Programozási modell
A Hadoop analitikai motorként mutatja be a MapReduce-t, és „a színfalak mögött” a Hadoop elosztott fájlrendszert (HDFS) használja.1 A HDFS a Google fájlrendszeréhez (GFS)2 hasonló fájlrendszert használ, és a bemeneti adathalmazokat rögzített méretű tömbökben (blokkokban) particionálja, majd szétosztja őket az érintett fürtcsomópontokon. Az alapértelmezés szerint 64 MB-os HDFS-blokkokat a felhasználók igény szerint konfigurálhatják. A feladatok ezután párhuzamosan dolgozzák fel a HDFS-blokkokat az elosztott gépeken, ezáltal kihasználják az adathalmazok particionálásával lehetővé tett párhuzamosságot. A MapReduce több, leképezési és csökkentési tevékenységnek nevezett elemre bontja a feladatokat. Minden leképezési tevékenység egy leképezési fázisnak nevezett egységbe tartozik, a csökkentési tevékenységeket pedig a csökkentési fázis nevű egység tartalmazza. A leképezési fázis egy vagy több leképezési tevékenységből állhat, a csökkentési fázis pedig nulla vagy számos csökkentési tevékenységet tartalmazhat. Ha egy MapReduce-feladat nem tartalmaz csökkentési tevékenységeket, akkor „csökkentés nélküli” feladatnak nevezik.3
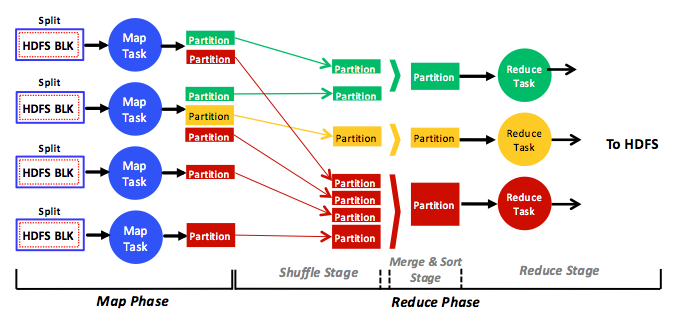
1. ábra: A MapReduce elemzési motor fázisainak, szakaszainak, feladatainak, adatbemenetének, adatkimenetének és adatfolyamának teljes, egyszerűsített nézete
Ez az ábra a MapReduce analitikai motor teljes, ám egyszerűsített nézetét mutatja be. A leképezési tevékenységek elosztott HDFS-blokkokon üzemelnek, a csökkentési tevékenységek pedig a leképezési tevékenységek köztes kimenetnek vagy partíciónak nevezett kimenetén. Minden egyes leképezési tevékenység egy vagy több különböző HDFS-blokkot dolgoz fel (ezekről rövidesen bővebben is szót ejtünk), és minden egyes csökkentési tevékenység egy vagy több partíció feldolgozásáért felelős. Egy szokványos MapReduce-programban az összes bemeneti HDFS-blokkon futtatott leképezési tevékenység azonos, ahogy az összes partíción futtatott csökkentési feladatok is. Ezért egy adott leképezési vagy csökkentési fázison belül a MapReduce-feladatok besorolhatók az egyetlen program többféle adattal (SPMD) kategóriába.
A leképezési és csökkentési tevékenységek különböző adatokat használnak fel, és alapvetően egymástól függetlenül működnek, párhuzamosan csak a megfelelő fázisokban üzemelnek. Ez azt jelenti, hogy az azonos fázisban lévő tevékenységek soha nem kommunikálnak egymással (nem küldenek és nem fogadnak üzeneteket), így a MapReduce-ban kizárólag az eltérő fázisban lévő különböző feladatok között zajlik kommunikáció (a MapReduce keretrendszerén keresztül). A leképezési tevékenységek új partíciókat hoznak létre a leképezési fázisban, a Hadoop-motor pedig egy elosztás néven ismert folyamat során viszi át a partíciókat (a hálózaton keresztül) a csökkentési tevékenységekhez a csökkentési fázisban. Az ilyen stratégiákra azért van szükség, mert a Hadoopot nem lehetne a (több száz vagy több ezer csomópontból álló) nagy fürtök méretéhez felskálázni, ha a tevékenységek önkényes kommunikációja engedélyezett lenne. Ehelyett minden kommunikáció kizárólag a leképezési és csökkentési fázisok között zajlik, ezt pedig teljes mértékben a motor szabályozza (nem pedig maguk a tevékenységek). Ezért egy MapReduce-változatban futó szokványos program az üzenettovábbítási modell egy speciális esetének tekinthető. A feladatok nem rendelkeznek hozzáféréssel egy közös elosztott memóriához. Ehelyett a keretrendszer továbbítja az üzeneteket a leképezési és csökkentési szinkronizálási határok között.
Hivatkozások
- HDFS Architecture Guide Hadoop
- S. Ghemawat, H. Gobioff és S. T. Leung (2003. október). A Google fájlrendszer SOSP-je
- S. Chen és S. W. Schlosser (2008). MapReduce Megfelel az alkalmazások szélesebb fajtáinak IRP-TR-08-05, Intel Research