Azure HDInsighton futó Apache Spark-feladatok hibakeresése
Ebből a cikkből megtudhatja, hogyan követheti nyomon és hibakeresésre használhatja a HDInsight-fürtökön futó Apache Spark-feladatokat. Hibakeresés az Apache Hadoop YARN felhasználói felületén, a Spark felhasználói felületén és a Spark-előzménykiszolgálón. Spark-feladat indítása a Spark-fürttel elérhető jegyzetfüzettel, Gépi tanulás: Az élelmiszer-ellenőrzési adatok prediktív elemzése az MLLib használatával. Az alábbi lépésekkel nyomon követheti az ön által bármely más módszerrel elküldött alkalmazást, például a spark-submitt is.
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot.
Előfeltételek
Apache Spark-fürt megléte a HDInsightban. További útmutatásért lásd: Apache Spark-fürt létrehozása az Azure HDInsightban.
El kellett volna kezdenie a machine learning: Prediktív elemzés az élelmiszer-ellenőrzési adatokon az MLLib használatával. A jegyzetfüzet futtatásával kapcsolatos utasításokért kövesse a hivatkozást.
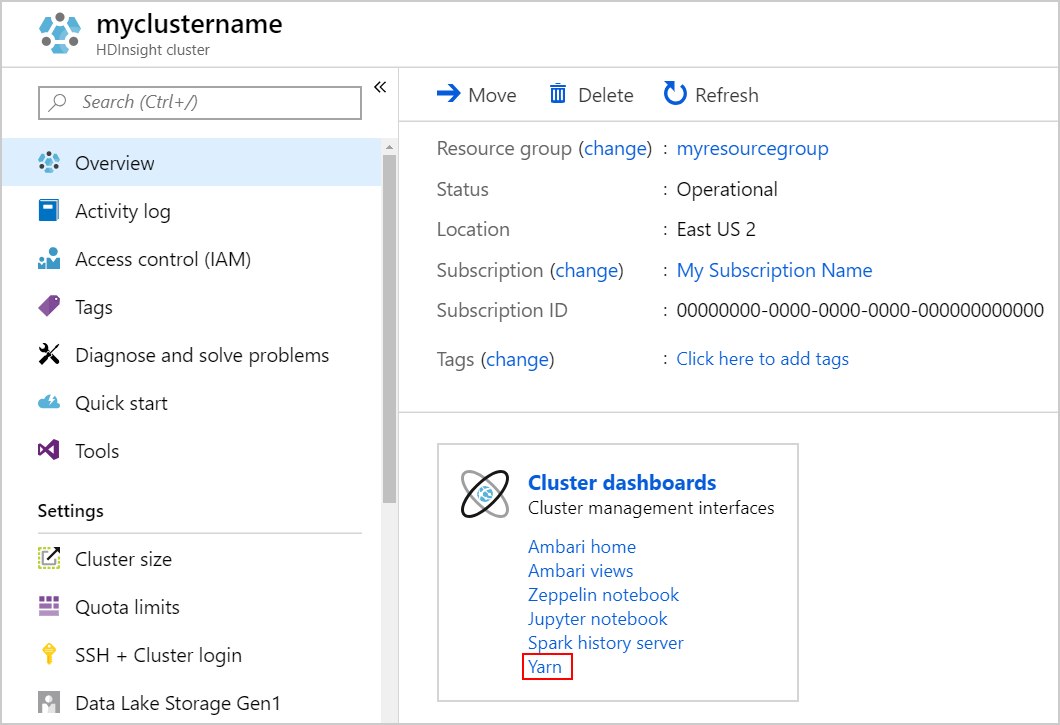
Alkalmazás nyomon követése a YARN felhasználói felületén
Indítsa el a YARN felhasználói felületet. Válassza a Yarn lehetőséget a Fürt irányítópultok alatt.
Tipp.
Azt is megteheti, hogy elindítja a YARN felhasználói felületet az Ambari felhasználói felületén. Az Ambari felhasználói felületének elindításához válassza az Ambari kezdőlapot a Fürt irányítópultok alatt. Az Ambari felhasználói felületén lépjen a YARN>gyorshivatkozásokra> az aktív Resource Manager >Resource Manager felhasználói felületén.
Mivel a Spark-feladatot Jupyter Notebooks használatával indította el, az alkalmazás neve remotesparkmagics (a jegyzetfüzetekből indított összes alkalmazás neve). Válassza ki az alkalmazásazonosítót az alkalmazás nevére, hogy további információt kapjon a feladatról. Ez a művelet elindítja az alkalmazásnézetet.
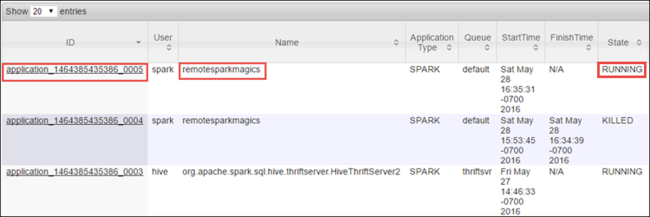
A Jupyter-jegyzetfüzetekből indított alkalmazások esetében az állapot mindig FUT , amíg ki nem lép a jegyzetfüzetből.
Az alkalmazásnézetből részletesebben is megismerheti az alkalmazáshoz és a naplókhoz (stdout/stderr) társított tárolókat. A Spark felhasználói felületét úgy is elindíthatja, hogy a nyomkövetési URL-címnek megfelelő hivatkozásra kattint, ahogy az alább látható.

Alkalmazás nyomon követése a Spark felhasználói felületén
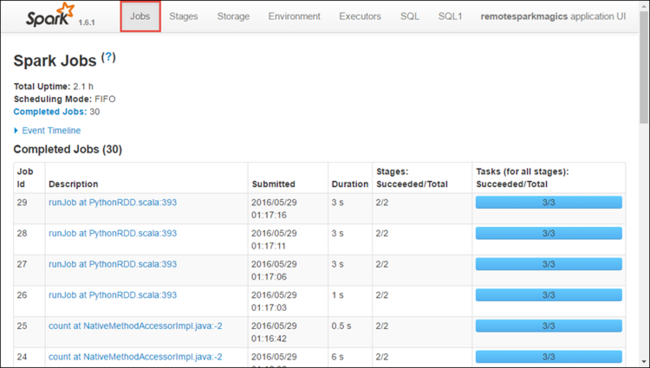
A Spark felhasználói felületén részletezheti a korábban elindított alkalmazás által létrehozott Spark-feladatokat.
A Spark felhasználói felületének elindításához az alkalmazásnézetből válassza ki a nyomkövetési URL-címre mutató hivatkozást a fenti képernyőfelvételen látható módon. A Jupyter Notebookban futó alkalmazás által elindított összes Spark-feladatot láthatja.
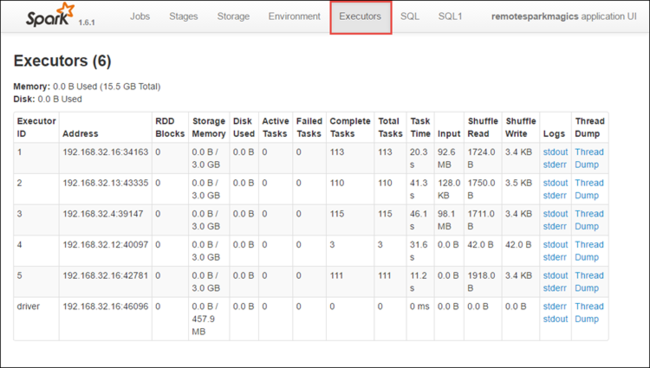
A Végrehajtók lapon megtekintheti az egyes végrehajtók feldolgozási és tárolási adatait. A hívásverem lekéréséhez válassza a Szálkép hivatkozását.
Válassza a Szakaszok lapot az alkalmazáshoz társított szakaszok megtekintéséhez.
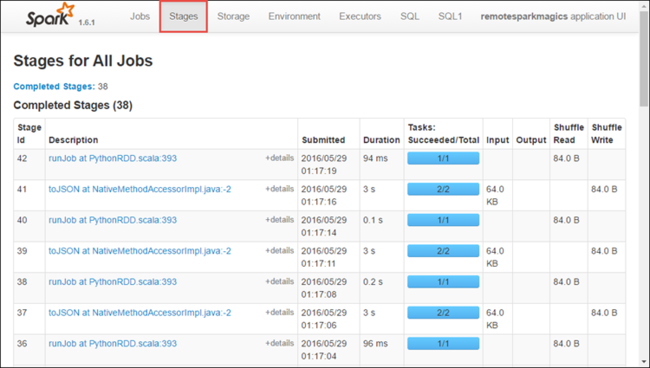
Minden fázisban több tevékenység is lehet, amelyek végrehajtási statisztikáit tekintheti meg, az alábbiakban látható módon.
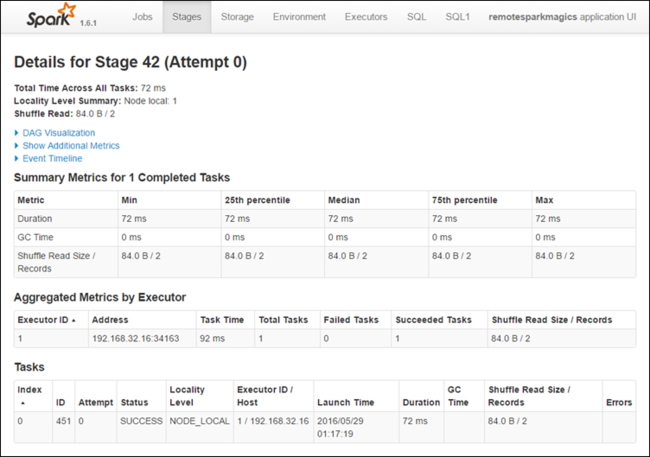
A szakasz részletei lapon elindíthatja a DAG-vizualizációt. Bontsa ki a DAG Vizualizáció hivatkozást a lap tetején, ahogy az alább látható.
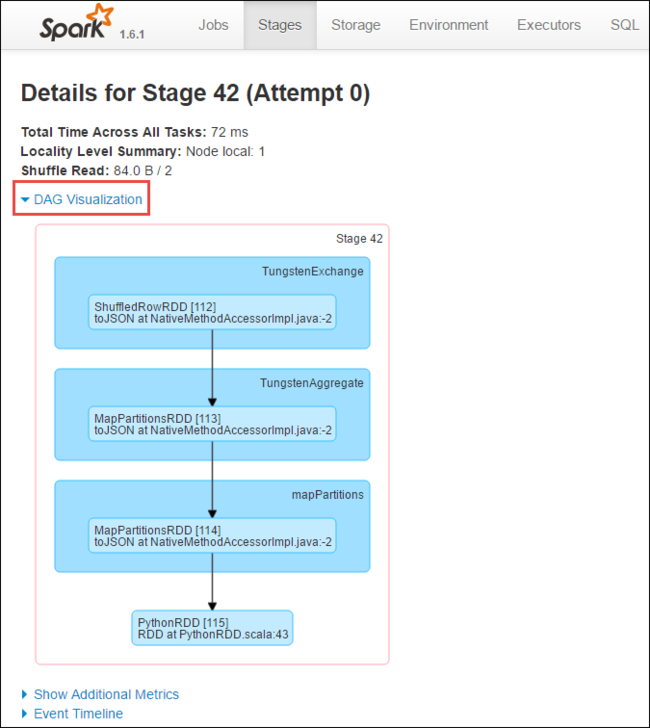
A DAG vagy a Közvetlen Aklyic Graph az alkalmazás különböző szakaszait jelöli. A gráf minden kék mezője az alkalmazásból meghívott Spark-műveletet jelöli.
A szakasz részletei lapon elindíthatja az alkalmazás idővonal nézetét is. Bontsa ki az eseménysor hivatkozását a lap tetején, ahogy az alább látható.

Ez a kép ütemterv formájában jeleníti meg a Spark-eseményeket. Az ütemterv nézet három szinten érhető el, feladatok között, egy feladaton belül és egy fázison belül. A fenti kép egy adott szakasz idővonalnézetét rögzíti.
Tipp.
Ha bejelöli a Nagyítás engedélyezése jelölőnégyzetet, görgethet balra és jobbra az idővonal nézetében.
A Spark felhasználói felületén található egyéb lapok is hasznos információkat nyújtanak a Spark-példányról.
- Storage tab – Ha az alkalmazás RDD-t hoz létre, a Tár lapon talál információkat.
- Környezet lap – Ez a lap hasznos információkat nyújt a Spark-példányról, például a következőkről:
- Scala-verzió
- A fürthöz társított eseménynapló-címtár
- Az alkalmazás végrehajtó magjainak száma
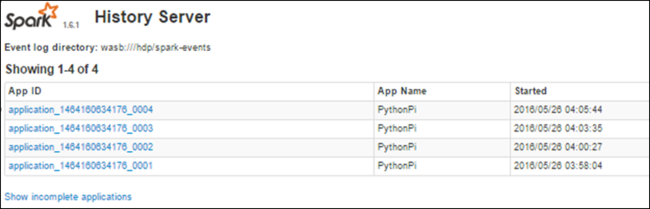
A sparkelőzmény-kiszolgálóval befejezett feladatok adatainak megkeresése
A feladat befejezése után a feladat adatai megmaradnak a Spark-előzménykiszolgálón.
A Spark-előzménykiszolgáló elindításához az Áttekintés lapon válassza a Spark-előzménykiszolgálót a Fürt irányítópultok területén.
Tipp.
Másik lehetőségként elindíthatja a Spark History Server felhasználói felületét is az Ambari felhasználói felületén. Az Ambari felhasználói felületének elindításához az Áttekintés panelen válassza az Ambari kezdőlapot a Fürt irányítópultok alatt. Az Ambari felhasználói felületén lépjen a Spark2 Gyorshivatkozások>Spark2>előzménykiszolgáló felhasználói felületére.
Az összes befejezett alkalmazás megjelenik a listában. Válasszon ki egy alkalmazásazonosítót az alkalmazások részletes részletezéséhez további információkért.