Azure Kubernetes hálózati szabályzatok
A hálózati házirendek mikroszegmentációt biztosítanak a podokhoz, csakúgy, mint a hálózati biztonsági csoportok (NSG-k) a virtuális gépek mikroszegmentálását. Az Azure Network Policy Manager implementációja támogatja a Kubernetes szabványos hálózati házirend-specifikációját. Címkék használatával kijelölheti a podok egy csoportját, és meghatározhatja a bejövő és kimenő szabályok listáját a podok felé és onnan érkező forgalom szűréséhez. További információ a Kubernetes hálózati szabályzatairól a Kubernetes dokumentációjában.
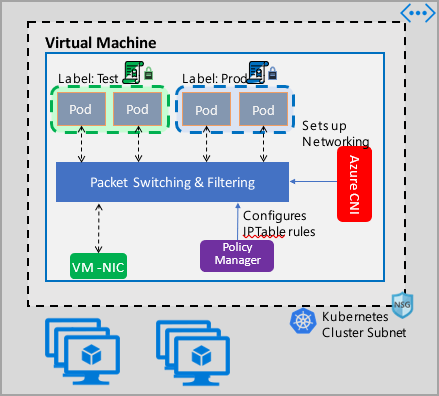
Az Azure Network Policy Management implementációja az Azure CNI-vel működik, amely virtuális hálózati integrációt biztosít a tárolókhoz. A Network Policy Manager linuxos és Windows Server rendszeren is támogatott. Az implementáció úgy kényszeríti ki a forgalomszűrést, hogy engedélyezi és megtagadja az IP-szabályokat a Linux IPTables vagy a Host Network Service (HNS) ACLPolicies for Windows Server meghatározott szabályzatai alapján.
A Kubernetes-fürt biztonságának megtervezése
A fürt biztonságának megvalósításakor használjon hálózati biztonsági csoportokat (NSG-ket) a fürt alhálózatába belépő és onnan kilépő forgalom szűrésére (észak-déli forgalom). Használja az Azure Network Policy Managert a fürt podjai közötti forgalomhoz (kelet-nyugati forgalom).
Az Azure Network Policy Manager használata
Az Azure Network Policy Manager a következő módokon használható a podok mikroszegmentálásának biztosítására.
Azure Kubernetes Service (AKS)
A Network Policy Manager natív módon érhető el az AKS-ben, és a fürt létrehozásakor engedélyezhető.
További információt az Azure Kubernetes Service (AKS) hálózati házirendek használatával történő biztonságos forgalmát ismertető cikkben talál.
Saját kezű (DIY) Kubernetes-fürtök az Azure-ban
A DIY-fürtök esetében először telepítse a CNI beépülő modult, és engedélyezze azt egy fürt összes virtuális gépén. Részletes információ: A beépülő modul üzembe helyezése saját kezűleg üzembe helyezett Kubernetes-fürthöz.
A fürt üzembe helyezése után futtassa az alábbi kubectl parancsot a fürtre beállított Azure Network Policy Manager-démon letöltéséhez és alkalmazásához.
Linux esetén:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Windows esetén:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
A megoldás nyílt forráskód is, és a kód elérhető az Azure Container Networking-adattárban.
Hálózati konfigurációk monitorozása és vizualizációja az Azure NPM használatával
Az Azure Network Policy Manager olyan informatív Prometheus-metrikákat tartalmaz, amelyek lehetővé teszik a konfigurációk monitorozását és jobb megértését. Beépített vizualizációkat biztosít az Azure Portalon vagy a Grafana Labsban. Ezeket a metrikákat az Azure Monitor vagy egy Prometheus-kiszolgáló használatával kezdheti el gyűjteni.
Az Azure Network Policy Manager-metrikák előnyei
A felhasználók korábban csak a hálózati konfigurációjukat iptables ismerhették meg, és ipset a parancsok egy fürtcsomóponton belül futnak, ami részletes és nehezen érthető kimenetet eredményez.
A metrikák összességében a következőt biztosítják:
Szabályzatok, ACL-szabályok, ipsetek, ipset-bejegyzések és bejegyzések száma egy adott ipsetben
Az egyes operációsrendszer-hívások végrehajtási ideje és a Kubernetes-erőforrásesemények kezelése (medián, 90. percentilis és 99. percentilis)
Hibainformációk a Kubernetes-erőforrásesemények kezeléséhez (ezek az erőforrásesemények az operációs rendszer hívásának sikertelensége esetén meghiúsulnak)
Példa metrikák használati eseteire
Riasztások Prometheus AlertManageren keresztül
Tekintse meg a riasztások konfigurációját az alábbiak szerint.
Riasztás, ha a Network Policy Manager operációsrendszer-hívással vagy hálózati házirend fordításával kapcsolatos hibát észlelt.
Riasztás, ha a létrehozási esemény módosításainak alkalmazásának mediánja több mint 100 ezredmásodperc volt.
Vizualizációk és hibakeresés a Grafana-irányítópulton vagy az Azure Monitor-munkafüzeten keresztül
Megtudhatja, hogy a szabályzatok hány IPTables-szabályt hoznak létre (ha nagy számú IPTables-szabályt használ, az kismértékben növelheti a késést).
A fürtszámokat (például ACL-eket) korrelálja a végrehajtási időpontokkal.
Egy ipset emberbarát nevének lekérése egy adott IPTables-szabályban (például
azure-npm-487392a következőt jelölipodlabel-role:database).
Minden támogatott metrika
Az alábbi lista támogatott metrikákat tartalmaz. Bármely quantile címke lehetséges értékekkel 0.5rendelkezik, 0.9és 0.99. Bármely had_error címke rendelkezik lehetséges értékekkel false , és trueazt jelzi, hogy a művelet sikeres volt-e vagy sikertelen volt.
| Metrika neve | Leírás | Prometheus metrika típusa | Labels |
|---|---|---|---|
npm_num_policies |
hálózati szabályzatok száma | Kijelző | - |
npm_num_iptables_rules |
IPTables-szabályok száma | Kijelző | - |
npm_num_ipsets |
IPS-halmazok száma | Kijelző | - |
npm_num_ipset_entries |
IP-címbejegyzések száma az összes IPS-halmazban | Kijelző | - |
npm_add_iptables_rule_exec_time |
futtatókörnyezet IPTables-szabály hozzáadásához | Összesítés | quantile |
npm_add_ipset_exec_time |
futtatókörnyezet IPS-halmaz hozzáadásához | Összesítés | quantile |
npm_ipset_counts (speciális) |
az egyes IPS-halmazokon belüli bejegyzések száma | GaugeVec | set_name & set_hash |
npm_add_policy_exec_time |
futtatókörnyezet hálózati szabályzat hozzáadásához | Összesítés | quantile & had_error |
npm_controller_policy_exec_time |
futtatókörnyezet hálózati szabályzat frissítéséhez/törléséhez | Összesítés | quantile > had_erroroperation (értékekkel update vagy delete) |
npm_controller_namespace_exec_time |
futtatókörnyezet névtér létrehozásához/frissítéséhez/törléséhez | Összesítés | quantile > had_erroroperation (értékekkel create, updatevagy delete) |
npm_controller_pod_exec_time |
futtatókörnyezet pod létrehozásához/frissítéséhez/törléséhez | Összesítés | quantile > had_erroroperation (értékekkel create, updatevagy delete) |
Az egyes "exec_time" összefoglaló metrikákhoz "exec_time_count" és "exec_time_sum" metrikák is tartoznak.
A metrikák lekaparhatók az Azure Monitoron tárolókhoz vagy a Prometheuson keresztül.
Beállítás az Azure Monitorhoz
Az első lépés az Azure Monitor engedélyezése a Kubernetes-fürt tárolóihoz. A lépések az Azure Monitor for Containers áttekintésében találhatók. Ha engedélyezte az Azure Monitor for Containers szolgáltatást, konfigurálja a tárolókhoz készült Azure Monitor konfigurációtérképét a Network Policy Manager integrációjának és a Prometheus Network Policy Manager-metrikák gyűjteményének engedélyezéséhez.
Az Azure Monitor for Containers ConfigMap rendelkezik egy integrations , a Network Policy Manager-metrikák gyűjtésére szolgáló beállításokkal rendelkező szakaszsal.
Ezek a beállítások alapértelmezés szerint le vannak tiltva a konfigurációtérképen. Az alapbeállítás collect_basic_metrics = trueengedélyezésével alapszintű Network Policy Manager-metrikákat gyűjt. A speciális beállítás collect_advanced_metrics = true engedélyezése az alapszintű metrikák mellett speciális metrikákat is gyűjt.
A ConfigMap szerkesztése után mentse helyileg, és alkalmazza a ConfigMap-ot a fürtre az alábbiak szerint.
kubectl apply -f container-azm-ms-agentconfig.yaml
A következő kódrészlet az Azure Monitor for Containers ConfigMap-ból származik, amely a Speciális metrikák gyűjteményével engedélyezett Network Policy Manager-integrációt mutatja be.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
A speciális metrikák megadása nem kötelező, és a bekapcsolásuk automatikusan bekapcsolja az alapszintű metrikák gyűjteményét. A speciális metrikák jelenleg csak Network Policy Manager_ipset_countsa .
További információ az Azure Monitor tárolók gyűjteménybeállításairól a konfigurációs térképen.
Az Azure Monitor vizualizációs beállításai
Ha engedélyezve van a Network Policy Manager metrikagyűjteménye, megtekintheti a metrikákat az Azure Portalon a container insights vagy a Grafana használatával.
Megtekintés az Azure Portalon a fürt elemzési adatai alatt
Nyissa meg az Azure Portalt. Miután a fürt megállapításaiba betekintett, lépjen a Munkafüzetek elemre, és nyissa meg a Network Policy Manager (Network Policy Manager) konfigurációját.
A munkafüzet megtekintése mellett közvetlenül is lekérdezheti a Prometheus-metrikákat a "Naplók" szakaszban az elemzések szakaszban. Ez a lekérdezés például az összes összegyűjtött metrikát visszaadja.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
A naplóelemzéseket közvetlenül is lekérdezheti a metrikákhoz. További információ: A Log Analytics-lekérdezések használatának első lépései.
Megtekintés a Grafana irányítópulton
Állítsa be a Grafana-kiszolgálót, és konfiguráljon egy log analytics-adatforrást az itt leírtak szerint. Ezután importálja a Grafana-irányítópultot egy Log Analytics-háttérrendszerrel a Grafana Labsba.
Az irányítópulton az Azure-munkafüzethez hasonló vizualizációk vannak. A Elemzések Metrics tábla Network Policy Manager-metrikáit ábrázoló diagramhoz hozzáadhat paneleket.
Beállítás a Prometheus-kiszolgálóhoz
Egyes felhasználók dönthetnek úgy, hogy a tárolókhoz készült Azure Monitor helyett prometheus-kiszolgálóval gyűjtenek metrikákat. Csak két feladatot kell hozzáadnia a kaparó konfigurációjához a Network Policy Manager-metrikák gyűjtéséhez.
Prometheus-kiszolgáló telepítéséhez adja hozzá ezt a helm-adattárat a fürthöz:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
majd adjon hozzá egy kiszolgálót
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
ahol prometheus-server-scrape-config.yaml a következőkből áll:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
A feladatot a azure-npm-node-metrics következő tartalomra is lecserélheti, vagy beépítheti egy már meglévő feladatba a Kubernetes-podokhoz:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Riasztások beállítása a AlertManagerhez
Ha Prometheus-kiszolgálót használ, beállíthatja a AlertManagert. Íme egy példakonfiguráció a korábban ismertetett két riasztási szabályhoz:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
A Prometheus vizualizációs beállításai
Prometheus-kiszolgáló használata esetén csak a Grafana-irányítópult támogatott.
Ha még nem tette meg, állítsa be a Grafana-kiszolgálót, és konfiguráljon egy Prometheus-adatforrást. Ezután importálja a Grafana-irányítópultot egy Prometheus háttérrendszerrel a Grafana Labsba.
Az irányítópult vizualizációi megegyeznek a tárolóelemzési/log analytics-háttérrendszerrel rendelkező irányítópulttal.
Minta-irányítópultok
Az alábbiakban néhány minta irányítópultot böngészünk a Network Policy Manager-metrikákhoz a tárolóelemzésekben (CI) és a Grafana-ban.
CI-összefoglalók száma
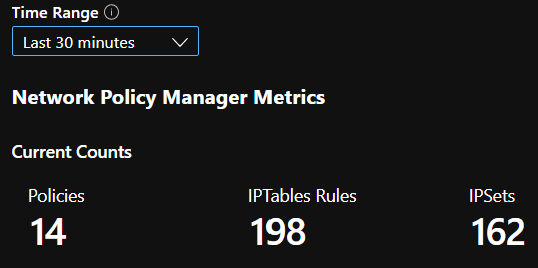
CI-szám az idő függvényében

CI IPSet-bejegyzések

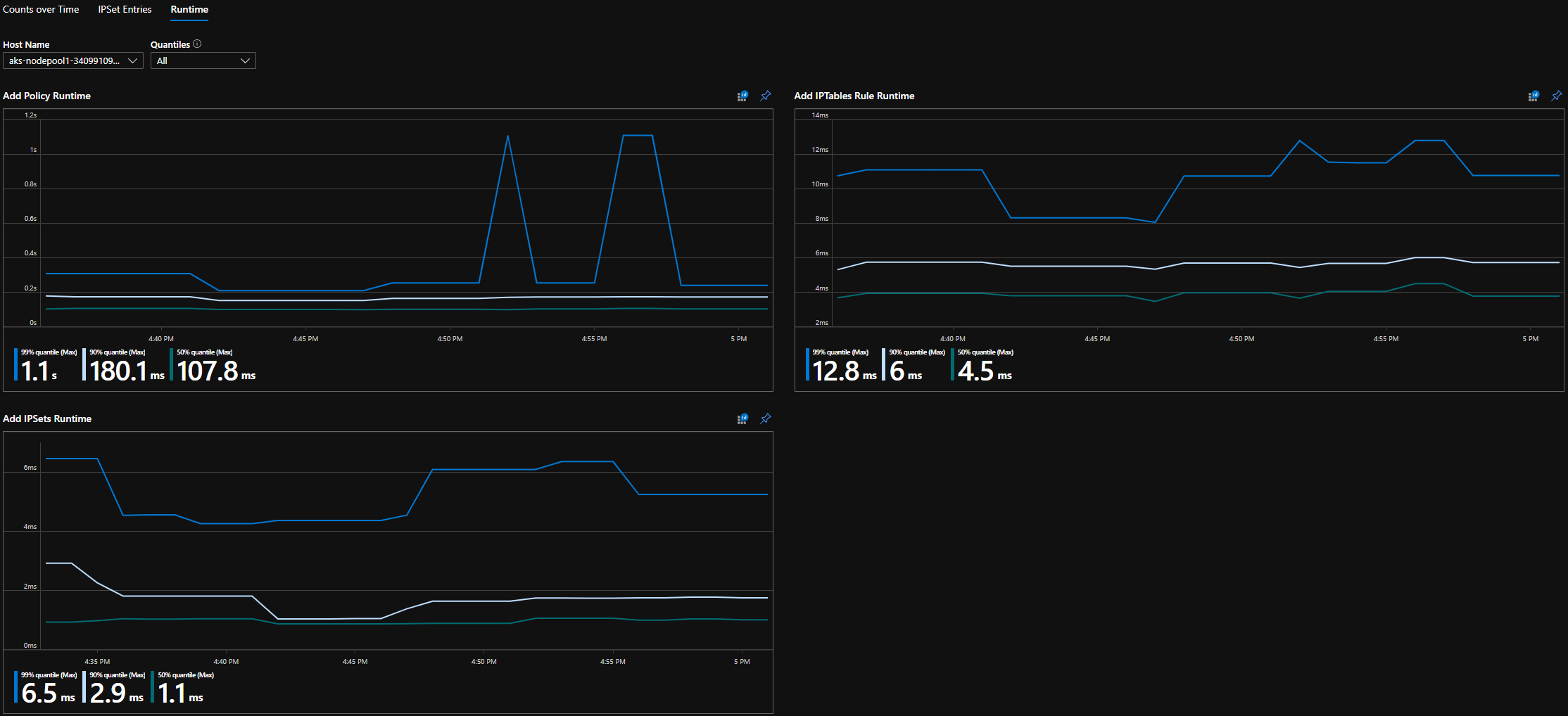
CI-futtatókörnyezeti kvantilisek
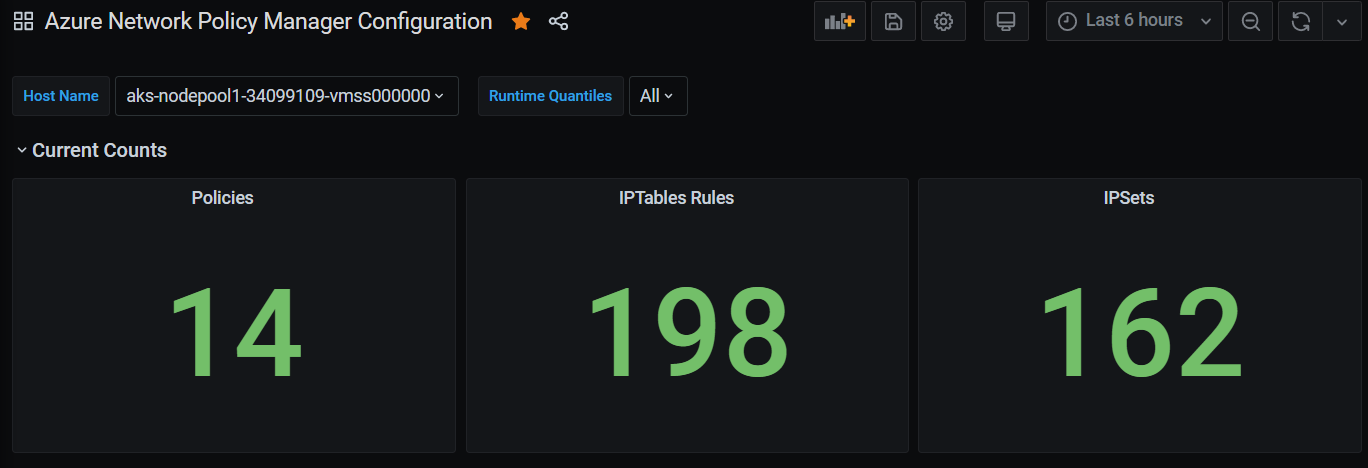
A Grafana-irányítópult összesítési száma
A Grafana-irányítópultok száma az idő függvényében

Grafana irányítópult IPSet-bejegyzései

Grafana irányítópult futtatókörnyezetének kvantitásai
