Csatlakozás az Azure Data Explorerhez az Azure Synapse Analyticshez készült Apache Spark használatával
Ez a cikk azt ismerteti, hogyan férhet hozzá egy Azure Data Explorer-adatbázishoz a Synapse Studióból az Apache Spark for Azure Synapse Analyticsszel.
Előfeltételek
- Hozzon létre egy Azure Data Explorer-fürtöt és -adatbázist.
- Rendelkezik egy meglévő Azure Synapse Analytics-munkaterületével, vagy hozzon létre egy új munkaterületet az Azure Synapse-munkaterület létrehozása című rövid útmutató lépéseit követve.
- Hozzon létre egy meglévő Apache Spark-készletet, vagy hozzon létre egy új készletet a rövid útmutató lépéseit követve: Apache Spark-készlet létrehozása az Azure Portal használatával.
- Microsoft Entra-alkalmazás létrehozásához hozzon létre egy Microsoft Entra-alkalmazást.
- Az Azure Data Explorer adatbázis-engedélyeinek kezelésével hozzáférést biztosíthat a Microsoft Entra-alkalmazásnak az adatbázishoz.
Ugrás a Synapse Studióra
Egy Azure Synapse-munkaterületen válassza a Synapse Studio indítása lehetőséget. A Synapse Studio kezdőlapján válassza az Adatok lehetőséget az Adatobjektum-kezelőhöz való ugráshoz.
Azure Data Explorer-adatbázis Csatlakozás egy Azure Synapse-munkaterületre
Az Azure Data Explorer-adatbázis munkaterületre való Csatlakozás egy társított szolgáltatáson keresztül történik. Az Azure Data Explorer társított szolgáltatásával az Azure Synapse-hez készült Apache Sparkból tallózhat és vizsgálhat meg adatokat, olvashat és írhat. Integrációs feladatokat is futtathat egy folyamatban.
Az Adatobjektum-kezelőben kövesse az alábbi lépéseket egy Azure Data Explorer-fürt közvetlen csatlakoztatásához:
Válassza az + Adatok melletti ikont.
A külső adatokhoz való csatlakozáshoz válassza a Csatlakozás lehetőséget.
Válassza az Azure Data Explorer (Kusto) lehetőséget.
Válassza a Folytatás lehetőséget.
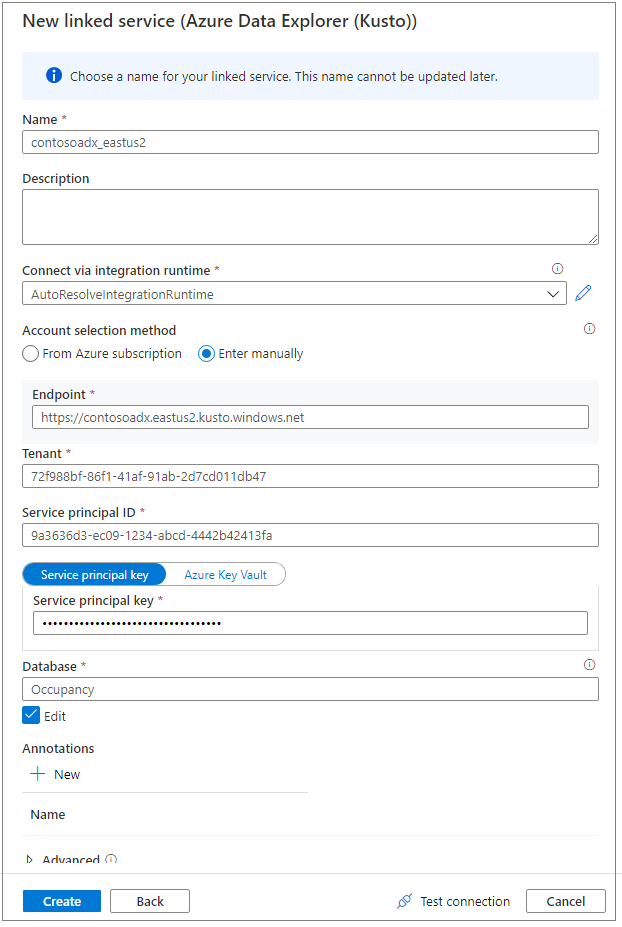
Rövid névvel nevezze el a társított szolgáltatást. A név megjelenik az Adatobjektum-kezelőben, és az Azure Synapse-futtatókörnyezetek használják az adatbázishoz való csatlakozáshoz.
Válassza ki az Azure Data Explorer-fürtöt az előfizetéséből, vagy adja meg az URI-t.
Adja meg a szolgáltatásnév azonosítóját és a szolgáltatásnévkulcsot. Győződjön meg arról, hogy ez a szolgáltatásnév megtekintési hozzáféréssel rendelkezik az adatbázisban az olvasási művelethez és az adatok betöltéséhez való hozzáférés betöltéséhez.
Adja meg az Azure Data Explorer-adatbázis nevét.
Válassza a Kapcsolat tesztelése lehetőséget, és győződjön meg arról, hogy rendelkezik a megfelelő engedélyekkel.
Válassza a Létrehozás parancsot.
Megjegyzés:
(Nem kötelező) A tesztkapcsolat nem ellenőrzi az írási hozzáférést. Győződjön meg arról, hogy a szolgáltatásnév-azonosító írási hozzáféréssel rendelkezik az Azure Data Explorer-adatbázishoz.
Az Azure Data Explorer-fürtök és -adatbázisok az Azure Data Explorer szakasz Csatolt lapján jelennek meg.
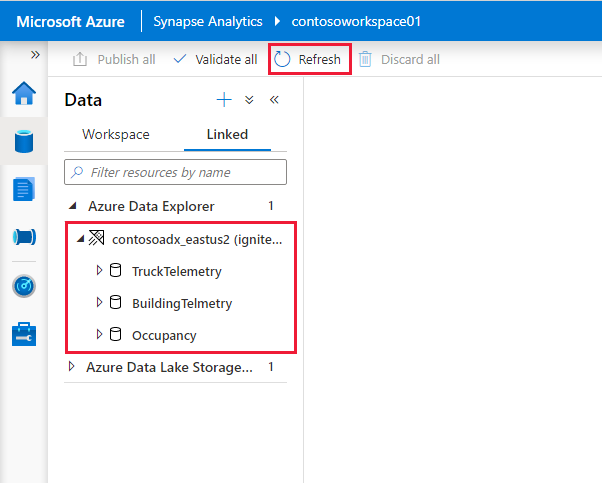
Ahhoz, hogy a csatolt szolgáltatást egy jegyzetfüzetből használhassa, közzé kell tenni a munkaterületen. Kattintson a Közzététel gombra az eszköztáron, tekintse át a függőben lévő módosításokat, és kattintson az OK gombra.
Megjegyzés:
Az aktuális kiadásban az adatbázis-objektumok a Microsoft Entra-fiók engedélyei alapján lesznek feltöltve az Azure Data Explorer-adatbázisokban. Az Apache Spark-jegyzetfüzetek vagy integrációs feladatok futtatásakor a rendszer a hivatkozásszolgáltatás hitelesítő adatait használja (például szolgáltatásnév).
A kód által létrehozott műveletek gyors használata
Amikor a jobb gombbal egy adatbázisra vagy táblára kattint, megjelenik a Spark-mintajegyzetfüzetek listája. Válassza ki az adatok olvasására, írására vagy az Azure Data Explorerbe való streamelésére vonatkozó lehetőséget.

Íme egy példa az adatok olvasására. Csatolja a jegyzetfüzetet a Spark-készlethez, és futtassa a cellát.

Megjegyzés:
Az első végrehajtás több mint három percet vehet igénybe a Spark-munkamenet elindításához. A későbbi végrehajtások jelentősen gyorsabbak lesznek.
Korlátozások
Az Azure Data Explorer-összekötő jelenleg nem támogatott az Azure Synapse által felügyelt virtuális hálózatokban.