Apache Hive-lekérdezések optimalizálása az Azure HDInsightban
Ez a cikk az Apache Hive-lekérdezések teljesítményének javítására használható leggyakoribb teljesítményoptimalizálásokat ismerteti.
Fürttípus kiválasztása
Az Azure HDInsightban Apache Hive-lekérdezéseket futtathat néhány különböző fürttípuson.
Válassza ki a megfelelő fürttípust a számítási feladatok teljesítményének optimalizálásához:
- Az interaktív lekérdezésekhez optimalizálandó
ad hocinteraktív lekérdezésfürttípus kiválasztása. - Válassza az Apache Hadoop-fürttípust a kötegelt folyamatként használt Hive-lekérdezésekhez való optimalizáláshoz.
- A Spark - és HBase-fürttípusok Hive-lekérdezéseket is futtathatnak, és megfelelőek lehetnek, ha ezeket a számítási feladatokat futtatja.
További információ a Hive-lekérdezések különböző HDInsight-fürttípusokon való futtatásáról: Mi az Az Apache Hive és a HiveQL az Azure HDInsighton?
Feldolgozó csomópontok vertikális felskálázása
A HDInsight-fürtök feldolgozó csomópontjainak számának növelése lehetővé teszi, hogy a munka több leképezőt és redukálót használjon párhuzamosan. A HDInsightban kétféleképpen növelheti a skálázást:
Fürt létrehozásakor megadhatja a feldolgozó csomópontok számát az Azure Portal, az Azure PowerShell vagy a parancssori felület használatával. További információ: HDInsight-fürtök létrehozása. Az alábbi képernyőképen a feldolgozó csomópont konfigurációja látható az Azure Portalon:
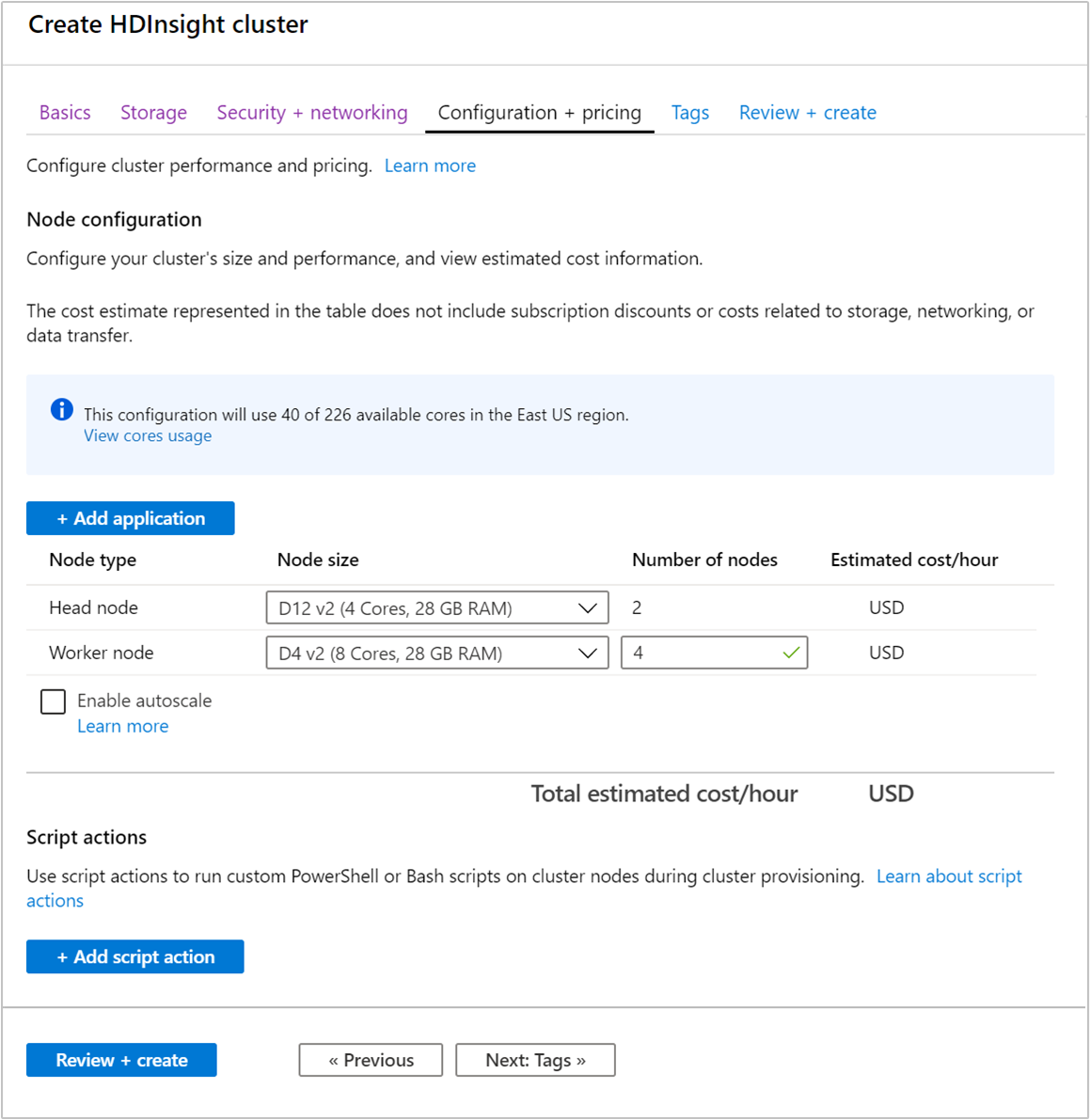
A létrehozás után a feldolgozó csomópontok számát is módosíthatja a fürtök további skálázásához anélkül, hogy újra létrehozunk egyet:
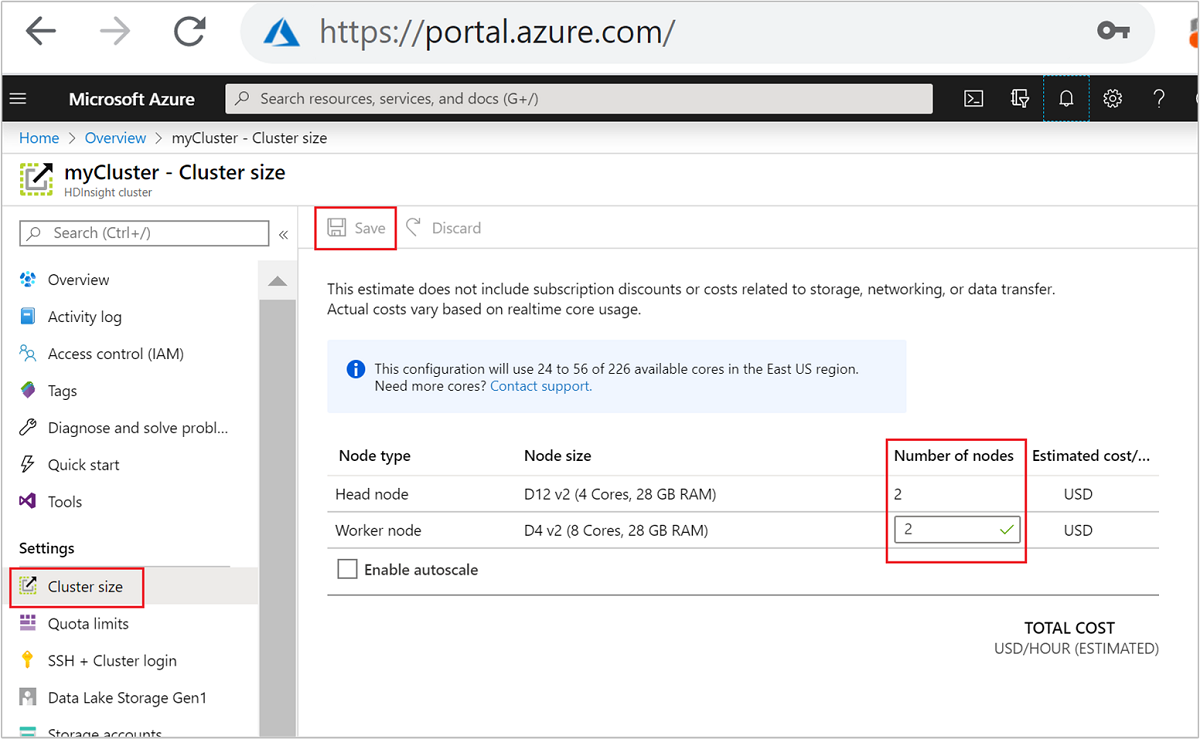
A HDInsight skálázásával kapcsolatos további információkért lásd: HDInsight-fürtök méretezése
Az Apache Tez használata térképcsökkentés helyett
Az Apache Tez a MapReduce motor alternatív végrehajtó motorja. A Linux-alapú HDInsight fürtökben a Tez alapértelmezés szerint engedélyezve.
Tez gyorsabb, mert:
- Directed Acyclic Graph (DAG) egyetlen feladatként történő végrehajtása a MapReduce motorban. A DAG megköveteli, hogy a leképezők minden egyes csoportját egy-egy redukáló csoport kövesse. Ez a követelmény azt eredményezi, hogy minden egyes Hive-lekérdezéshez több MapReduce-munkát kell indítani. A Tez nem rendelkezik ilyen korlátozással, és képes az összetett DAG-ot egyetlen feladatként feldolgozni, minimalizálva a feladat indítási terheit.
- Elkerüli a felesleges írásokat. A MapReduce motorban több feladatot használnak ugyanazon Hive-lekérdezés feldolgozására. Az egyes MapReduce-feladatok kimenete a HDFS-re kerül kiírásra a köztes adatokhoz. Mivel a Tez minimalizálja az egyes Hive-lekérdezésekhez tartozó feladatok számát, elkerülheti a szükségtelen írásokat.
- Minimalizálja az indítási késedelmeket. A Tez jobban képes minimalizálni az indítási késedelmet azáltal, hogy csökkenti az indításhoz szükséges leképezők számát, és az optimalizálást is végig javítja.
- Újrahasznosítja a tartályokat. Amikor csak lehetséges, a Tez újrafelhasználja a konténereket, hogy a konténerek indításából adódó késleltetés csökkenjen.
- Folyamatos optimalizálási technikák. Az optimalizálást hagyományosan a fordítási fázisban végezték. A bemenetekről azonban több információ áll rendelkezésre, amelyek lehetővé teszik a jobb optimalizálást a futás során. A Tez folyamatos optimalizálási technikákat alkalmaz, amelyek lehetővé teszik a terv további optimalizálását a futási fázisban.
További információ ezekről a fogalmakról: Apache TEZ.
Bármely Hive-lekérdezést engedélyezhet a lekérdezés előtagjával a következő beállítási paranccsal:
set hive.execution.engine=tez;
Hive particionálás
Az I/O-műveletek a Hive-lekérdezések futtatásának fő teljesítménybeli szűk keresztmetszetei. A teljesítmény javítható, ha az olvasni kívánt adatok mennyisége csökkenthető. A Hive-lekérdezések alapértelmezés szerint teljes Hive-táblákat vizsgálnak. Az olyan lekérdezések esetében azonban, amelyeknek csak kis mennyiségű adatot kell beolvasni (például szűréssel rendelkező lekérdezéseket), ez a viselkedés szükségtelen többletterhelést okoz. A Hive particionálása lehetővé teszi, hogy a Hive-lekérdezések csak a Szükséges mennyiségű adatot érhessék el a Hive-táblákban.
A Hive particionálás a nyers adatok új könyvtárakba való átrendezésével implementálható. Minden partíciónak saját fájlkönyvtára van. A felhasználó határozza meg a particionálást. Az alábbi ábra egy Hive-tábla Év oszlop szerinti particionálását mutatja be. Minden évben létrejön egy új könyvtár.
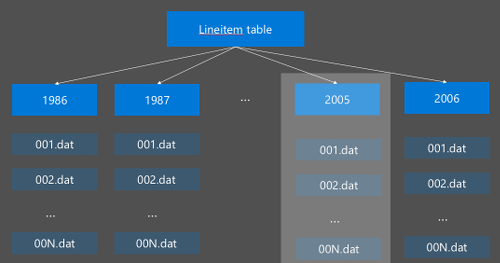
Néhány particionálási szempont:
- Nincs partíció alatt – A csak néhány értékkel rendelkező oszlopok particionálása kevés partíciót okozhat. A nem szerinti particionálás például csak két létrehozandó partíciót hoz létre (férfi és nő), így a késést legfeljebb felére csökkentheti.
- Ne használja a partíciót – A másik szélső esetben egy egyedi értékkel (például userid) rendelkező oszlop partíciójának létrehozása több partíciót okoz. A particionálás túl sok stresszt okoz a fürtnévcsomóponton, mivel nagy számú könyvtárat kell kezelnie.
- Kerülje az adateltérést – Válassza ki bölcsen a particionálási kulcsot, hogy az összes partíció mérete egyenletes legyen. Az Állapot oszlop particionálása például eltűrheti az adatok eloszlását. Mivel Kalifornia állam lakossága majdnem 30-szor nagyobb, mint Vermonté, a partíció mérete valószínűleg ferde, és a teljesítmény rendkívül eltérő lehet.
Partíciótábla létrehozásához használja a Particionált by záradékot:
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
A particionált tábla létrehozása után statikus particionálást vagy dinamikus particionálást hozhat létre.
A statikus particionálás azt jelenti, hogy a megfelelő könyvtárakban már vannak horizontálisan elosztott adatok. Statikus partíciók esetén manuálisan adja hozzá a Hive-partíciókat a címtár helye alapján. A következő kódrészlet egy példa.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'A dinamikus particionálás azt jelenti, hogy azt szeretné, hogy a Hive automatikusan hozzon létre partíciókat. Mivel már létrehozta a particionáló táblát az előkészítési táblából, mindössze annyit kell tennie, hogy adatokat szúr be a particionált táblába:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
További információ: Particionált táblák.
Az ORCFile formátum használata
A Hive különböző fájlformátumokat támogat. Példa:
- Szöveg: az alapértelmezett fájlformátum, és a legtöbb forgatókönyv esetében működik.
- Avro: jól működik az együttműködési forgatókönyvekben.
- ORC/Parquet: a legjobban alkalmas teljesítményre.
Az ORC (optimalizált soroszlopos) formátum rendkívül hatékony módszer a Hive-adatok tárolására. Más formátumokhoz képest az ORC a következő előnyökkel jár:
- összetett típusok, például a DateTime és az összetett és félig strukturált típusok támogatása.
- akár 70%-os tömörítést is.
- 10 000 soronként indexel, ami lehetővé teszi a sorok kihagyását.
- a futásidejű végrehajtás jelentős csökkenése.
Az ORC formátum engedélyezéséhez először létre kell hoznia egy táblát az ORC-ként tárolt záradékkal:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Ezután adatokat szúr be az ORC-táblába az előkészítési táblából. Példa:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Az ORC formátumról az Apache Hive Language kézikönyvében olvashat bővebben.
Vektorizálás
A vektorizálás lehetővé teszi a Hive számára, hogy 1024 sorból álló kötegeket együttesen dolgozzon fel ahelyett, hogy egyszerre egy-egy sort dolgozna fel. Ez azt jelenti, hogy az egyszerű műveletek gyorsabban végezhetők el, mivel kevesebb belső kódot kell futtatni.
A Hive-lekérdezés vektorizálási előtagjának engedélyezéséhez a következő beállítással:
set hive.vectorized.execution.enabled = true;
További információ: Vektoros lekérdezés végrehajtása.
Egyéb optimalizálási módszerek
Több optimalizálási módszer is megfontolható, például:
- Hive-gyűjtő: olyan technika, amellyel nagy adathalmazokat csoportosíthat vagy szegmentelhet a lekérdezési teljesítmény optimalizálása érdekében.
- Csatlakozás optimalizálása: a Hive lekérdezés-végrehajtási tervezésének optimalizálása az illesztések hatékonyságának javítása és a felhasználói tippek szükségletének csökkentése érdekében. További információ: Csatlakozás optimalizálása.
- Csökkentse a redukálókat.
Következő lépések
Ebben a cikkben számos gyakori Hive-lekérdezésoptimalizálási módszert ismert meg. További tudnivalókért olvassa el a következő cikket: