Adatok átalakítása az Azure Machine Tanulás tervezőjében
Ebben a cikkben megtudhatja, hogyan alakíthatja át és mentheti az adathalmazokat az Azure Machine Tanulás tervezőjében, hogy előkészítse a saját adatait a gépi tanuláshoz.
Az Adult Census Income Binary Classification mintaadatkészletet két adathalmaz előkészítéséhez fogja használni: egy olyan adatkészletet, amely csak a Egyesült Államok felnőttkori összeírási adatait tartalmazza, valamint egy másik adatkészletet, amely nem USA-beli felnőttektől származó összeírási adatokat tartalmaz.
Ebből a cikkből megtudhatja, hogyan:
- Átalakíthat egy adathalmazt, hogy felkészítse a betanításra.
- Exportálja az eredményként kapott adathalmazokat egy adattárba.
- Tekintse meg az eredményeket.
Ez a útmutató előfeltétele a tervezőmodellek újratanítását ismertető cikknek. Ebben a cikkben megtudhatja, hogyan használhatja az átalakított adatkészleteket több modell betanítása folyamatparaméterekkel.
Fontos
Ha nem figyeli meg a dokumentumban említett grafikus elemeket, például a stúdióban vagy a tervezőben lévő gombokat, előfordulhat, hogy nem rendelkezik a megfelelő szintű engedélyekkel a munkaterülethez. Forduljon az Azure-előfizetés rendszergazdájához, és ellenőrizze, hogy a megfelelő hozzáférési szintet kapta-e. További információ: Felhasználók és szerepkörök kezelése.
Adathalmaz átalakítása
Ebben a szakaszban megtudhatja, hogyan importálhatja a mintaadatkészletet, és hogyan oszthatja fel az adatokat usa-beli és nem USA-beli adatkészletekre. A saját adatok tervezőbe való importálásával kapcsolatos további információkért tekintse meg az adatok importálásának módját.
Adatok importálása
Az alábbi lépésekkel importálhatja a mintaadatkészletet:
Jelentkezzen be az Azure Machine Tanulás Studióba, és válassza ki a használni kívánt munkaterületet
Lépjen a tervezőhöz. Új folyamat létrehozásához válassza az Új folyamat létrehozása klasszikus előre összeállított összetevőkkel lehetőséget
A folyamatvászon bal oldalán, az Összetevő lapon bontsa ki a Minta adatcsomópontot
Húzza a Felnőtt Census Income Bináris besorolási adatkészletet a vászonra
Válassza ki a jobb gombbal a Felnőtt Census Income adathalmaz összetevőt, és válassza az Előzetes adatok lehetőséget
Az adathalmaz megismeréséhez használja az adatelőnézet ablakát. Jegyezze fel a "natív ország" oszlop értékeit
Az adatok felosztása
Ebben a szakaszban az Adatok felosztása összetevő használatával azonosíthatja és feloszthatja azokat a sorokat, amelyek a "natív ország" oszlopban tartalmazzák az "Egyesült Államok" értéket.
A vászon bal oldalán, az összetevő lapon bontsa ki az Adatátalakítás szakaszt, és keresse meg az Adatok felosztása összetevőt
Húzza az Adatok felosztása összetevőt a vászonra, és húzza az összetevőt az adathalmaz-összetevő alá
Csatlakozás az adathalmaz-összetevőt a Adatösszetevő felosztása
Válassza ki az Adatok felosztása összetevőt az Adatok felosztása panel megnyitásához
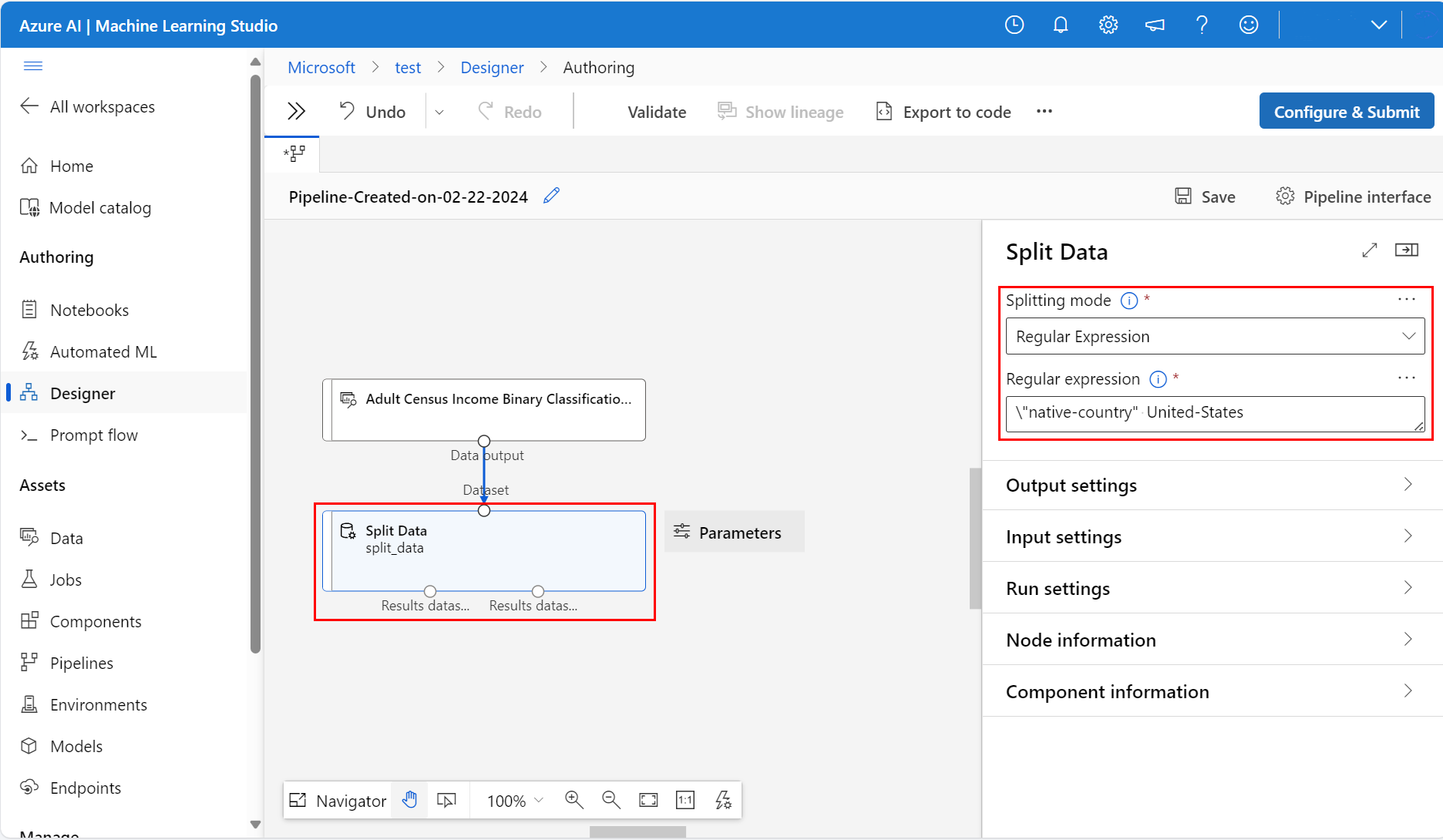
A vásznon a Paraméterek ikontól jobbra állítsa a felosztási módot Normál kifejezésre
Adja meg a reguláris kifejezést:
\"native-country" United-StatesA Reguláris kifejezésmód egy érték egyetlen oszlopát teszteli. A split data összetevővel kapcsolatos további információkért látogasson el a kapcsolódó algoritmusösszetevő referenciaoldalára
A folyamatnak a következő képernyőképhez kell hasonlítania:
Az adathalmazok mentése
Most, hogy beállította a folyamatot az adatok felosztására, meg kell adnia az adathalmazok megőrzésének helyét. Ebben a példában az Adatok exportálása összetevővel mentheti az adathalmazt egy adattárba. Az adattárakról további információt Csatlakozás az Azure Storage-szolgáltatásokban talál.
Az összetevőpalettán a vászontól balra bontsa ki az Adatbemenet és - kimenet szakaszt, és keresse meg az Adatok exportálása összetevőt
Két Adatexportálási összetevő húzása az Adatok felosztása összetevő alá
Csatlakozás a Adatösszetevő felosztása másik adatexportálási összetevőre
A folyamatnak a következőhöz kell hasonlítania:
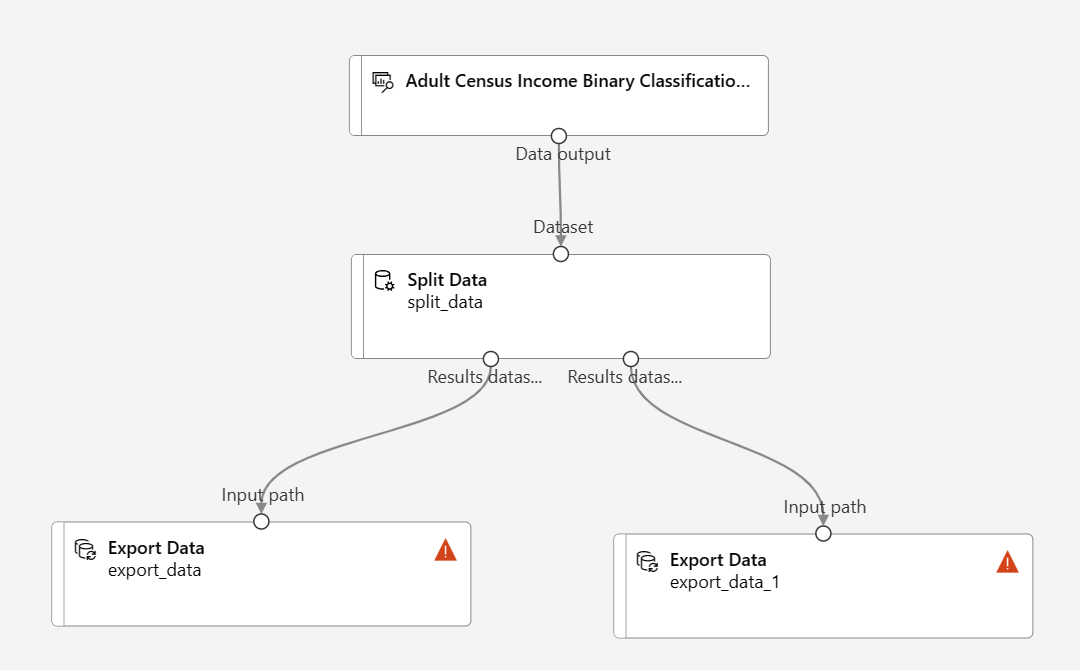
Válassza ki az Adatok exportálása összetevőt, amely az Adatok felosztása összetevő bal oldali portjához csatlakozik, és nyissa meg az Adatok exportálása konfigurációs panelt
Az Adatok felosztása összetevő esetében fontos a kimeneti port sorrendje. Az első kimeneti port tartalmazza azokat a sorokat, ahol a reguláris kifejezés igaz. Ebben az esetben az első port az USA-alapú jövedelmek sorait, a második port pedig az USA-ból származó jövedelmek sorait tartalmazza
A vászontól jobbra található Összetevő részletei panelen adja meg a következő beállításokat:
Adattár típusa: Azure Blob Storage
Adattár: Válasszon ki egy meglévő adattárat, vagy az "Új adattár" lehetőséget választva hozzon létre egy újat
Elérési út:
/data/us-incomeFájlformátum: csv
Feljegyzés
Ez a cikk feltételezi, hogy rendelkezik hozzáféréssel az aktuális Azure Machine Tanulás-munkaterületen regisztrált adattárhoz. Az adattár beállítási utasításaiért látogasson el Csatlakozás az Azure Storage-szolgáltatásokhoz
Ha még nem rendelkezik ilyen adattárkal, létrehozhat egy adattárat. Ez a cikk például a munkaterülethez társított alapértelmezett Blob Storage-fiókba menti az adathalmazokat. Az adathalmazokat a
azuremltárolóba menti egy új, névvel ellátott mappábadataVálassza ki az Adatok exportálása összetevőt, amely az Adatok felosztása összetevő jobb oldali portjához csatlakozik, és nyissa meg az Adatok exportálása konfigurációs panelt
Az összetevő részletei panelen a vászon jobb oldalán adja meg a következő beállításokat:
Adattár típusa: Azure Blob Storage
Adattár: Válassza ki a korábbi adattárat
Elérési út:
/data/non-us-incomeFájlformátum: csv
Ellenőrizze, hogy az Adatok exportálása összetevő a felosztási adatok bal portjához csatlakozik-e az elérési úttal
/data/us-incomeEllenőrizze, hogy a megfelelő porthoz csatlakoztatott Adatexportálási összetevő rendelkezik-e elérési úttal
/data/non-us-incomeA folyamatnak és a beállításoknak a következőképpen kell kinéznie:

Feladat küldése
Most, hogy beállította a folyamatot az adatok felosztására és exportálására, küldjön be egy folyamatfeladatot.
Válassza a Konfigurálás > Küldés lehetőséget a vászon tetején
Kísérlet létrehozásához válassza az Új létrehozása lehetőséget a Folyamat beállítása feladat alapszintű paneljén
A kísérletek logikailag csoportosítják a kapcsolódó folyamatfeladatokat. Ha ezt a folyamatot a jövőben futtatja, ugyanazt a kísérletet kell használnia naplózási és nyomkövetési célokra
Adjon meg egy leíró kísérletnevet – például "split-census-data"
Válassza a Véleményezés + Küldés lehetőséget, majd a Küldés lehetőséget
Eredmények megtekintése
A folyamat futtatása után navigálhat az Azure Portal blobtárolójához az eredmények megtekintéséhez. Az Adatok felosztása összetevő köztes eredményeit is megtekintheti annak ellenőrzéséhez, hogy az adatok megfelelően oszlanak-e el.
Válassza ki az Adatok felosztása összetevőt
A vászontól jobbra található Összetevő részletei panelen válassza a Kimenetek + naplók lapot
Válassza az Adatkimenetek megjelenítése legördülő menüt
A Vizualizáció ikon
 kiválasztása az Eredmények adathalmaz1 mellett
kiválasztása az Eredmények adathalmaz1 mellettEllenőrizze, hogy a "native-country" oszlop csak az "Egyesült Államok" értéket tartalmazza-e
A Vizualizáció ikon
kiválasztása az Eredmények adathalmaz2 mellettEllenőrizze, hogy a "native-country" oszlop nem tartalmazza-e az "Egyesült Államok" értéket
Az erőforrások eltávolítása
Ha folytatni szeretné az Újratanítási modellek második részét az Azure Machine Tanulás tervezői útmutatóval, hagyja ki ezt a szakaszt.
Fontos
A létrehozott erőforrásokat más Azure Machine-Tanulás oktatóanyagok és útmutató cikkek előfeltételeként használhatja.
Minden törlése
Ha nem tervez semmit, amit létrehozott, törölje a teljes erőforráscsoportot, hogy ne járjon költségekkel.
Az Azure Portalon válassza ki az erőforráscsoportokat az ablak bal oldalán.
A listában válassza ki a létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
Az erőforráscsoport törlése a tervezőben létrehozott összes erőforrást is törli.
Egyes objektumok törlése
Abban a tervezőben, ahol létrehozta a kísérletet, törölje az egyes objektumokat a kijelöléssel, majd a Törlés gombra kattintva.
Az itt létrehozott számítási cél automatikusan nulla csomópontra skálázódik automatikusan, ha nincs használatban. Ez a művelet a díjak minimalizálása érdekében történik. Ha törölni szeretné a számítási célt, hajtsa végre az alábbi lépéseket:
Az adathalmazok regisztrációját a munkaterületről az egyes adathalmazok kiválasztásával és a Regisztráció törlése lehetőség kiválasztásával szüntetheti meg.
Adathalmaz törléséhez lépjen a tárfiókba az Azure Portal vagy az Azure Storage Explorer használatával, és törölje manuálisan ezeket az eszközöket.
Következő lépések
Ebben a cikkben megtanulta, hogyan alakíthat át egy adathalmazt, és mentheti azt egy regisztrált adattárba.
Folytassa ennek az útmutatósorozatnak a következő részével az Azure Machine Tanulás designerrel végzett újratanítási modellekkel, hogy az átalakított adathalmazokat és folyamatparamétereket használja a gépi tanulási modellek betanításához.