K-közép csoportosítás
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- A gépi tanulási projektek ML Studióból (klasszikus) Azure Machine Learningbe való áthelyezéséről szóló információk.
- További információ az Azure Machine Learningről.
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
K-közép fürtözési modell konfigurálása és inicializálása
Kategória: Gépi tanulás / Modell inicializálása / Fürtözés
Megjegyzés
Csak a következőre vonatkozik: Machine Learning Studio ( klasszikus)
Hasonló húzási modulok érhetők el az Azure Machine Learning-tervezőben.
A modul áttekintése
Ez a cikk azt ismerteti, hogyan hozhat létre betanítatlan K-közép fürtözési modellt a Machine Learning Studióban (klasszikus) a K-Közép fürtözési modullal.
A K-közép az egyik legegyszerűbb és legismertebb nem felügyelt tanulási algoritmus, és számos gépi tanulási feladathoz használható, például rendellenes adatok észleléséhez, szöveges dokumentumok csoportosításához és adathalmaz elemzéséhez más besorolási vagy regressziós módszerek használata előtt. Fürtözési modell létrehozásához hozzáadja ezt a modult a kísérlethez, csatlakoztat egy adatkészletet, és olyan paramétereket állít be, mint a várt fürtök száma, a fürtök létrehozásához használandó távolságmetrika stb.
Miután konfigurálta a modul hiperparamétereit, csatlakoztassa a nem betanított modellt a Fürtözési modell betanítása vagy a Fürtözés takarítása modulhoz, hogy betanítsa a modellt a megadott bemeneti adatokon. Mivel a K-közép algoritmus nem felügyelt tanulási módszer, a címkeoszlop megadása nem kötelező.
- Ha az adatok tartalmaznak címkét, a címkeértékek segítségével kiválaszthatja a fürtöket, és optimalizálhatja a modellt.
- Ha az adatok nem rendelkezik címkével, az algoritmus olyan fürtöket hoz létre, amelyek a lehetséges kategóriákat jelölik, kizárólag az adatok alapján.
Tipp
Ha a betanítási adatok címkékkel vannak ellátva, fontolja meg a Machine Learningben biztosított felügyelt besorolási módszerek egyikének használatát. Összehasonlíthatja például a fürtözés eredményeit az eredményekkel a többosztályos döntési fa algoritmusok egyikének használatakor.
A k-közép fürtözés ismertetése
A fürtözés általában iteratív technikákkal csoportosítja az adathalmazok eseteit hasonló jellemzőkkel rendelkező fürtökbe. Ezek a csoportosítások hasznosak az adatok feltárásához, az adatok rendellenességeinek azonosításához és végül az előrejelzések készítéséhez. A fürtözési modellek segíthetnek azonosítani az adathalmazok olyan kapcsolatait is, amelyek böngészéssel vagy egyszerű megfigyeléssel nem feltétlenül származnak logikusan. Ezen okok miatt a fürtözést gyakran használják a gépi tanulási feladatok korai fázisaiban, az adatok feltárására és a váratlan korrelációk felderítésére.
Ha a k-közép módszerrel konfigurál egy fürtözési modellt, meg kell adnia egy k célszámot, amely a modellben használni kívánt centroidok számát jelzi. A centroid az egyes fürtökre jellemző pont. A K-közép algoritmus minden bejövő adatpontot hozzárendel az egyik fürthöz a fürtön belüli négyzetösszeg minimalizálásával.
A betanítási adatok feldolgozásakor a K-közép algoritmus véletlenszerűen kiválasztott centroidok kezdeti készletével kezdődik, amelyek az egyes fürtök kiindulási pontjaiként szolgálnak, és Lloyd algoritmusát alkalmazza a centroidok helyének iteratív finomítására. A K-közép algoritmus leállítja a fürtök összeállítását és finomítását, ha megfelel az alábbi feltételek valamelyikének:
A centroidok stabilizálódnak, ami azt jelenti, hogy az egyes pontok fürt-hozzárendelései már nem változnak, és az algoritmus konvergált egy megoldáson.
Az algoritmus befejezte a megadott számú iteráció futtatását.
A betanítási fázis befejezése után az Adatok hozzárendelése fürtökhöz modullal rendelhet új eseteket a k-közép algoritmus által talált fürtök egyikéhez. A fürthozzárendelés az új eset és az egyes fürtök centroidja közötti távolság kiszámításával történik. Minden új eset a legközelebbi centroidmal rendelkező fürthöz van rendelve.
K-Közép-fürtszolgáltatás konfigurálása
Adja hozzá a K-Közép fürtszolgáltatás modult a kísérlethez.
A Modell betanításának módját az Oktatói mód létrehozása beállítással adhatja meg.
Egyetlen paraméter: Ha ismeri a fürtözési modellben használni kívánt pontos paramétereket, argumentumként megadhat egy adott értékkészletet.
Paramétertartomány: Ha nem biztos a legjobb paraméterekben, több érték megadásával és a Takarítási fürtszolgáltatás modul használatával megtalálhatja az optimális konfigurációt.
A tréner a megadott beállítások több kombinációját is iterálja, és meghatározza az optimális csoportosítási eredményeket eredményező értékek kombinációját.
A Centroidok száma mezőbe írja be azoknak a fürtöknek a számát, amellyel az algoritmust kezdeni szeretné.
A modell nem garantáltan pontosan ennyi fürtöt állít elő. Az algorithn ekkora adatpontszámmal kezdődik, és iterál, hogy megtalálja az optimális konfigurációt a Műszaki megjegyzések szakaszban leírtak szerint.
Ha paraméteres takarítást végez, a tulajdonság neve a Centroidok számának tartománya értékre változik. A Tartományszerkesztővel megadhat egy tartományt, vagy beírhat egy számsort, amely különböző számú fürtöt hoz létre az egyes modellek inicializálása során.
A takarítás inicializálása vagy inicializálása tulajdonság a kezdeti fürtkonfiguráció meghatározásához használt algoritmus megadására szolgál.
Első N: Az adatkészletből néhány kezdeti adatpontszám van kiválasztva, és kezdeti eszközként szolgál.
Más néven Forgy metódus.
Véletlenszerű: Az algoritmus véletlenszerűen helyez el egy adatpontot egy fürtben, majd kiszámítja a kezdeti középértékeket, hogy a fürt véletlenszerűen hozzárendelt pontjainak centroidja legyen.
Más néven a véletlenszerű partíciós metódus.
K-Közép++: Ez a fürtök inicializálásának alapértelmezett módja.
A K-közép ++ algoritmust David Arthur és Sergei Vassilvitskii javasolta 2007-ben a standard k-közép algoritmus gyenge csoportosításának elkerülése érdekében. A K-közép ++ a standard K-középértékek alapján javul, ha egy másik módszert használ a kezdeti fürtközpontok kiválasztásához.
K-Közép++Gyors: A K-közép ++ algoritmus egy változata, amely a gyorsabb fürtözésre lett optimalizálva.
Egyenletes: A centroidok egyenlő távolságban vannak egymástól az n adatpontok d-dimenziós terében.
Címkeoszlop használata: A címkeoszlop értékei a centroidok kiválasztásának irányítására szolgálnak.
Véletlenszerű számmagok esetén igény szerint írjon be egy értéket, amelyet a fürt inicializálásának magjaként szeretne használni. Ez az érték jelentős hatással lehet a fürt kiválasztására.
Ha paraméteres takarítást használ, megadhatja, hogy több kezdeti mag is létre legyen hozva, hogy a legjobb kezdeti magértéket keresse. A Vetendő magok száma mezőbe írja be a kezdőpontként használandó véletlenszerű magértékek teljes számát.
A Metrika beállításnál válassza ki a fürtvektorok közötti távolság, illetve az új adatpontok és a véletlenszerűen kiválasztott centroid közötti távolság méréséhez használni kívánt függvényt. A Machine Learning a következő fürttávmetrikákat támogatja:
Euklideszi: Az euklideszi távolságot gyakran használják a K-közép klaszterezés fürt pontjának mérésére. Ez a metrika azért ajánlott, mert minimálisra csökkenti a pontok és a centroidok közötti átlagos távolságot.
Koszinusza: A koszinusza függvény a fürt hasonlóságának mérésére szolgál. A koszinuszas hasonlóság olyan esetekben hasznos, amikor nem érdekli a vektor hossza, csak a szöge.
Iterációk esetén írja be, hogy hányszor kell iterálni az algoritmust a betanítási adatokon a centroidok kiválasztásának véglegesítése előtt.
Ezt a paramétert a pontosság és a betanítási idő egyensúlyba hozásához módosíthatja.
A Címke hozzárendelése módnál válassza ki azt a beállítást, amely meghatározza, hogy az adathalmazban található címkeoszlopokat hogyan kell kezelni.
Mivel a K-közép csoportosítás nem felügyelt gépi tanulási módszer, a címkék megadása nem kötelező. Ha azonban az adathalmaznak már van címkeoszlopa, akkor ezekkel az értékekkel irányíthatja a fürtök kiválasztását, vagy megadhatja, hogy az értékek figyelmen kívül legyenek hagyva.
Címkeoszlop figyelmen kívül hagyása: A címkeoszlop értékeit a rendszer figyelmen kívül hagyja, és nem használja fel a modell létrehozásához.
Hiányzó értékek kitöltése: A címkeoszlop értékei funkcióként szolgálnak a fürtök létrehozásához. Ha bármelyik sorból hiányzik egy címke, az érték más funkciókkal lesz imputált.
Felülírás a legközelebbitől a középig: A címkeoszlop értékeit előrejelzett címkeértékek váltják fel az aktuális centroidhoz legközelebbi pont címkéjével.
A modell betanítása.
Ha a Create trainer mode (Oktató létrehozása) módotEgyetlen paraméter értékre állítja, adjon hozzá egy címkézett adatkészletet, és tanítsa be a modellt a Fürtözési modell betanítása modullal.
Ha a Create trainer mode (Oktató létrehozása) módotParamétertartomány értékre állítja, adjon hozzá egy címkézett adatkészletet, és tanítsa be a modellt a Sweep Clustering használatával. Használhatja a paraméterekkel betanított modellt, vagy jegyezheti fel a tanuló konfigurálásakor használandó paraméterbeállításokat.
Results (Eredmények)
Miután befejezte a modell konfigurálását és betanítását, rendelkezik egy modellel, amellyel pontszámokat hozhat létre. A modell betanítása azonban többféleképpen is lehetséges, és többféleképpen is megtekintheti és használhatja az eredményeket:
A modell pillanatképének rögzítése a munkaterületen
Ha a Fürtözési modell betanítása modult használta
- Kattintson a jobb gombbal a Fürtmodell betanítása modulra.
- Válassza a Betanított modell lehetőséget, majd kattintson a Mentés betanított modellként elemre.
Ha a Sweep Clustering modult használta a modell betanításához
- Kattintson a jobb gombbal a Fürtözés takarítása modulra .
- Válassza a Legjobban betanított modell lehetőséget, majd kattintson a Mentés betanított modellként elemre.
A mentett modell a modell mentésekor a betanítási adatokat jelöli. Ha később frissíti a kísérletben használt betanítási adatokat, az nem frissíti a mentett modellt.
A modellben lévő fürtök vizuális ábrázolásának megtekintése
Ha a Fürtözési modell betanítása modult használta
- Kattintson a jobb gombbal a modulra, és válassza az Eredmények adatkészletet.
- Válassza a Vizualizáció lehetőséget.
Ha a Takarítási fürtszolgáltatás modult használta
Adja hozzá az Adatok hozzárendelése fürtökhöz modul egy példányát, és hozzon létre pontszámokat a legjobban betanított modell használatával.
Kattintson a jobb gombbal az Adatok hozzárendelése fürtökhöz modulra , válassza az Eredmények adatkészlet lehetőséget, majd válassza a Vizualizáció lehetőséget.
A diagram a Fő összetevő-elemzés használatával jön létre, amely egy adatelemzési módszer a modell funkciótartományának tömörítésére. A diagram néhány olyan funkciót mutat be, amelyek két dimenzióba vannak tömörítve, amelyek a legjobban jellemzik a fürtök közötti különbséget. Ha vizuálisan áttekinti az egyes fürtök jellemzőterületének általános méretét és a fürtök átfedését, képet kaphat arról, hogy milyen jól teljesíthet a modell.
A következő PCA-diagramok például két, azonos adatokkal betanított modell eredményeit ábrázolják: az első két fürt kimenetére, a második pedig három fürt kimenetére lett konfigurálva. Ezekből a diagramokból látható, hogy a fürtök számának növelése nem feltétlenül javította az osztályok elkülönítését.
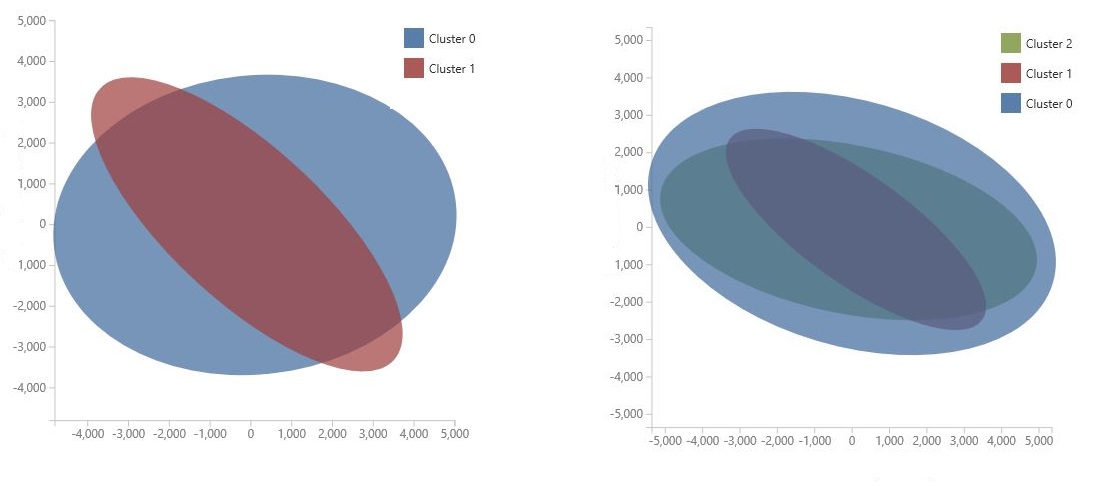
Tipp
A Sweep Clustering modullal kiválaszthatja a hiperparaméterek optimális készletét, beleértve a véletlenszerű magot és a kezdő centroidok számát.
Tekintse meg az adatpontok és a fürtök listáját, amelyekhez tartoznak
Az adathalmazt kétféleképpen tekintheti meg az eredményekkel, a modell betanítási módjától függően:
Ha a Sweep Clustering modult használta a modell betanításához
- A Fürtözés takarítása modul jelölőnégyzetével adja meg, hogy a bemeneti adatokat az eredményekkel együtt szeretné-e látni, vagy csak az eredményeket.
- Amikor a betanítás befejeződött, kattintson a jobb gombbal a modulra, és válassza az Eredmények adatkészletet (2- es kimeneti szám)
- Kattintson a Vizualizáció elemre.
Ha a Fürtözési modell betanítása modult használta
- Adja hozzá az Adatok hozzárendelése fürtökhöz modult, és csatlakoztassa a betanított modellt a bal oldali bemenethez. Adathalmaz csatlakoztatása a jobb oldali bemenethez.
- Adja hozzá a Kísérlethez a Konvertálás adathalmazsá modult, és csatlakoztassa az Adatok hozzárendelése fürtökhöz kimenetéhez.
- Az Adatok hozzárendelése fürtökhöz modul jelölőnégyzetével adja meg, hogy a bemeneti adatokat az eredményekkel együtt szeretné-e látni, vagy csak az eredményeket.
- Futtassa a kísérletet, vagy futtassa csak a Konvertálás adatkészletté modult .
- Kattintson a jobb gombbal a Konvertálás adatkészletté parancsra, válassza az Eredmények adatkészlet lehetőséget, majd kattintson a Vizualizáció elemre.
A kimenet tartalmazza először a bemeneti adatok oszlopait, ha belefoglalta őket, és a következő oszlopokat minden egyes bemeneti adatsorhoz:
Hozzárendelés: A hozzárendelés egy 1 és n közötti érték, ahol n a modellben lévő fürtök teljes száma. Minden adatsor csak egy fürthöz rendelhető hozzá.
DistancesToClusterCenter no.n: Ez az érték az aktuális adatpont és a fürt centroidja közötti távolságot méri. Külön oszlop a kimenetben a betanított modellben lévő összes fürthöz.
A fürt távolságának értékei a fürt eredményének mérésére szolgáló metrika beállításban kiválasztott távolságmetrikán alapulnak. Még ha paraméteres takarítást is végez a fürtözési modellen, a takarítás során csak egy metrika alkalmazható. Ha módosítja a metrikát, különböző távolságértékeket kaphat.
Fürtön belüli távolságok megjelenítése
Az előző szakasz eredményeinek adathalmazában kattintson az egyes fürtök távolságainak oszlopára. A Studio (klasszikus) egy hisztogramot jelenít meg, amely a fürtön belüli pontok távolságainak eloszlását jeleníti meg.
Az alábbi hisztogramok például a fürt távolságának eloszlását mutatják ugyanabból a kísérletből, négy különböző metrikával. A paraméteres takarítás minden más beállítása ugyanaz volt. A metrika módosítása egy modellben eltérő számú fürtöt eredményezett.

Általában olyan metrikát kell választania, amely maximalizálja a különböző osztályokban lévő adatpontok közötti távolságot, és minimalizálja az osztályon belüli távolságokat. A Statisztika panelen az előre lefordított eszközök és egyéb értékek segítségével végigvezetheti ebben a döntésben.
Tipp
A vizualizációkban használt eszközöket és egyéb értékeket a Machine Learning PowerShell-moduljának használatával nyerheti ki.
Vagy használja az R-szkript végrehajtása modult egy egyéni távolságmátrix kiszámításához.
Tippek a legjobb fürtözési modell létrehozásához
Ismert, hogy a fürtözés során használt magolási folyamat jelentősen befolyásolhatja a modellt. A vetés azt jelenti, hogy a pontok kezdeti elhelyezése erős centroidokba.
Ha például az adathalmaz sok kiugró értéket tartalmaz, és kiugró érték van kiválasztva a fürtök bevetéséhez, más adatpontok nem férnének el jól az adott fürthöz, és a fürt egyetlen pont lehet: vagyis egy fürt, amely csak egy ponttal rendelkezik.
A probléma többféleképpen is elkerülhető:
A paraméteres takarítással módosíthatja a centroidok számát, és több magértéket próbálhat ki.
Több modell létrehozása, a metrika módosítása vagy további iterálás.
Olyan változók megkereséséhez használjon olyan metódusokat, mint a PCA, amelyek hátrányos hatással vannak a fürtözésre. Ennek a technikának a bemutatásához tekintse meg a Hasonló vállalatok keresése mintát.
A fürtözési modellek esetében általában lehetséges, hogy egy adott konfiguráció helyileg optimalizált fürtkészletet eredményez. Más szóval a modell által visszaadott fürtök csak az aktuális adatpontokhoz illeszkednek, és más adatokra nem általánosíthatók. Ha eltérő kezdeti konfigurációt használt, a K-közép metódus eltérő, esetleg fölérendelt konfigurációt találhat.
Fontos
Javasoljuk, hogy mindig kísérletezzen a paraméterekkel, hozzon létre több modellt, és hasonlítsa össze az eredményként kapott modelleket.
Példák
Példák a K-közép fürtözés machine learningben való felhasználására, tekintse meg ezeket a kísérleteket az Azure AI-galériában:
Íriszadatok csoportosítása: Egy besorolási feladat K-Közép csoportosítási és többosztályos logisztikai regressziójának eredményeit hasonlítja össze.
Színkvantálási minta: Több K-közép modellt hoz létre különböző paraméterekkel, hogy megtalálja az optimális képtömörítést.
Csoportosítás: Hasonló vállalatok: Az S&P500-ban található hasonló vállalatok csoportjainak megkereséséhez a centroidok száma változik.
Technikai megjegyzések
Tekintettel arra, hogy adott számú fürtöt (K) kell megkeresni az N adatpontokkal rendelkező D-dimenziós adatpontok halmazához, a K-közép algoritmus az alábbiak szerint hozza létre a fürtöket:
A modul inicializál egy K-by-D tömböt a talált K-fürtöket meghatározó végső centroidokkal.
Alapértelmezés szerint a modul hozzárendeli az első K adatpontokat a K-fürtökhöz.
A K centroidok kezdeti készletétől kezdve a metódus Lloyd algoritmusát használja a centroidok helyének iteratív finomítására.
Az algoritmus leáll, amikor a centroidok stabilizálódnak, vagy ha egy adott számú iteráció befejeződik.
Egy hasonlósági metrika (alapértelmezés szerint euklideszi távolság) használatával rendeli hozzá az egyes adatpontokhoz a legközelebbi centroidot tartalmazó fürtöt.
Figyelmeztetés
- Ha paramétertartományt ad át a Fürtözési modell betanítása szolgáltatásnak, az csak az első értéket használja a paramétertartományok listájában.
- Ha egyetlen paraméterérték-készletet ad át a Takarítási fürtszolgáltatás modulnak, amikor az minden paraméterhez egy beállítástartományt vár, figyelmen kívül hagyja az értékeket, és az alapértelmezett értékeket használja a tanuló számára.
- Ha a Paramétertartomány lehetőséget választja, és egyetlen értéket ad meg bármely paraméterhez, akkor a rendszer az adott értéket használja a takarítás során, még akkor is, ha más paraméterek egy értéktartományon belül változnak.
Modulparaméterek
| Name | Tartomány | Típus | Alapértelmezett | Description |
|---|---|---|---|---|
| Centroidok száma | >=2 | Egész szám | 2 | Centroidok száma |
| Metrika | Lista (részhalmaz) | Metrika | Euklideszi | Kiválasztott metrika |
| Inicializálás | Lista | Centroid inicializálási módszer | K-Közép++ | Inicializálási algoritmus |
| Iterációk | >=1 | Egész szám | 100 | Iterációk száma |
Kimenetek
| Név | Típus | Description |
|---|---|---|
| Nem betanított modell | ICluster-felület | Nem betanított K-Means fürtözési modell |
Kivételek
Az összes kivétel listáját a Machine Learning-modul hibakódjai című témakörben találja.
| Kivétel | Description |
|---|---|
| 0003-os hiba | Kivétel akkor fordul elő, ha egy vagy több bemenet null értékű vagy üres. |
Lásd még
Fürtözés
Adatok hozzárendelése fürtökhöz
Csoportosítási modell betanítása
Fürtözés takarítása