Felhőbeli kihívások: Hibatűrés
A felhőket és más elosztott rendszereket az egyprocesszoros rendszerektől megkülönböztető egyik alapvető jellegzetesség a részleges meghibásodás fogalma. Ez azt jelenti, hogy ha egy elosztott rendszer egy csomópontja vagy összetevője meghibásodik, a teljes rendszer továbbra is működőképes maradhat. Ezzel szemben ha egy egyprocesszoros rendszer egy összetevője (például a RAM) meghibásodik, akkor a teljes rendszer meghibásodik. Az elosztott rendszerek/programok tervezésének egyik lényeges célkitűzése egy olyan összeállítási mód, amely automatikusan, a teljesítmény jelentős befolyásolása nélkül elviseli a részleges meghibásodásokat. Az elosztott rendszerek hibáinak elrejtésére használt egyik fő technika a hardveres redundancia, például a RAID technológia használata (lásd e kurzus 3. képzési tervét). Az elosztott programok azonban a legtöbb esetben nem függhetnek kizárólag az elosztott rendszerek mögöttes hardverének hibatűrési technikáitól. Az elosztott programok által alkalmazható népszerű technikák egyike a szoftveres redundancia.
 .
.
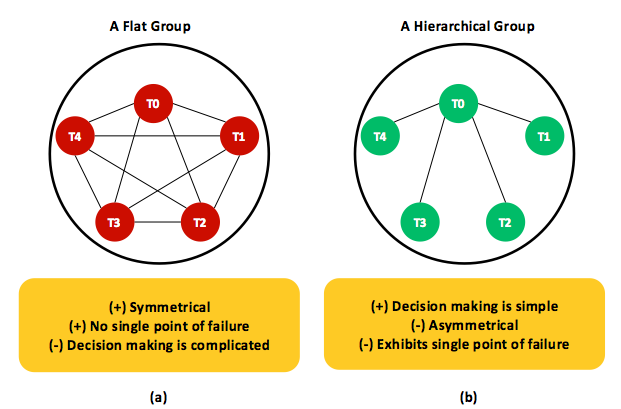
15. ábra: A feladatredundancia alkalmazásának két klasszikus módja. (a) Egyenrangú tevékenységcsoport. (b) A tevékenységek hierarchikus csoportja egy központi folyamattal (azaz T0, ahol a T1 az 1. feladatot jelenti).
A szoftveres redundancia egyik elterjedt típusa a tevékenységredundancia (más néven ellenállóképesség vagy replikáció), amely a tevékenységek hibáival és lassúságával szemben nyújt védelmet. A tevékenységek a 15. ábrán bemutatott példának megfelelően egyenrangú vagy hierarchikus csoportokként replikálhatók. Egyenrangú csoportokban (15.(a) ábra) minden tevékenység azonos abból a szempontból hogy mind ugyanazt a munkát végzik. Végül csak egy tevékenység eredménye lesz elfogadva, a többi eredményt a rendszer elveti. Az egyenrangú csoportok nyilvánvalóan szimmetrikusak és kizárják a rendszerkritikus meghibásodási pontok jelenlét: ha egy tevékenység összeomlik, az alkalmazás továbbra is működni fog, bár a csoport a helyreállásig kisebb lesz. Ha azonban egy alkalmazás döntéshozatalt (például zárolást) igényel, szavazási mechanizmusra lehet szükség. Már volt szó arról, hogy a szavazási mechanizmusok bonyolultabbá teszik az implementációt, valamint kommunikációs késésekkel és a teljesítményt érintő többletmunkával járnak.
A hierarchikus csoportok (15.(b) ábra) általában egy koordinátor-tevékenységet alkalmaznak, a többi tevékenységet pedig feldolgozóként sorolják be. Ebben a modellben a felhasználói kérések a koordinátornak vannak továbbítva, amely eldönti, hogy melyik feldolgozó a legalkalmasabb a kérés teljesítésére. A hierarchikus és az egyenrangú csoportok nyilván ellentétes tulajdonságokat is mutatnak. A koordinátor például rendszerkritikus meghibásodási pont, és a teljesítményt érintő szűk keresztmetszetté válhat (különösen nagyméretű, több millió felhasználóval rendelkező rendszerek esetében). Amíg azonban a koordinátor védve van, addig az egész csoport működőképes marad. Emellett a döntéshozatal is egyszerű, amelyet egyedül a koordinátor végez anélkül, hogy a feldolgozókat befolyásolná, vagy kommunikációs késéseket és teljesítményt érintő többletmunkát okozna. A Hadoop MapReduce az egyenrangú és hierarchikus tevékenységcsoportok hibridjeit alkalmazza, de csak a tevékenységhibák kezelésére. Ennek részleteit a Hadoop MapReduce-t ismertető szakasz tartalmazza.
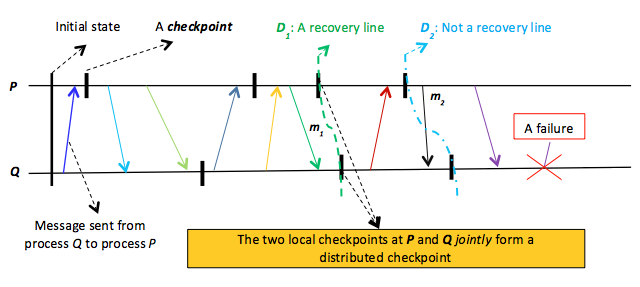
16. ábra: Az elosztott ellenőrzőpontok bemutatása. D1 egy érvényes elosztott ellenőrzőpont, D2 viszont nem az, mert inkonzisztens. A Q D2 ellenőrzőpontja azt jelzi, hogy m2 érkezett, míg a P-néla D2 ellenőrzőpont nem jelzi, hogy m2 lett elküldve.
Elosztott programokban a hibatűrés célja nem csupán a hibák átvészelése, hanem a meghibásodások utáni helyreállítás. Az alapötlet a hibás állapot hibamentes állapotra cserélése, ennek a célnak az elérésére pedig a visszamenőleges helyreállítás az egyik módszer. Ehhez a stratégiához az szükséges, hogy az elosztott program vagy rendszer a jelenlegi hibás állapotából átvihető legyen egy korábbi helyes állapotba, ehhez pedig bizonyos időközönként minden folyamatban rögzíteni kell a rendszer állapotát, egy úgynevezett ellenőrzőpont rögzítésével. Meghibásodás esetén a helyreállítás az utolsó rögzített helyes állapotról, elterjedt nevén helyreállítási vonalról indítható.
Az egy elosztott rendszerben, egy elosztott program különböző folyamataiban rögzített ellenőrzőpontok elosztott ellenőrzőpontot alkotnak. Az elosztott ellenőrzőpontok rögzítése egy lényeges okból adódóan nem egyszerű. Egy elosztott ellenőrzőpontnak ugyanis konzisztens globális állapotot kell rögzítenie, tehát rendelkeznie kell azzal a tulajdonsággal, hogy ha egy $P$ folyamat rögzítette egy $m$ üzenet nyugtázását, akkor léteznie kell egy másik, $Q$ folyamatnak, amely az $m$ küldését rögzítette. Az $m$ üzenetnek végső soron egy ismert folyamattól kell származnia. A 16. ábrán bemutatott két elosztott ellenőrzőpont egyike, $D_{1}$ konzisztens globális állapotot rögzít, a másik, $D_{2}$ viszont nem. A $Q$ folyamat $D_{1}$ ellenőrzőpontja azt jelzi, hogy $Q$ fogadott egy $m_{1}$ üzenetet, a $P$ folyamat $D_{1}$ ellenőrzőpontja pedig jelzi, hogy $P$ elküldte az $m_{1}$ üzenetet, tehát $D_{1}$ konzisztens. Ezzel ellentétben a $Q$ folyamat $D_{2}$ ellenőrzőpontja jelzi az $m_{2}$ beérkezését, a $P$ $D_{2}$ ellenőrzőpontja viszont nem jelzi, hogy $m_{2}$ el lett volna küldve a $P$ folyamatból. Emiatt $D_{2}$ inkonzisztensnek minősül, és nem használható helyreállítási vonalként.
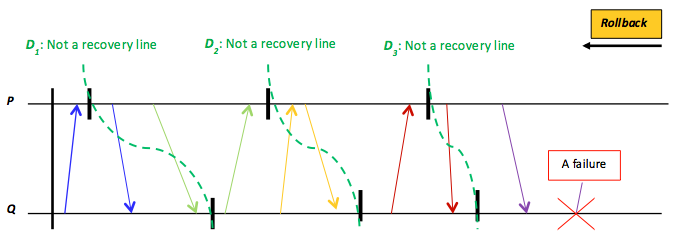
17. ábra: A dominóeffektus, amely az egyes folyamatok (azaz a P és A folyamatok) egy mentett helyi ellenőrzőpontra való visszagördüléséből eredhet a helyreállítási vonal megkeresése érdekében. A D1, D2 és D3 nem helyreállítási vonalak, mert inkonzisztens globális állapotokat mutatnak.
Az egyes folyamatokat az utoljára mentett állapotra visszaállítva egy elosztott program/rendszer megvizsgálhat egy lehetséges elosztott ellenőrzőpontot, hogy megállapítsa annak konzisztenciáját. Ha a lokális állapotok együttesen konzisztens globális állapotot alkotnak, akkor a rendszer helyreállítási vonalat talált. Például a 16. ábrán bemutatott rendszer egy hiba után visszaáll a $D_{1}$ ellenőrzőpontig. Mivel $D_{1}$ globálisan konzisztens állapotot tükröz, a rendszernek van helyreállítási vonala. Az egymást követő visszaállítások folyamata sajnos problémát okozhat, mert dominóhatást idézhet elő. A 17. ábrán látható konkrét esetben például nem található helyreállítási vonal. A 17. ábrán az összes elosztott ellenőrzőpont ténylegesen inkonzisztens. Ez a buktató költséges műveletté teszi az elosztott ellenőrzőpont-kezelést, amely nem mindig konvergál elfogadható helyreállítási megoldáshoz. Éppen ezért sok hibatűrő elosztott rendszer üzenetnaplózással kombinálja az ellenőrzőpont-kezelést, tehát a folyamatok összes üzenetét rögzíti annak elküldése előtt, és egy ellenőrzőpont rögzítése után. Ez a taktika megoldja például a 16. ábra $D_{2}$ ellenőrzőpontjának problémáját. Pontosan az történik, hogy a $P$ folyamat $D_{2}$ ellenőrzőpontjának rögzítése után az $m_{2}$ küldése jelezve lesz a $P$ egy naplóüzenetében, amely a $Q$ $D_{2}$ ellenőrzőpontjával egyesítve már globálisan konzisztens állapotot alkothat. Maga a Hadoop elosztott fájlrendszer (HDFS) is az elosztott ellenőrzőpont-kezelés (a lemezképfájl) és az üzenetnaplózás (a szerkesztési fájl) kombinációját használja a NameNode-hibák utáni helyreállításhoz (lásd e kurzus harmadik képzési tervét). A későbbi szakaszokban bemutatott Pregel és GraphLab csak elosztott ellenőrzőpont-kezelést használ.