Bevezetés
Napjainkban exponenciálisan terjednek a gépi tanulással és adatbányászattal (MLDM) kapcsolatos problémák. Ezzel együtt növekszik az igény az olyan elemzési motorok iránt, amelyek hatékonyan képesek MLDM-algoritmusokat végrehajtani olyan elosztott rendszereken, mint a felhők. Az elosztott MLDM-alkalmazások tervezését, implementálását és tesztelését megnehezíti, hogy általában olyan szakértőket igényel, akik képesek hatékonyan kezelni a szinkronizálás, a holtpontok, a kommunikáció, az ütemezés, az elosztottállapot-kezelés és a hibatűrés szempontjait. Az MLDM-algoritmusok tervezésének sok közelmúltbeli eredménye épül az ilyen algoritmusok gráfként modellezésére.
Adatok és számítások kifejezése gráf-absztrakcióval
Vizsgáljuk meg a gráfként modellezett adatok néhány példáját, és hogy hogyan fejezhetők ki a számítások ebben a modellben. Matematikailag egy gráf egy $G = \lbrace V, E \rbrace$ halmazként van modellezve, ahol $V$ a $v_{i}$ csúcsok halmaza, $E$ pedig az $e_{i}$ élek halmaza. Továbbá minden $G$-beli $e_{i}$ él egy pontosan két csúcs, $\lbrace v_{i}, v_{j} \rbrace \in V$ közötti élet jelent. A gráfoknak több változata létezik: lehetnek irányítatlanok, ami azt jelenti, hogy $e = \lbrace v_{i}, v_{j} \rbrace = \lbrace v_{j}, v_{i} \rbrace \forall e \in E$ (tehát minden él ekvivalens és kétirányú), vagy irányítottak, ahol az élek különböznek, nem egyenlők. A gráfok súlyozhatók is egy további paraméter, a minden élhez ($\forall e \in E$) hozzárendelt úgynevezett súly ($w_{i}$) bevezetésével. Ezen kívül a csúcsok is súlyozhatók. Látni fogjuk, hogy ez hasznos lehet a különféle alkalmazásokban. A gráfokkal kapcsolatos tipikus számítások közé tartozik sok más mellett a két csúcs közötti legrövidebb út kiszámítása, a gráf részgráfokra való felosztása valamilyen optimalizálási metrika (például a megszakított élek minimális száma vagy gráfok közötti maximális értékű folyam) alapján, és a maximális fokszám (a legtöbb élhez tatozó csúcs) meghatározása.
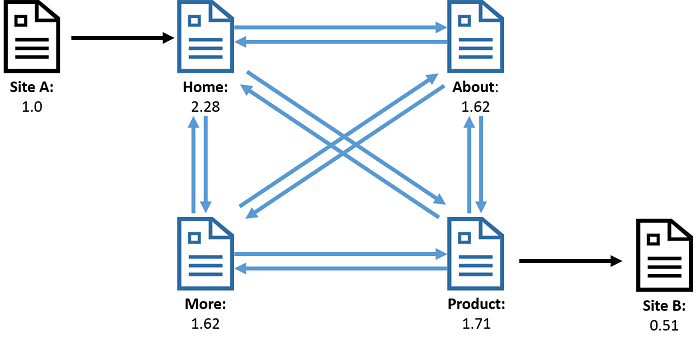
1. ábra: Egy webgráf, ahol a csúcsok weblapokat, a szélek pedig a lapok közötti kapcsolatokat jelölik. A PageRank ezen a gráfon történő futtatásának eredményeként minden csúcshoz hozzá lesz rendelve egy érték, az úgynevezett rang, amely a lap fontosságát jellemzi. A rang a lapra mutató és onnan kiinduló hivatkozások számából van kiszámítva.
Az ábra a webgráfra mutat be egy példát. A csúcsok weblapokat jelölnek, az élek pedig a weblapok közötti hivatkozásokat. A webgráfon végzett számítások kanonikus példája a PageRank, amely egy weblap fontosságát számítja ki a hivatkozással hozzá kapcsolódó lapok alapján. A 2. ábrán látható kapcsolati hálózat személyeket ábrázol csúcsokként, élekként pedig olyan kapcsolatokat, mint a „barát” vagy „követő”. Az érdekesebb számítások közé tartozik a legnépszerűbb személyek (a legtöbb élhez tartozó csúcsok) keresése, vagy az olyan szorosan összetartozó közösségeké, amelyekben mindenki mindenkit ismer (háromszögszámlálás).
2. ábra: A Facebook közösségi grafikonjának vizualizációja korlátozott számú felhasználó számára. (Forrás)
Belátható, hogy a fentiekben említett problémák egy része méretét és összetettségét tekintve is egyre nagyobb. A nyilvánosan elérhető legnagyobb webgráfok egyike 1,7 milliárd weblapból és 64 milliárd hivatkozásból áll. Sokak szerint ez is sokkal kevesebb az olyan webszolgáltató vállalatok éles rendszereiben kezelt adatmennyiségnél, mint a Google és a Microsoft. Ennyi adatot lehetetlen volna egyetlen számítógép memóriájában elhelyezni, mégis szükség van egy hatékony rendszerre, amely képes megbirkózni egy ekkora adattömeg feldolgozásával.
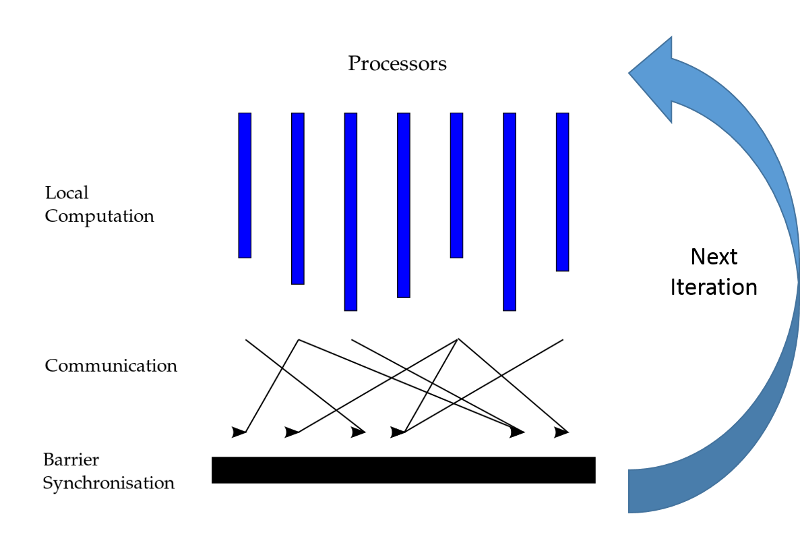
3. ábra: A tömeges szinkron párhuzamos (BSP) párhuzamos paradigma
A nagy gráfok elosztott feldolgozására tervezett rendszerekre példa a Google Pregel rendszere. A Pregel iteratív, összehangolt módon végez számításokat gráfokon (ezt nevezik szinkronizált párhuzamos, röviden BSP-módszernek). A Pregel-programok globálisan szinkronizált iterációk sorozatát futtatják, amelyek eredményeként bizonyos számítások lesznek elvégezve egy gráf minden csúcsának kontextusában (3. ábra). A csúcsok ez után üzeneteket válthatnak a szomszédaikkal; ez általában az állapot vagy más változók frissítését jelenti. A Pregel akkor futtatja le a következő iterációt, ha már minden csúcs végzett az aktuális végrehajtás feldolgozásával. A gépek között az $i$ iterációban váltott üzenetek az $i + 1$ iterációban lesznek kézbesítve. A program addig futtat egymást követő iterációkat, amíg egy konvergenciafeltétel nem teljesül, vagy végre nem hajt $N$ iterációt, ahol $N$ a végrehajtandó iterációknak a felhasználó által definiált maximális száma.
Bár a Pregel ígéretes lehetőséget kínál elosztott, gráf-párhuzamos elemzési motorként, jelentős hiányosságot szenved: a Pregel szinkron módon futtatja a számításokat, ami hatással lehet a teljesítményre, mivel az egyes iterációk futásidejét mindig az utolsó szál határozza meg a végrehajtás befejezéséhez. Elképzelhető, hogy milyen következményekkel jár, ha egy gráfban nem egyenletes a csúcsok fokszáma. A big data elemzések szempontjából érdekes gráfok többsége esetében éppen ez a helyzet. A szociális gráfok például exponenciális eloszlást mutatnak, tehát nagyon kevés csúcshoz csatlakozik nagyon sok él. Erre a jelenségre példa a Twitter követési gráfja (4. ábra), ahol a hírességeknek és a befolyásos személyeknek több millió követőjük van, a többi felhasználó többségét pedig kevesen követik.
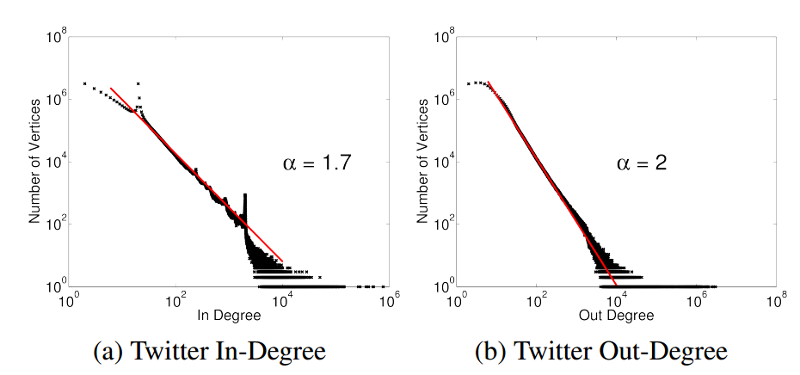
4. ábra: Power-law eloszlás a Twitter követő grafikonon. Figyelje meg, hogy egy kis számú csúcspont (<100) nagyon magas fokban és felsőfokú (>10 000)1
Ez a modul a gráfalapú párhuzamos elosztott elemzési motor egy változatát, a GraphLabot mutatja be, amely a szinkron és aszinkron MLDM- és más problémákat is képes hatékonyan és helyesen kezelni. A GraphLab exponenciális eloszlást mutató gráfokhoz is jól alkalmazható.
Ez a modul:
- Ismerteti az adatstruktúrát, amelyben a GraphLab által felhasználandó és feldolgozandó bemeneti gráfokat tárolni kell.
- Bemutatja, hogyan haladnak át a bemeneti gráfok a GraphLab-motoron a fogyasztástól az eredmények előállításáig.
- Bemutatja a GraphLab architekturális modelljét.
- Bemutatja a GraphLab által alkalmazott programozási modellt, valamint a megosztott adatok olvasás-írás/írás-írás ütközésekkel szembeni védelméhez támogatott konzisztencia-mechanizmusokat.
- Ismerteti a GraphLab alapját képező aszinkron számítási modellt.
- Megvizsgálja a GraphLab hibatűrési technikáit.
Tanulási célkitűzések
Ebben a modulban a következőkkel foglalkozunk:
- A GraphLab egyedi jellemzői és az általa megcélzott alkalmazástípusok leírása
- A gráfalapú párhuzamos és elosztott programozási keretrendszerek jellemzői
- A GraphLab-motor három fő összetevője
- A GraphLab végrehajtási motorja által érintett lépések leírása
- A GraphLab architekturális modelljének ismertetése
- A GraphLab ütemezési stratégiája
- A GraphLab programozási modelljének ismertetése
- A GraphLab konzisztencia-szintjeinek felsorolása és magyarázata
- A GraphLab memóriabeli adatelhelyezési stratégiája, és annak a bizonyos gráftípusok esetében a teljesítményre gyakorolt hatása
- A GraphLab számítási modelljének bemutatása
- A GraphLab hibatűrési mechanizmusainak ismertetése
- A GraphLab-programok végrehajtása során érintett lépések azonosítása
- A MapReduce, a Spark és a GraphLab hasonlóságainak és különbségeinek kiemelése azok programozási, számítási, párhuzamossági, architekturális és ütemezési modelljeinek szempontjából
- A megfelelő elemzési motor kiválasztása egy alkalmazás jellemzői alapján
Előfeltételek
- A felhőalapú számítástechnika, a felhőszolgáltatás-modellek és felhőszolgáltatók fogalmának ismerete
- A felhőalapú számítást lehetővé tevő technológiák megismerése
- Annak ismerete, hogy a felhőszolgáltatók hogyan fizetnek és számláznak a felhőhasználatért.
- Megtudhatja, mik azok az adatközpontok, és hogy mire valók
- Megtudhatja, hogyan lehet az adatközpontokat beállítani, üzemeltetni és kiépíteni
- Megtudhatja, hogyan lehet a felhőerőforrásokat kiépíteni és mérni
- A virtualizálás fogalmának ismerete
- A különböző virtualizációs típusok ismerete
- A CPU-virtualizálás ismerete
- A memória virtualizálásának ismerete
- Az I/O-virtualizálás ismerete
- A különböző adattípusok és azok tárolásának ismerete
- Az elosztott fájlrendszerek és azok működésének ismerete
- A NoSQL-adatbázisok, az objektumtárolás és ezek működésének ismerete
- Annak ismerete, hogy mit jelent az elosztott programozás, illetve hogy miért hasznos a felhőben
- A MapReduce és annak ismertetése, hogy a MapReduce hogyan teszi lehetővé a big data-számításokat
- A Spark ismertetése és a MapReduce-tól való eltérés
Hivatkozások
- J. Gonzalez, Y. Low, H. Gu, D. Bickson és C. Guestrin (2012. október). PowerGraph: Elosztott gráf-párhuzamos számítás természetes gráfokon az operációs rendszerek tervezéséről és implementálásáról szóló 10. U Standard kiadás NIX konferencia során