Streamfeldolgozó rendszerek
Az eddig megvizsgált keretrendszereket (MapReduce, Spark, GraphLab) elsősorban a kötegelt számítások elvégzéséhez tervezték. A bemeneteik jellemzően nagy méretű elosztott adathalmazok, amelyeket a rendszer több órán keresztül dolgoz fel, így az eredmény nagy és hasznos kimenet lesz. E keretrendszerek használata eredetileg korlátozva volt az adatszakértők és a programozók körére, akik adott nagy méretű lekérdezésekhez használták őket, amelyek esetében a nagy késés elfogadható volt. Mivel azonban a big data egyre inkább elterjedt a vállalati környezetben, az adatok eseti lekérdezése is gyakoribbá vált, amelyeknél a várt késés percekben, nem órákban mérhető. A Pig, a Hive, a Shark és a Spark SQL számos vállalat számára lehetővé tette, hogy összetett kérdéseket tegyenek fel az adataikról anélkül, hogy a magasan képzett programozók körére kellene támaszkodniuk. A felhő tovább ösztönözte ezt a bevezetést, mivel számítási feladatok rugalmas készletét biztosítja az eseti lekérdezés során.
Hamarosan a késések várható időtartama még alacsonyabb lett. A big data fogadása valós idejűvé kezdett válni, és az adatok gyakran csak rövid ideig voltak értékesek. A keresőmotoroknak például a hirdetések legjobb kombinációját kell megjeleníteniük a lekérdezés utáni ezredmásodpercben. A közösségimédia-webhelyek trendeket, népszerű témaköröket és hashtageket észleltek, a rendszer-monitorozó eszközök pedig összetett mintákat észleltek több nagy méretű infrastruktúra-összetevőkön. Ahhoz, hogy ilyen alacsony késést lehessen biztosítani, a streamfeldolgozó keretrendszerek új osztálya kezdett formát ölteni. Ezek a korábbi kötegelt és interaktív feldolgozó rendszerektől alapvetően eltérő követelményekkel és korlátozásokkal rendelkeztek.
Ez a streamfeldolgozó rendszerek elterjedéséhez vezetett.
Streamfeldolgozás
A streamfeldolgozási paradigma műveletsort alkalmaz a végtelenül hosszú bemeneti adatforrás által kibocsátott minden adatelemre. A műveletsor általában folyamatvezérelt, ami függőségeket eredményez a műveletek között. A feldolgozó alkalmazásban az állapotadatok gyakran egy kicsi, gyors adatforrásból olvashatók, és abba írhatók. A streamműveletek folyamatának kimenete szintén egy adatstream. Ezzel más alkalmazások indíthatók el, vagy pufferelhető és stabil tárolóban is tárolható. Az ilyen rendszerek alapvető, elvi architektúrája lent látható.
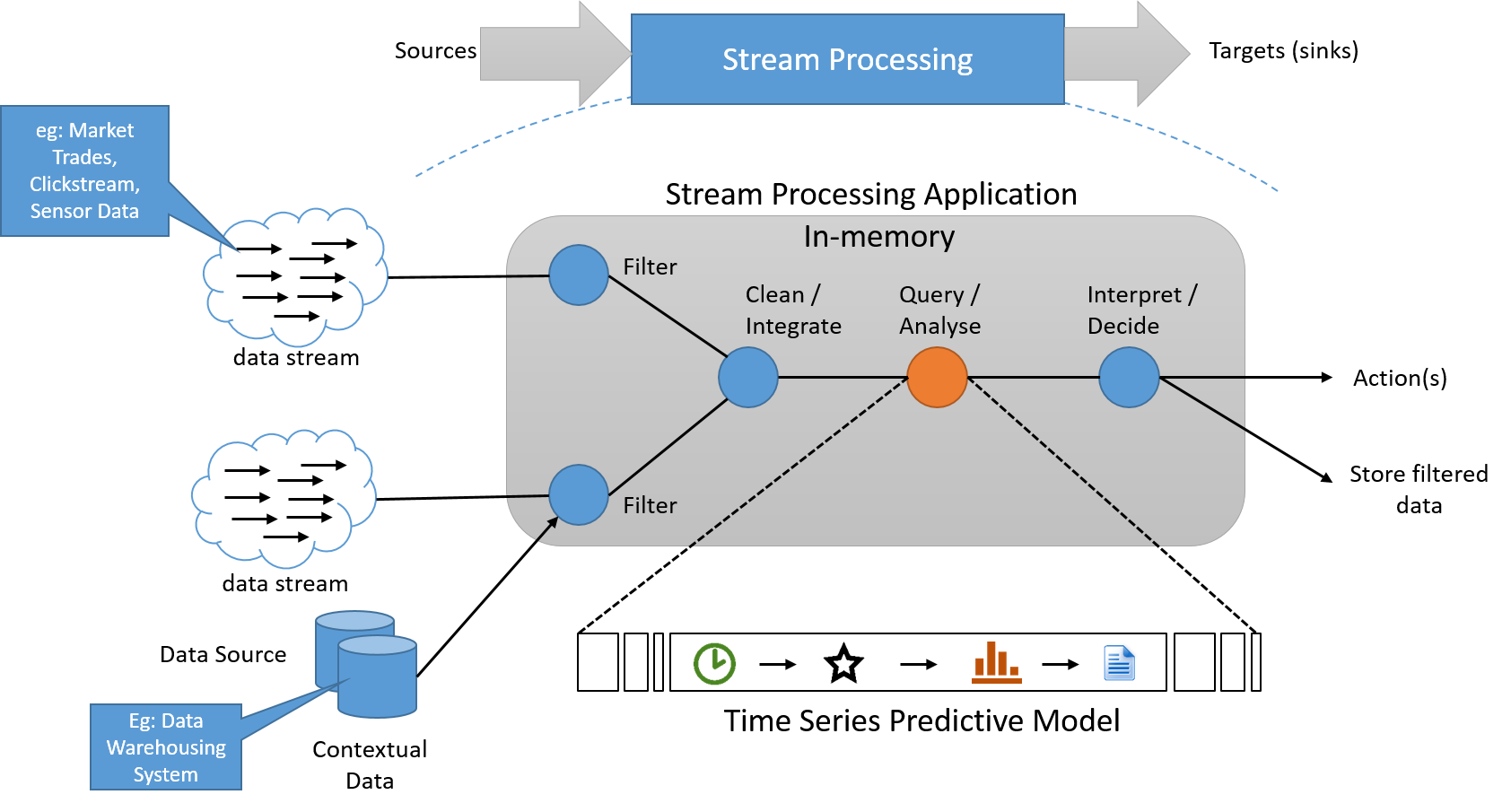
6. ábra: A streamfeldolgozó rendszernek streamben kell feldolgoznia az adatokat, szükség esetén külön tárolófolyamattal, amely nem a "kritikus útvonalon" található
A streamfeldolgozás nyolc szabálya
Stonebraker et. Al. nyolc szabályt alkottak meg a streamfeldolgozó rendszerekhez.
1. szabály: Az adatok áthelyezésének megtartása
A valós idejű streamfeldolgozó keretrendszernek képesnek kell lennie az üzenetek „streamben” történő feldolgozására anélkül, hogy lemezen kellene őket tárolni, mert ez elfogadhatatlan késésest okoz a kritikus útvonalon. Emellett ezeknek a rendszereknek aktívnak (eseményvezéreltnek) és nem passzívnak kell lenniük. (Ha a rendszer passzív, az alkalmazásoknak le kell kérdezni az eredményeket az érdeklődési feltételek észleléséhez.)
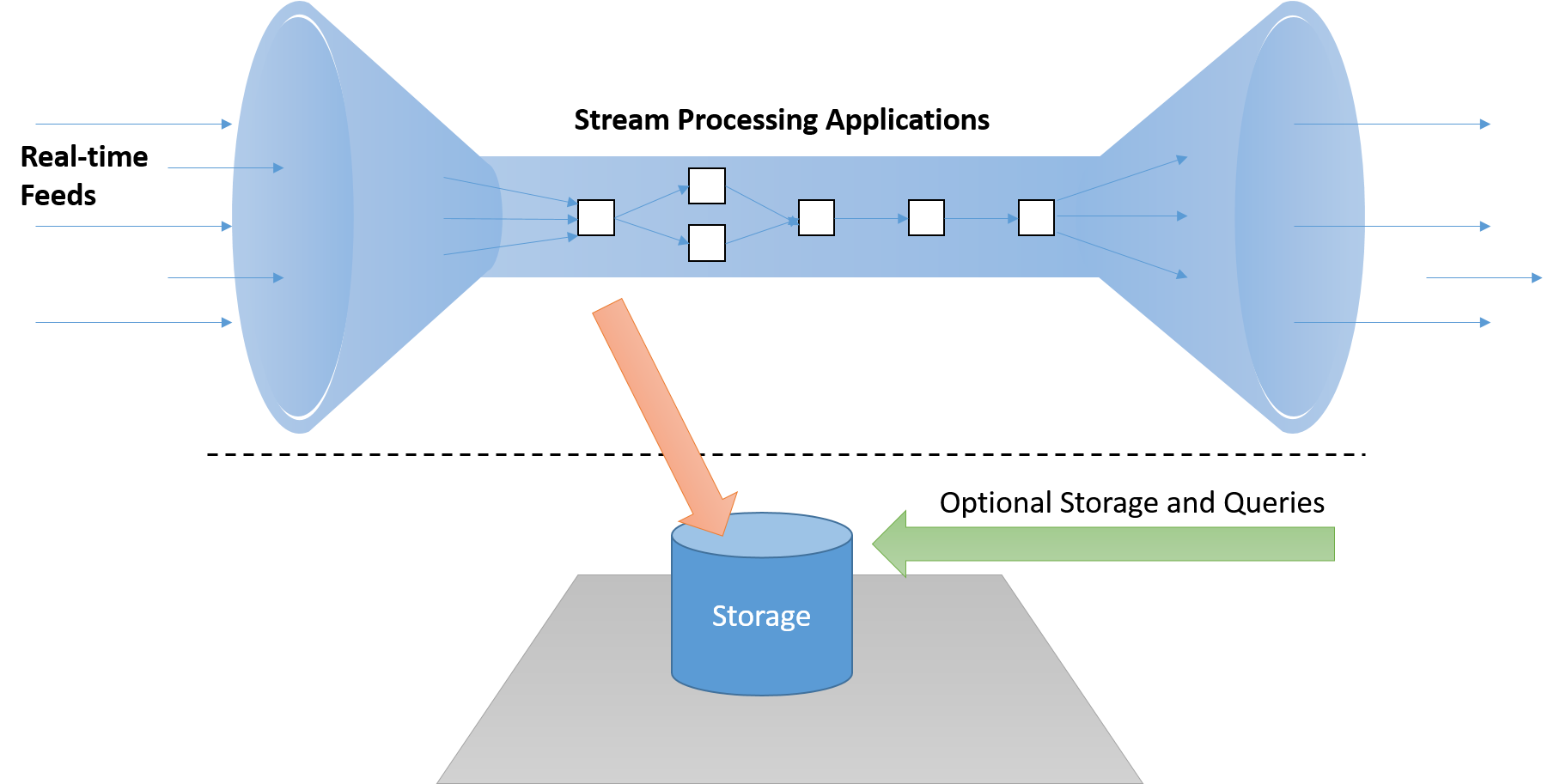
7. ábra: A streamfeldolgozó rendszernek streamben kell feldolgoznia az adatokat, szükség esetén külön tárolófolyamattal, amely nem a "kritikus útvonalon" található
2. szabály: adatfolyamok támogatnia kell az SQL használatával történő lekérdezést
Az SQL széles körben használt és jól ismert szabvány lett az adatok lekérdezéséhez. A hagyományos SQL azonban rögzített mennyiségű adattal működik, ami azt jelenti, hogy a tábla végének elérésével közli a lekérdezéssel, hogy befejeződött. A streamelési forgatókönyvekben az adatok mennyisége folyamatosan növekszik. Stonebraker et. Al. úgy vélték, hogy szükség van egy StreamSQL nyelvre, amely a lekérdezés hatókörét meghatározó, változó hosszúságú, időalapú csúszóablakokkal rendelkezik. Az ablakok meghatározhatók az idő, az üzenetek száma vagy tetszőleges paraméterek használatával. További operátorokra lehet szükség a több streamből származó üzenetek egyesítéséhez.
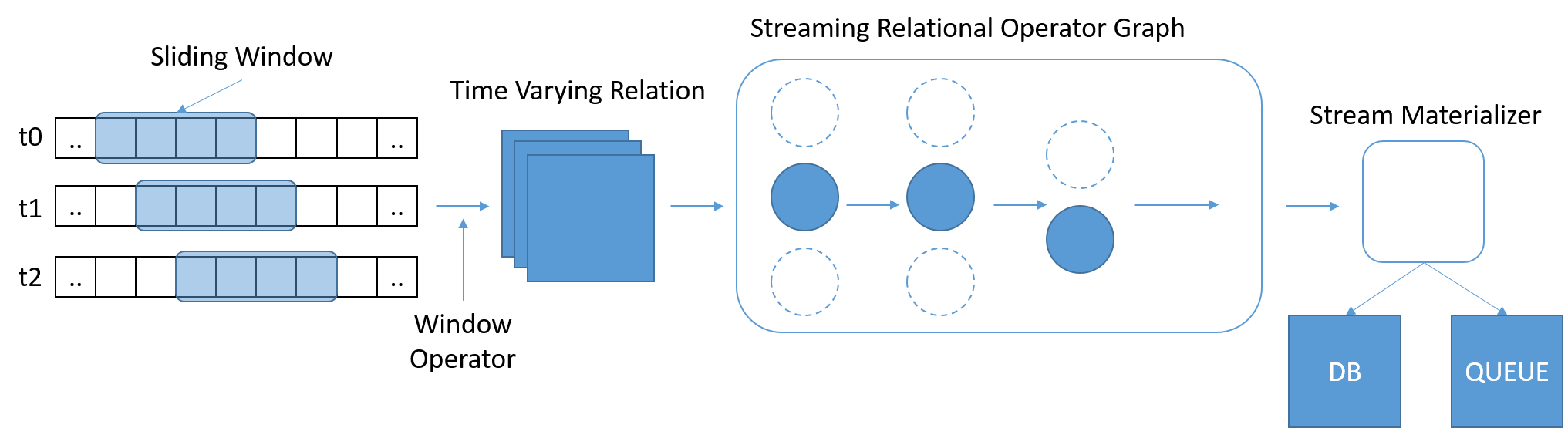
8. ábra: A StreamSQL-nek feldolgoznia kell az adatok részhalmazait, és engedélyeznie kell a kapcsolatok kifejezését az ablakok között
3. szabály: Streamhibák kezelése
A valós idejű rendszerek esetében előfordulhat, hogy az adatok elvesznek, későn vagy nem sorrendben érkeznek meg. A streamfeldolgozó rendszerek nem tudnak végtelen ideig várni az adatokra, de nem is annyira rugalmasak, hogy figyelmen kívül hagyják vagy kihagyják az adatokat. Az ilyen rendszereknek ellenállónak kell lenniük a streamek tökéletlenségeivel szemben, olyan mechanizmusokkal, mint a konfigurálható időtúllépések és a „tartalékidő”, amely során a késői beérkezés elfogadható.
4. szabály: Kiszámítható eredmények létrehozása
A streamfeldolgozó rendszerek eredményének determinisztikusnak és ismételhetőnek kell lennie a stream újbóli lejátszásával. Ez különösen akkor nehéz, amikor a rendszer több egyidejű streamen dolgozik, vagy ha az üzenetek nem sorrendben érkeznek. Az üzeneteket növekvő időrendi sorrendben kell létrehozni, az érkezésük időpontjától függetlenül. Ez a tulajdonság a hibatűrést is lehetővé teszi azáltal, hogy indokolttá teszi azon streamek újbóli lejátszását, amelyeken a feldolgozás sikertelen volt.
5. szabály: Tárolt állapot integrálása
A streamfeldolgozó alkalmazásoknak gyakran össze kell kapcsolniuk a jelent és a múltat. Ha például egy hirdetést ajánl a felhasználónak, a keresőmotornak össze kell kapcsolnia a keresési kifejezés aktuális adatait és a reklámpiac aktuális állapotát a felhasználó kattintási szokásaival kapcsolatos múltbeli információkkal. A tárolt állapot és a streamelési adatok integrálása lehetővé teszi a zökkenőmentes váltást is, amelynek során az algoritmus tesztelhető az előzményadatokon, majd átválthat az élő streamre, ha az megfelelően működik. Az adatokat ugyanabban a rendszercímtartományban kell tárolni, mint az alkalmazást. Ez lehetséges például egy beágyazott adatbázissal, amely lehetővé teszi egy egységes, a tárolt és a streamelési adatokkal foglalkozó nyelv használatát.
6. szabály: Magas rendelkezésre állás garantálása
A streamfeldolgozó rendszerek valós időben működnek, és a működésüket gyakran zavarják az újraindítással járó helyreállítások. Az ilyen rendszereknek lehetővé kell tenniük a gyors átállást egy biztonsági másolatra vagy árnyékmásolatra, amelyet rendszeresen szinkronizálni kell az elsődleges rendszerrel. Garantálni kell az adatok integritását, a 4. szabálynak megfelelően.
7. szabály: Particionálás és automatikus skálázás támogatása
Az elosztott feldolgozás a standard működési modell az összes nagy méretű rendszer esetében. A jó streamfeldolgozó architektúrának nem szabad blokkolónak lennie, és modern, többszálas architektúrákat kell használnia. Továbbá képesnek kell lennie arra, hogy számítógépek hozzáadásával vagy eltávolításával saját maga kezelje a rendszer horizontális fel- vagy leskálázását, a megnövekedett vagy csökkent adatmennyiség, illetve a késések feldolgozása vagy összetettségek alapján. Emellett automatikusan és transzparens módon kell végrehajtania a terheléselosztást az elérhető számítógépeken. A végfelhasználónak nem kellene ilyen összetett megoldásokkal foglalkoznia.
8. szabály: Győződjön meg arról, hogy képes lépést tartani
Minden rendszerösszetevőt nagy teljesítményhez kell kialakítani, és a lehető legkevesebb műveletnek kell a magon kívül történnie. A rendszer teljesítményét és működését a kívánt számítási feladat alapján kell tesztelni, és az átviteli sebességet és a késési célokat érvényesíteni kell.
A streamfeldolgozó motorok fejlődése
Az Aurora (2002) volt az egyik legkorábbi streamfeldolgozó rendszer, amelyet Stonebraker és mtsai. fejlesztettek az MIT-n és a Brown Universityn. Az Aurora a streamfeldolgozási problémákat irányított aciklikus gráfként (DAG) kezelte.
A stream bemenete kötetlen rekordok időbeli alakulásának sorozata (a1, a2, …, an), amely a kiindulóponttól (indítás) a végeredmény (kimenet) felé tart. Egy teljes alkalmazás létrehozható a feldolgozó dobozok különböző kombinációinak hozzáadásával és a közöttük lévő kapcsolatok megrajzolásával. Az Aurora egycsomópontos rendszer volt, amely nem rendelkezett a streamfeldolgozó motorok skálázhatósági követelményeivel. Az Aurora * (2003) új verziója úgy lett létrehozva, hogy több Aurora-csomópontot egyesítsen egy hálózaton keresztül. Ezért a skálázhatóság úgy valósult meg, hogy a streamfeldolgozó feladatok különböző szakaszait különböző fizikai csomópontokon keresztül particionálták. Végül a Medusa projekt (2003) összevonási támogatást biztosított az Aurora számára, amely lehetővé tette a felhasználók közötti együttműködést és megosztást.
Az Aurora projekt következő bővítménye a Borealis volt (2005), amely bevezette a magas rendelkezésre állás támogatását az aktív replikáció használatával. A replikákat a rendszer óvatosan szinkronizálta, hogy fenntartsa az adatkonzisztenciát.
Az Apache Storm (2011) a Twitter által fejlesztett streamfeldolgozó motor volt. Ebben a feldolgozó csomópontok (Boltok) feliratkozhattak a különböző forrásokból származó streamekre (Spoutok), így lehetővé tettek egy egyszerű előfizetői számítási modellt. A Storm a csomópontok meghibásodásától függetlenül garantálja az üzenetek feldolgozását, és engedélyezi a pontosan egyszeri szemantikákat annak biztosítása érdekében, hogy az adatok ne legyenek sem kevesebbszer, sem többször számolva. Az Apache S4 (2011) egy ehhez hasonló, a Yahoo! által kifejlesztett előfizetési rendszer volt. Ez a rendszer abban az értelemben szimmetrikus, hogy az összes csomópont egyenlő, és nincs központi vezérlés, amitől azt remélték, hogy a rendszer skálázhatóvá válik. Az S4 nem támogatta a csomópontok dinamikus hozzáadását a futó fürtökhöz vagy az azokból való eltávolítását. Az Apache Samza (2013) egy ezekhez hasonló másik, több előfizetős rendszer, amellyel részletesebben is foglalkozunk.
A Storm, a Samza és az S4 a hagyományos streamelési modellt követi, amely egyszerre csak egy rekordot dolgoz fel. Ebben a modellben az állapotalapú operátorok dolgozzák fel a rekordokat, az új adatok használatával módosítják a belső állapotot, majd új rekordokat bocsátanak ki. A hibatűrést és a helyreállítást a replikációval végzi el a rendszer úgy, hogy több másolatot készít a feldolgozási elemekről, vagy azáltal, hogy a kiindulási üzeneteket puffereli, és biztonsági mentést tárol róluk, majd ezeket hiba esetén újra beküldi a folyamatba. Továbbá, mivel a DAG elrendezése egyre összetettebbé válik, nehezen biztosítható a különböző útvonalak közötti konzisztencia. Végül pedig e keretrendszerek kötegelt rendszerekkel történő egyesítése nem triviális, és gyakran a Lambda architektúra segítségével történik (ezt az architektúrát később tárgyaljuk).
A streamfeldolgozó rendszerek tervezésének másik megközelítését a Spark Streaming (2012) biztosítja, amely "mikro kötegelést" biztosít. A mikrokötegelés rendkívül gyors számítások sorozatává alakítja a streamszámításokat, több száz ezredmásodperctől néhány másodpercig. A késés növekedése mellett könnyebb a hibatűrés biztosítása és a pontosan egyszeri szemantika az egyes mikrokötegek eredményein.
Egy tevékenységhez használt megfelelő keretrendszer kiválasztásához figyelembe kell venni a kívánt késést, a hibatűrést és az üzenetkézbesítés biztosítékait, valamint a felhasználó készségeit és a fejlesztési költségeket. A következő leckében az Apache Samza vizsgálatával részletesebben megismerjük e keretrendszerek elemeit.