Oktatóanyag: Adatok betöltése és lekérdezések futtatása egy Apache Spark-fürtön az Azure HDInsightban
Ebben az oktatóanyagban megtudhatja, hogyan hozhat létre adatkeretet egy csv-fájlból, és hogyan futtathat interaktív Spark SQL-lekérdezéseket egy Apache Spark-fürtön az Azure HDInsightban. A Sparkban az adathalmazok olyan elosztott adatgyűjtemények, amelyek megnevezett oszlopokba vannak rendezve. Az adathalmazok elméleti szinten azonosak a relációs adatbázisokban található táblákkal vagy R/Python-adathalmazokkal.
Ebben az oktatóanyagban az alábbiakkal fog megismerkedni:
- Adathalmaz létrehozása egy CSV-fájlból
- Lekérdezések futtatása az adathalmazon
Előfeltételek
Apache Spark-fürt megléte a HDInsightban. Lásd: Apache Spark-fürt létrehozása.
Jupyter-notebook létrehozása
A Jupyter Notebook egy interaktív notebook-környezet, amely számos programozási nyelvet támogat. A notebook lehetővé teszi az adatai használatát, a kódok és markdown-szövegek egyesítését, valamint egyszerű vizualizációk elvégzését.
Szerkessze az URL-címet
https://SPARKCLUSTER.azurehdinsight.net/jupytera Spark-fürt nevére cserélveSPARKCLUSTER. Ezután adja meg a szerkesztett URL-címet egy webböngészőben. Ha a rendszer kéri, adja meg a fürthöz tartozó bejelentkezési hitelesítő adatokat.A Jupyter weblapján a Spark 2.4-fürtök esetében válassza az Új>PySpark lehetőséget jegyzetfüzet létrehozásához. A Spark 3.1 kiadásnál válassza az Új>PySpark3 lehetőséget a jegyzetfüzet létrehozásához, mert a PySpark kernel már nem érhető el a Spark 3.1-ben.
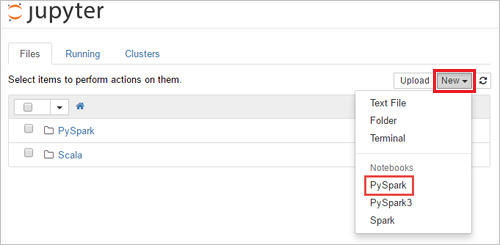
A rendszer létrehoz és megnyit egy új jegyzetfüzetet Untitled(
Untitled.ipynb) néven.Feljegyzés
Ha a PySpark vagy a PySpark3 kernel használatával hoz létre egy jegyzetfüzetet, a rendszer automatikusan létrehozza a
sparkmunkamenetet az első kódcella futtatásakor. A munkamenetet nem szükséges manuálisan létrehoznia.
Adathalmaz létrehozása egy CSV-fájlból
Az alkalmazások közvetlenül a távoli tároló fájljaiból vagy mappáiból hozhatnak létre adatkereteket, például az Azure Storage-ból vagy az Azure Data Lake Storage-ból; Hive-táblából; vagy a Spark által támogatott egyéb adatforrásokból, például az Azure Cosmos DB-ből, az Azure SQL DB-ből, a DW-ből stb. A következő képernyőképen az oktatóanyaghoz használt HVAC.csv fájl pillanatfelvétele látható. Ez a csv-fájl minden HDInsight Spark-fürtön megtalálható. Az adatok néhány épület hőmérséklet-változását rögzítik.

Illessze be a következő kódot a Jupyter Notebook üres cellájába, majd nyomja le a SHIFT + ENTER billentyűkombinációt a kód futtatásához. A kód importálja az alábbi forgatókönyvhöz szükséges típusokat:
from pyspark.sql import * from pyspark.sql.types import *Amikor a Jupyterben interaktív lekérdezést futtatunk, a böngésző ablakának vagy lapjának címsorában a (Foglalt) állapot jelenik meg a notebook neve mellett. A jobb felső sarokban lévő PySpark felirat mellett ekkor egy teli kör is megjelenik. A feladat befejezése után ez a jel üres körre változik.
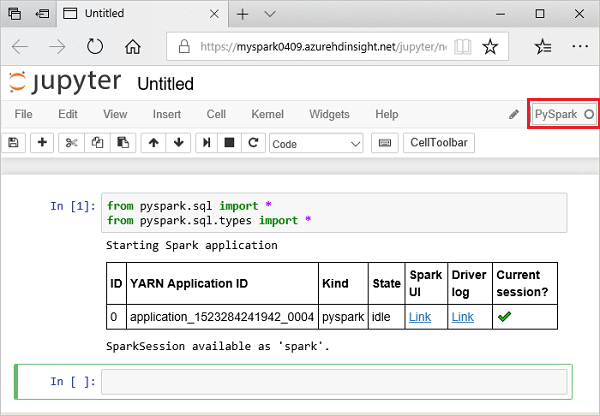
Jegyezze fel a visszaadott munkamenet-azonosítót. A fenti képen a munkamenet azonosítója 0. Szükség esetén lekérheti a munkamenet adatait, ha arra a helyre navigál
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statements, ahol a CLUSTERNAME a Spark-fürt neve, az azonosító pedig a munkamenet-azonosító száma.Hozzon létre egy adathalmazt és egy ideiglenes táblát (hvac) a következő kód futtatásával.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Lekérdezések futtatása az adathalmazon
A tábla létrehozása után az adatokon interaktív lekérdezéseket futtathat.
Futtassa a következő kódot a notebook egy üres cellájában:
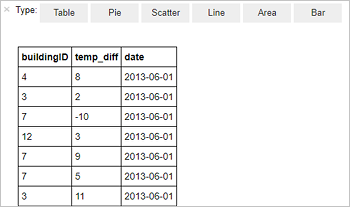
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Az alábbi táblázatos kimenet jelenik meg.
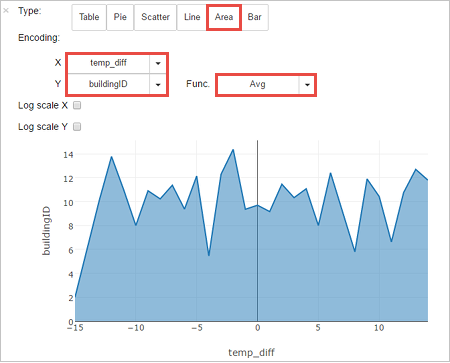
Az eredményeket egyéb megjelenítési formákban is megtekintheti. Az azonos kimenethez tartozó területgrafikon megjelenítéséhez válassza az Area (Terület) lehetőséget, majd állítsa be a további értékeket az ábra szerint.
A jegyzetfüzet menüsávjában keresse meg a Fájl>mentése és az Ellenőrzőpont lehetőséget.
Ha most kezd bele a következő oktatóanyagba, hagyja nyitva a notebookot. Ha nem, állítsa le a jegyzetfüzetet a fürterőforrások felszabadításához: a jegyzetfüzet menüsávjában keresse meg a Fájlbezárás>és a Leállítás lehetőséget.
Az erőforrások eltávolítása
A HDInsight segítségével az adatok és a Jupyter Notebookok az Azure Storage-ban vagy az Azure Data Lake Storage-ban vannak tárolva, így biztonságosan törölheti a fürtöket, ha nincsenek használatban. A HDInsight-fürtökért is díjat számítunk fel, még akkor is, ha nincs használatban. Mivel a fürt díjai sokszor nagyobbak, mint a tárolási díjak, érdemes törölni a fürtöket, ha nincsenek használatban. Ha azt tervezi, hogy rögtön elvégzi a következő oktatóanyagot is, akkor érdemes lehet megtartani a fürtöt.
Nyissa meg az Azure Portalon a fürtöt, és válassza a Törlés lehetőséget.

Az erőforráscsoport nevét kiválasztva is megnyílik az erőforráscsoport oldala, ahol kiválaszthatja az Erőforráscsoport törlése elemet. Az erőforráscsoport törlésekor a rendszer a HDInsight Spark-fürtöt és az alapértelmezett tárfiókot is törli.
Következő lépések
Ebben az oktatóanyagban megtanulta, hogyan hozhat létre adatkeretet egy csv-fájlból, és hogyan futtathat interaktív Spark SQL-lekérdezéseket egy Apache Spark-fürtön az Azure HDInsightban. A következő cikkből megtudhatja, hogy az Apache Sparkban regisztrált adatok hogyan állíthatók be egy OLYAN BI-elemző eszközbe, mint a Power BI.