Tippek az Azure AI Search jobb teljesítményéért
Ez a cikk tippek és ajánlott eljárások gyűjteménye a lekérdezési és indexelési teljesítmény növeléséhez. Ha tudja, hogy mely tényezők befolyásolják leginkább a keresési teljesítményt, elkerülheti a hatékonyságot, és a lehető legtöbbet hozhatja ki a keresési szolgáltatásból. Néhány fontos tényező:
- Indexösszeállítás (séma és méret)
- Lekérdezések tervezése
- Szolgáltatáskapacitás (szint, replikák és partíciók száma)
Feljegyzés
Stratégiákat keres a nagy mennyiségű indexeléshez? Lásd: Nagyméretű adathalmazok indexelése az Azure AI Searchben.
Indexméret és séma
A lekérdezések gyorsabban futnak kisebb indexeken. Ez részben annak a függvénye, hogy kevesebb mezőt kell beolvasni, de annak is köszönhető, hogy a rendszer hogyan gyorsítótárazza a jövőbeli lekérdezések tartalmát. Az első lekérdezés után egyes tartalmak a memóriában maradnak, ahol hatékonyabban keresnek. Mivel az index mérete általában idővel nő, az egyik ajánlott eljárás az indexösszetétel rendszeres időközönként történő újrafelfedése, mind a séma, mind a dokumentumok esetében, a tartalomcsökkentési lehetőségek keresése érdekében. Ha azonban az index megfelelő méretű, az egyetlen további kalibráció a kapacitás növelése: replikák hozzáadásával vagy a szolgáltatási szint frissítésével. A "Tipp: Frissítés standard S2 szintre" című szakasz a vertikális felskálázást és a vertikális felskálázási döntést ismerteti.
A séma összetettsége az indexelést és a lekérdezési teljesítményt is hátrányosan befolyásolhatja. A túlzott mezőfeltribúció korlátozásokat és feldolgozási követelményeket támaszt. Az összetett típusok indexelése és lekérdezése hosszabb időt vesz igénybe. A következő néhány szakasz az egyes állapotokat ismerteti.
Tipp: Legyen szelektív a mezőmegjelölésben
Gyakori hiba, amelyet a rendszergazdák és a fejlesztők követnek el a keresési index létrehozásakor, hogy a mezők összes elérhető tulajdonságát kiválasztják, és nem csak a szükséges tulajdonságokat választják ki. Ha például egy mezőnek nem kell teljes szöveges kereshetőnek lennie, hagyja ki ezt a mezőt a kereshető attribútum beállításakor.
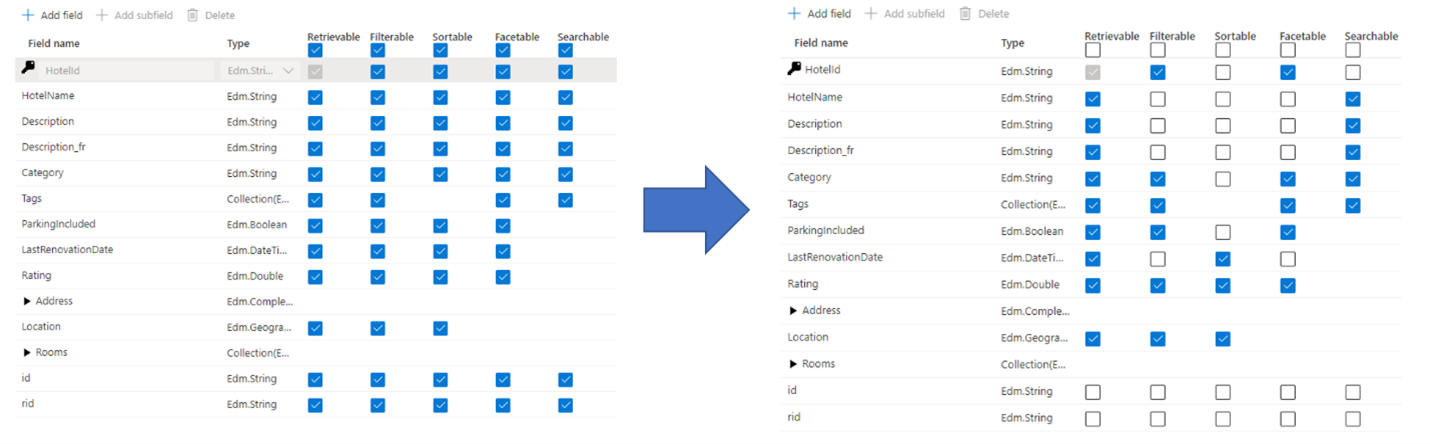
A szűrők, aspektusok és rendezés támogatása megnégyszerezheti a tárolási követelményeket. Ha javaslatokat ad hozzá, a tárolási követelmények még nagyobbak lesznek. Az attribútumok tárolóra gyakorolt hatásáról az attribútumok és az indexméret című témakörben talál illusztrációt.
Összefoglalva, a túlterjeszkedés következményei a következők:
Az indexelési teljesítmény romlása a mező tartalmának feldolgozásához szükséges többletmunka miatt, majd a keresési invertált indexben tárolva (a "kereshető" attribútumot csak a kereshető tartalmat tartalmazó mezőkön állítsa be).
Nagyobb felületet hoz létre, amelyet minden lekérdezésnek el kell fednie. A kereshetőként megjelölt összes mező teljes szöveges keresésben lesz beolvasva.
A többlettárolás miatt növeli a működési költségeket. A szűréshez és rendezéshez további hely szükséges az eredeti (nem elemzett) sztringek tárolásához. Ne állítsa be a szűrhető vagy rendezhető mezőket olyan mezőkre, amelyekre nincs szüksége.
A túlterjeszkedés sok esetben korlátozza a mező képességeit. Ha például egy mező facetable, filterable és searchable, akkor csak 16 KB szöveget tárolhat egy mezőben, míg a kereshető mezők legfeljebb 16 MB szöveget tartalmazhatnak.
Feljegyzés
Csak a szükségtelen hozzárendelést kell elkerülni. A szűrők és aspektusok gyakran nélkülözhetetlenek a keresési élményhez, és a szűrők használata esetén gyakran kell rendezni, hogy a találatokat rendezhesse (a szűrők önmagukban rendezetlen készletben térnek vissza).
Tipp: Fontolja meg az összetett típusok alternatíváit
Az összetett adattípusok akkor hasznosak, ha az adatok bonyolult beágyazott struktúrával rendelkeznek, például a JSON-dokumentumokban található szülő-gyermek elemek. Az összetett típusok hátránya a tartalom indexeléséhez szükséges további tárolási követelmények és további erőforrások a nem összetett adattípusokhoz képest.
Bizonyos esetekben elkerülheti ezeket a kompromisszumokat, ha egy összetett adatstruktúrát egy egyszerűbb mezőtípusra, például gyűjteményre képez le. Másik lehetőségként dönthet úgy is, hogy egy mezőhierarchiát egyes gyökérszintű mezőkbe egyesít.

Lekérdezések tervezése
A lekérdezések összetétele és összetettsége a teljesítmény egyik legfontosabb tényezője, és a lekérdezésoptimalizálás jelentősen javíthatja a teljesítményt. A lekérdezések tervezésekor vegye figyelembe a következőket:
Kereshető mezők száma. Minden további kereshető mező több munkát eredményez a keresési szolgáltatás számára. A lekérdezési időpontban keresendő mezőket a "searchFields" paraméterrel korlátozhatja. Érdemes csak az érdeklődésre számot tartó mezőket megadni, ezzel javíthatja a teljesítményt.
A visszaadott adatok mennyisége. A nagy mennyiségű tartalom beolvasása lelassíthatja a lekérdezéseket. A lekérdezés felépítése során úgy járjon el, hogy a lekérdezés csak azokat a mezőket adja vissza, amelyek az eredményeket tartalmazó oldal rendereléséhez szükségesek, majd a fennmaradó mezőket a keresési API használatával kérje le, miután a felhasználó kiválasztott egy találatot.
Részleges kifejezéskeresések használata.A részleges kifejezéskeresések, például az előtagkeresés, a homályos keresés és a reguláris kifejezéskeresések számításilag drágábbak, mint a tipikus kulcsszókeresések, mivel teljes indexvizsgálatot igényelnek az eredmények előállításához.
Aspektusok száma. Az aspektusok lekérdezésekhez való hozzáadásához összesítésre van szükség minden lekérdezés esetén. Ha egy aspektushoz magasabb „darabszámot” kér, az a szolgáltatás részéről is több munkát igényel. Általánosságban elmondható, hogy érdemes csak azokat az aspektusokat hozzáadni, amelyeket az alkalmazásban renderelni szeretne, és csak szükség esetén kérjen magas darabszámot az aspektusokhoz.
Magas kihagyásértékek. A
$skipparaméter magas (például ezres nagyságrendű) értékre való beállítása növeli a keresés késését, mivel a motor minden egyes kéréshez nagy számú dokumentumot kér le és rangsorol. A teljesítmény javítása érdekében érdemes kerülni a magas$skipértékeket, és más technikát (például szűrést) használni a sok dokumentum lekéréséhez.Korlátozza a magas számosságú mezőket. A magas számosságú mező olyan arculati vagy szűrhető mezőre utal, amely jelentős számú egyedi értékkel rendelkezik, és ennek eredményeként jelentős erőforrásokat használ fel az eredmények kiszámításakor. Ha például egy Termékazonosító vagy Leírás mezőt facetable-ként és szűrhetőként állít be, az magas számosságnak számít, mivel a dokumentumtól a dokumentumig minden érték egyedi.
Tipp: Keresési függvények használata a szűrőfeltételek túlterhelése helyett
Mivel a lekérdezés egyre összetettebb szűrési feltételeket használ, a keresési lekérdezés teljesítménye csökkenni fog. Tekintse meg az alábbi példát, amely bemutatja, hogy a szűrők használatával a felhasználói identitás alapján vágja ki az eredményeket:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
Ebben az esetben a szűrőkifejezések annak ellenőrzésére szolgálnak, hogy az egyes dokumentumok egyetlen mezője megegyezik-e a felhasználói identitás számos lehetséges értékének egyikével. Ezt a mintát valószínűleg a biztonsági vágást implementáló alkalmazásokban találja (egy vagy több egyszerű azonosítót tartalmazó mező ellenőrzése a lekérdezést kibocsátó felhasználót képviselő egyszerű azonosítók listájában).
A nagy számú értéket tartalmazó szűrők végrehajtásának hatékonyabb módja a függvény használatasearch.in, ahogyan az ebben a példában látható:
search.in(userid, '123,234,345,456,567', ',')
Tipp: Partíciók hozzáadása lassú egyéni lekérdezésekhez
Ha a lekérdezési teljesítmény általában lelassul, a további replikák hozzáadása gyakran megoldja a problémát. De mi a teendő, ha a probléma egy olyan lekérdezés, amely túl sokáig tart? Ebben a forgatókönyvben a replikák hozzáadása nem segít, de több partíció is előfordulhat. A partíciók felosztják az adatokat a további számítási erőforrások között. Két partíció félbe osztja az adatokat, egy harmadik partíció pedig harmadokra osztja őket, és így tovább.
A partíciók hozzáadásának egyik pozitív mellékhatása, hogy a lassabb lekérdezések néha gyorsabban hajtanak végre a párhuzamos számítástechnika miatt. Megfigyeltük az alacsony szelektivitású lekérdezések párhuzamosságát, például a sok dokumentumnak megfelelő lekérdezéseket, vagy olyan aspektusokat, amelyek nagy számú dokumentumot számlálnak meg. Mivel jelentős számításokra van szükség a dokumentumok relevanciájának pontszámához vagy a dokumentumok számának megszámlálásához, további partíciók hozzáadásával gyorsabban befejeződnek a lekérdezések.
Partíciók hozzáadásához használja az Azure Portalt, a PowerShellt, az Azure CLI-t vagy a felügyeleti SDK-t.
Szolgáltatási kapacitás
A szolgáltatás túlterhelt, ha a lekérdezések túl hosszúak, vagy amikor a szolgáltatás elkezdi elvetni a kéréseket. Ha ez történik, a szolgáltatás frissítésével vagy kapacitás hozzáadásával megoldhatja a problémát.
A keresési szolgáltatás szintje és a replikák/partíciók száma is nagy hatással van a teljesítményre. A fokozatosan magasabb szintek gyorsabb processzorokat és több memóriát biztosítanak, amelyek mindkettő pozitív hatással vannak a teljesítményre.
Tipp: Új nagy kapacitású keresési szolgáltatás létrehozása
A (támogatott régiókban) létrehozott alapszintű és standard szolgáltatások (a 2024. április 3. után támogatott régiók partíciónként több tárterületet használnak, mint a régebbi szolgáltatások). Mielőtt magasabb szintre és magasabb számlázható díjra frissít, tekintse meg újra a rétegszolgáltatás korlátait , és ellenőrizze, hogy egy újabb szolgáltatás ugyanazon szintje biztosítja-e a szükséges tárterületet.
Tipp: Frissítés standard S2 szintre
A Standard S1 keresési szint gyakran az ügyfelek kiindulópontja. Az S1-szolgáltatások gyakori mintája, hogy az indexek idővel növekednek, ami több partíciót igényel. A további partíciók lassabb válaszidőt eredményeznek, ezért a rendszer további replikákat ad hozzá a lekérdezési terhelés kezeléséhez. Ahogy el tudja képzelni, az S1-szolgáltatások futtatásának költsége a kezdeti konfiguráción túli szintekre nőtt.
Ebben a helyzetben fontos kérdés, hogy érdemes-e magasabb szintre lépni, nem pedig fokozatosan növelni a jelenlegi szolgáltatás partícióinak vagy replikáinak számát.
Tekintsük a következő topológiát példaként egy olyan szolgáltatásra, amely egyre nagyobb kapacitásszinteket vett igénybe:
- Standard S1 szint
- Indexméret: 190 GB
- Partíciók száma: 8 (S1 esetén a partíció mérete partíciónként 25 GB)
- Replikaszám: 2
- Összes keresési egység: 16 (8 partíció x 2 replika)
- Feltételezett kiskereskedelmi ár: ~4000 USD / hó (feltételezzük, hogy 250 USD x 16 keresési egység)
Tegyük fel, hogy a szolgáltatásadminisztrátor továbbra is nagyobb késést lát, és fontolgatja egy másik replika hozzáadását. Ez a replikaszámot 2-ről 3-ra módosítaná, és ennek eredményeként a keresési egység számát 24-re módosítaná, és az eredményként kapott ár 6000 USD/hó.
Ha azonban a rendszergazda a Standard S2 szintre való áttérést választja, a topológia a következőképpen nézne ki:
- Standard S2 szint
- Indexméret: 190 GB
- Partíciók száma: 2 (S2 esetén a partíció mérete partíciónként 100 GB)
- Replikaszám: 2
- Összes keresési egység: 4 (2 partíció x 2 replika)
- Feltételezett kiskereskedelmi ár: ~4000 USD / hónap (1000 USD x 4 keresési egység)
Ahogy ez a hipotetikus forgatókönyv is szemlélteti, alacsonyabb szinteken is rendelkezhet olyan konfigurációkkal, amelyek hasonló költségeket eredményeznek, mintha először magasabb szintet választott volna. A magasabb szintek azonban prémium szintű tárterületekkel járnak, ami felgyorsítja az indexelést. A magasabb szintek is sokkal nagyobb számítási teljesítménnyel és extra memóriával rendelkeznek. Ugyanezért a költségekért hatékonyabb infrastruktúrával is rendelkezhet, amely ugyanazt az indexet használja.
A hozzáadott memória egyik fontos előnye, hogy az index több része gyorsítótárazható, ami alacsonyabb keresési késést és nagyobb számú lekérdezést eredményez másodpercenként. Ezzel az extra teljesítménnyel előfordulhat, hogy a rendszergazdának nem kell növelnie a replikák számát, és akár kevesebbet is fizethet, mint az S1 szolgáltatásban.
Tipp: Fontolja meg a reguláris kifejezéses lekérdezések alternatíváit
A reguláris kifejezés-lekérdezések vagy regex különösen költségesek lehetnek. Bár ezek nagyon hasznosak lehetnek a speciális keresésekhez, a végrehajtás sok feldolgozási teljesítményt igényelhet, különösen akkor, ha a reguláris kifejezés bonyolult, vagy ha nagy mennyiségű adatot keres. Mindezek a tényezők hozzájárulnak a magas keresési késéshez. Megoldásként próbálja leegyszerűsíteni a reguláris kifejezést, vagy bontsa le az összetett lekérdezést kisebb, kezelhetőbb lekérdezésekre.
Következő lépések
Tekintse át a szolgáltatás teljesítményével kapcsolatos további cikkeket: