezési utasításokat. A csatlakozás után az Azure-fiók neve megjelenik a Visual Studio Code ablakának alján található állapotsoron.
Fürt csatolása
Hivatkozás: Azure HDInsight
Egy normál fürtöt Apache Ambari által felügyelt felhasználónévvel kapcsolhat össze, vagy csatolhat egy Enterprise Security Pack biztonságos Hadoop-fürtöt egy tartománynévvel (például: user1@contoso.com).
A menüsávon navigáljon a Parancskatalógus megtekintése>... elemre, és írja be a Spark/Hive: Fürt csatolása parancsot.

Válassza ki az Azure HDInsight társított fürttípust.
Adja meg a HDInsight-fürt URL-címét.
Adja meg Ambari-felhasználónevét; az alapértelmezett beállítás a rendszergazda.
Adja meg az Ambari-jelszót.
Válassza ki a fürt típusát.
Állítsa be a fürt megjelenítendő nevét (nem kötelező).
Tekintse át a KIMENETI nézetet ellenőrzés céljából.
Feljegyzés
A csatolt felhasználónevet és jelszót akkor használja a rendszer, ha a fürt bejelentkezett az Azure-előfizetésbe, és csatolt egy fürtöt.
Hivatkozás: Általános Livy-végpont
A menüsávon navigáljon a Parancskatalógus megtekintése>... elemre, és írja be a Spark/Hive: Fürt csatolása parancsot.
Válassza ki a csatolt fürttípust általános Livy-végpontként.
Adja meg az általános Livy-végpontot. Például: http://10.172.41.42:18080.
Válassza az Egyszerű vagy a Nincs engedélyezési típust. Ha az Alapszintű lehetőséget választja:
Adja meg Ambari-felhasználónevét; az alapértelmezett beállítás a rendszergazda.
Adja meg az Ambari-jelszót.
Tekintse át a KIMENETI nézetet ellenőrzés céljából.
Fürtök listázása
A menüsávon navigáljon a Parancskatalógus megtekintése>..., majd írja be a Spark/Hive: Listafürt parancsot.
Válassza ki a kívánt előfizetést.
Tekintse át a KIMENETI nézetet. Ez a nézet a csatolt fürtöket (vagy fürtöket) és az Azure-előfizetéshez tartozó összes fürtöt jeleníti meg:

Az alapértelmezett fürt beállítása
Ha bezárja, nyissa meg újra a korábban tárgyalt HDexample mappát.
Válassza ki a korábban létrehozott HelloWorld.hql fájlt. Megnyílik a szkriptszerkesztőben.
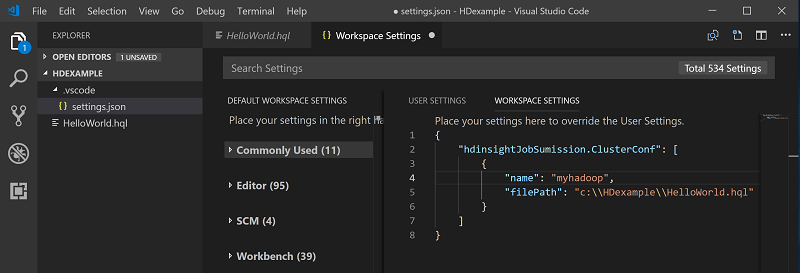
Kattintson a jobb gombbal a szkriptszerkesztőre, majd válassza a Spark/Hive: Alapértelmezett fürt beállítása lehetőséget.
Csatlakozás az Azure-fiókjához, vagy csatoljon egy fürtöt, ha még nem tette meg.
Jelöljön ki egy fürtöt az aktuális szkriptfájl alapértelmezett fürtjeként. Az eszközök automatikusan frissítik a . VSCode\settings.json konfigurációs fájl:
Interaktív Hive-lekérdezések és Hive-kötegszkriptek küldése
A Spark > Hive Tools for Visual Studio Code használatával interaktív Hive-lekérdezéseket és Hive-kötegszkripteket küldhet a fürtökre.
Ha bezárja, nyissa meg újra a korábban tárgyalt HDexample mappát.
Válassza ki a korábban létrehozott HelloWorld.hql fájlt. Megnyílik a szkriptszerkesztőben.
Másolja és illessze be a következő kódot a Hive-fájlba, majd mentse:
SELECT * FROM hivesampletable;Csatlakozás az Azure-fiókjához, vagy csatoljon egy fürtöt, ha még nem tette meg.
Kattintson a jobb gombbal a szkriptszerkesztőre, és válassza a Hive: Interaktív parancsot a lekérdezés elküldéséhez, vagy használja a Ctrl+Alt+I billentyűparancsot. Válassza a Hive: Batch lehetőséget a szkript elküldéséhez, vagy használja a Ctrl+Alt+H billentyűparancsot.
Ha még nem adott meg alapértelmezett fürtöt, válasszon ki egy fürtöt. Az eszközök segítségével a helyi menü használatával a teljes szkriptfájl helyett kódblokkot is elküldhet. Néhány pillanat múlva a lekérdezés eredményei egy új lapon jelennek meg:
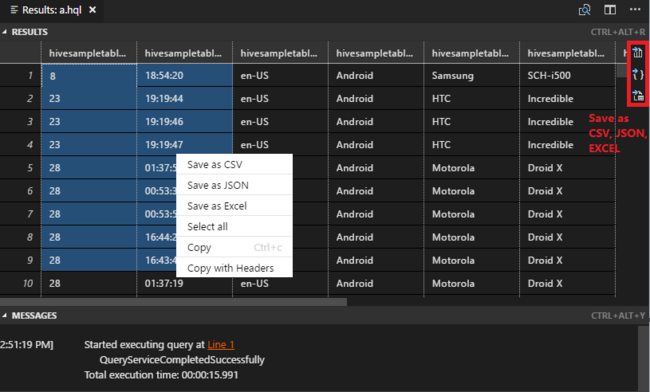
EREDMÉNYEK panel: A teljes eredményt mentheti CSV-, JSON- vagy Excel-fájlként egy helyi elérési útra, vagy egyszerűen kijelölhet több sort.
ÜZENETEK panel: Amikor kiválaszt egy sorszámot , az a futó szkript első sorára ugrik.
Interaktív PySpark-lekérdezések küldése
A Pyspark interaktív használatának előfeltétele
Vegye figyelembe, hogy a Jupyter Extension (ms-jupyter): v2022.1.1001614873 és Python Extension version (ms-python): v2021.12.1559732655, Python 3.6.x és 3.7.x szükséges a HDInsight interaktív PySpark-lekérdezésekhez.
A felhasználók az alábbi módokon végezhetik el a PySpark interaktív végrehajtását.
A PySpark interaktív parancs használata PY-fájlban
A PySpark interaktív parancsával küldje el a lekérdezéseket, kövesse az alábbi lépéseket:
Ha bezárja, nyissa meg újra a korábban tárgyalt HDexample mappát.
Hozzon létre egy új HelloWorld.py fájlt a korábbi lépések végrehajtásával.
Másolja és illessze be a következő kódot a szkriptfájlba:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])A PySpark/Synapse Pyspark kernel telepítésére vonatkozó kérés az ablak jobb alsó sarkában jelenik meg. A Telepítés gombra kattintva továbbléphet a PySpark/Synapse Pyspark telepítéseihez, vagy a Kihagyás gombra kattintva kihagyhatja ezt a lépést.
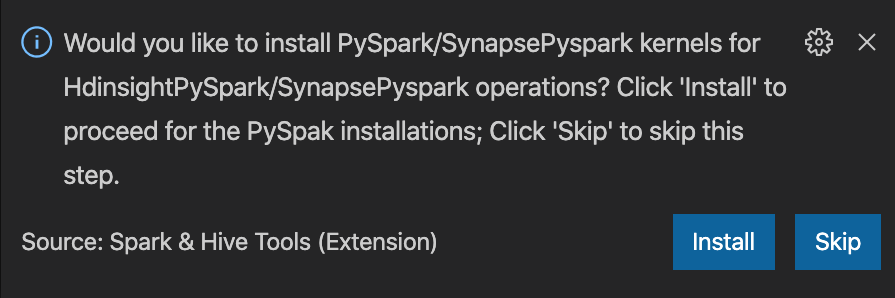
Ha később telepítenie kell, lépjen a Fájlbeállítások>> elemre Gépház majd törölje a HDInsight jelölését: Engedélyezze a Pyspark telepítésének kihagyását a beállítások között.
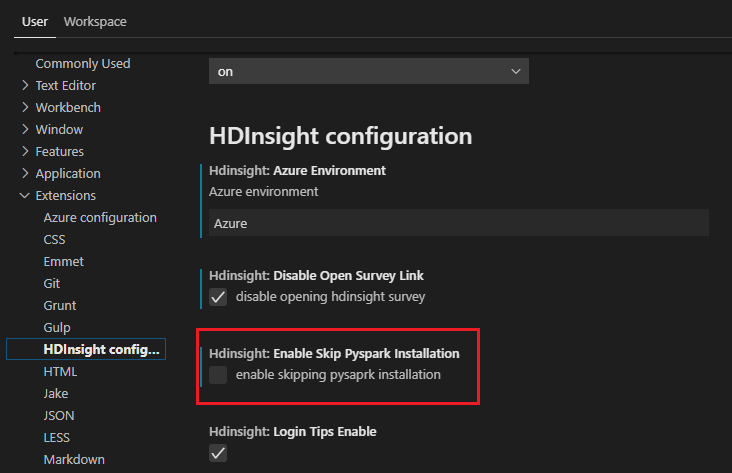
Ha a telepítés sikeres a 4. lépésben, az ablak jobb alsó sarkában megjelenik a "PySpark telepítése sikeresen" üzenetmező. Kattintson az Újratöltés gombra az ablak újbóli betöltéséhez.
A menüsávon navigáljon a Parancskatalógus megtekintése>elemre... vagy használja a Shift + Ctrl + P billentyűparancsot, és írja be a Python: Értelmező kiválasztása parancsot a Jupyter Server elindításához.

Válassza az alábbi Python lehetőséget.

A menüsávon navigáljon a Parancskatalógus megtekintése>elemre... vagy használja a Shift + Ctrl + P billentyűparancsot, és írja be a Developer: Reload Window parancsot.

Csatlakozás az Azure-fiókjához, vagy csatoljon egy fürtöt, ha még nem tette meg.
Válassza ki az összes kódot, kattintson a jobb gombbal a szkriptszerkesztőre, és válassza a Spark: PySpark Interactive / Synapse: Pyspark Interactive lehetőséget a lekérdezés elküldéséhez.
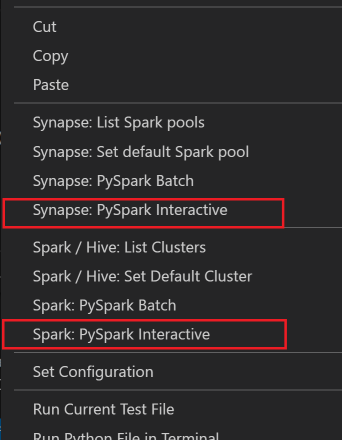
Jelölje ki a fürtöt, ha nem adott meg alapértelmezett fürtöt. Néhány pillanat múlva a Python Interaktív eredmények egy új lapon jelennek meg. Kattintson a PySparkra a kernel PySpark/Synapse Pysparkra való átváltásához, és a kód sikeresen lefut. Ha Synapse Pyspark kernelre szeretne váltani, javasoljuk, hogy tiltsa le az automatikus beállításokat az Azure Portalon. Ellenkező esetben a fürt felébresztése és a synapse kernel első alkalommal történő beállítása hosszabb időt vehet igénybe. Ha az eszközök lehetővé teszik, hogy a helyi menü használatával a teljes szkriptfájl helyett kódblokkot küldjön be:
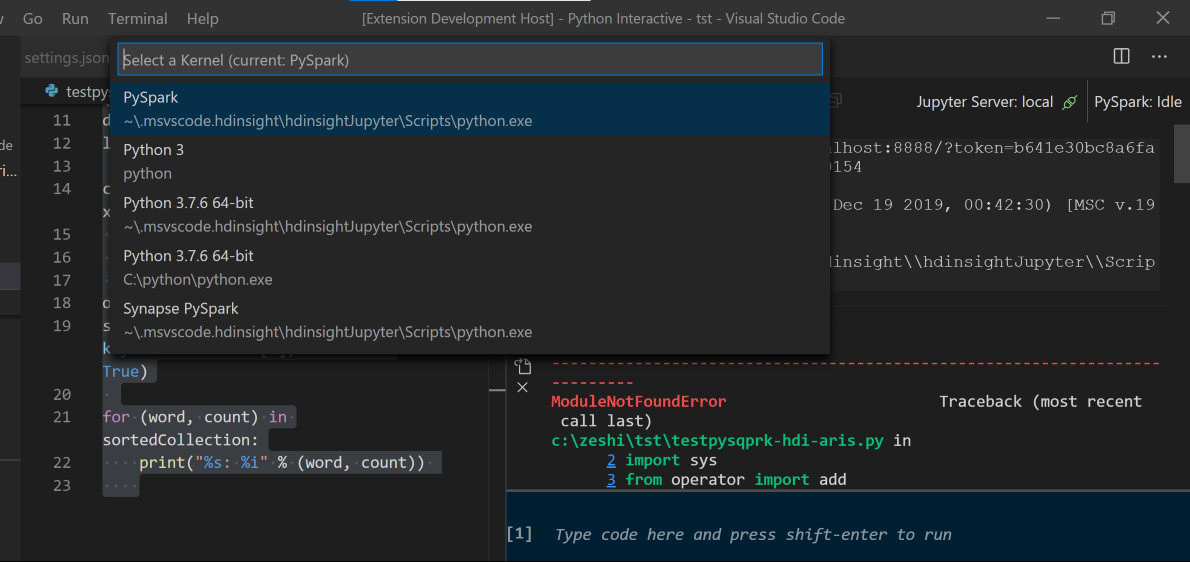
Írja be a %%-adatokat, majd nyomja le a Shift+Enter billentyűkombinációt a feladatadatok megtekintéséhez (nem kötelező):

Az eszköz a Spark SQL-lekérdezést is támogatja:
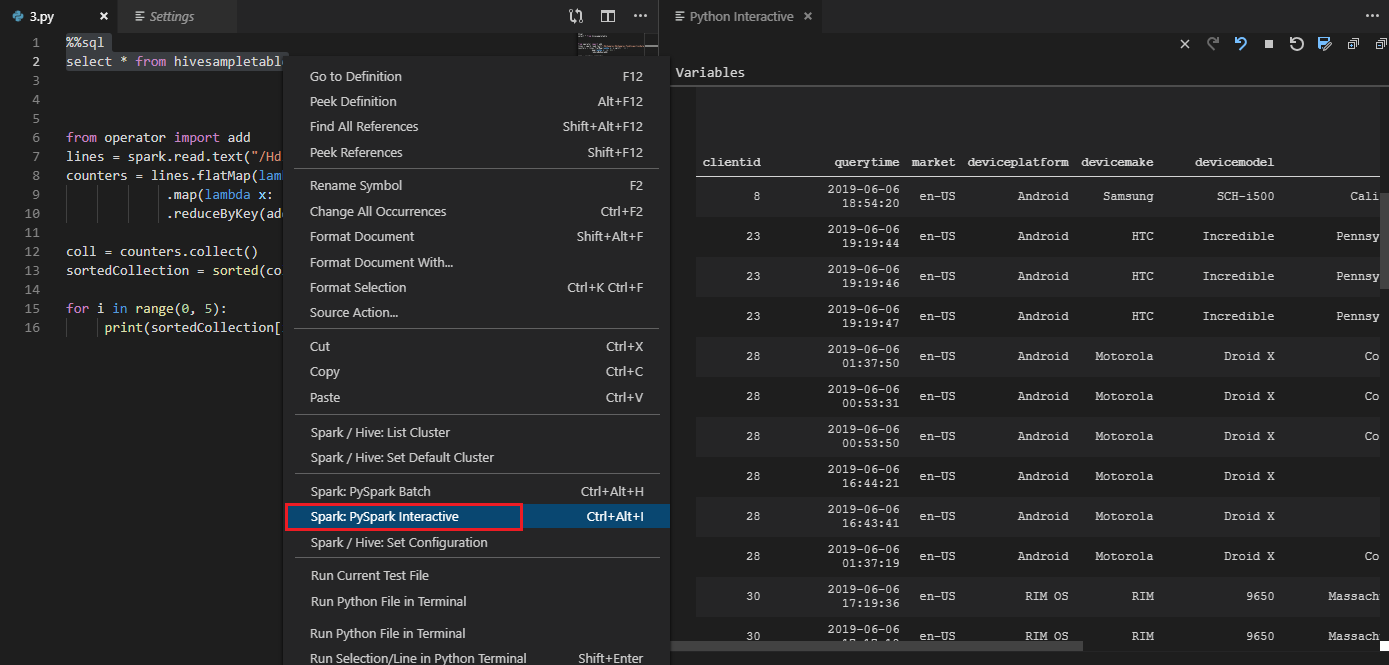
Interaktív lekérdezés végrehajtása PY-fájlban #%% megjegyzés használatával
Adja hozzá #%% a Py-kód előtt a jegyzetfüzet élményének lekéréséhez.
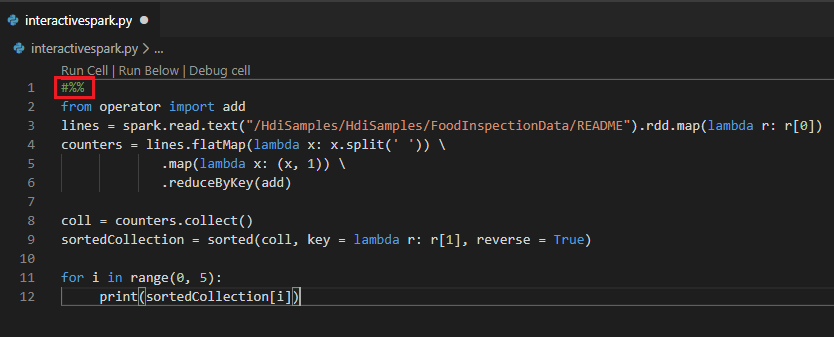
Kattintson a Cella futtatása elemre. Néhány pillanat múlva a Python Interaktív eredmények egy új lapon jelennek meg. Kattintson a PySparkra a kernel PySpark/Synapse PySparkra való váltásához, majd kattintson ismét a Cella futtatása elemre, és a kód sikeresen lefut.
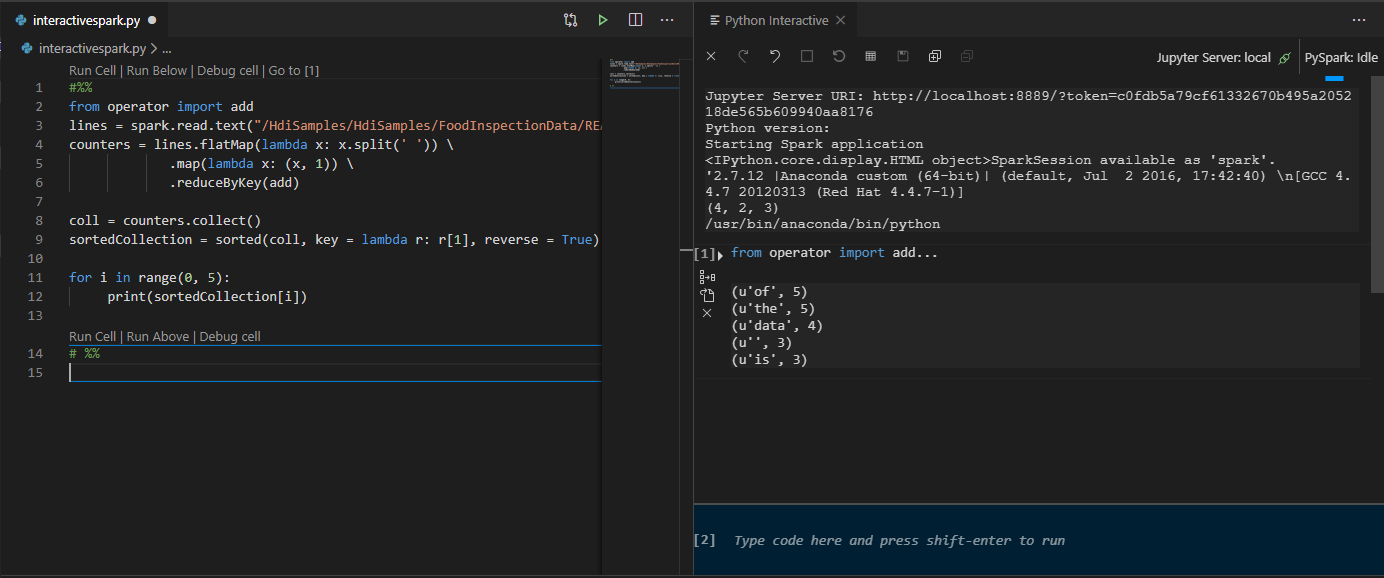
IPYNB-támogatás használata Python-bővítményből
Jupyter-jegyzetfüzetet a parancskatalógusból vagy egy új .ipynb-fájl létrehozásával hozhat létre a munkaterületen. További információ: Jupyter-jegyzetfüzetek használata a Visual Studio Code-ban
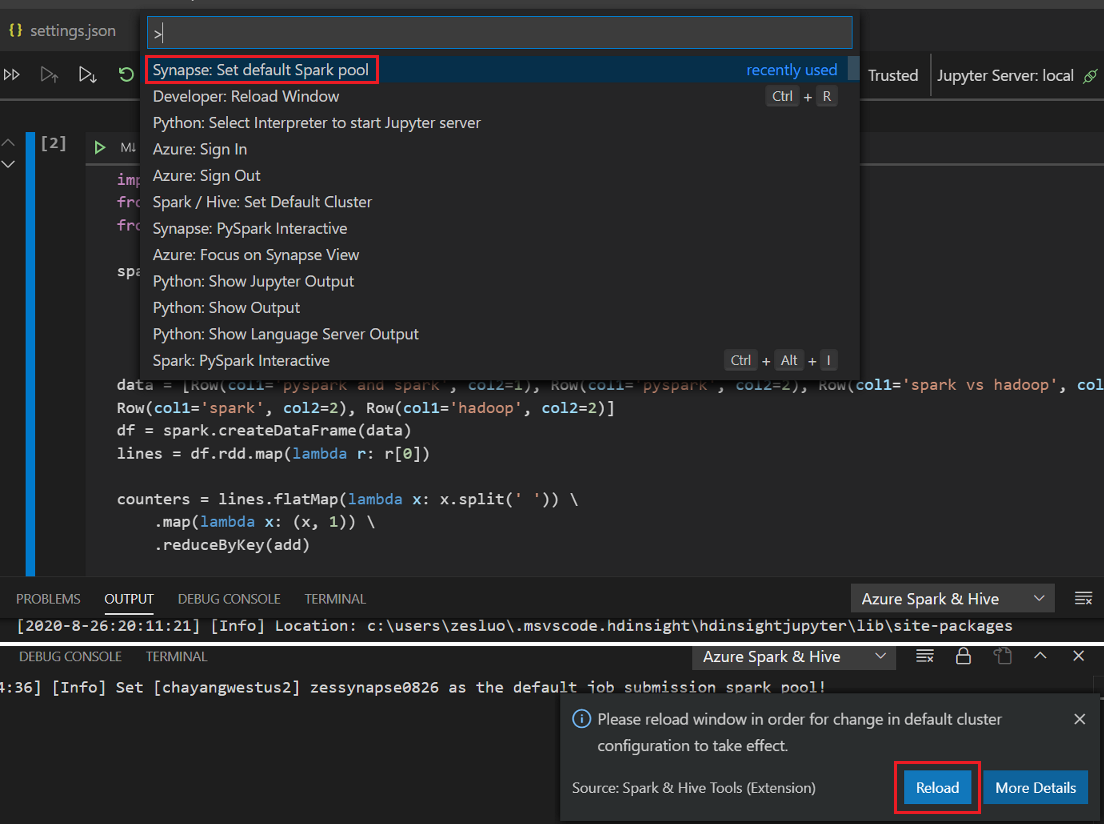
Kattintson a Cella futtatása gombra, kövesse az utasításokat az alapértelmezett spark-készlet beállításához (erősen javasoljuk, hogy a jegyzetfüzet megnyitása előtt minden alkalommal állítsa be az alapértelmezett fürtöt/készletet), majd töltse be újra az ablakot.
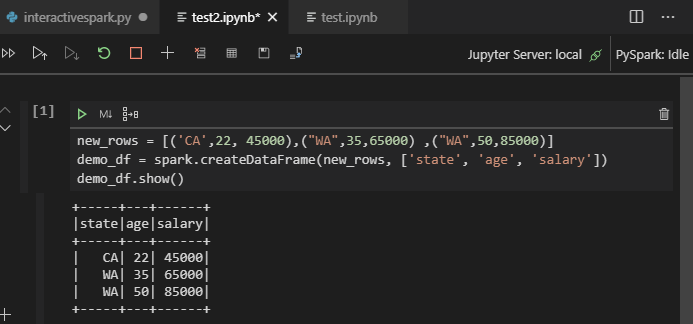
Kattintson a PySparkra a kernel PySpark/Synapse Pysparkra való váltásához, majd kattintson a Futtató cellára, egy idő után megjelenik az eredmény.
Feljegyzés
A Synapse PySpark telepítési hibája esetén, mivel a függőségét a többi csapat már nem fogja fenntartani, ezt már nem tartjuk fenn. Ha interaktívan szeretné használni a Synapse Pysparkot, váltson inkább az Azure Synapse Analytics használatára. És ez hosszú távú változás.
PySpark-kötegelt feladat elküldése
Ha bezárja, nyissa meg újra a korábban tárgyalt HDexample mappát.
Hozzon létre egy új BatchFile.py fájlt a korábbi lépések végrehajtásával.
Másolja és illessze be a következő kódot a szkriptfájlba:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Csatlakozás az Azure-fiókjához, vagy csatoljon egy fürtöt, ha még nem tette meg.
Kattintson a jobb gombbal a szkriptszerkesztőre, majd válassza a Spark: PySpark Batch vagy a Synapse: PySpark Batch* lehetőséget.
Válasszon ki egy fürtöt/spark-készletet a PySpark-feladat elküldéséhez a következő címre:
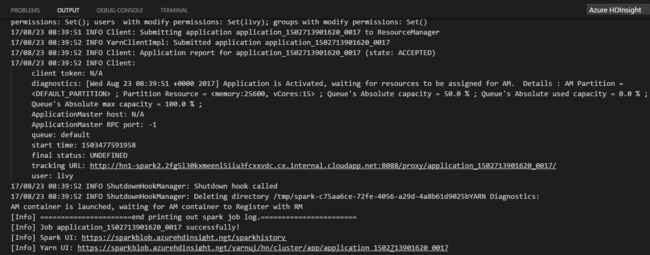
A Python-feladat elküldése után a beküldési naplók megjelennek a Visual Studio Code OUTPUT ablakában. Megjelenik a Spark felhasználói felület URL-címe és a Yarn felhasználói felületének URL-címe is. Ha egy Apache Spark-készletbe küldi el a kötegelt feladatot, megjelenik a Spark-előzmények felhasználói felületének URL-címe és a Spark-feladatalkalmazás felhasználói felületének URL-címe is. A feladat állapotának nyomon követéséhez megnyithatja az URL-címet egy webböngészőben.
Integrálás a HDInsight Identity Brokerrel (HIB)
Csatlakozás a HDInsight ESP-fürthöz az ID Broker (HIB) használatával
A normál lépéseket követve bejelentkezhet az Azure-előfizetésbe a HDInsight ESP-fürthöz való csatlakozáshoz az ID Broker (HIB) használatával. A bejelentkezés után megjelenik a fürtlista az Azure Explorerben. További útmutatásért tekintse meg a HDInsight-fürtre vonatkozó Csatlakozás.
Hive/PySpark-feladat futtatása HDInsight ESP-fürtön id Brokerrel (HIB)
Hive-feladat futtatásához kövesse a normál lépéseket a feladat HDInsight ESP-fürtbe való elküldéséhez az ID Broker (HIB) használatával. További útmutatásért tekintse meg az interaktív Hive-lekérdezések és a Hive-kötegszkriptek beküldését.
Interaktív PySpark-feladat futtatásához kövesse a normál lépéseket a feladat HDInsight ESP-fürtbe való elküldéséhez az ID Broker (HIB) használatával. Tekintse meg az interaktív PySpark-lekérdezések beküldését.
PySpark-kötegelt feladat futtatásához kövesse a normál lépéseket a feladat HDInsight ESP-fürtbe való elküldéséhez az ID Broker (HIB) használatával. További útmutatásért tekintse meg a PySpark-kötegelt feladat elküldését.
Apache Livy-konfiguráció
Az Apache Livy-konfiguráció támogatott. Konfigurálhatja a . VSCode\settings.json fájl a munkaterület mappájában. A Livy-konfiguráció jelenleg csak a Python-szkripteket támogatja. További információ: Livy README.
1. módszer
- A menüsávon lépjen a Fájlbeállítások>> Gépház elemre.
- A Keresési beállítások mezőbe írja be a HDInsight-feladatbeküldést: Livy Conf.
- Válassza a Szerkesztés lehetőséget a settings.json a megfelelő keresési eredményhez.
2. módszer
Küldjön be egy fájlt, és figyelje meg, hogy a .vscode mappa automatikusan bekerül a munkahelyi mappába. A Livy-konfiguráció a .vscode\settings.json lehetőséget választva jelenik meg.
A projekt beállításai:

Feljegyzés
A driverMemory és a executorMemory beállításoknál adja meg az értéket és az egységet. Például: 1g vagy 1024m.
Támogatott Livy-konfigurációk:
POST /batches
Kérelem törzse
név leírás típus fájl A végrehajtandó alkalmazást tartalmazó fájl Elérési út (kötelező) proxyUser A feladat futtatásakor megszemélyesítendő felhasználó Sztring Osztálynév Java-alkalmazás/Spark főosztály Sztring args Az alkalmazás parancssori argumentumai Sztringek listája Tégelyek Az ebben a munkamenetben használandó jarok Sztringek listája pyFiles A munkamenetben használandó Python-fájlok Sztringek listája fájlok Az ebben a munkamenetben használandó fájlok Sztringek listája driverMemory Az illesztőprogram-folyamathoz használandó memória mennyisége Sztring driverCores Az illesztőprogram-folyamathoz használandó magok száma Int executorMemory A végrehajtói folyamatonként használandó memória mennyisége Sztring executorCores Az egyes végrehajtókhoz használandó magok száma Int numExecutors A munkamenethez elindítandó végrehajtók száma Int Archívum Az ebben a munkamenetben használandó archívumok Sztringek listája feldolgozási sor Annak a YARN-üzenetsornak a neve, amelybe elküldendő Sztring név A munkamenet neve Sztring Conf Spark-konfiguráció tulajdonságai A key=val térképe Válasz törzs A létrehozott Batch-objektum.
név leírás típus ID (Azonosító) Munkamenet-azonosító Int appId A munkamenet alkalmazásazonosítója Sztring appInfo Részletes alkalmazásadatok A key=val térképe napló Naplósorok Sztringek listája állapot Batch-állapot Sztring Feljegyzés
A hozzárendelt Livy-konfiguráció megjelenik a kimeneti panelen a szkript elküldésekor.
Integrálás az Azure HDInsighttal az Explorerből
A Hive Table előnézetét közvetlenül az Azure HDInsight Explorer használatával tekintheti meg a fürtökben:
Válassza ki az Azure ikont a bal szélső oszlopból.
A bal oldali panelen bontsa ki az AZURE: HDINSIGHT elemet. Az elérhető előfizetések és fürtök listája megjelenik.
Bontsa ki a fürtöt a Hive metaadat-adatbázis és a táblaséma megtekintéséhez.
Kattintson a jobb gombbal a Hive táblára. Például: hivesampletable. Válassza a Előnézet elemet.
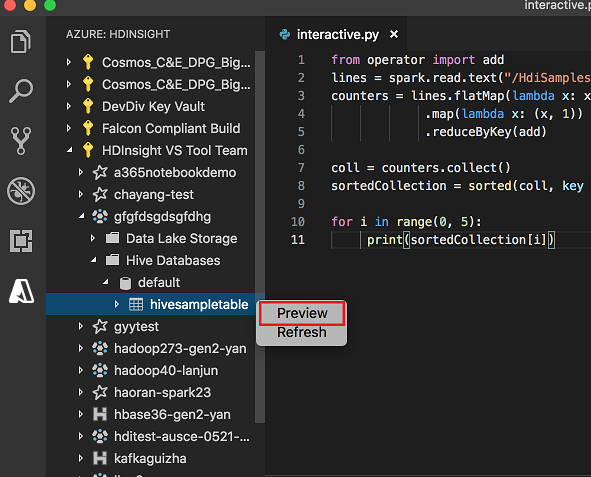
Megnyílik az Előnézeti eredmények ablak:
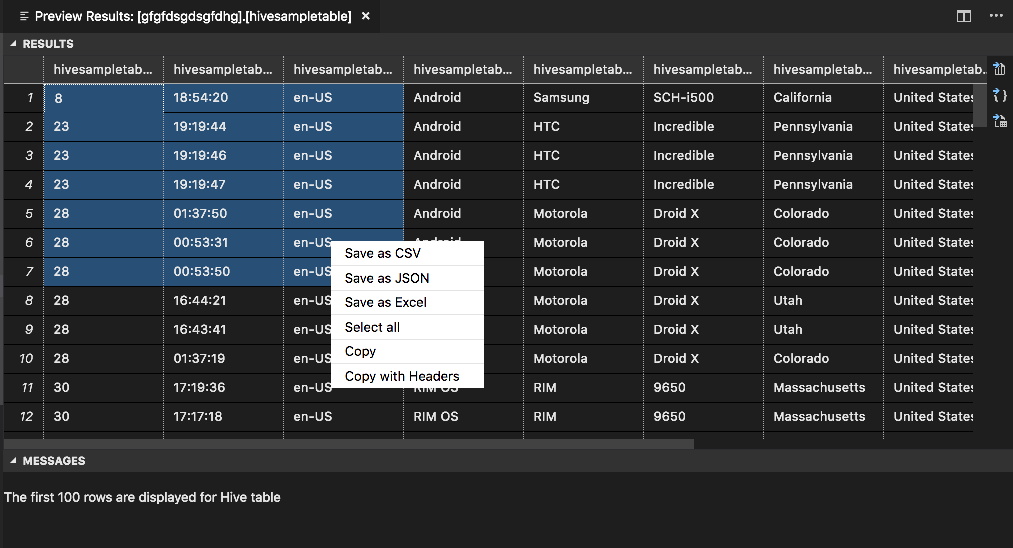
EREDMÉNYEK panel
A teljes eredményt mentheti CSV-, JSON- vagy Excel-fájlként egy helyi elérési útra, vagy egyszerűen kijelölhet több sort.
ÜZENETEK panel
Ha a táblázat sorainak száma meghaladja a 100-t, a következő üzenet jelenik meg: "A Hive-tábla első 100 sora jelenik meg."
Ha a táblázat sorainak száma kisebb vagy egyenlő 100-nál, a következő üzenet jelenik meg: "60 sor jelenik meg a Hive-tábla esetében".
Ha nincs tartalom a táblázatban, a következő üzenet jelenik meg: "
0 rows are displayed for Hive table."Feljegyzés
Linuxon telepítse az xclipet a másolási tábla adatainak engedélyezéséhez.

További funkciók
A Visual Studio Code-hoz készült Spark > Hive a következő funkciókat is támogatja:
IntelliSense automatikus kiegészítés. Kulcsszavakra, metódusokra, változókra és egyéb programozási elemekre vonatkozó javaslatok jelennek meg. A különböző ikonok különböző típusú objektumokat jelölnek:
IntelliSense hibajelölő. A nyelvi szolgáltatás aláhúzza a Hive-szkript szerkesztési hibáit.
Szintaxiskiemelések. A nyelvi szolgáltatás különböző színekkel különbözteti meg a változókat, kulcsszavakat, adattípust, függvényeket és egyéb programozási elemeket:

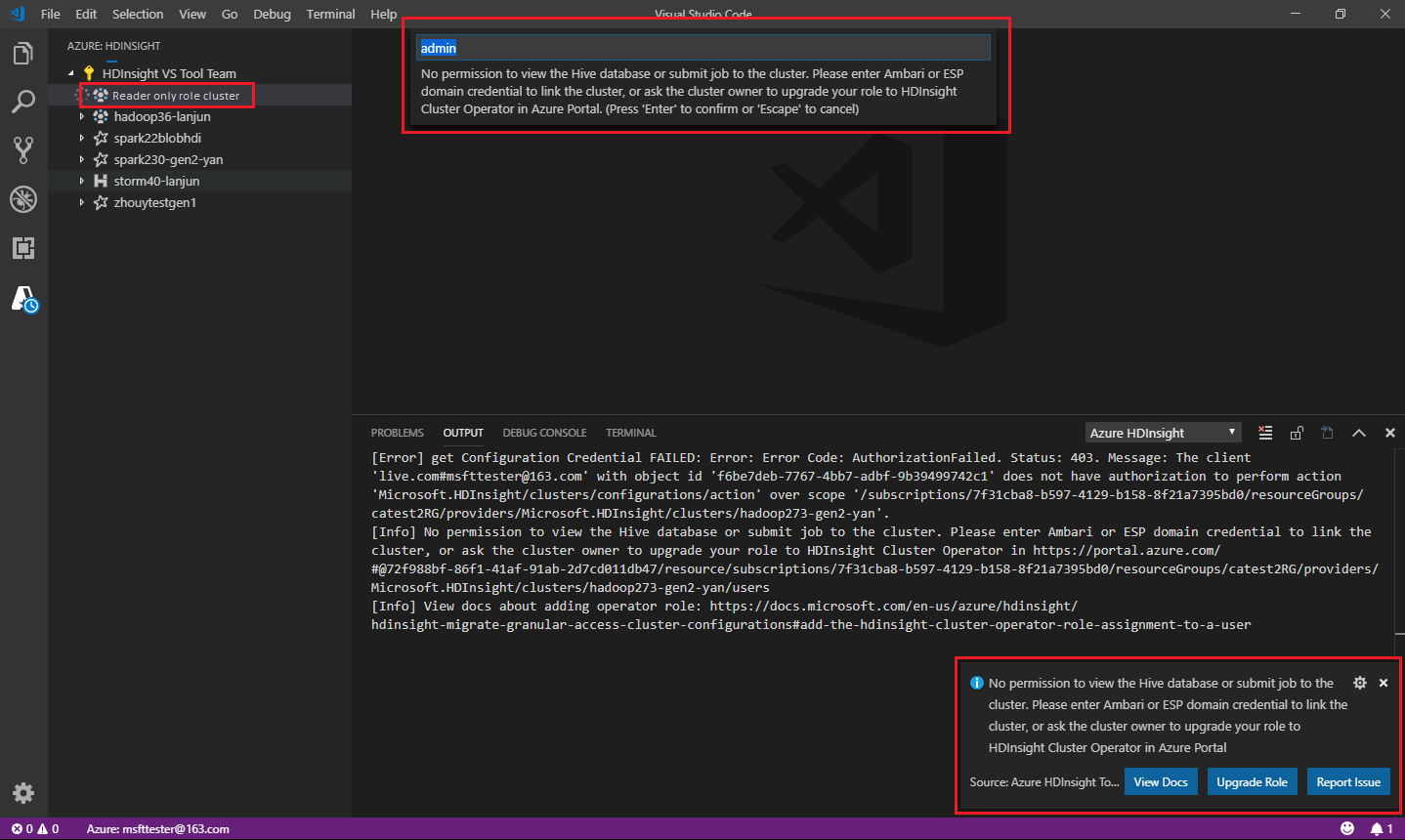
Csak olvasói szerepkör
A fürt csak olvasó szerepkörével rendelkező felhasználók nem küldhetnek feladatokat a HDInsight-fürtnek, és nem tekinthetik meg a Hive-adatbázist. Lépjen kapcsolatba a fürt rendszergazdájával, és frissítse a szerepkört a HDInsight-fürt operátorára az Azure Portalon. Ha rendelkezik érvényes Ambari-hitelesítő adatokkal, az alábbi útmutató segítségével manuálisan csatolhatja a fürtöt.
Tallózás a HDInsight-fürtben
Amikor egy HDInsight-fürt kibontásához az Azure HDInsight Explorert választja, a rendszer arra kéri, hogy kapcsolja össze a fürtöt, ha a fürt csak olvasó szerepkörrel rendelkezik. Az alábbi módszerrel csatolhatja a fürtöt az Ambari hitelesítő adataival.
A feladat elküldése a HDInsight-fürtre
Amikor feladatot küld egy HDInsight-fürtnek, a rendszer arra kéri, hogy kapcsolja össze a fürtöt, ha a fürt csak olvasó szerepkörben van. Az alábbi lépésekkel csatolhatja a fürtöt az Ambari hitelesítő adataival.
Hivatkozás a fürtre
Adjon meg érvényes Ambari-felhasználónevet.
Adjon meg érvényes jelszót.
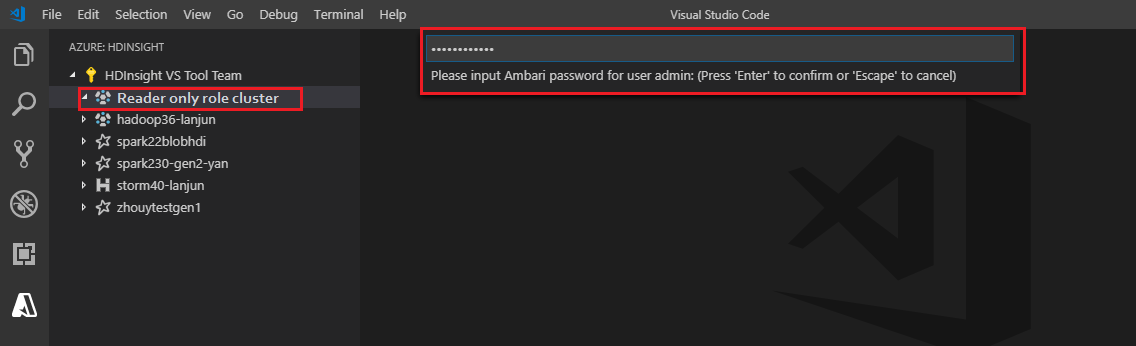
Feljegyzés
A csatolt fürt ellenőrzéséhez használhatja
Spark / Hive: List Clustera következőt:
Azure Data Lake Storage Gen2
2. generációs Data Lake Storage-fiók tallózása
A Data Lake Storage Gen2-fiók kibontásához válassza az Azure HDInsight Explorert. A rendszer kéri, hogy adja meg a tárelérési kulcsot, ha az Azure-fiókja nem fér hozzá a Gen2-tárolóhoz. A hozzáférési kulcs érvényesítése után a Data Lake Storage Gen2-fiók automatikusan ki lesz bontva.
Feladatok elküldése HDInsight-fürtbe a Data Lake Storage Gen2 használatával
Feladat elküldése EGY HDInsight-fürtbe a Data Lake Storage Gen2 használatával. A rendszer kéri, hogy adja meg a tárelérési kulcsot, ha az Azure-fiókja nem rendelkezik írási hozzáféréssel a Gen2 Storage-hoz. A hozzáférési kulcs ellenőrzése után a feladat sikeresen el lesz küldve.

Feljegyzés
A tárfiók hozzáférési kulcsát az Azure Portalon szerezheti be. További információ: Tárfiók hozzáférési kulcsainak kezelése.
Fürt leválasztva
A menüsávon lépjen a Parancskatalógus megtekintése>lapra, majd írja be a Spark/Hive: Fürt leválasztása parancsot.
Válassza ki a leválasztani kívánt fürtöt.
Az ellenőrzéshez tekintse meg a OUTPUT nézetet.
Kijelentkezés
A menüsávon lépjen a Parancskatalógus megtekintése>lapra, majd írja be az Azure: Kijelentkezés parancsot.
Ismert problémák
A Synapse PySpark telepítési hibája.
A Synapse PySpark telepítési hibája esetén, mivel függőségét a többi csapat már nem fogja fenntartani, többé nem fogja fenntartani. Ha a Synapse Pyspark interaktív használatát szeretné használni, használja inkább az Azure Synapse Analyticset . És ez hosszú távú változás.

Következő lépések
A Visual Studio Code-hoz készült Spark & Hive használatát bemutató videóért tekintse meg a Spark > Hive for Visual Studio Code-ot.