Gépi tanulási modellek üzembe helyezése az Azure-ban
ÉRVÉNYES: Azure CLI ml-bővítmény v1Python SDK azureml v1
Azure CLI ml-bővítmény v1Python SDK azureml v1
Megtudhatja, hogyan helyezheti üzembe gépi tanulási vagy mélytanulási modelljét webszolgáltatásként az Azure-felhőben.
Megjegyzés:
Az Azure Machine Tanulás Végpontok (v2) továbbfejlesztett, egyszerűbb üzembe helyezést biztosítanak. A végpontok támogatják a valós idejű és a kötegelt következtetési forgatókönyveket is. A végpontok egységes felületet biztosítanak a modelltelepítések számítási típusok közötti meghívásához és kezeléséhez. Tekintse meg az Azure Machine Tanulás végpontjait.
Modell üzembe helyezésének munkafolyamata
A munkafolyamat a modell telepítésének helyétől függetlenül hasonló:
- A modell regisztrálása.
- Bejegyzésszkript előkészítése.
- Következtetéskonfiguráció előkészítése.
- Helyezze üzembe a modellt helyileg, hogy minden működjön.
- Válasszon ki egy számítási célt.
- A modell üzembe helyezése a felhőben.
- Tesztelje az eredményként kapott webszolgáltatást.
A gépi tanulási üzembe helyezési munkafolyamattal kapcsolatos fogalmakkal kapcsolatos további információkért lásd: Modellek kezelése, üzembe helyezése és monitorozása az Azure Machine Tanulás használatával.
Előfeltételek
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
Fontos
A cikkben szereplő Azure CLI-parancsok némelyike az azure-cli-mlAzure Machine Tanulás vagy v1 bővítményét használja. A v1-bővítmény támogatása 2025. szeptember 30-án megszűnik. Addig a dátumig telepítheti és használhatja a v1-bővítményt.
Javasoljuk, hogy 2025. szeptember 30-a előtt váltsa át a ml(vagy v2) bővítményt. További információ a v2-es bővítményről: Azure ML CLI-bővítmény és Python SDK v2.
- Egy Azure Machine Learning-munkaterület. További információ: Munkaterület-erőforrások létrehozása.
- Egy modell. A cikkben szereplő példák egy előre betanított modellt használnak.
- Olyan gép, amely képes futtatni a Dockert, például egy számítási példányt.
Csatlakozás a munkaterülethez
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
Azoknak a munkaterületeknek a megtekintéséhez, amelyekhez hozzáféréssel rendelkezik, használja a következő parancsokat:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Regisztrálja a modellt
Az üzembe helyezett gépi tanulási szolgáltatások tipikus helyzete, hogy a következő összetevőkre van szüksége:
- Az üzembe helyezni kívánt modellt képviselő erőforrások (például egy pytorch-modellfájl).
- A modellt egy adott bemeneten végrehajtó szolgáltatásban futtatandó kód.
Az Azure Machine Learning lehetővé teszi az üzembe helyezés két külön összetevőre történő szétválasztását, így megtarthatja ugyanazt a kódot, de csak a modellt kell frissítenie. A modell kódtól való elkülönített feltöltésének mechanizmusát úgy definiáljuk, hogy „a modell regisztrálása”.
Amikor regisztrál egy modellt, mi feltöltjük azt a felhőbe (a munkaterület alapértelmezett tárfiókjába), majd csatoljuk ugyanahhoz a számítási célhoz, amelyben a webszolgáltatás is fut.
Az alábbi példák bemutatják, hogyan regisztrálhat egy modellt.
Fontos
Kizárólag az Ön által létrehozott vagy megbízható forrásból beszerzett modelleket használjon. A szerializált modelleket kódként kezelje, mert számos népszerű formátumban észleltek biztonsági réseket. A modelleket emellett kártevő szándékkal is betaníthatták, hogy torz vagy pontatlan kimenetet biztosítsanak.
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
A következő parancsok letöltenek egy modellt, majd regisztrálják azt az Azure Machine Tanulás-munkaterületen:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Állítsa be -p a regisztrálni kívánt mappa vagy fájl elérési útját.
További információkért az ml model registerlásd a referenciadokumentációt.
Modell regisztrálása Azure Machine-Tanulás betanítási feladatból
Ha olyan modellt kell regisztrálnia, amelyet korábban egy Azure Machine Tanulás betanítási feladaton keresztül hoztak létre, megadhatja a kísérlet, a futtatás és a modell elérési útját:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
A --asset-path paraméter a modell felhőbeli helyére hivatkozik. Ebben a példában egyetlen fájl elérési útját használjuk. Ha több fájlt szeretne felvenni a modellregisztrációba, állítsa be --asset-path a fájlokat tartalmazó mappa elérési útját.
További információkért az ml model registerlásd a referenciadokumentációt.
Megjegyzés:
A modellt helyi fájlból is regisztrálhatja a Munkaterület felhasználói felület portálján keresztül.
Jelenleg két lehetőség van helyi modellfájl feltöltésére a felhasználói felületen:
- Helyi fájlokból, amelyek regisztrálnak egy v2-modellt.
- Helyi fájlokból (keretrendszer alapján), amelyek regisztrálnak egy v1-modellt.
Vegye figyelembe, hogy az SDKv1/CLIv1 használatával csak a Helyi fájlokból (keretrendszeren alapuló) bejáraton keresztül regisztrált modellek (v1-modellek) helyezhetők üzembe webszolgáltatásként.
Próbabejegyzési szkript definiálása
A bejegyzés parancsfájlja fogadja az üzembe helyezett webszolgáltatásnak küldött adatokat, majd továbbítja azokat a modellnek. Ezután visszaadja a modell válaszát az ügyfélnek. A szkript a modellre jellemző. A belépési szkriptnek ismernie kell a modell által várt és visszaadott adatokat.
A beviteli szkriptben a következő két dolgot kell elvégeznie:
- A modell betöltése (a ) függvény
init()használatával - A modell futtatása bemeneti adatokon (egy ) nevű
run()függvény használatával
A kezdeti üzembe helyezéshez használjon egy álbejegyzési szkriptet, amely kinyomtatja a kapott adatokat.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Mentse a fájlt echo_score.py egy nevű source_dirkönyvtárba. Ez a próbaszkript visszaadja a neki küldött adatokat, így nem használja a modellt. Hasznos azonban tesztelni, hogy a pontozó szkript fut-e.
Következtetéskonfiguráció definiálása
A következtetési konfiguráció ismerteti a Docker-tárolót és a webszolgáltatás inicializálása során használandó fájlokat. A webszolgáltatás üzembe helyezésekor a forráskönyvtárban lévő összes fájl, beleértve az alkönyvtárakat is, tömörítve lesznek, és fel lesznek töltve a felhőbe.
Az alábbi következtetési konfiguráció azt határozza meg, hogy a gépi tanulás központi telepítése a könyvtárban lévő fájlt echo_score.py fogja használni a ./source_dir bejövő kérések feldolgozásához, és hogy a Docker-rendszerképet a környezetben megadott project_environment Python-csomagokkal fogja használni.
A projektkörnyezet létrehozásakor bármely Azure Machine-Tanulás következtetési környezet használható alap Docker-rendszerképként. Felülre telepítjük a szükséges függőségeket, és az eredményül kapott Docker-lemezképet a munkaterülethez társított adattárban tároljuk.
Megjegyzés:
Az Azure Machine Learning következtetési forráskönyvtárának feltöltése nem tartja tiszteletben a .gitignore vagy a .amlignore fájlt
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
A minimális következtetési konfiguráció a következőképpen írható:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Mentse a fájlt a névvel dummyinferenceconfig.json.
Ebből a cikkből részletesebben is tájékozódhat a következtetési konfigurációkról.
Üzembehelyezési konfiguráció definiálása
Az üzembe helyezési konfiguráció megadja a webszolgáltatás futtatásához szükséges memória- és magmennyiséget. Emellett a mögöttes webszolgáltatás konfigurációs adatait is tartalmazza. Az üzembehelyezési konfiguráció segítségével például megadhatja, hogy a szolgáltatásnak 2 gigabájtnyi memóriára, 2 processzormagra, 1 GPU-magra van szüksége, és hogy engedélyezni szeretné az automatikus skálázást.
Az üzembe helyezési konfigurációhoz rendelkezésre álló lehetőségek a választott számítási céltól függően eltérőek. Egy helyi üzemelő példányban csak azt adhatja meg, hogy a webszolgáltatás melyik porton lesz kiszolgálva.
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
A dokumentum bejegyzései megfeleltetik a deploymentconfig.json LocalWebservice.deploy_configuration paramétereit. Az alábbi táblázat a JSON-dokumentumban szereplő entitások és a metódus paraméterei közötti leképezést ismerteti:
| JSON-entitás | Metódusparaméter | Leírás |
|---|---|---|
computeType |
NA | A számítási cél. Helyi célok esetén az értéknek a következőnek kell lennie local: . |
port |
port |
Az a helyi port, amelyen elérhetővé szeretné tenni a szolgáltatás HTTP-végpontját. |
Ez a JSON egy példa üzembe helyezési konfiguráció a parancssori felülettel való használatra:
{
"computeType": "local",
"port": 32267
}
Mentse ezt a JSON-t nevű fájlként deploymentconfig.json.
További információkért tekintse meg az üzembe helyezési sémát.
A gépi tanulási modell üzembe helyezése
Most már készen áll a modell üzembe helyezésére.
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
Cserélje le bidaf_onnx:1 a modell nevét és verziószámát.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Hívás a modellbe
Ellenőrizzük, hogy az echo-modell sikeresen üzembe lett-e helyezve. Meg kell tudnia csinálni egy egyszerű élőségi kérelmet, valamint egy pontozási kérelmet:
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Bejegyzésszkript definiálása
Most itt az ideje, hogy ténylegesen betöltse a modellt. Először módosítsa a bejegyzésszkriptet:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Mentse a fájlt a score.py fájlon belülre source_dir.
Figyelje meg a környezeti változó használatát a AZUREML_MODEL_DIR regisztrált modell megkereséséhez. Most, hogy hozzáadott néhány pipcsomagot.
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
A fájl mentése másként inferenceconfig.json
Újra üzembe helyezés és a szolgáltatás meghívása
A szolgáltatás ismételt üzembe helyezése:
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
Cserélje le bidaf_onnx:1 a modell nevét és verziószámát.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Ezután győződjön meg arról, hogy elküldhet egy post requestt a szolgáltatásnak:
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Számítási cél kiválasztása
A modell üzemeltetéséhez használt számítási cél hatással lesz az üzembe helyezett végpont költségeire és rendelkezésre állására. Ezzel a táblával válasszon ki egy megfelelő számítási célt.
| Számítási cél | Used for | GPU-támogatás | Leírás |
|---|---|---|---|
| Helyi webszolgáltatás | Tesztelés/hibakeresés | Korlátozott teszteléshez és hibaelhárításhoz használható. A hardveres gyorsítás a kódtárak helyi rendszerben való használatától függ. | |
| Azure Machine Tanulás Kubernetes | Real-time inference | Igen | Következtetési számítási feladatok futtatása a felhőben. |
| Azure Container Instances | Valós idejű következtetés Csak fejlesztési/tesztelési célokra ajánlott. |
A 48 GB-nál kevesebb RAM-ot igénylő, alacsony skálázású CPU-alapú számítási feladatokhoz használható. Nincs szükség fürtök kezelésére. Csak 1 GB-nál kisebb méretű modellekhez alkalmas. A tervező támogatja. |
Megjegyzés:
Fürt termékváltozatának kiválasztásakor először vertikális felskálázást, majd vertikális felskálázást kell végezni. Kezdje egy olyan géppel, amely a modell által igényelt RAM 150%-ával rendelkezik, profilozza az eredményt, és keressen egy olyan gépet, amely rendelkezik a szükséges teljesítménnyel. Ha ezt megtanulta, növelje a gépek számát, hogy megfeleljen az egyidejű következtetés szükségletének.
Megjegyzés:
Az Azure Machine Tanulás Végpontok (v2) továbbfejlesztett, egyszerűbb üzembe helyezést biztosítanak. A végpontok támogatják a valós idejű és a kötegelt következtetési forgatókönyveket is. A végpontok egységes felületet biztosítanak a modelltelepítések számítási típusok közötti meghívásához és kezeléséhez. Tekintse meg az Azure Machine Tanulás végpontjait.
Üzembe helyezés a felhőben
Miután megerősítette, hogy a szolgáltatás helyileg működik, és kiválasztott egy távoli számítási célt, készen áll a felhőben való üzembe helyezésre.
Módosítsa az üzembe helyezési konfigurációt úgy, hogy megfeleljen a választott számítási célnak, ebben az esetben az Azure Container Instancesnek:
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
Az üzembe helyezési konfigurációhoz rendelkezésre álló lehetőségek a választott számítási céltól függően eltérőek.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Mentse a fájlt a következőképpen re-deploymentconfig.json: .
További információkért tekintse meg ezt a hivatkozást.
A szolgáltatás ismételt üzembe helyezése:
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
Cserélje le bidaf_onnx:1 a modell nevét és verziószámát.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
A szolgáltatásnaplók megtekintéséhez használja a következő parancsot:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Távoli webszolgáltatás meghívása
Távoli üzembe helyezés esetén lehetséges, hogy engedélyezve van a kulcshitelesítés. Az alábbi példa bemutatja, hogyan szerezheti be a szolgáltatáskulcsot a Pythonnal egy következtetési kérés létrehozásához.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Tekintse meg az ügyfélalkalmazásokkal kapcsolatos cikket, amely webszolgáltatásokat használ fel más nyelvű példákat használó ügyfelek számára.
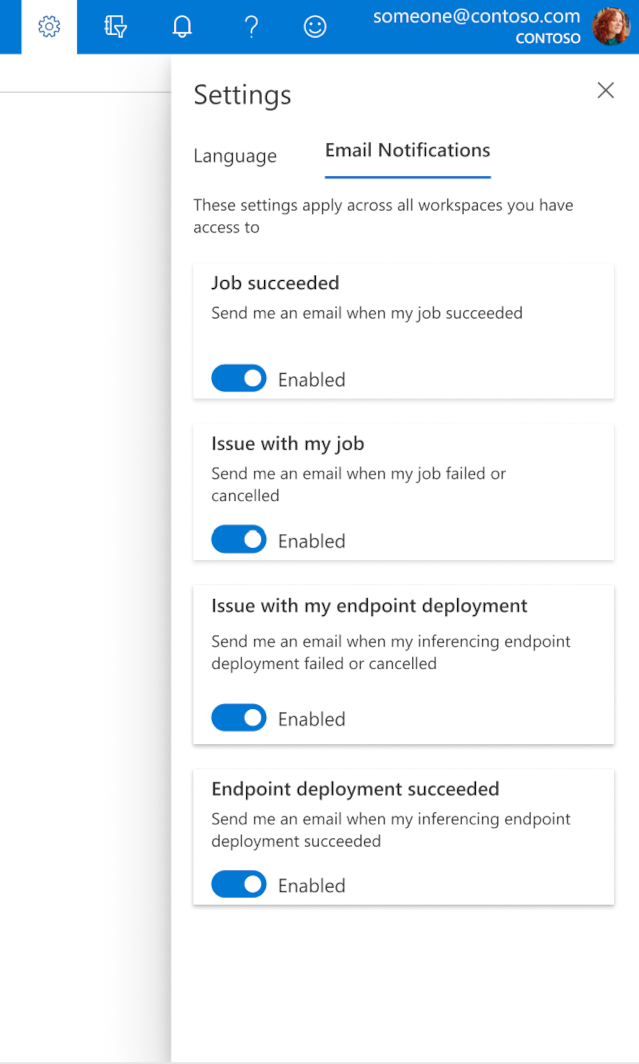
E-mailek konfigurálása a stúdióban
Ha el szeretné kezdeni az e-mailek fogadását, ha a feladat, az online végpont vagy a kötegvégpont befejeződött, vagy ha probléma merült fel (sikertelen, megszakítva), kövesse az alábbi lépéseket:
- Az Azure ML Studióban a fogaskerék ikon kiválasztásával nyissa meg a beállításokat.
- Válassza az E-mail értesítések lapot.
- Váltás az e-mail-értesítések engedélyezésére vagy letiltására egy adott eseményhez.
A szolgáltatás állapotának ismertetése
A modell üzembe helyezése során előfordulhat, hogy a szolgáltatás állapota megváltozik, amíg az teljesen üzembe van helyezve.
Az alábbi táblázat a különböző szolgáltatásállapotokat ismerteti:
| Webszolgáltatás állapota | Leírás | Végleges állapot? |
|---|---|---|
| Átmenet | A szolgáltatás üzembe helyezése folyamatban van. | Nem |
| Nem kifogástalan | A szolgáltatás üzembe lett helyezve, de jelenleg nem érhető el. | Nem |
| Nem ütemezhető | A szolgáltatás jelenleg nem helyezhető üzembe erőforrások hiánya miatt. | Nem |
| Failed | A szolgáltatás üzembe helyezése hiba vagy összeomlás miatt nem sikerült. | Igen |
| Kifogástalan | A szolgáltatás kifogástalan állapotban van, és a végpont elérhető. | Igen |
Tipp.
Üzembe helyezéskor a Számítási célokhoz készült Docker-rendszerképek az Azure Container Registryből (ACR) jönnek létre és töltődnek be. Alapértelmezés szerint az Azure Machine Tanulás létrehoz egy ACR-t, amely az alapszintű szolgáltatási szintet használja. Ha a munkaterület ACR-ét standard vagy prémium szintre módosítja, az csökkentheti a rendszerképek számítási célokra történő létrehozásához és üzembe helyezéséhez szükséges időt. További információ: az Azure Container Registry szolgáltatásszintjei.
Megjegyzés:
Ha az Azure Kubernetes Service-ben (AKS-ben) helyez üzembe modellt, javasoljuk, hogy engedélyezze az Azure Monitort a fürt esetében. Ez segít értelmezni a fürt általános állapotát és erőforrás-használatát. A következő forrásanyagokat is hasznosnak találhatja:
- Az AKS-fürtöt befolyásoló erőforrásállapot-események keresése
- Azure Kubernetes Service – Diagnosztika
Ha a modellt nem megfelelő állapotú vagy túlterhelt fürtön próbál üzembe helyezni, várhatóan problémákat fog tapasztalni. Ha segítségre van szüksége az AKS-fürt problémáinak elhárításához, forduljon az AKS ügyfélszolgálatához.
Erőforrások törlése
A KÖVETKEZŐre vonatkozik: Azure CLI ml-bővítmény 1-es verzió
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Üzembe helyezett webszolgáltatás törléséhez használja a következőt az ml service delete <name of webservice>: .
Regisztrált modell munkaterületről való törléséhez használja a az ml model delete <model id>
További információ a webszolgáltatás törléséről és a modell törléséről.
További lépések
- Sikertelen üzembe helyezés hibaelhárítása
- Webszolgáltatás frissítése
- Egykattintásos üzembe helyezés automatizált gépi tanuláshoz az Azure Machine Tanulás Studióban
- TLS használata webszolgáltatás védelméhez az Azure Machine Learning szolgáltatás segítségével
- Azure Machine-Tanulás-modellek monitorozása az Alkalmazás Elemzések
- Eseményriasztások és eseményindítók létrehozása modelltelepítésekhez