Nagyméretű dokumentumok adattömbje vektorkeresési megoldásokhoz az Azure AI Searchben
A nagyméretű dokumentumok kisebb adattömbökre való particionálása segíthet a modellek beágyazási modelljeinek maximális jogkivonat-beviteli korlátai alatt maradni. Az Azure OpenAI-beágyazási modellek bemeneti szövegének maximális hossza például 8191 token. Mivel minden token körülbelül négy karakterből áll a közös OpenAI-modellek esetében, ez a maximális korlát körülbelül 6000 szó szövegnek felel meg. Ha ezeket a modelleket használja beágyazások létrehozásához, kritikus fontosságú, hogy a bemeneti szöveg a korlát alatt maradjon. A tartalom adattömbökre való particionálása biztosítja, hogy az adatok feldolgozhatók legyenek a vektortárolók feltöltéséhez és a szöveg-vektoros lekérdezések konvertálásához használt beágyazási modellek segítségével.
Ez a cikk az adattömbök különböző megközelítéseit ismerteti. Az adattömb csak akkor szükséges, ha a forrásdokumentumok túl nagyok a modellek által előírt maximális bemeneti mérethez.
Feljegyzés
Ha a vektorkeresés általánosan elérhető verzióját használja, az adatbeíráshoz és -beágyazáshoz külső kódra van szükség, például kódtárra vagy egyéni képességre. A jelenleg előzetes verzióban elérhető integrált vektorizálás nevű új szolgáltatás belső adattömb-adattömb-készítést és beágyazást kínál. Az integrált vektorizálás függőséget vesz fel az indexelők, a készségkészletek, a szövegfelosztási képesség és az AzureOpenAiEmbedding képesség (vagy egyéni képesség) között. Ha nem tudja használni az előzetes verziójú funkciókat, a cikkben szereplő példák alternatív elérési utat biztosítanak.
Gyakori adattömbelési technikák
Íme néhány gyakori adattömbkészítési technika, kezdve a leggyakrabban használt módszerrel:
Rögzített méretű adattömbök: Olyan rögzített méret meghatározása, amely elegendő a szemantikailag értelmezhető bekezdésekhez (például 200 szó), és lehetővé teszi bizonyos átfedéseket (például a tartalom 10-15%-át) jó adattömböket hozhat létre a vektorgenerátorok beágyazásához.
Változó méretű adattömbök tartalom alapján: Az adatok particionálása tartalomjellemzők, például mondatvégi írásjelek, sorvégi jelölők vagy a természetes nyelvi feldolgozási (NLP) kódtárak funkcióinak használatával. A Markdown nyelvi struktúrája az adatok felosztására is használható.
A fenti technikák egyikének testreszabása vagy iterálása. Nagy méretű dokumentumok kezelésekor például használhat változó méretű adattömböket, de a dokumentum címét is hozzáfűzheti a dokumentum közepéről származó adattömbökhöz a környezet elvesztésének elkerülése érdekében.
Tartalomfedés szempontjai
Adattömbök esetén az adattömbök közötti kis mennyiségű szöveg átfedése segíthet megőrizni a környezetet. Javasoljuk, hogy körülbelül 10%-os átfedéssel kezdjen. Ha például egy rögzített adattömbméret 256 jogkivonatot ad meg, 25 token átfedésben kell kezdenie a tesztelést. Az átfedés tényleges mennyisége az adatok típusától és az adott használati esettől függően változik, de megállapítottuk, hogy a 10-15% számos forgatókönyv esetében működik.
Az adattömbökre vonatkozó tényezők
Az adattömbök használatakor gondolja át az alábbi tényezőket:
A dokumentumok alakja és sűrűsége. Ha ép szövegre vagy szakaszokra van szüksége, a nagyobb adattömbök és a mondatszerkezetet megőrző változó adattömbök jobb eredményeket hozhatnak.
Felhasználói lekérdezések: A nagyobb adattömbök és az egymást átfedő stratégiák segítenek megőrizni az adott információkat megcélozó lekérdezések kontextusát és szemantikai gazdagságát.
A nagyméretű nyelvi modellek (LLM) teljesítményre vonatkozó irányelvekkel rendelkeznek az adattömb méretére vonatkozóan. Olyan adattömbméretet kell beállítania, amely az összes használt modell esetében a legjobban működik. Ha például modelleket használ összegzéshez és beágyazáshoz, válasszon egy optimális adattömbméretet, amely mindkettőhöz használható.
Hogyan illeszkedik az adattömb a munkafolyamatba?
Ha nagyméretű dokumentumokkal rendelkezik, be kell szúrnia egy darabolási lépést az indexelési és lekérdezési munkafolyamatokba, amelyek nagy szövegrészeket bontanak fel. Integrált vektorizálás (előzetes verzió) használatakor a rendszer egy alapértelmezett adattömb-stratégiát alkalmaz a szövegfelosztási képesség használatával. Egyéni adattömb-stratégiát is alkalmazhat egyéni szakértelemmel. Egyes adattömböket biztosító kódtárak a következők:
A legtöbb kódtár gyakori adattömb-technikákat biztosít a rögzített mérethez, változómérethez vagy kombinációhoz. Olyan átfedést is megadhat, amely kis mennyiségű tartalmat duplikál az egyes adattömbökben a környezet megőrzése érdekében.
Példák adattömbökre
Az alábbi példák bemutatják, hogyan alkalmazzák az adattömb-stratégiákat a NASA Earth at Night e-book PDF-fájljára:
Példa szövegfelosztási képességre
A Text Split-képességen keresztüli integrált adattömb-készítés nyilvános előzetes verzióban érhető el. Ehhez a forgatókönyvhöz használjon egy előzetes verziójú REST API-t vagy egy Azure SDK-bétacsomagot.
Ez a szakasz a készségalapú megközelítéssel és a szövegfelosztási képességparaméterekkel végzett beépített adattömböket ismerteti.
Ehhez a példához egy mintajegyzetfüzet található az azure-search-vector-samples adattárban.
Állítsa be textSplitMode , hogy kisebb adattömbökre bontsa a tartalmat:
pages(alapértelmezett). Az adattömbök több mondatból állnak.sentences. Az adattömbök egyetlen mondatból állnak. Ami "mondatot" jelent, az nyelvfüggő. Angol nyelven szabványos mondatvégződést használ, például.vagy!használ. A nyelvet adefaultLanguageCodeparaméter vezérli.
A pages paraméter további paramétereket ad hozzá:
maximumPageLengthaz egyes adattömbökben legfeljebb 1 karaktert határoz meg. A szövegelosztó elkerüli a mondatok felosztását, így a tényleges karakterszám a tartalomtól függ.pageOverlapLengthMeghatározza, hogy az előző oldal végétől hány karakter szerepel a következő oldal elején. Ha be van állítva, ennek a maximális oldalhossznak kevesebbnek kell lennie, mint a fele.maximumPagesToTakemeghatározza, hogy hány oldalt/adattömbet kell egy dokumentumból átvenni. Az alapértelmezett érték 0, ami azt jelenti, hogy az összes lapot vagy adattömbet ki kell venni a dokumentumból.
1 A karakterek nem igazodnak a jogkivonat definícióihoz. Az LLM által mért jogkivonatok száma eltérhet a Szöveg felosztása képesség által mért karakterméretétől.
Az alábbi táblázat bemutatja, hogy a paraméterek kiválasztása hogyan befolyásolja a Földből származó teljes adattömbök számát az Éjszakai e-könyvben:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Teljes adattömbszám |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000. | 0 | 85 |
pages |
2000. | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
N.A. | N.A. | 13361 |
Találatok textSplitModepages használata a teljes karakterszámhoz közelítő adattömbök többségében maximumPageLength. Az adattömbkaraktérfogat-szám attól függ, hogy a mondathatárok hol esnek az adattömbbe. Az adattömb jogkivonatának hossza az adattömb tartalmának különbségei miatt változik.
Az alábbi hisztogramok azt mutatják, hogy az adattömb karakterhosszának eloszlása hogyan hasonlítható össze a gpt-35 turbó adattömbök hosszával egy maximumPageLengthtextSplitModepages2000-es és egy pageOverlapLength 500-ból álló szám használatakor a Földön az Éjszakai e-könyvben:

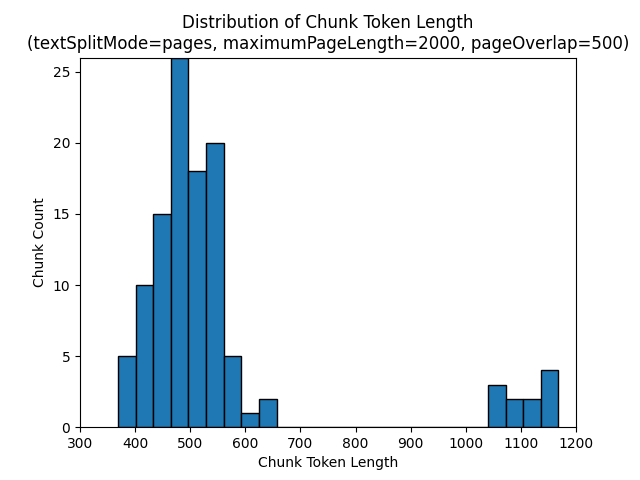
textSplitModesentences Az eredmények nagy számú, egyedi mondatokból álló adattömbben való használata. Ezek az adattömbök jelentősen kisebbek, mint a általuk pageselőállítottak, és az adattömbök tokenszáma jobban megfelel a karakterszámnak.
Az alábbi hisztogramok azt mutatják be, hogy az adattömb karakterhosszának eloszlása hogyan hasonlítható össze a gpt-35-turbo adattömbök hosszával, ha a Föld at Night e-book egyikét textSplitModesentences használja:
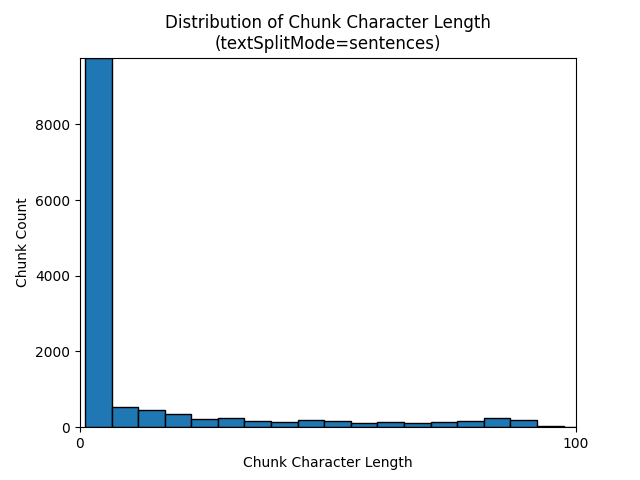
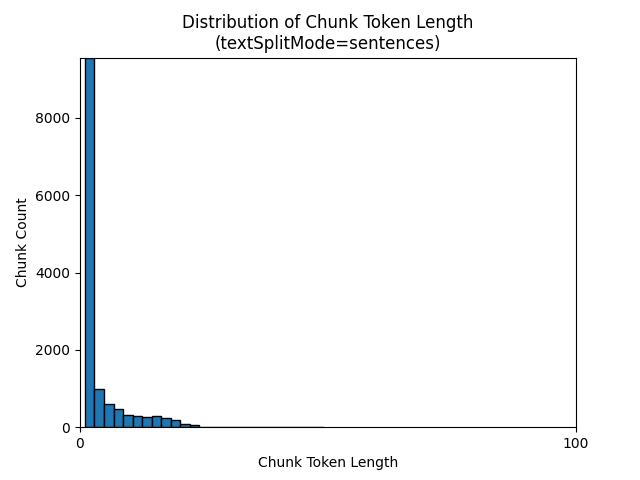
A paraméterek optimális kiválasztása az adattömbök használatától függ. A legtöbb alkalmazás esetében ajánlott az alábbi alapértelmezett paraméterekkel kezdeni:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000. | 500 |
Példa LangChain-adattömbre
A LangChain dokumentumbetöltőket és szövegosztókat biztosít. Ez a példa bemutatja, hogyan tölthet be PDF-fájlokat, hogyan kérhet le jogkivonatokat, és hogyan állíthat be szövegelosztót. A jogkivonatok számának lekérésével megalapozott döntést hozhat az adattömbök méretezéséről.
Ehhez a példához egy mintajegyzetfüzet található az azure-search-vector-samples adattárban.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
A kimenet 200 dokumentumot vagy lapot jelöl a PDF-fájlban.
A lapok becsült tokenszámának lekéréséhez használja a TikTokent.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
A kimenet azt jelzi, hogy egyetlen oldal sem rendelkezik nulla jogkivonattal, az átlagos tokenhossz oldalanként 189 jogkivonat, és a lapok maximális tokenszáma 1583.
Az átlagos és maximális tokenméret ismeretében betekintést nyerhet az adattömb méretének beállításába. Bár a szabványos 2000 karakteres javaslatot 500 karakteres átfedéssel használhatja, ebben az esetben érdemes alacsonyabbra lépni a mintadokumentum tokenszáma alapján. A túl nagy átfedési érték beállítása valójában azt eredményezheti, hogy egyáltalán nem jelenik meg átfedés.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Két egymást követő adattömb kimenete az első adattömb szövegét jeleníti meg, amely átfedésben van a második adattömbtel. A kimenet könnyen szerkeszthető az olvashatóság érdekében.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Egyéni képesség
Egy rögzített méretű adattömb- és beágyazási generációs minta bemutatja az azure OpenAI-beágyazási modellek használatával történő adattömb- és vektorbeágyazási generációt is. Ez a minta egy Egyéni Azure AI Search-készséget használ a Power Skills adattárban az adattömb-lépés burkolásához.