Az Azure Machine Learning és a Fairlearn nyílt forráskódú csomag használata az ML-modellek méltányosságának felméréséhez (előzetes verzió)
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Ebből az útmutatóból megtudhatja, hogyan végezheti el a következő feladatokat a Fairlearn nyílt forráskódú Python-csomag és az Azure Machine Learning használatával:
- Mérje fel a modell-előrejelzések méltányosságát. Ha többet szeretne megtudni a gépi tanulás méltányosságáról, tekintse meg a méltányosságot a gépi tanulásban című cikket.
- Töltse fel, sorolja fel és töltse le a méltányossági felmérési megállapításokat Azure Machine Learning stúdió.
- A modell(ek) méltányossági megállapításaival való interakcióhoz tekintse meg a Azure Machine Learning stúdió méltányossági felmérési irányítópultját.
Megjegyzés
A méltányossági értékelés nem pusztán technikai gyakorlat. Ez a csomag segíthet felmérni a gépi tanulási modellek méltányosságát, de csak Ön konfigurálhat és hozhat döntéseket a modell teljesítményével kapcsolatban. Bár ez a csomag segít azonosítani a mennyiségi metrikákat a méltányosság értékeléséhez, a gépi tanulási modellek fejlesztőinek minőségi elemzést is végre kell hajtaniuk a saját modelljeik méltányosságának értékeléséhez.
Fontos
Ez a funkció jelenleg nyilvános előzetes verzióban érhető el. Ez az előzetes verzió szolgáltatói szerződés nélkül érhető el, éles számítási feladatokhoz nem ajánljuk. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik.
További információ: Kiegészítő használati feltételek a Microsoft Azure előzetes verziójú termékeihez.
Azure Machine Learning Fairness SDK
Az Azure Machine Learning Fairness SDK integrálja azureml-contrib-fairnessa Fairlearn nevű nyílt forráskódú Python-csomagot az Azure Machine Learningben. Ha többet szeretne megtudni a Fairlearn Azure Machine Learningen belüli integrációjáról, tekintse meg ezeket a mintajegyzetfüzeteket. A Fairlearnről további információt a példaútmutatóban és a mintajegyzetfüzetekben talál.
A és fairlearn a csomag telepítéséhez használja az azureml-contrib-fairness alábbi parancsokat:
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
A Fairlearn későbbi verzióinak az alábbi példakódban is működnie kell.
Méltányossági elemzések feltöltése egyetlen modellhez
Az alábbi példa bemutatja, hogyan használhatja a méltányossági csomagot. Modellbeli méltányossági megállapításokat töltünk fel az Azure Machine Learningbe, és megtekintjük a méltányossági felmérés irányítópultját Azure Machine Learning stúdió.
Mintamodell betanítása Jupyter Notebook.
Az adatkészlethez a jól ismert felnőtt összeírási adatkészletet használjuk, amelyet az OpenML-ből kérünk le. Úgy teszünk, mintha hiteldöntési problémánk lenne a címkével, amely azt jelzi, hogy egy magánszemély visszafizetett-e egy korábbi kölcsönt. Betanítunk egy modellt annak előrejelzésére, hogy a korábban még nem látott személyek visszafizetik-e a hitelt. Ilyen modell használható a hitelekkel kapcsolatos döntések meghozatalához.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Jelentkezzen be az Azure Machine Learningbe, és regisztrálja a modellt.
A méltányosság irányítópultja integrálható a regisztrált vagy nem regisztrált modellekkel. Regisztrálja a modellt az Azure Machine Learningben az alábbi lépésekkel:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)A méltányossági metrikák előzetes kiegészítése.
Hozzon létre egy irányítópult-szótárt a Fairlearn csomagjával
metrics. A_create_group_metric_setmetódus argumentumai az Irányítópult konstruktorhoz hasonlóak, azzal a kivételrel, hogy a bizalmas funkciók szótárként lesznek átadva (a nevek elérhetőségének biztosítása érdekében). A metódus meghívásakor meg kell adnunk az előrejelzés típusát (ebben az esetben bináris besorolás).# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Töltse fel az előre összeállított méltányossági metrikákat.
Most importálja
azureml.contrib.fairnessa csomagot a feltöltés végrehajtásához:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idHozzon létre egy kísérletet, majd egy Futtatás parancsot, és töltse fel az irányítópultot a következőre:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Ellenőrizze a méltányossági irányítópultot a Azure Machine Learning stúdió
Ha elvégezte az előző lépéseket (a létrehozott méltányossági megállapítások feltöltése az Azure Machine Learningbe), megtekintheti a méltányossági irányítópultot Azure Machine Learning stúdió. Ez az irányítópult a Fairlearnben található vizualizációs irányítópult, amely lehetővé teszi, hogy elemezze a bizalmas funkció alcsoportjai (például a férfi és a nő) közötti eltéréseket. Az alábbi útvonalak egyikét követve érheti el a vizualizációs irányítópultot Azure Machine Learning stúdió:
- Feladatok panel (előzetes verzió)
- A bal oldali panelen válassza a Feladatok lehetőséget az Azure Machine Learningben futtatott kísérletek listájának megtekintéséhez.
- Válasszon ki egy adott kísérletet a kísérlet összes futtatásának megtekintéséhez.
- Jelöljön ki egy futtatást, majd a Méltányosság lapot a magyarázó vizualizáció irányítópultjához.
- Miután leszállt a Méltányosság lapon, kattintson a jobb oldali menü méltányossági azonosítójára .
- Az irányítópult konfigurálásához válassza ki a fontos bizalmas attribútumot, teljesítménymetrikát és méltányossági metrikát, hogy az a méltányosság-felmérés oldalára omljon.
- Váltson át diagramtípust egyikről a másikra a foglalási ártalmak és a szolgáltatásminőségi ártalmak megfigyeléséhez.
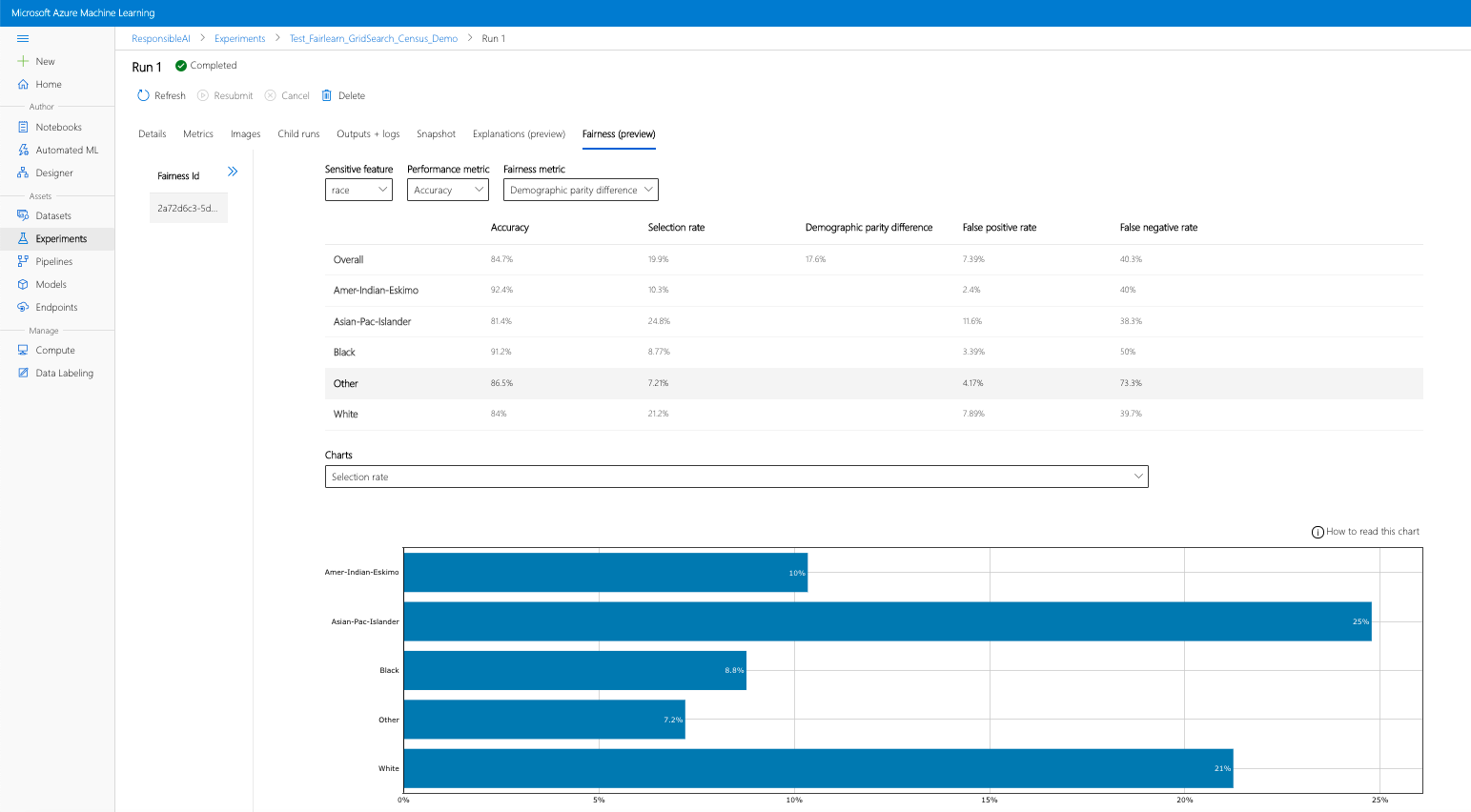
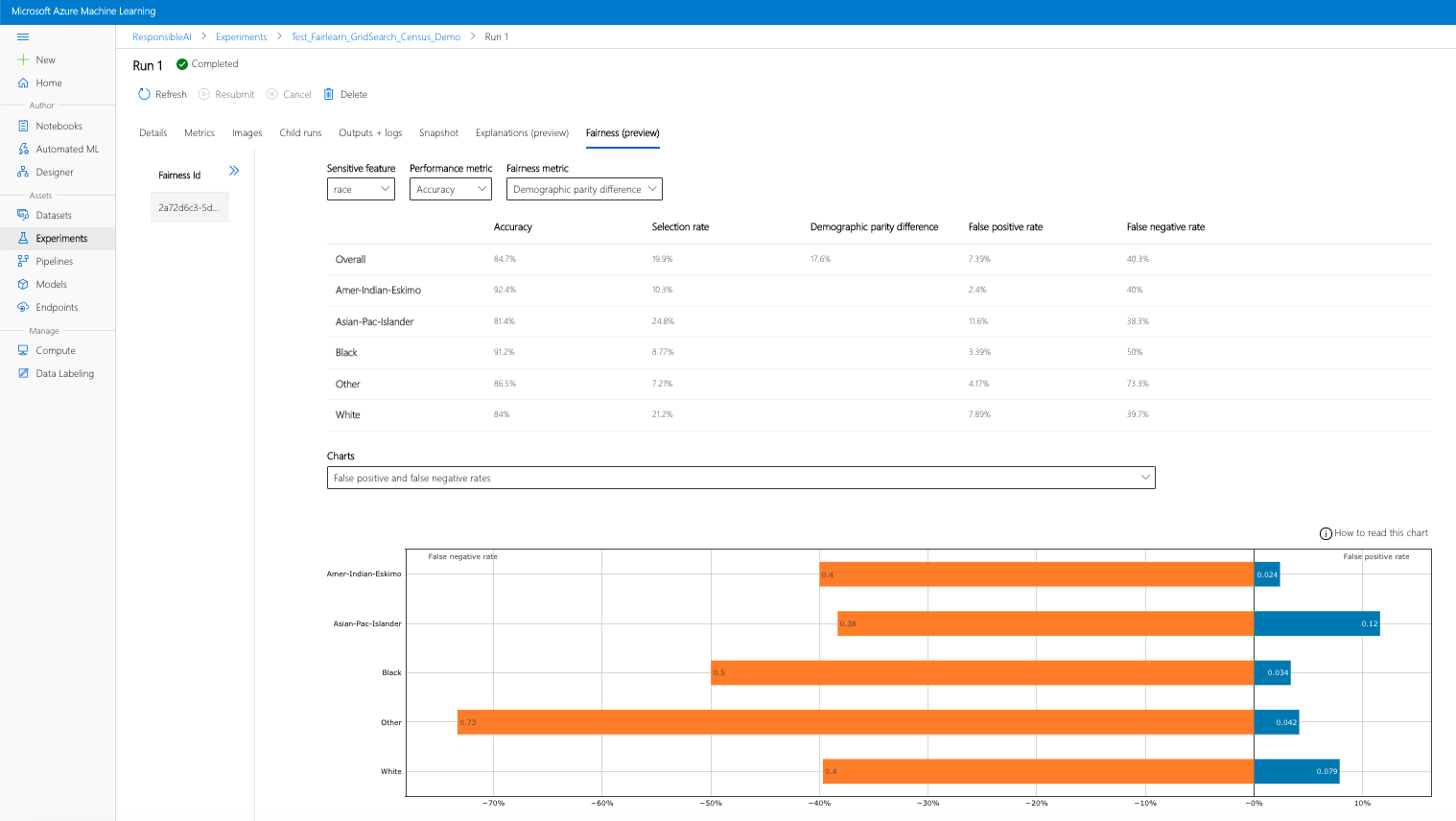
- Modellek panel
- Ha az előző lépések végrehajtásával regisztrálta az eredeti modellt, a bal oldali panelen a Modellek lehetőséget választva tekintheti meg.
- Válasszon ki egy modellt, majd a Méltányosság lapon tekintse meg a magyarázó vizualizáció irányítópultját.
A vizualizációs irányítópultról és annak tartalmairól a Fairlearn felhasználói útmutatójában talál további információt.


Méltányossági megállapítások feltöltése több modellhez
Ha több modellt szeretne összehasonlítani, és látni szeretné, hogy miben különböznek a méltányossági értékelések, több modellt is átadhat a vizualizációs irányítópultnak, és összehasonlíthatja a teljesítmény-méltányosság kompromisszumait.
Modellek betanítása:
Most létrehozunk egy második osztályozót egy támogatási vektorgép-becslő alapján, és feltöltünk egy méltányossági irányítópult-szótárt a Fairlearn csomagjával
metrics. Feltételezzük, hogy a korábban betanított modell továbbra is elérhető.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Modellek regisztrálása
Ezután regisztrálja mindkét modellt az Azure Machine Learningben. Az egyszerűség kedvéért tárolja az eredményeket egy szótárban, amely leképezi a
idregisztrált modell (egy sztringname:versionformátumú) értékét magához a prediktorhoz:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorA Méltányosság irányítópult helyi betöltése
Mielőtt feltöltené a méltányossági megállapításokat az Azure Machine Learningbe, megvizsgálhatja ezeket az előrejelzéseket egy helyileg meghívott Méltányosság irányítópulton.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)A méltányossági metrikák előzetes kiegészítése.
Hozzon létre egy irányítópult-szótárt a Fairlearn csomagjával
metrics.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Töltse fel az előre összeállított méltányossági metrikákat.
Most importálja
azureml.contrib.fairnessa csomagot a feltöltés végrehajtásához:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idHozzon létre egy kísérletet, majd egy Futtatás parancsot, és töltse fel az irányítópultot a következőre:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Az előző szakaszhoz hasonlóan a fenti útvonalak egyikét követve (a Kísérletek vagy a Modellek segítségével) elérheti a vizualizációs irányítópultot Azure Machine Learning stúdió, és összehasonlíthatja a két modellt a méltányosság és a teljesítmény szempontjából.
Nem utánzott és enyhített méltányossági megállapítások feltöltése
Használhatja a Fairlearn kockázatcsökkentési algoritmusait, összehasonlíthatja a létrehozott enyhített modell(ek)et az eredeti nem utánzott modellel, és navigálhat a teljesítmény/méltányosság kompromisszumoi között az összehasonlított modellek között.
Ha egy olyan példát szeretne látni, amely bemutatja a Grid Search kockázatcsökkentési algoritmusának használatát (amely különböző méltányosságú és teljesítménnyel kapcsolatos enyhített modellek gyűjteményét hozza létre), tekintse meg ezt a mintajegyzetfüzetet.
Ha több modell méltányossági megállapításait tölti fel egyetlen futtatásban, az lehetővé teszi a modellek összehasonlítását a méltányosság és a teljesítmény szempontjából. A modell-összehasonlító diagramon megjelenő modellekre kattintva megtekintheti az adott modell részletes méltányossági megállapításait.

Következő lépések
További információ a modell méltányosságáról
Tekintse meg az Azure Machine Learning Fairness mintajegyzetfüzeteit