Az elmúlt néhány évben a biztosítók és a biztosítási termékeket biztosító társaságok számos új szabályozást léptek életbe. Ezek az új szabályozások kiterjedtebb pénzügyi modellezést igényeltek a biztosítók számára. Az Európai Unió a Szolvencia II. Ez a törvény megköveteli a biztosítóktól, hogy bizonyítsák, hogy elvégezték a megfelelő elemzésüket annak ellenőrzéséhez, hogy a biztosító fizetőképes lesz-e az év végén. A változó járadékot biztosító biztosítóknak az XLIII. aktuáriusi iránymutatást kell követniük az eszköz- és a felelősségi pénzáramlás átfogó elemzésével. 2021-ig minden biztosítótípusnak, beleértve a biztosítási jellegű termékeket terjesztőket is, 2021-ig végre kell hajtania a 17. nemzetközi pénzügyi beszámolási standardot (IFRS 17 ). (Az IFRS a nemzetközi finanszírozási jelentési szabványokat jelenti.) Más szabályozások is léteznek, attól függően, hogy a biztosítók milyen joghatóságokban működnek. Ezek a szabványok és szabályozások megkövetelik, hogy az aktuáriusok számításigényes technikákat alkalmazzanak az eszközök és kötelezettségek modellezése során. Az elemzés nagy része a stochastly által generált forgatókönyvadatokat használja fel az eszközök és kötelezettségek seriatim bemeneteihez. A szabályozási igényeken túl az aktuáriusok megfelelő mennyiségű pénzügyi modellezést és számítást végeznek. A szabályozási jelentéseket létrehozó modellek bemeneti tábláinak létrehozása. A belső rácsok nem elégítik ki a számítási igényeket, ezért az aktuáriusok folyamatosan a felhőbe kerülnek.
Az aktuáriusok áttérnek a felhőbe, hogy több ideje legyen az eredmények áttekintésére, kiértékelésére és ellenőrzésére. A szabályozók a biztosítók ellenőrzésekor az aktuáriusoknak képesnek kell lenniük az eredmények magyarázatára. A felhőbe való áttérés hozzáférést biztosít a számítási erőforrásokhoz, hogy 24–120 óra óra alatt 20 000 órányi elemzést futtasson a párhuzamosítás erejével. A skálázás szükségletének elősegítése érdekében az aktuáriusi szoftvereket létrehozó vállalatok közül sok olyan megoldást kínál, amely lehetővé teszi a számítások futtatását az Azure-ban. Ezen megoldások némelyike a helyszínen és az Azure-ban futó technológiákra épül, például a nagy teljesítményű számítási PowerShell-megoldásra, a HPC Packre. Más megoldások natívak az Azure-ban, és az Azure Batchet, a virtuálisgép-méretezési csoportokat vagy egy egyéni skálázási megoldást használnak.
Ebben a cikkben azt vizsgáljuk meg, hogyan használhatják az aktuáriusi fejlesztők az Azure-t modellezési csomagokkal párosítva a kockázatok elemzéséhez. A cikk ismerteti az azure-technológiák némelyikét, amelyeket a modellezési csomagok az Azure-ban való nagy léptékű futtatáshoz használnak. Ugyanezzel a technológiával végezheti el az adatok további elemzését. A következő elemeket tekintjük meg:
- Nagyobb modellek futtatása kevesebb idő alatt az Azure-ban.
- Jelentéskészítés az eredményekről.
- Adatmegőrzés kezelése.
Akár élettartamot, vagyont, balesetet, egészséget vagy egyéb biztosítást nyújt, pénzügyi és kockázati modelleket kell létrehoznia eszközeiről és kötelezettségeiről. Ezután módosíthatja befektetéseit és díjait, hogy fizetőképes maradjon biztosítóként. Az IFRS 17 jelentéskészítés az aktuáriusok által létrehozott modelleket módosítja, például a szerződéses szolgáltatási árrést (CSM) számítja ki, amely megváltoztatja, hogy a biztosítók hogyan kezelik a nyereségüket az idő függvényében.
Több futás kevesebb idő alatt az Azure-ban
Hisz a felhő ígéretében: gyorsabban és egyszerűbben futtathatja pénzügyi és kockázati modelljeit. Sok biztosító esetében a borítékszámítás hátoldalán látható a probléma: évekre, vagy akár évtizedekre van szükségük ezeknek a számításoknak az elejétől a végéig történő futtatásához. A futtatókörnyezeti probléma megoldásához technológiára van szükség. A stratégiák a következők:
- Adat-előkészítés: Egyes adatok lassan változnak. Egy szabályzat vagy szolgáltatási szerződés hatályba lépése után a jogcímek kiszámítható ütemben mozognak. A modellfuttatásokhoz szükséges adatokat a beérkezéskor előkészítheti, így nincs szükség arra, hogy sok időt tervezzen az adatok tisztítására és előkészítésére. A fürtözés használatával is létrehozhat stand-ineket a seriatim adatokhoz súlyozott reprezentációkon keresztül. A kevesebb rekord általában csökkentett számítási időt eredményez.
- Párhuzamosítás: Ha ugyanazt az elemzést két vagy több elemhez kell elvégeznie, lehetséges, hogy egyszerre is el tudja végezni az elemzést.
Tekintsük át ezeket az elemeket egyenként.
Adatok előkészítése
Az adatfolyamok több különböző forrásból származnak. Részben strukturált szabályzatadatokkal rendelkezik üzleti könyveiben. A biztosítottakról, a cégekről és a különböző jelentkezési űrlapokon megjelenő elemekről is rendelkezik információval. A gazdasági forgatókönyv-generátorok (ESG-k) különböző formátumokban állítanak elő adatokat, amelyekhez szükség lehet a modell által használható űrlapra való fordításra. Az eszközök értékeinek aktuális adatai szintén normalizálást igényelnek. A tőzsdei adatok, a bérleti díjak pénzáramlási adatai, a jelzáloghitelek fizetési adatai és az egyéb eszközadatok mind némi előkészítést igényelnek, amikor a forrásról a modellre vált. Végül frissítenie kell az esetleges feltételezéseket a legutóbbi felhasználói adatok alapján. A modell futtatásának felgyorsításához előre előkészítheti az adatokat. Futásidőben az utolsó ütemezett frissítés óta szükséges frissítéseket kell hozzáadnia a módosításokhoz.
Hogyan készíti elő az adatokat? Először nézzük meg a gyakori biteket, majd nézzük meg, hogyan dolgozhatunk az adatok különböző megjelenési módjaival. Először is azt szeretné, hogy egy mechanizmus lekérje az összes módosítást az utolsó szinkronizálás óta. Ennek a mechanizmusnak egy rendezhető értéket kell tartalmaznia. A legutóbbi módosítások esetében ennek az értéknek nagyobbnak kell lennie, mint bármely korábbi módosítás. A két leggyakoribb két mechanizmus egy folyamatosan növekvő azonosító mező vagy időbélyeg. Ha egy rekordhoz növekvő azonosítókulcs tartozik, de a rekord többi része frissíthető mezőket tartalmaz, akkor a módosítások megkereséséhez egy "utolsó módosítású" időbélyeget kell használnia. A rekordok feldolgozása után jegyezze fel az utolsó frissített elem rendezhető értékét. Ez az érték, valószínűleg egy lastModified nevű mező időbélyege lesz a vízjele, amelyet az adattár későbbi lekérdezéseihez használnak. Az adatmódosítások többféleképpen is feldolgozhatók. Az alábbiakban két gyakori mechanizmust használunk, amelyek minimális erőforrásokat használnak:
- Ha több száz vagy több ezer módosítást kell feldolgoznia, töltse fel az adatokat a Blob Storage-ba. A változáskészlet feldolgozásához használjon eseményindítót az Azure Data Factoryben.
- Ha kis számú módosítást szeretne feldolgozni, vagy ha a módosítás után azonnal frissíteni szeretné az adatokat, helyezze az egyes módosításokat a Service Bus vagy a Tárolási üzenetsorok által üzemeltetett üzenetsorba. Ez a cikk nagyszerű magyarázatot ad a két várólistás technológia közötti kompromisszumokra. Ha egy üzenet egy üzenetsorba kerül, az Azure Functionsben vagy az Azure Data Factoryben használható eseményindítóval feldolgozhatja az üzenetet.
Az alábbi ábra egy tipikus forgatókönyvet mutat be. Az ütemezett feladatok először gyűjtenek néhány adatot, és tárolóba helyezik a fájlt. Az ütemezett feladat lehet egy helyszínen futó CRON-feladat, ütemező tevékenység, logikai alkalmazás vagy bármi, amely egy időzítőn fut. A fájl feltöltése után egy Azure-függvény vagy Data Factory-példány aktiválható az adatok feldolgozásához. Ha a fájl rövid idő alatt feldolgozható, használjon függvényt. Ha a feldolgozás összetett, mesterséges intelligenciát vagy más összetett szkripteket igényel, előfordulhat, hogy a HDInsight, az Azure Databricks vagy valami egyéni funkció jobban működik. Ha elkészült, a fájl használható formában, új fájlként vagy egy adatbázisban lévő rekordként megszűnik.
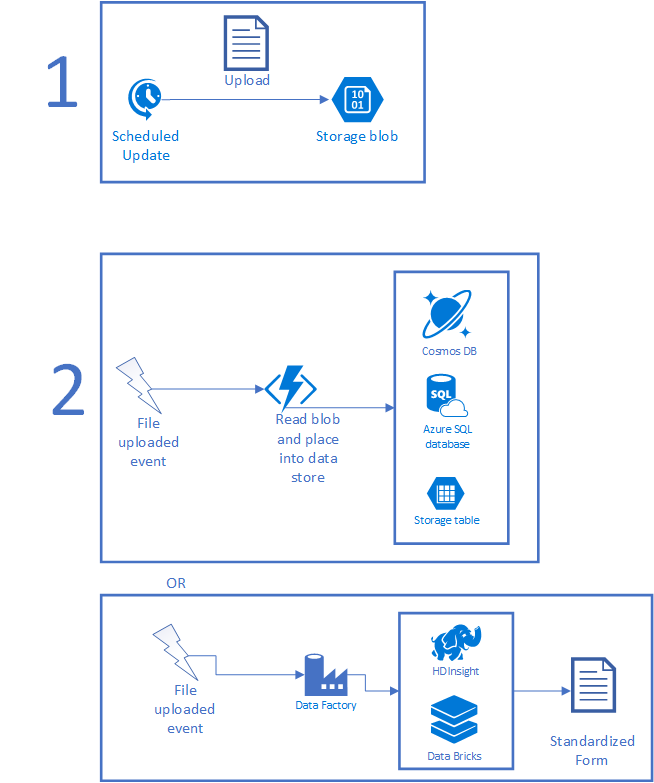
Ha az adatok az Azure-ban lesznek, a modellezési alkalmazásnak használhatóvá kell tennie azokat. Írhat kódot egyéni átalakításokhoz, futtathatja az elemeket a HDInsighton vagy az Azure Databricksen keresztül a nagyobb elemek betöltéséhez, vagy átmásolhatja az adatokat a megfelelő adatkészletekbe. A big data-eszközök használata olyan műveletekben is segíthet, mint a strukturálatlan adatok strukturált adatokká alakítása, valamint bármilyen AI és gépi tanulás futtatása a kapott adatokon keresztül. Virtuális gépeket is üzemeltethet, adatokat tölthet fel közvetlenül a helyszíni adatforrásokra, közvetlenül meghívhatja az Azure Functionst stb.
Később a modelleknek fel kell használniuk az adatokat. Ennek módja nagyban függ attól, hogy a számításoknak hogyan kell hozzáférnie az adatokhoz. Egyes modellezési rendszerekhez az összes adatfájlnak a számítást futtató csomóponton kell élnie. Mások olyan adatbázisokat használhatnak, mint az Azure SQL Database, a MySQL vagy a PostgreSQL. Bármelyik elemhez használhat alacsony költségű verziót, majd felskálázhatja a teljesítményt a modellezési futtatás során. Ez megadja a mindennapi munkához szükséges árat. Emellett további sebességet is biztosít, amikor több ezer mag kér adatokat. Ezek az adatok általában csak olvashatók lesznek a modellezési futtatás során. Ha a számítások több régióban is előfordulnak, fontolja meg az Azure Cosmos DB vagy az Azure SQL georeplikálását. Mindkettő olyan mechanizmusokat biztosít, amelyek alacsony késéssel automatikusan replikálják az adatokat a régiók között. A választás a fejlesztők által ismert eszközöktől, az adatok modellezésének módjától és a modellezési futtatáshoz használt régiók számától függ.
Szánjon egy kis időt arra, hogy átgondolja az adatok tárolásának helyét. Ismerje meg, hogy hány egyidejű kérés lesz ugyanarra az adatra vonatkozóan. Gondolja át, hogyan fogja terjeszteni az információkat:
- Minden számítási csomópont saját másolatot kap?
- A másolat nagy sávszélességű helyen van megosztva?
Ha az azure SQL-sel központosítottan tartja az adatokat, az adatbázis valószínűleg az idő nagy részében alacsonyabb árszinten marad. Ha az adatokat csak modellezési futtatás során használják, és nem frissítik túl gyakran, az Azure-ügyfelek olyan messzire mennek, hogy biztonsági másolatot készíthessenek az adatokról, és kikapcsolják az adatbázispéldányaikat a futtatások között. A lehetséges megtakarítások nagyok. Az ügyfelek az Azure SQL Elastic-készleteket is használhatják. Ezek az adatbázisok költségeinek szabályozására szolgálnak, különösen akkor, ha nem tudja, hogy mely adatbázisok lesznek nagy terhelés alatt különböző időpontokban. A rugalmas készletek lehetővé teszik az adatbázisok gyűjteményének, hogy annyi energiát használjanak, amennyire szükségük van, majd skálázzák vissza az igényeket a rendszer más részeire.
Előfordulhat, hogy le kell tiltania az adatszinkronizálást egy modellezési futtatás során, hogy a folyamat későbbi szakaszaiban a számítások ugyanazokat az adatokat használják. Ha sorba állítást használ, tiltsa le az üzenetfeldolgozókat, de engedélyezze az üzenetsorok számára az adatok fogadását.
A futtatás előtti időt gazdasági forgatókönyvek létrehozására, a biztosításmatematikai feltételezések frissítésére és általában más statikus adatok frissítésére is használhatja. Tekintsük át a gazdasági forgatókönyvek létrehozását (ESG). A Society of Actuaries biztosítja az Academy Kamatláb Generátor (AIRG), egy ESG, amely modell u. s. kincstár hozamok. Az AIRG-t olyan tételekben kell használni, mint az Értékelési kézikönyv 20 (VM-20). Más ESG-k modellezhetik a részvénypiacot, a jelzáloghiteleket, az áruárakat stb.
Mivel a környezet előre feldolgozza az adatokat, más adatokat is futtathat korábban. Előfordulhat például, hogy olyan dolgokat modellez, amelyek rekordokkal jelölik a nagyobb sokaságokat. Ezt általában rekordok fürtözésével lehet. Ha az adathalmaz szórványosan, például naponta egyszer frissül, a rekordhalmazt a betöltési folyamat részeként a modellben használt értékre csökkentheti.
Tekintsünk meg egy gyakorlati példát. Az IFRS-17 esetén a szerződéseket úgy kell csoportosítania, hogy a két szerződés kezdési dátuma közötti maximális távolság egy évnél rövidebb legyen. Tegyük fel, hogy ezt egyszerű módon teszi, és a szerződés évét használja csoportosítási mechanizmusként. Ez a szegmentálás akkor végezhető el, amikor az adatok betöltődnek az Azure-ba úgy, hogy beolvassa a fájlt, és áthelyezi a rekordokat a megfelelő évcsoportokba.
Az adatok előkészítésére összpontosítva kevesebb idő szükséges a modellösszetevők futtatásához. Az adatok korai beolvasásával időt takaríthat meg a modellek futtatásához.
Párhuzamosítás
A lépések megfelelő párhuzamosítása jelentősen lecsökkentheti az óra végrehajtási idejét. Ez a gyorsítás úgy történik, hogy hatékonyabbá teszi a megvalósítandó részeket, és tudja, hogyan fejezheti ki a modellt úgy, hogy két vagy több tevékenység egyszerre fusson. A trükk az, hogy megtaláljuk az egyensúlyt a munkahelyi kérelem mérete és az egyes csomópontok termelékenysége között. Ha a feladat több időt tölt a beállítással és a tisztítással, mint a kiértékelés során, túl kicsire ment. Ha a tevékenység túl nagy, a végrehajtási idő nem javul. Azt szeretné, hogy a tevékenység elég kicsi legyen ahhoz, hogy több csomóponton terjesszen el, és pozitív különbséget tegyen az eltelt végrehajtási időben.
Ahhoz, hogy a lehető legtöbbet hozhassa ki a rendszerből, ismernie kell a modell munkafolyamatát, valamint azt, hogy a számítások hogyan működnek együtt a vertikális felskálázás lehetőségével. A szoftvernek lehetnek feladatai, feladatai vagy hasonló fogalmai. Ezzel a tudással olyan dolgot tervezhet, amely feloszthatja a munkát. Ha van néhány egyéni lépés a modellben, tervezzen úgy, hogy a bemenetek kisebb csoportokra legyenek felosztva feldolgozásra. Ezt a kialakítást gyakran pontgyűjtési mintának is nevezik.
- Pont: ossza fel a bemeneteket természetes vonalak mentén, és engedélyezze a különálló tevékenységek futtatását.
- Gyűjtse össze: a feladatok befejeződése után gyűjtse össze a kimeneteket.
A dolgok felosztásakor azt is tudnia kell, hogy hol kell szinkronizálni a folyamatot, mielőtt továbblépne. Van néhány gyakori hely, ahol az emberek felosztják a dolgokat. Beágyazott sztochasztikus futtatások esetén ezer külső hurok lehet, amelyek inflexiós pontok készletével száz forgatókönyv belső ciklusait futtatják. Minden külső hurok egyszerre futhat. Megáll egy inflexiós ponton, majd egyszerre futtatja a belső hurkokat, visszahozza az adatokat a külső hurok adatainak módosításához, és folytassa újra. Az alábbi ábra a munkafolyamatot mutatja be. Elegendő számítási kapacitást figyelembe véve 100 000 magon futtathatja a 100 000 belső hurkot, így a feldolgozási idő a következő időpontok összegére csökken:

A terjesztés a művelet módjától függően egy kicsit nő. Ez lehet olyan egyszerű, mint egy kis feladat létrehozása a megfelelő paraméterekkel, vagy olyan összetett, mint 100 000 fájl másolása a megfelelő helyekre. A feldolgozási eredmények akkor is felgyorsíthatók, ha az eredményösszesítést az Azure HDInsightból, az Azure Databricksből vagy a saját üzembe helyezéséből származó Apache Spark használatával terjesztheti. A számítástechnika átlaga például az eddig látott elemek számának és az összegnek a megjegyzése. Más számítások több ezer maggal rendelkező gépen jobban működnek. Ezekhez gpu-kompatibilis gépeket használhat az Azure-ban.
A legtöbb aktuáriusi csapat úgy kezdi ezt az utat, hogy a modelljeit az Azure-ba helyezi át. Ezután időzítési adatokat gyűjtenek a folyamat különböző lépéseiről. Ezután az egyes lépések óraidejének rendezése a leghosszabbtól a legrövidebb eltelt időig. Nem fogják megvizsgálni a teljes végrehajtási időt, mivel valami több ezer magórát, de csak 20 percet fog igénybe használni. Az aktuáriusi fejlesztők a leghosszabb ideig futó feladatlépések mindegyikében keresnek módot az eltelt idő csökkentésére, miközben a megfelelő eredményeket kapják. Ez a folyamat rendszeresen ismétlődik. Néhány aktuáriusi csapat beállít egy cél futási időt, tegyük fel, hogy egy éjszakai fedezeti elemzés célja, hogy 8 órán belül fusson. Amint az idő több mint 8,25 órát csúszik, az aktuáriusi csapat egy része átvált, hogy javítsa az elemzés leghosszabb darabjának idejét. Ha 7,5 óra alatt visszakapják az időt, visszaállnak a fejlesztésre. A visszalépéshez és az optimalizáláshoz használt heurisztika az aktuáriusok között eltérő.
Mindezek futtatásához több lehetősége is van. A legtöbb aktuáriusi szoftver számítási rácsokkal működik. A helyszínen és az Azure-ban működő rácsok HPC-csomagot, partnercsomagot vagy egyénit használnak. Az Azure-ra optimalizált rácsok virtuálisgép-méretezési csoportokat, Batch-et vagy valami egyénit fognak használni. Ha méretezési csoportok vagy Batch használata mellett dönt, ellenőrizze, hogy támogatják-e az alacsony prioritású virtuális gépeket (alacsony prioritású skálázási csoportok , Batch alacsony prioritású dokumentumok). Az alacsony prioritású virtuális gép egy hardveren futó virtuális gép, amelyet a normál ár töredékéért bérelhet. Az alacsonyabb ár azért érhető el, mert az alacsony prioritású virtuális gépek elővehetők, amikor a kapacitás megköveteli. Ha némi rugalmasságot biztosít az időkeretben, az alacsony prioritású virtuális gépek nagyszerű módot kínálnak a modellezési futtatások árának csökkentésére.
Ha több gépen is koordinálnia kell a végrehajtást és az üzembe helyezést, esetleg néhány különböző régióban futó géppel, kihasználhatja a CycleCloud előnyeit. A CycleCloud semmi extraba nem kerül. Szükség esetén összehangolja az adatáthelyezést. Ez magában foglalja a gépek lefoglalását, monitorozását és leállítását. Még az alacsony prioritású gépeket is képes kezelni, így biztosítva a költségek kezelését. A szükséges gépek kombinációjának leírásához érdemes végighaladni. Lehet például, hogy szüksége van egy géposztályra, de bármilyen, 2 vagy több maggal rendelkező verzión jól futtatható. A ciklus képes magokat lefoglalni ezeken a géptípusokon.
Jelentéskészítés az eredményekről
Miután az aktuáriusi csomagok lefutottak és előállították az eredményeket, számos, szabályozóra kész jelentést fog készíteni. Emellett olyan új adatokkal is rendelkezik, amelyeket elemezni szeretne, hogy olyan megállapításokat hozzon létre, amelyeket a szabályozók vagy az ellenőrök nem igényelnek. Érdemes lehet megismernie a legjobb ügyfelek profilját. Az elemzések segítségével megadhatja a marketingnek, hogyan néz ki egy alacsony költségű ügyfél, hogy a marketing és az értékesítés gyorsabban megtalálhassa őket. Hasonlóképpen, az adatok segítségével felderítheti, hogy mely csoportok élvezik a legjobban a biztosítást. Felfedezheti például, hogy azok az emberek, akik kihasználják az éves fizikai előnyöket, korábban felfedezték a korai szakasz egészségügyi problémáit. Ez időt és pénzt takarít meg a biztosítótársaságnak. Ezeket az adatokat felhasználhatja az ügyfélbázis viselkedésének ösztönzésére.
Ehhez számos adatelemzési eszközhöz és néhány vizualizációhoz is hozzá kell férnie. Attól függően, hogy mennyi vizsgálatot szeretne elvégezni, kezdhet egy Adattudomány virtuális géppel, amely az Azure Marketplace-ről építhető ki. Ezek a virtuális gépek Windows és Linux verzióval is rendelkeznek. A telepített Microsoft R Open, a Microsoft Machine Tanulás Server, az Anaconda, a Jupyter és más eszközök készen állnak a használatra. Dobjon be egy kis R-t vagy Pythont az adatok vizualizációjához és az elemzések megosztásához a munkatársaival.
Ha további elemzésre van szüksége, használhatja az Apache adatelemzési eszközeit, például a Sparkot, a Hadoopot és másokat a HDInsighton vagy a Databricksen keresztül. Ezeket a további tudnivalókat akkor használhatja, ha az elemzést rendszeresen el kell végezni, és automatizálni szeretné a munkafolyamatot. Nagy adathalmazok élő elemzéséhez is hasznosak.
Miután talált valami érdekeset, be kell mutatnia az eredményeket. Sok aktuárius először a mintaeredmények felvételével és az Excelbe való csatlakoztatásával hoz létre diagramokat, grafikonokat és egyéb vizualizációkat. Ha olyan dolgot szeretne, amely az adatokba való befúráshoz is jó felületet biztosít, tekintse meg a Power BI-t. A Power BI néhány szép vizualizációt készíthet, megjelenítheti a forrásadatokat, és lehetővé teszi az adatok magyarázatát az olvasónak rendezett, jegyzetekkel ellátott könyvjelzők hozzáadásával.
Adatmegőrzés
A rendszerbe behozott adatok nagy részét meg kell őrizni a jövőbeli auditokhoz. Az adatmegőrzési követelmények általában 7 és 10 év között változnak, de a követelmények eltérőek. A minimális megőrzés a következőket foglalja magában:
- Pillanatkép a modell eredeti bemenetéről. Ide tartoznak az eszközök, a források, a feltételezések, az ESG-k és más bemenetek.
- Pillanatkép a végleges kimenetekről. Ide tartoznak a szabályozó szerveknek bemutatott jelentések létrehozásához használt adatok.
- Egyéb fontos, köztes eredmények. Egy auditor megkérdezi, hogy a modell miért kapott valamilyen eredményt. Meg kell őriznie a bizonyítékokat arról, hogy a modell miért hozott bizonyos döntéseket, vagy adott számokkal állt elő. Számos biztosító úgy dönt, hogy megtartja az eredeti bemenetek végső kimenetének előállításához használt bináris fájlokat. Ezt követően, amikor a kérdés felmerül, újrafuttatják a modellt, hogy friss másolatot kapjanak a köztes eredményekről. Ha a kimenetek egyeznek, akkor a köztes fájloknak is tartalmazniuk kell a szükséges magyarázatokat.
A modell futtatása során az aktuáriusok olyan adatkézbesítési mechanizmusokat használnak, amelyek képesek kezelni a kérelembetöltést a futtatásból. Ha a futtatás befejeződött, és már nincs szükség adatokra, megőrzik az adatok egy részét. Legalább a biztosítónak meg kell őriznie a bemeneteket és a futásidejű konfigurációt a reprodukálhatósági követelményeknek megfelelően. Az adatbázisok megmaradnak az Azure Blob Storage biztonsági mentéseihez, és a kiszolgálók leállnak. A nagy sebességű tárolás adatai a kevésbé költséges Azure Blob Storage-ba is átkerülnek. A Blob Storage-ban kiválaszthatja az egyes blobokhoz használt adatszintet: gyakori, ritka elérésű vagy archív. A gyakori elérésű tárolás jól működik a gyakran használt fájlok esetében. A ritka elérésű tárterület ritkán használt adathozzáféréshez van optimalizálva. Az archivált tárolás a legjobban a naplózható fájlok tárolására szolgál, de az ármegtakarítás késési költséggel jár: az archivált rétegbeli adatok késését órákban mérik. Olvassa el az Azure Blob Storage: Gyakori elérésű, ritka elérésű és archív tárolási szinteket a különböző tárolási szintek teljes körű megértéséhez. Az adatok a létrehozástól a törlésen keresztül az életciklus-kezeléssel kezelhetők. A blobok URI-i statikusak maradnak, de ahol a blob tárolása történik, az idővel olcsóbb lesz. Ez a funkció sok pénzt és fejfájást takarít meg az Azure Storage számos felhasználója számára. Megismerkedhet az Azure Blob Storage életciklusának kezelésével kapcsolatos ins és outs elemekkel. Az a tény, hogy automatikusan törölheti a fájlokat, csodálatos: azt jelenti, hogy nem fog véletlenül kibontani egy auditot egy olyan fájlra hivatkozva, amely hatókörön kívül esik, mert maga a fájl automatikusan eltávolítható.
Megfontolások
Ha a futtatott aktuáriusi rendszer helyszíni rácsos implementációval rendelkezik, akkor a rács implementációja valószínűleg az Azure-ban is futni fog. Egyes gyártók speciális Azure-implementációkkal rendelkeznek, amelyek rugalmas skálázáson futnak. Az Azure-ba való áttérés részeként helyezze át a belső eszközkészletet is. Az aktuáriusok mindenhol azt tették, hogy adatelemzési készségeik jól működnek a laptopjukon vagy egy nagy környezetben. Keressen olyan dolgokat, amelyeket a csapat már csinál: lehet, hogy van valami, amely mély tanulást használ, de órákig vagy napokig tart, amíg egy GPU-n fut. Próbálja meg ugyanazt a számítási feladatot futtatni egy négy csúcskategóriás GPU-val rendelkező gépen, és nézze meg a futtatási időket; az esélyek jó, akkor jelentős gyorsításokat fog látni a már meglévő dolgokhoz.
A dolgok javítása érdekében győződjön meg arról, hogy a modellezési adatok betáplálásához adatszinkronizálást is készít. A modellfuttatás csak akkor indulhat el, ha az adatok készen állnak. Ez némi erőfeszítést igényelhet, hogy csak olyan adatokat küldjön, amelyek megváltoztak. A tényleges megközelítés az adatmérettől függ. Néhány MB frissítése talán nem nagy dolog, de a gigabájtos feltöltések számának csökkentése sokat felgyorsítja a dolgokat.
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerző:
- Scott Seely | Szoftvertervező
Következő lépések
- R-fejlesztők: Párhuzamos R-szimuláció futtatása az Azure Batch használatával
- ETL a Databricks használatával: Adatok kinyerása, átalakítása és betöltése az Azure Databricks használatával
- ETL a HDInsighttal: Adatok kinyerése, átalakítása és betöltése az Apache Hive használatával az Azure HDInsighton
- Adattudomány virtuális gép útmutatója (Linux)
- Adattudomány virtuális gép útmutatója (Windows)