Adatstruktúra és gráffolyamat
A Carnegie Mellon Egyetem által kifejlesztett GraphLab a felhőben használható gráfalapú párhuzamos elosztott elemzési motorok egyike. A többi gráfalapú párhuzamos motorhoz hasonlóan a GraphLab is feltételezi, hogy a bemenő problémák gráfként vannak modellezve, amelyben a csúcsok a számításoknak felelnek meg, az élek pedig az adatfüggőségeket vagy a kommunikációt kódolják.
A GraphLab fejlődése és verziói
A GraphLab-et eredetileg megosztott memóriarendszerekhez (sokmagos gépekhez) szánt gráffeldolgozási keretrendszerként fejlesztették ki1. A GraphLab ezután egy elosztott végrehajtási motort is tartalmazott, amely lehetővé teszi a rendkívül nagy gráfok számítását egy gépcsoporton.2A PowerGraph3 (más néven GraphLab 2.0) olyan technikákkal jelent meg, amelyek lehetővé tették a hatalmi jog szerinti eloszlást követő gráfok (például közösségi gráfok) gyorsabb elosztott feldolgozását. A GraphLab egy változata azóta a Dato Inc. kereskedelmi startup vállalathoz került, amely a GraphLab Create szoftvercsomagot kínálja. A GraphLab ismertetése ebben a modulban a legfrissebb nyílt forráskódú verzióra, a PowerGraphra (GraphLab 2.0) vonatkozik.
A GraphLab-ben a fájlok kezdetben fájlokként vannak tárolva egy mögöttes elosztott (például HDFS) tárolási rétegben, ahogyan az 5. ábrán látható. A GraphLab két fázisból áll: inicializálás és végrehajtás. Az inicializálás során a GraphLab-motor beolvassa a bemeneti gráffájlokat a mögöttes tárolóból, és több partícióra osztja azokat, amelyek eloszthatók a fürt több gépe között. A végrehajtási fázisban minden gép a felhasználó által definiált számításokat futtatja a gráf csúcsain, továbbítja a frissítéseket, és ezt valamely konvergencia-feltétel teljesülésig iterálja.
Inicializálási fázis
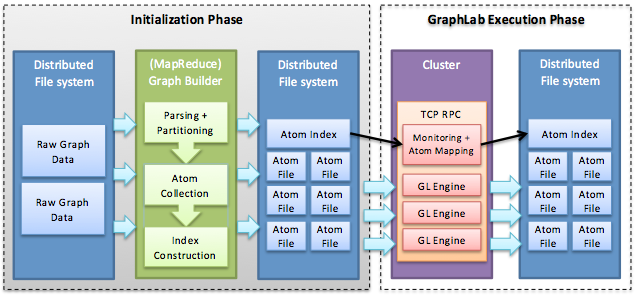
5. ábra: A GraphLab rendszer. Az inicializálási fázisban az atomok (például) a MapReduce használatával vannak felépítve. A GraphLab végrehajtási fázisában az atomok a fürt gépeihez vannak rendelve, és a gépek betöltik azokat egy elosztott fájlrendszerből (HDFS).
Az első fázisban a bemeneti gráf k partícióra, úgynevezett atomra van felosztva, ahol k sokkal nagyobb a fürt gépeinek számánál. Az atomok az 5. ábrán bemutatott módon soros vagy párhuzamos betöltési módszerrel, például a MapReduce segítségével is felépíthetők. A GraphLab nem a tényleges csúcsokat és éleket tárolja az atomokban, hanem az azokat generáló parancsokat egy napló formájában. A GraphLab így a csomópontok meghibásodása esetén képes rekonstruálni a gráf egyes részeit. A GraphLab emellett minden atomban megőriz a szomszédos csúcsokra és élekre vonatkozó információkat. Ez a GraphLab szóhasználatával szellemcsúcsoknak nevezett információ a szomszédossági adatok elérhetőségét szolgáló gyorsítótárazási képességet biztosít.
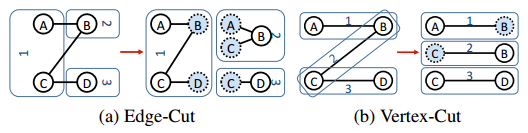
6. ábra: Gráfparticionálási stratégiák. (a) az élvágási particionálási technikát, (b) pedig a csúcsvágási technikát mutatja be.
A gráf többféleképpen particionálható a fürt gépein (6. ábra). Egy egyszerű technika az élvágás, amely a csúcsok mentén particionálja a gráfot (6.(a) ábra). Minden csúcs véletlenszerűen van egy géphez rendelve a hozzá tartozó összes éllel együtt. Emiatt szellemcsúcsok lesznek generálva, hogy az élek társíthatók legyenek a nem az adott gépen lévő csúcsokkal. Ez azonban az olyan gráfok esetében, ahol az élek eloszlása exponenciális, kiegyensúlyozatlan particionáláshoz vezet, és egyes gépek terhelése nagyobb lesz a többiénél (a néhány csúcsnál kialakuló csillagszerű elrendezés miatt). Az ilyen gráfokat a GraphLab egy új technikával (az úgynevezett mohó csúcsvágással) kezeli, és a számítások hatékonyabb elosztása érdekében a nagy fokszámú csúcsokat több gépnek osztja szét. A nagy fokszámú csúcsok több gépen lesznek replikálva, melyek mindegyike az adott csúcshoz tartozó élek egy részhalmazát kapja meg (6.(b) ábra). Azt, hogy egy csúcs egy adott élét melyik gép kapja meg, az alábbi algoritmus határozza meg:
1. algoritmus
Mohó élvágások a $v_{i}$ csúcshoz tartozó $e = \lbrace v_{i}, v_{j} \rbrace$ él elhelyezéséhez:
Ha létezik olyan gép, amelyhez a $v_{i}$ és a $v_{j}$ csúcs is hozzá van rendelve, akkor
- $v_{j}$ legyen ehhez a géphez rendelve
egyébként, ha $v_{i}$ és $v_{j}$ más gépekhez van rendelve, akkor
- $e$ legyen ahhoz a géphez rendelve, amelyhez a legkevesebb él van hozzárendelve
egyébként
- $e$ legyen a legkisebb terhelésű géphez rendelve
$e$ legyen megjelölve kiosztottként
Ezeknek a partícióknak a betöltése elosztott és összehangolt módon megvalósítható, ez pedig biztosítja, hogy a csúcsok és élek optimálisan vannak kiosztva a fürtben, a betöltéshez szükséges idő azonban sokkal hosszabb, mint véletlenszerű elhelyezés esetén. A véletlenszerű elhelyezés viszont kiegyenlítetlen terheléshez és a lokalitás elvesztéséhez vezet. A két megközelítés közötti kompromisszum, amely szerint minden gép megbecsüli a fürt széleinek és csúcsainak hozzárendelését, a "PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs" című témakörben javasolt kompromisszum.3
A felhasználóknak viszont olyan formátumokban kell tárolniuk a gráfokat, amelyeket a GraphLab képes felhasználni és feldolgozni az inicializálási fázisban. Ez nyilván a mögöttes tárolási rétegtől és a GraphLab által alkalmazott feldolgozó motortól függ. Ha például a bemeneti gráffájlok a MapReduce használatával vannak beolvasva a HDFS-ből, ehhez a MapReduce kulcs-érték adatstruktúrájával formázott gráffájlok szükségesek.
Az adott bemeneti gráf atomjainak generálásával befejeződik a GraphLab particionálási stratégiájának első fázisa. A motor ettől kezdve egy metagráfnak is nevezett indexfájlban tárolja a kapcsolatstruktúrát és az atomok helyét (5. ábra). Az atomindex-fájl k csúcsot foglal magában, melyek mindegyike egy atomnak felel meg, a köztük lévő kapcsolatokat kódoló élekkel együtt. A második fázisban az atomindex-fájlt egyenletesen felosztja a fürt gépei között. Az atomok ez után be lesznek töltve a fürt gépeire, és mindegyik gép felépíti a gráf rá jutó egy vagy több partícióját a hozzá rendelt atomok naplójának végrehajtásával. Azzal, hogy a partíciókat az atomnaplókból generálja (nem pedig közvetlenül képez le partíciókat a fürtbeli gépekre) a GraphLab lehetővé teszi, hogy a gráf későbbi módosításait egyszerűen hozzá lehessen fűzni a napló parancsaihoz anélkül, hogy az egész gráfot újra kellene particionálni. Emellett ugyanazok a gráfatomok eltérő méretű fürtökben is újra felhasználhatók a megfelelő atomindex-fájl egyszerű újraosztásával és az atomnaplók ismételt végrehajtásával, tehát csupán a második particionálási fázis megismétlésével.
A gráfpartícióknak a fürt gépein történő felépítésével befejeződik a GraphLab inicializálási fázisa, és megkezdődik a végrehajtási fázis.
Végrehajtási fázis
Ahogyan az 5. ábrán látható, minden fürtbeli gép a GraphLab-motor egy példányát futtatja, amely két fő részből áll: az adatgráfból és az adatgráfon értelmezett, felhasználó által definiált függvényekből. Az adatgráf a felhasználói program állapotának felel meg a fürt adott gépén, és tartalmaz egy $G = (V, E, D)$ irányított gráfot, amelyben $V$ a csúcsok halmaza, $E$ az élek halmaza, $D$ pedig felhasználói adat (paraméterek, felhasználói bemeneti adatok és statisztikai adatok). A GraphLab-ben az adatok csúcsokhoz és élekhez is társulnak.
A számítások egy állapot nélküli program formájában jelennek meg, amely a gráf összes csúcsán párhuzamosan van végrehajtva. Ez a program három különböző fázisból áll: Összegyűjtés, Alkalmazás és Pont (GAS).
Gyűjtési fázis: Az adatgyűjtési fázisban minden csúcs (a továbbiakban: központi csúcs) információkat gyűjt a szomszédos csúcsokról és élekről. A GraphLab ekkor egy felhasználó által definiált összesítési vagy összegzési műveletet hajthat végre:
$$\Sigma \leftarrow \bigoplus_{\substack{v \in Nbr[u]}} g(D_{u}, D_{u, v}, D_{v})$$
A fenti egyenletben $D_{u}$, $D_{v}$ és $D_{u, v}$ az $u$, $v$ csúcs illetve az $(u, v)$ él értékeit és metaadatait jelöli. A felhasználó által definiált ($\bigoplus$) műveletnek kommutatívnak és asszociatívnak kell lennie, és a numerikus összeadástól az összes szomszédos csúcs és él adatainak uniójáig sokféle lehet.
Alkalmazási fázis: Az alkalmazás fázisában az eredményül kapott $\Sigma$ érték a központi csúcs értékének frissítésére szolgál:
$$D_u^{new} \leftarrow a(D_{u}, \Sigma)$$
Pontfázis: Végül a pontfázisban a központi csúcs új értékét a rendszer elküldi az összes szomszédos csúcsnak:
$$\forall v \in Nbr[u]:(D_{(u, v)}) \leftarrow s(D_u^{new}, D_{u, v}, D_{v})$$
A szórási művelettel véget ér a csúcs számításainak egy iterációja.
A GAS függvények minden iterációban az aktív csúcsok egy halmazán vannak végrehajtva. A kezdeti iteráció során minden csúcs az aktív csúcsok halmazában van elhelyezve. Egy csúcs a GAS függvények logikája alapján aktívként jelölheti meg egyik szomszédját, hogy azon számítást lehessen végezni a következő iterációban.
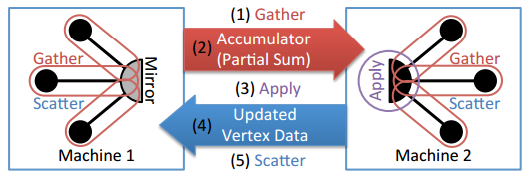
7. ábra: Az Adatgyűjtés, Alkalmazás, Pont függvény végrehajtása két gépen, amelyek ugyanazon csúcs éleinek egy részhalmazát képezik.
Az ábra a korábban ismertetett mohó élvágási algoritmussal particionált gráfon alkalmazott GAS függvények alkalmazása következtében kialakuló kommunikáció mintázatát szemlélteti. A begyűjtési függvények helyileg futnak minden olyan gépen, amely tartalmazza egy csúcs szellemét. Az összesítés során ezek a begyűjtött értékek a csúcs fő példányát tartalmazó géphez lesznek elküldve, ahol kiszámítható az alkalmazási fázisban definiált függvény. A csúcs frissített adatai végül minden olyan gépre át lesznek másolva, amely rendelkezik a csúcs szellemmásolataival, és az értékek a szóró függvény végrehajtásával a szomszédos csúcsokhoz lesznek továbbítva.
Delta-gyorsítótárazás: Vannak olyan helyzetek, amikor egy csúcsprogram aktiválódik (aktívvá válik), mert csak néhány szomszédja módosul. Az aktivált csúcs begyűjtési műveletet hajt végre az összes szomszédján, amelyek közül sok nem futott, tehát olyan értékeket ad vissza, amelyek az adott csúcs utolsó futása óta nem módosultak. A GraphLab által bevezetett finom optimalizáció az úgynevezett delta-gyorsítótárazás, mellyel a begyűjtési műveleteknek az egy csúcs összes szomszédjától származó eredménye az adott csúcsnál van gyorsítótárazva. A szomszédos csúcsokon futó szórási művelet során elküldhető egy opcionális $\Delta a$ paraméter, amely az $a$ változó értékének az iterációk közötti változásait összegzi. Ez az érték felhasználható a begyűjtési fázis kihagyására, és hozzáadható az $a$ gyorsítótárazott értékéhez, ezáltal felgyorsítva a végrehajtást.
Hivatkozások
- Y. Low, J. Gonzalez, A. Kyrola, D. Bickson, C. Guestrin és J. M. Hellerstein (2010). GraphLab: Új párhuzamos keretrendszer gépi Tanulás mesterséges intelligencia bizonytalanságáról (UAI)
- Y. Low, J. Gonzalez, A. Kyrola, D. Bickson, C. Guestrin és J. M. Hellerstein (2012). Elosztott GraphLab: Keretrendszer gépi Tanulás és adatbányászathoz a felhőbeli PVLDB-ben
- J. Gonzalez, Y. Low, H. Gu, D. Bickson és C. Guestrin (2012. október). PowerGraph: Elosztott gráf-párhuzamos számítás természetes gráfokon az operációs rendszerek tervezéséről és implementálásáról szóló 10. U Standard kiadás NIX konferencia során