YARN
Ebben a leckében a Hadoop 2.0-val, más néven a YARN-nal foglalkozunk.
A Hadoop esetében jelentős fejlesztés történt a meglévő műszaki hiányosságok kezelésére, beleértve a JobTracker (JT) megbízhatóságát és rendelkezésre állását, valamint a statikus erőforrások (leképezési és csökkentési tárolóhelyek)10 lefoglalását a TaskTracker elemeken (TT-ken). Az újratervezett keretrendszer a JT, a Hadoop elsődleges csomópontjának ilyen problémáival foglalkozik, ezért egyetlen meghibásodási ponttal (SPOF) foglalkozik. Az új Hadoop másik fő célja, hogy a MapReduce-on kívül más elosztott elemzési motorokat is támogasson. Ez lehetővé teszi a Hadoop-fürtök nagyobb mértékű használatát, és szükségtelenné teszi, hogy nagy fürtöt kelljen üzembe helyezni minden egyes keretrendszer esetében. A Hadoop esetében ennek eredménye egy új verzió: a Yet Another Resource Negotiator (YARN). A következőkben bemutatjuk a YARN-t, és rámutatunk arra, hogy az miben különbözik a korábbi Hadoop MapReduce verziótól, amelyet MapReduce 1.0-nak hívunk.
A YARN A Hadoop második generációja (2.0-s és újabb verziók). A YARN legfőbb előnye a Hadoop korábbi generációjával szemben, hogy az erőforrás-elosztás már nem rögzített, és a YARN nincs kötve semmilyen kizárólagos programozási keretrendszerhez. Ez lehetővé teszi, hogy a YARN független fürtütemezőként működjön, amely különböző számítási feladatok és alkalmazások ütemezésére képes. A YARN egy kétszintű ütemező. A Hadoop v1 JobTrackere felel a YARN-ban az erőforrás-elosztásért és a feladatkezelésért, ami lehetővé teszi a YARN-fürtök egyszerű vertikális felskálázását.
Architektúra és munkafolyamat
A MapReduce 1.0 újratervezésének alapvető célja a JT-funkciók elkülönítése több, egymástól független démonba, az alábbi ábrán látható módon. A YARN továbbra is elsődleges-alárendelt topológiát alkalmaz, de hozzáadja az alábbi fejlesztéseket:
- A MapReduce mellett további elosztott elemzési motorok támogatásához az erőforrás-kezelési modul teljes mértékben le lett választva a JT-ről, és külön entitásként (Resource Manager (RM)) van meghatározva. Az RM két további két fő összetevőre lett osztva, a Scheduler (S) és az Applications Manager (ASM) összetevőkre.
- Ahelyett, hogy egyetlen elsődleges JT-t használna minden alkalmazáshoz, a YARN alkalmazásonként egy elsődlegest jelöl ki, egy alkalmazás-főkiszolgálót (AM). Az AM-ek terjeszthetők a fürtcsomópontokon, így kiiktathatók az alkalmazások SPOF-jei és elkerülhető az esetleges teljesítménycsökkenés.
- A TT-k gyakorlatilag változatlanok maradnak, de mostantól csomópontkezelőknek (NM-eknek) hívjuk őket.
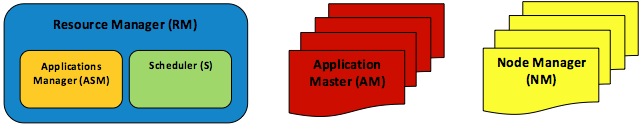
8. ábra: A YARN-architektúra elemei: egy RM, egy ASM, egy S, sok AM és sok NM
A YARN összetevői
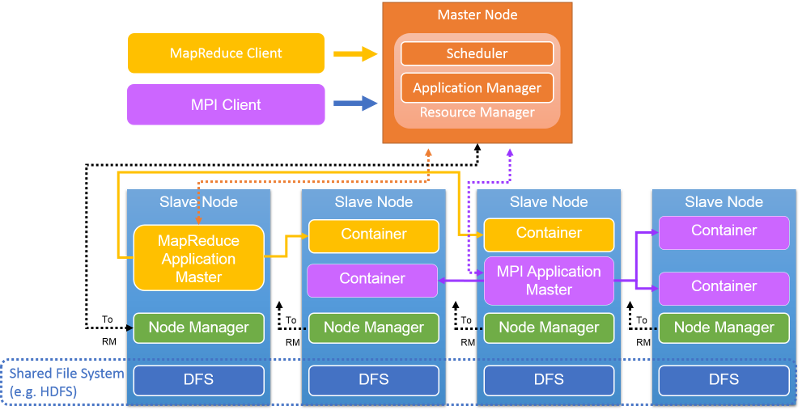
9. ábra: YARN-fürt architektúrája
A fürtönkénti Resource Manager az elsődleges csomópontban található (9. ábra). Az RM fogadja az ügyfél által küldött alkalmazásokat/feladatokat, erőforrásokat foglal le a feladatokhoz, monitorozza a fürt állapotát, és kezeli az erőforrásokhoz való hozzáférést. Az RM a következő két összetevővel rendelkezik: a Scheduler (amely ütemezi a feladatot) és az Applications Manager (amely létrehozza, kezeli, monitorozza, újraindítja és törli a feladatokat).
Az RM a központi összetevő: a különböző versengő alkalmazások/feladatok közötti erőforrás-lefoglalások egyeztetését végzi. Az RM dinamikusan, bérletekként foglal le erőforrásokat az alkalmazások számára, tárolók formájában. A tárolók az erőforrások logikai leképezései, memóriaméret vagy a processzorszám formájában. Jelenleg az RM kezeli a memóriakapacitásokat és a processzor-erőforrásokat, de még nem támogatja a lemez- és a hálózati erőforrásokat. Az RM együttműködik a csomópontkezelőkkel a fürt globális nézetének összeállítása és az erőforrás-hozzárendelések kényszerítése érdekében. Az RM egy szívverési mechanizmuson keresztül nyomon követi az erőforrás-használatot és a csomópontok működőképességét.
A Scheduler az RM részét képezi, és globális tervet hoz létre a fürt erőforrásaihoz, kiszolgálja az alkalmazás erőforrás-szükségleteit, és olyan stratégiák használatával ütemezi a feladatokat, mint például a Capacity vagy a Fair ütemezés. Az Applications Manager (az RM másik része) fogadja az elküldött feladatokat, egyeztet a Schedulerrel az erőforrások (egy tároló) inicializálásával kapcsolatban a feladat Application Masterének futtatásához, valamint szolgáltatásokat biztosít az AM-ek elfogadásához/újraindításához hiba esetén.
Az AM koordinálja az alkalmazás (vagy feladat) végrehajtását a YARN-fürtön. Minden egyes feladat (MapReduce-feladat, MPI-feladat vagy Spark-feladat) dedikált AM-mel rendelkezik a YARN-fürtben. Az AM – a többi feladathoz hasonlóan – egy közös tárolóban fut. Az AM feladata a tárolók beszerzése és a hozzá tartozó feladatok lefoglalása a tárolókon. Kiszámítja a szükséges erőforráskészletet az általa futtatandó feladatok alapján, és kérést küld az RM számára. Az erőforrások lefoglalása után az AM ezeken a tárolókon futtatja a feladatokat. Miután az erőforrások használata befejeződik, az AM visszaadja azokat az RM-nek. Az alábbiakban részletesebben ismertetjük ezt a folyamatot.
Az AM a tárolóban való futtatása során rendszeresen szívveréseket küld az RM-nek a működőképességének és erőforrásigényének frissítéséhez. Az AM kiszámítja a feladat erőforrásigényét, és tárolóval kapcsolatos kérést küld a beállításokkal és korlátozásokkal együtt az RM-nek a rendszeres szívverési üzenetben. Az RM dinamikusan válaszol a szívverésre tárolóbérletek (jogkivonatok) formájában. Az AM ezeket a jogkivonatokat használja, amikor kapcsolatba lép a megfelelő NM-ekkel a feladathoz tartozó tevékenységek indításához. Az AM egy köldökzsinór-mechanizmuson keresztül nyomon követi a futó feladatok állapotát. A feladat végrehajtása során az RM nincs tisztában az AM ütemezésével. MapReduce-feladatok esetén az AM a Hadoop 1.0-s verziójának JobTrackeréhez hasonlóan működik.
A csomópontkezelő az egyes csomópontokon található. YARN-fürtcsomópontonként egyetlen NM található. Az NM-ek hitelesítik a tárolóbérleteket és monitorozzák az erőforrás-használatot. Az NM-ek a szívveréseken keresztül lépnek kapcsolatba az RM-mel, és az RM vagy az AM utasításai alapján törlik a tárolókat.
A tároló a fürtben lefoglalt erőforrás bérletének felel meg. A bérlet az adott csomóponthoz kötött erőforrások logikai csomagja. Az RM az egyetlen egység, amely tárolók lefoglalását végzi a feladatokhoz. Minden lefoglalt tároló globálisan egyedi ContainerID azonosítóval rendelkezik. Minden tároló számos nem statikus attribútummal rendelkezik: CPU, memória, lemez BW, hálózati BW. A tárolók a Hadoop 1.0-s verziójának MapReduce-tárolóhelyeivel hasonlíthatók össze. A tárolót nem sokkal azután törli a rendszer, hogy az abban futó művelet befejeződött. Az RM visszavonja az erőforrásokat, és a későbbiekben használja azokat.
Az AM tárolóval kapcsolatos igényeket küld az RM Schedulernek, ha számítási erőforrásokra van szüksége. A Scheduler által támogatott protokoll a következő <priority, (host, rack, *), resources, #containers>. Az RM Scheduler ugyanabban a formátumban rendel hozzá vagy foglal le tárolókat. Az RM-naplóról készült pillanatfelvétel azt szemlélteti, hogyan foglal le az RM egy tárolót (10. ábra):

10. ábra: Tároló-hozzárendelés naplópillanatképe a YARN-ban. A bejegyzés fontos információi: 1. ContainerID, 2. Számítógépes erőforrások ebben a ContainerID-ben, 3. Annak a csomópontnak az azonosítója, ahol a ContainerID található, 4. A csomópont erőforrás-jelentése a lefoglalást követően.
Feladat- és tevékenységütemezés
A YARN egy kétszintű ütemező. Az RM a feladatok ütemezését végzi, az AM pedig az RM által a számára lefoglalt tárolókon ütemezi a tevékenységeket. Az RM-ben a feladatütemezésért felelős Scheduler különböző ütemezési stratégiákat alkalmaz:
- FIFO Scheduler: Ez egy egyszerű és egyszerű ütemező, amely egyetlen első be- és első kimenő üzenetsorsal rendelkezik, és ennek alapján ütemezi a tárolókéréseket. Egy feladat futás közben általában kizárólagos módon foglalhatja a fürtben lévő erőforrásokat. Bár az egyes feladatok számára nagyobb erőforrásokat is rendelkezésre lehet bocsátani, ez okozhat olyan problémákat, mint például az erőforrások elvétele más feladatok elől vagy a rendelkezésre álló erőforrások nem megfelelő elosztása. A FIFO Scheduler lehetővé teszi a feladatprioritások beállítását. Ezzel a rendszer a következő futtatandó feladatként a legmagasabb prioritású feladatot választja ki. Mivel azonban a FIFO Scheduler nem támogatja az előzetes lefoglalást, továbbra is fennáll az a probléma, hogy a feladatok nem jutnak elegendő erőforráshoz. A magas prioritású feladatokat hosszan futó, de alacsony prioritású feladat is blokkolhatja.
- Kapacitásütemező: Ez az ütemező feltételezi, hogy a Hadoop-feladatok megosztott, több-bérlős fürtön futnak, és maximalizálják a fürt átviteli sebességét és kihasználtságát. A Capacity Scheduler kapacitási garanciát biztosít azon felhasználók számára, akik közös, nagy méretű fürtöt használnak. A Capacity Scheduler várólistákba rendezi a feladatokat. A várólistákat általában az alapján állítják be a rendszergazdák, hogy hogyan lesz a YARN-fürt particionálva és használva a felhasználók különböző csoportjai által (az 1. csoport 1. sora kapja a fürt 50%-át). A Capacity Scheduler egy korlátozáskészletet biztosít annak érdekében, hogy egyetlen feladat vagy várólista se használjon aránytalan mennyiségű erőforrást a fürtben.
- Fair Scheduler: Ez az ütemező a különböző YARN-feladatok tisztességes futtatására összpontosít, így a feladatok az erőforrások egyenlő arányát biztosítják az idő során. Alapértelmezés szerint a Fair Scheduler ütemezési döntései kizárólag a memórián alapulnak. A Fair Scheduler azonban konfigurálható, így a memória és a processzor alapján is képes ütemezni. A Fair Scheduler biztosítja, hogy egyes rövid feladatok észszerű időn belül befejeződhessenek, anélkül, hogy az időigényes vagy nagyobb feladatok erőforráshiánnyal szembesülnének. Abban az esetben is ez az ajánlott ütemező, ha több felhasználó osztozik ugyanazon a fürtön. A Fair Scheduler az erőforrások egyenlő mértékű lefoglalásán kívül a különböző prioritású feladatok ütemezésére is képes. A felhasználók által beállított prioritások használhatók a feladatonként lefoglalandó erőforrás-mennyiség megállapításához.
- Az Ütemező: A felhasználók csatlakoztathatják a saját feladatütemezőjüket.
Az ütemezési stratégiákat a yarn-site.xml fájlban lehet konfigurálni. A yarn-site.xml fájlban többféle tulajdonságot is beállíthat a fent említett ütemezők működési paramétereinek finomhangolásához.
Miután egy feladat erőforrásokat (tárolókat) foglalt le, az AM felelős a feladatokhoz tartozó tevékenységek ütemezéséért ezeken a tárolókon. Az AM a feladatok ütemezését ugyanúgy végzi, mint a JobTracker a Hadoop 1.0-s verziójában. Ezen kívül az AM felel a feladatok állapotának monitorozásáért, amelyet a Hadoop 1.0-s verziójában a TaskTracker végez.
Hibatűrés a YARN-ban
A Resource Manager rendszerkritikus meghibásodási pont a YARN-fürt esetében. Az RM rendszeresen rögzíti az állapotát az állandó tárolóban. Ha az RM meghibásodik, akkor újraindítható valamelyik rögzített állapotból. Ezután a rendszer törli és újraindítja az összes AM-et, így a rendszer ütemezheti és végrehajthatja a rögzített állapottól függő alkalmazásokat és feladatokat.
Bármelyik AM meghibásodhat. Az RM észlelni fogja, ha az AM-nek nem sikerült szívverést küldenie, és újraindítja az AM-et. Az AM-nek azonban újból szinkronizálnia kell az összes futó tárolót, hogy a feladat zökkenőmentesen befejeződhessen.
Az NM hibáit az RM is képes észlelni. Ha egy NM meghibásodik, a csomóponton lévő összes tároló törölve lesz, és a rendszer a hibát jelenti az összes futó AM számára. Az AM-ek feladata, hogy új erőforrásokat szerezzenek be tárolók formájában az RM-től, a törölt feladatok futtatásához. A fürt meghibásodott csomópontjához nem lesz több tároló hozzárendelve, amíg az nem áll helyre és nem jelent az RM-nek.
Feladatfolyamat a MapReduce esetében a YARN-on
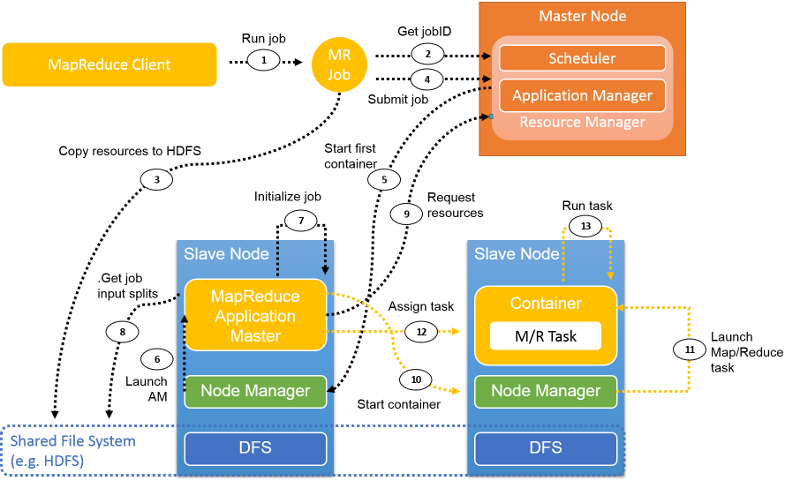
11. ábra: MapReduce-feladat végrehajtása a YARN-ban
Ezen az ábrán egy általános MapReduce-feladatfolyamat látható a YARN-ban. Az alábbi szakaszok a folyamat lépéseit ismertetik.
Feladatbeküldés
1. lépés A MapReduce-ügyfél a feladatok YARN-ba való beküldéséhez ugyanazt az API-t használja, mint a Hadoop 1.0-s verziója. Ha a mapreduce.framework.nameyarn értékre van állítva a feladat konfigurációjában, a rendszer aktiválja a YARN ClientProtocol elemét. A feladatokat a YARN-ban alkalmazásoknak nevezzük.
2. lépés A Hadoop 1.0-s verziójától eltérően, ahol a JobTracker a fürt összes feladatát kezeli, a YARN-ban a rendszer az új feladat azonosítóját az RM-ből kéri le. A jobID azonosítót a YARN-ban néha applicationID azonosítónak is hívjuk.
3. lépés A feladat futtatásához szükséges erőforrásokat, például a feladat JAR-fájlját, a konfigurációs fájlokat és a felosztási adatokat a rendszer előzetesen egy közös fájlrendszerbe másolja át.
Step 4. A feladatügyfél a feladat beküldéséhez a következőt hívja meg az RM-en: submitApplication().
Feladatinicializálás
5. lépés Az RM a submitApplication() meghívását követően továbbítja a feladatkérést a Schedulernek. A Scheduler erőforrásokat foglal le egy olyan tároló futtatásához, amelyben az Application Master megtalálható. Ezután az RM elküldi az erőforrásbérletet néhány csomópontkezelőnek.
6. lépés Az NM üzenetet kap az RM-től, és inicializál egy tárolót az AM számára.
7. lépés Az AM felelős a feladat inicializálásáért. A feladat monitorozásához számos könyvviteli objektum lesz létrehozva. Ezt követően, ha a feladat fut, az AM folyamatosan frissítéseket fog kapni a feladatai előrehaladásával egyidejűleg.
8. lépés Az AM kommunikál a közös fájlrendszerrel (például a HDFS-sel), hogy lekérje a bemeneti felosztási egységeit és olyan egyéb adatokat, amelyek a közös fájlrendszerre lettek másolva a 3. lépésben.
Feladat-hozzárendelés
9. lépés Az AM kiszámítja a leképezési feladatok számát, amely a bemeneti felosztási egységek száma alapján van meghatározva (a Hadoop 1.0-s verziójához hasonlóan). A csökkentési feladatok száma egy konfigurálható paraméter, amely a konfigurációs fájlban van beállítva. Az AM lekéri az összes leképezési és csökkentési feladathoz tartozó erőforrást az RM-ből, tárolókra vonatkozó kérés formájában. A kérés tartalmaz preferenciákat az adatok helye tekintetében (a leképezési feladatokhoz), továbbá tartalmazza a memóriaméretet és az egyes tárolókban lévő processzorok számát.
ResourceRequest: <Priority: 20,
Resource: <vCores: 1, memory: 1024>,
Num Containers: 2,
Desired Host: 192.1.1.1,
Relax Locality: true>
A fenti példában priority a tároló prioritását határozza meg, amely a feladat típusa (például leképezési vagy csökkentési) alapján konfigurálható. Az ehhez a feladathoz szükséges erőforrások egy Resource nevű alrekordként lesznek kijelölve. Itt a vCores (CPU-k) száma 1, míg a memory egy MB-ban megadott, egész szám értékű paraméter. A Num containers azon tárolók számát jelöli, amelyekre a YARN-nak szüksége van. A Desired host a kérés helyre vonatkozó követelményét jelöli. A Relax locality azt jelöli, hogy a megadott helyre vonatkozó követelmény szigorú-e, vagy bármilyen egyéb lefoglalás is elfogadható ehhez a feladathoz.
10 . és 11. lépés. Miután az RM tárolóbérletekkel válaszol, az AM kommunikál az NM-ekkel, és az NM-ek elindítják a tárolókat.
12. lépés Az AM hozzárendel egy feladatot ehhez a tárolóhoz, a hely ismeretében. A feladatot egy olyan Java-alkalmazás hajtja végre, amelynek a fő osztálya YarnChild.
Állapotjelentések
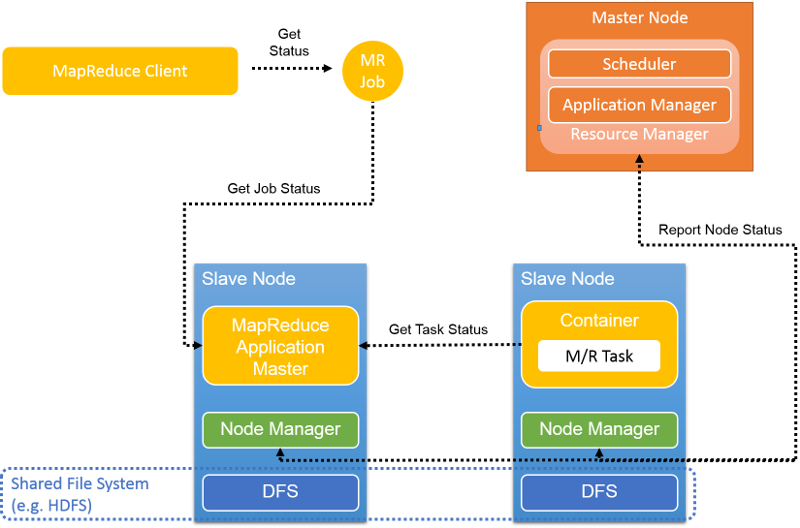
12. ábra: Szívverési és állapotjelentések a YARN-ban
A feladat futtatása során a feladatok folyamatosan jelentik az előrehaladásukat és állapotukat a megfelelő AM számára, ami biztosítja, hogy az AM rendelkezik a feladat összesített nézetével (12. ábra). A csomópontkezelők jelentik a működőképességet és az erőforrás-használatot az RM-nek, amely a fürt globális nézetével rendelkezik.
Feladat befejezése
A feladatügyfél öt másodpercenként ellenőrzi a feladat állapotát, hogy észlelje, ha a feladat befejeződött. Ennek a függvénynek a neve: waitForCompletion(). Miután a feladat befejeződött, a rendszer egy törlési metódust hív meg. A rendszer törli az összes tárolót és az AM működési állapotát. A feladatelőzmény-kiszolgáló nyomon követi a feladattal kapcsolatos információkat.
Példa: WordCount
Itt egy példát mutatunk be a WordCount futtatására egy 1 elsődleges csomópontból és 4 alárendelt csomópontból álló YARN-fürtön. Az Amazon Web Services (AWS) által biztosított m1.large példányt használjuk (2 vCPU, 6,5 ECU, 7,5 GB memória). A bemeneti adatok 39 sima szövegfájlként vannak particionálva az elosztott fájlrendszerben, amelynek teljes mérete 2,32 GB. A leképezési feladatok száma 39, és manuálisan 7 értéket adunk meg konfiguráljuk a feladat konfigurációs fájljában lévő csökkentési feladatok számaként.
Pillanatfelvételek segítségével részletesen ismertetjük a feladat végrehajtásának folyamatát a YARN-on:
Az ügyfél elindítja a WordCount-feladat futtatását.
Az RM egy
jobIDazonosítót rendel hozzá ehhez a WordCount-feladathoz.A rendszer a WordCount-feladathoz tartozó információkat a HDFS-re menti vagy másolja.
A WordCount-feladatot elküldi a rendszer az RM-nek (13. ábra).
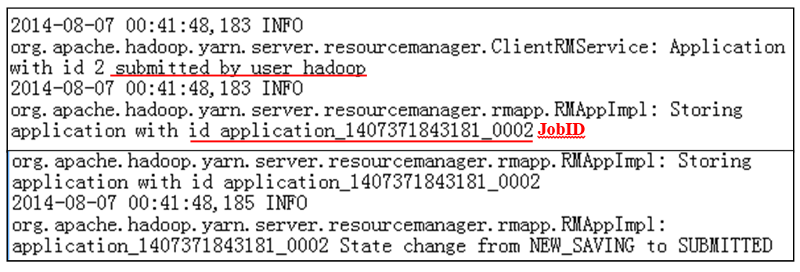
13. ábra: Feladatbeküldési napló
Az RM kommunikál az NM-mel a tároló lefoglalásához az AM számára.
Az NM hitelesíti az RM-től származó tárolóbérletet.
Az RM sikeresen elindítja a WordCount-feladathoz tartozó AM-et (14. ábra).
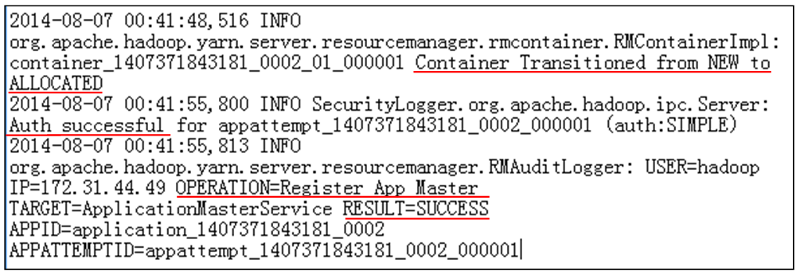
14. ábra: Feladatfoglalási napló
Az AM elindul, és kiszámítja a WordCount-feladat befejezéséhez szükséges erőforrásokat: 39 feladat leképezése és 7 csökkentési tevékenység.
Az RM kéréseket fogad az AM-től, és tárolók formájában lefoglal erőforrásokat.
Az AM elküldi a bérletet az NM-ek számára, és megtörténik néhány tároló indítása.
Az AM indítja azon leképezési feladatokhoz tartozó próbálkozásokat, amelyek készen állnak a tárolókban való futtatásra. A mi esetünkben az első helyen álló AM indítja a 12 leképezési feladathoz tartozó próbálkozásokat, mivel nincs elegendő erőforrás más tároló számára a négycsomópontos fürtön.
Az AM ezután az adatok helyének ismeretében hozzárendeli a tárolókat a leképezési feladatokhoz tartozó próbálkozásokhoz (15. ábra).

15. ábra: Feladat-hozzárendelési napló
A leképezési feladatok futtatása elkezdődik. Az AM egy szívverési mechanizmuson keresztül nyomon követi az egyes feladatokhoz tartozó próbálkozások állapotát.
Egy bizonyos ponton a leképezési feladat tárolóban való végrehajtása befejeződik, és erről az AM értesítésül.
Ezután a tárolót az AM törli. A rendszer lekéri a számítási erőforrásokat, és az NM egy új tárolót inicializál a fenti folyamat alapján. Az AM új leképezési vagy csökkentési feladathoz tartozó próbálkozást rendel az új tárolóhoz. Egy tárolón belül csak egy feladat futtatható.
A korai elosztás miatt, ha több leképezési feladat is befejeződik (alapértelmezés szerint legalább 5%-uk), az AM egy csökkentési feladathoz tartozó próbálkozást rendel egy rendelkezésre álló tárolóhoz. A csökkentési szakasz az elosztásból, az egyesítésből és a rendezésből, valamint a csökkentési függvény végrehajtásából áll. A csökkentési feladat csak azután fejeződhet be, ha a kimeneti bájtjai a HDFS-re lettek írva.
Az AM felügyeli az összes leképezési és csökkentési feladatot, és vár, amíg be nem fejeződnek. Miután az utolsó csökkentési feladat is befejeződött, a teljes feladat BEFEJEZVE állapotmegjelölést kap.
Az AM kommunikál az NM-ekkel a fennmaradó tárolók törléséhez.
Az AM értesíti az RM-et, hogy a feladat befejeződött.
Az RM törli az AM-et. A teljes WordCount-feladat befejeződik (16. ábra).

16. ábra: Feladatkarbantartási napló
Feladatok idővonala a WordCount-példafeladat esetében
Röviddel a feladat indítása után elkezd futni 12 leképezési feladat (kék sávok) (17. ábra). Nem futtatható ennél több leképezési feladat, mert a fürtben nem áll rendelkezésre több erőforrás (tároló) egy újabb leképezési feladat indításához. Több párhuzamosan, hullámként futó leképezési feladatra is hivatkozunk, ezért az első hullámban 12 leképezési feladatunk van. Bizonyos idő elteltével néhány leképezési feladat befejeződik. Amikor néhány leképezési feladat befejeződik (alapértelmezés szerint 5%-uk), a korai elosztás miatt a csökkentési feladatok már ütemezve vannak, és a rendszer elkezdi elosztani őket. Ebben a példában elegendő erőforrás áll rendelkezésre 4 csökkentési függvény indításához. Minden egyes csökkentési feladat 3 egymást követő alszakasszal rendelkezik: elosztás (piros), egyesítés és rendezés (sárga) és csökkentés (rózsaszín). Míg a 4 csökkentési feladat végrehajtja a korai elosztást, elkezdődik a leképezési feladatok második hullámának futtatása. Amikor az utolsó leképezési feladat befejeződik, a teljes leképezési szakasz lezárul. Ezután futtatható az egyesítés és rendezés, valamint a csökkentés. Ezt követően elegendő tároló áll rendelkezésre 3 további csökkentési feladat futtatásához. A feladat röviddel az utolsó csökkentési feladat befejezése után fejeződik be.
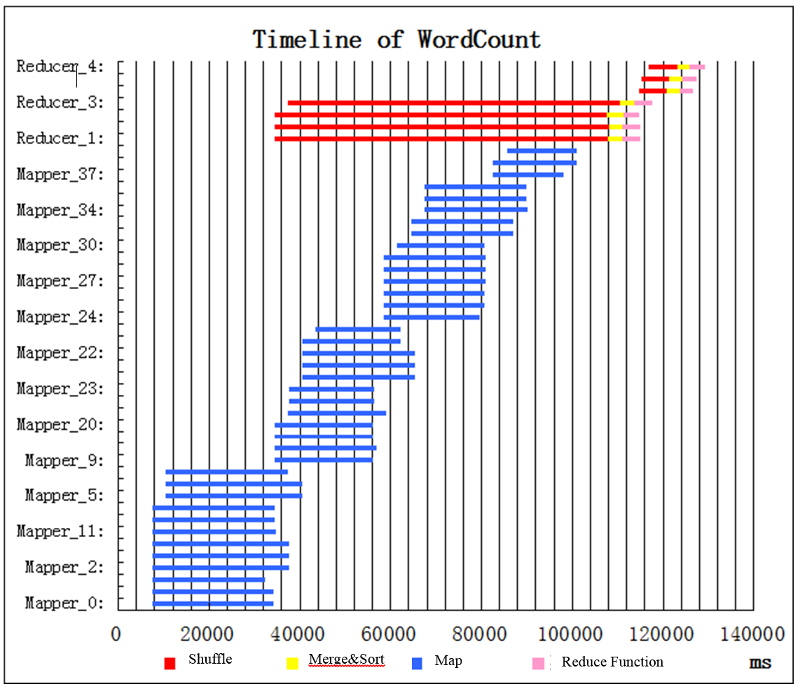
17. ábra: A WordCount feladat-végrehajtási ütemterve
10 A leképezési és a csökkentési tárolóhelyek száma konfigurálható paraméterek, amelyeket a felhasználó a feladatok Hadoop MapReduce-ba való beküldése előtt állíthat be.