Streamelési architektúrák: Esettanulmány
Most, hogy megismertük, hogyan fejlődtek a streamelési architektúrák, nézzünk meg egy adott keretrendszert, az Apache Samzát.
Apache Samza
A Samza-projektet a LinkedIn fejlesztette ki, elosztott streamfeldolgozó keretrendszerként. Az üzenetek bemeneti streamjét egy módosított kimeneti streammé alakítja, az állapotalapú vagy az állapot nélküli feldolgozás alapján. A Samzát a (korábban tárgyalt) Kafkával párhuzamosan fejlesztették. A Kafka egy kis késésű, elosztott üzenetküldési rendszer. A Samza lehetővé tette e Kafka-üzenetek valós idejű feldolgozását.
A Samza három rétegre osztható:
- A streamelési rétegre, amely particionált, replikált, és tartós streameket biztosít
- A végrehajtási rétegre, amely a tevékenységeket ütemezi és hangolja össze egy fürtön
- A feldolgozó rétegre, amely átalakítja a bemeneti streamet, és létrehoz egy új kimeneti streamet, módosítja az adatbázisokat, elindítja az eseményeket, és általában a bemeneti üzenetekre reagál
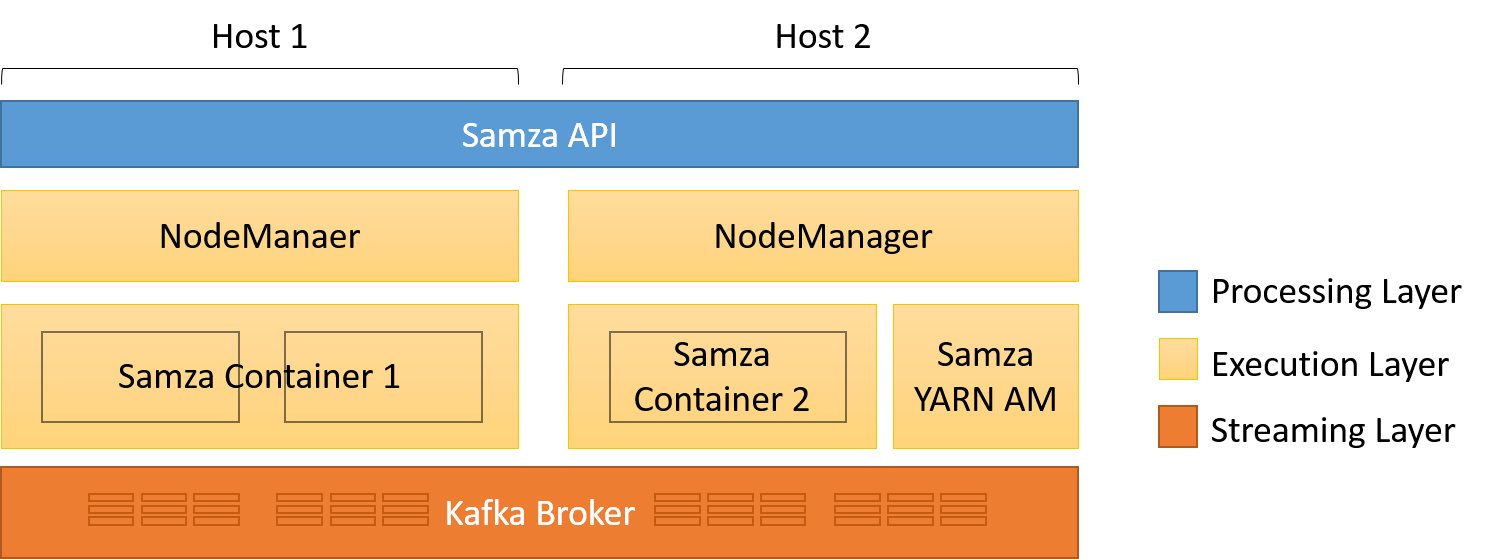
9. ábra: Egy Samza-alkalmazás három rétege
A streamelési és végrehajtási rétegek modulárisak. Az alapértelmezett implementáció a Kafkát használja a streamelési üzenetközvetítőként. A bemeneti és a kimeneti streamek nem módosítható üzenetsorozatok, amelyek a csomópontok között particionálhatók. Egy partíción belül az üzenetek globálisan vannak rendezve, és egyedileg azonosíthatók a streamen belüli eltolással. Az alapértelmezett végrehajtási réteg a YARN-t használja, bár a Mesos is használható, amely egy másik elterjedt erőforrás-kezelő. A YARN használatával könnyebb a Samza-alkalmazások hibatűrésének biztosítása, egyszerűbb az üzembe helyezés, valamint a beépített naplózási és erőforrás-elkülönítési funkciók használata. A YARN és a HDFS együttes használatával a Samza kihasználhatja az adatok helyi rendelkezésre állásának előnyeit.
A Samza cgroupok használatával dolgozza fel a JVM-eket futtató egymagos tárolókat, egy vagy több tevékenység egy feladaton belüli végrehajtásához. A cgroupok a Linux kernelfunkciójának részei, amelyek lehetővé teszik, hogy a folyamatok gyűjteménye a processzor, a memória és a fájlrendszer elérésének együttes kötésével rendelkezzen. A Samzában minden tárolót egyetlen szálként, logikailag hajt végre a rendszer egy üzenet feldolgozásakor. Ezt úgy kell érteni, hogy a tárolón belül egy időben csak egy tevékenységet hajt végre a rendszer. A feldolgozást a Samza API használatával írt egyéni kód végzi.
Ahhoz, hogy nagyobb párhuzamosságra tegyen szert, a Samza egyszerűen több tárolót származtat. Ezért a fejlesztőknek nem ajánlják több szál használatát a feladat kódjában. A Samza belsőleg több szálat használ a kommunikációhoz és a feldolgozáshoz. Azonban egyetlen szál olyan eseményhurokként fut, amely kezeli az üzenetek I/O-ját, az ellenőrzőpontok használatát, az ablakkezelést és a metrikák kiürítését.
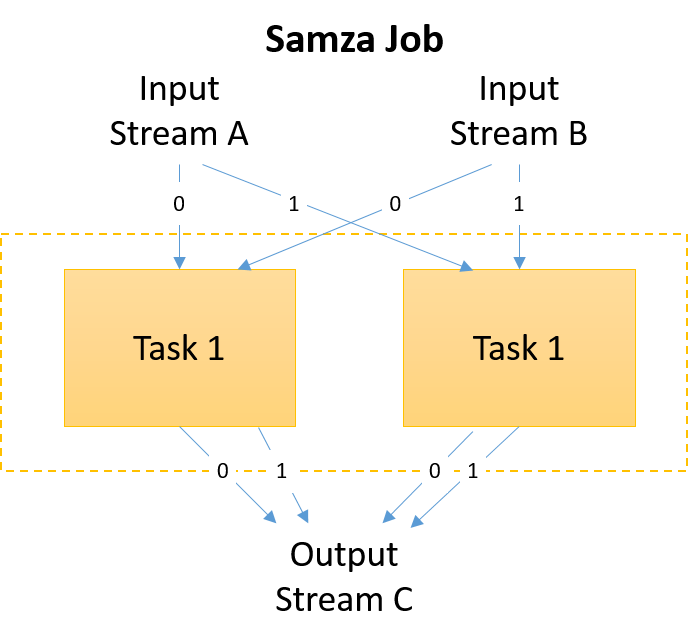
10. ábra: Bemeneti és kimeneti streamek egy Samza-feladatban
A Samza-ügyfelek Samza-feladatokat kezdeményeznek a YARN-ban. A Samza saját Application Masterrel rendelkezik, amely a Yarn erőforrás-kezelőjével (RM) egyeztet az erőforrásokra vonatkozóan. A YARN RM különböző csomópontkezelőkkel kommunikál, hogy lefoglalja az erőforrásokat a Samza-alkalmazás számára. A YARN SamzaContainereket (tevékenységfuttatókat) származtat, amelyek a Samza StreamTask API-t implementáló egyéni kódot futtatnak. Ezek gyakran a Kafka-közvetítők tárolóival közös helyen találhatók, hogy maximalizálják az adatok helyi rendelkezésre állásást.
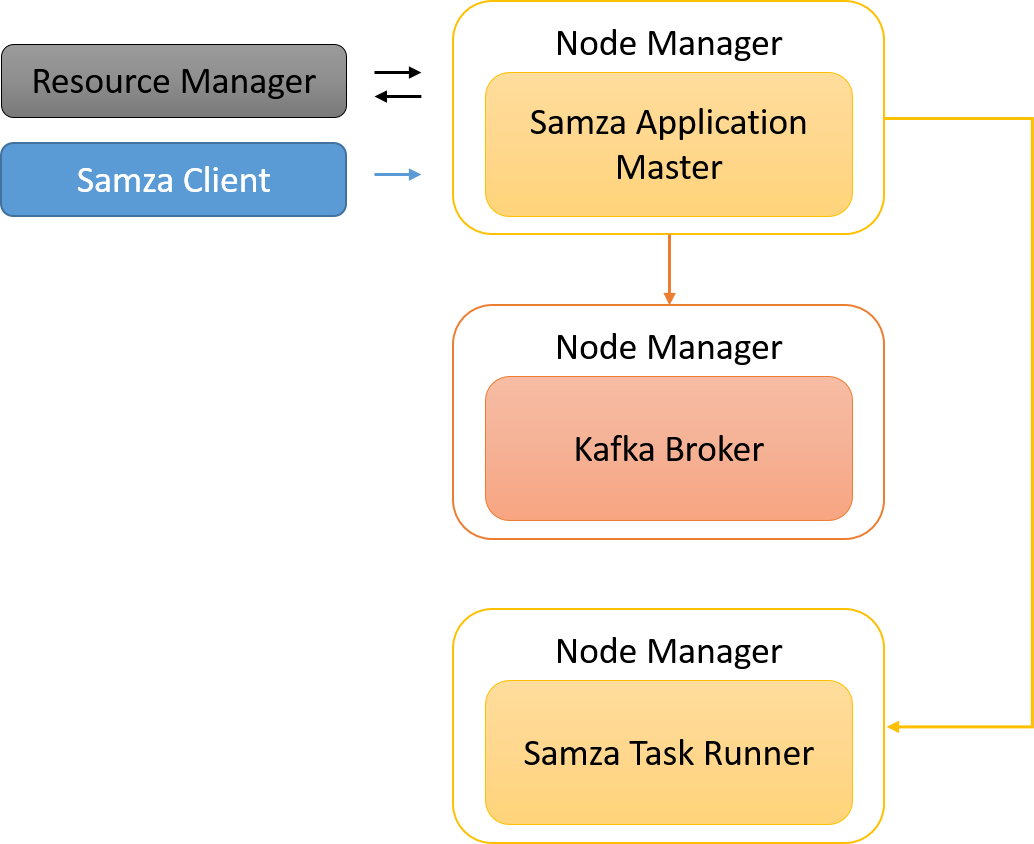
11. ábra: A Samza-feladatok tevékenységekre oszlanak, amelyek egy tárolón belül csoportosíthatók. Mivel tárolónként csak egy szál van, egyszerre mindig csak egy tevékenység aktív.
A Samza a horizontális skálázásra támaszkodik a teljesítmény növeléséhez. Ezt az egy feladatban található tevékenységek számának növelésével éri el. Minden tevékenység egy partíción üzemel a feladat bemeneti streamjein. Tehát több párhuzamos tevékenység futtatásához a streamet több partícióra kell bontani. Ennek módja a Kafkával kapcsolatos korábbi témakörben szerepel. Minden bemeneti témakör esetében legalább egy StreamTask-példány lesz elindítva az egyes partíciókhoz. Minden streamtevékenység önállóan dolgoz fel egy partíciót.

12. ábra: A Samza-alkalmazások a YARN-n futnak izolált tárolókban
Természetesen a fent látható streamelési példa egyszerűen kimenetté alakítja át a bejövő streamet. Számos streamfeldolgozó alkalmazás van, amelyekben a bemeneti üzeneteken végrehajtott számítások függetlenek az összes többi üzenettől. Ilyen például a szabályokon alapuló adatszűrés vagy az egyszerű időalapú módosítás.
A streamfeldolgozás érdekesebb használati eseteihez azonban több stream összekapcsolására, az üzenetek összesítésére, vagy az adatablakon alapuló döntések meghozására van szükség. Az összes ilyen forgatókönyv esetében el kell tárolni az állapotadatokat. A Samza a KeyValueStore-absztrakció használatával implementálja a tartósságot. Minden StreamTask-példány egy különálló, ugyanazon a gépen lévő beágyazott adattáron tárolja az állapotot. A Samza alapértelmezés szerint az írásra optimalizált RocksDB-t használja, amely kis késést és nagy átviteli sebességet biztosít. A beágyazott adatbázisok használata csökkenti az adatok lekérdezéséhez használt, költséges hálózati hívásokra támaszkodó terhelést.
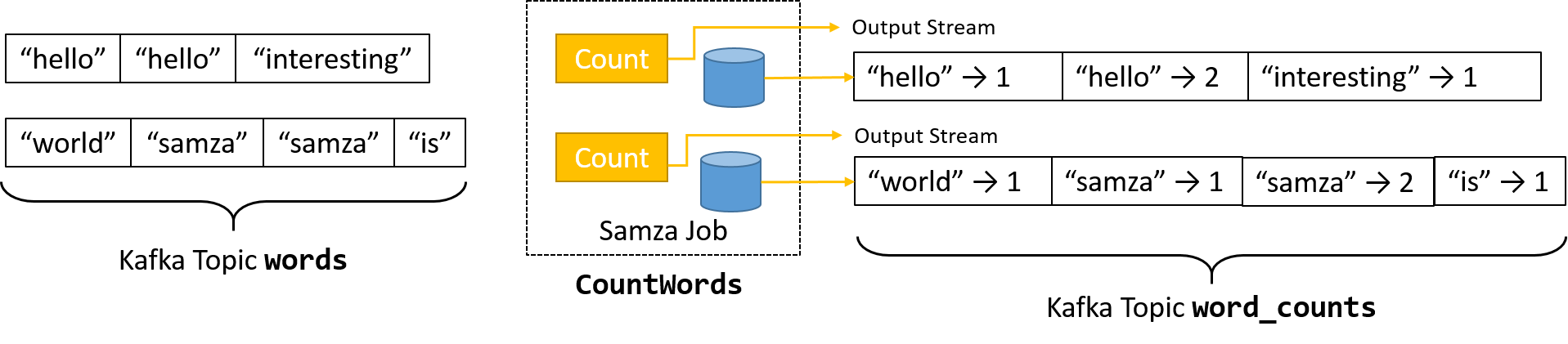
13. ábra: A feladat helyi állapotának tartósságának biztosítása beágyazott adattár használatával
Ezt a megvalósítást úgy is lehet tekinteni, mint egy távoli adatbázis horizontális skálázását és az egyes szegmensek egyedi adatpartíción történő közös elhelyezését. Annak biztosítása érdekében, hogy a hibák ne okozzanak állapotvesztést, a helyi adatbázis módosításait külön változásnapló-streamként kell kibocsátani, amely egy külön Kafka-témakör. Egy külön háttérfolyamat futtatja a naplók tömörítését, hogy csökkentse a változásnaplóban található adatok mennyiségét.
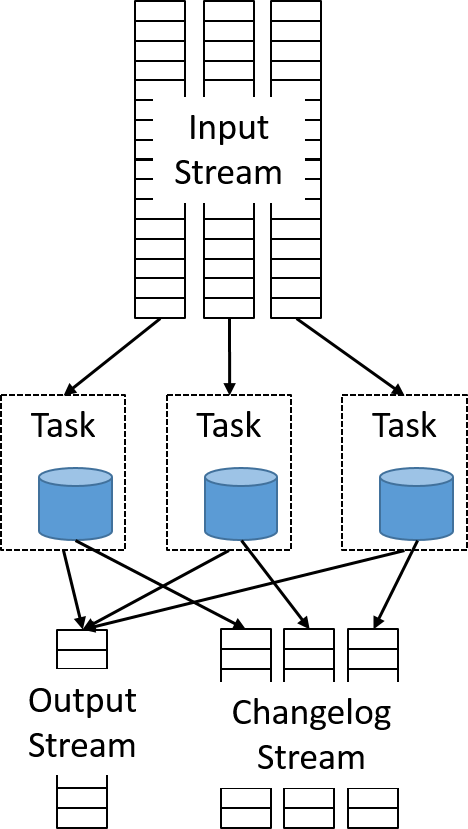
14. ábra: Minden helyi beágyazott adatbázis egy változásnapló kimeneti adatfolyamába ír
Így a tevékenységek egyszerűen skálázhatók fel horizontálisan egy saját adatbázissal rendelkező új tároló elindításával vagy egy párhuzamos változásnapló-streambe történő írással. Ha bármilyen hiba lép fel, egy új tároló indítható el, és visszaállítható konzisztens állapotba a sikertelen partíció kimeneti változásnaplójának felhasználásával.
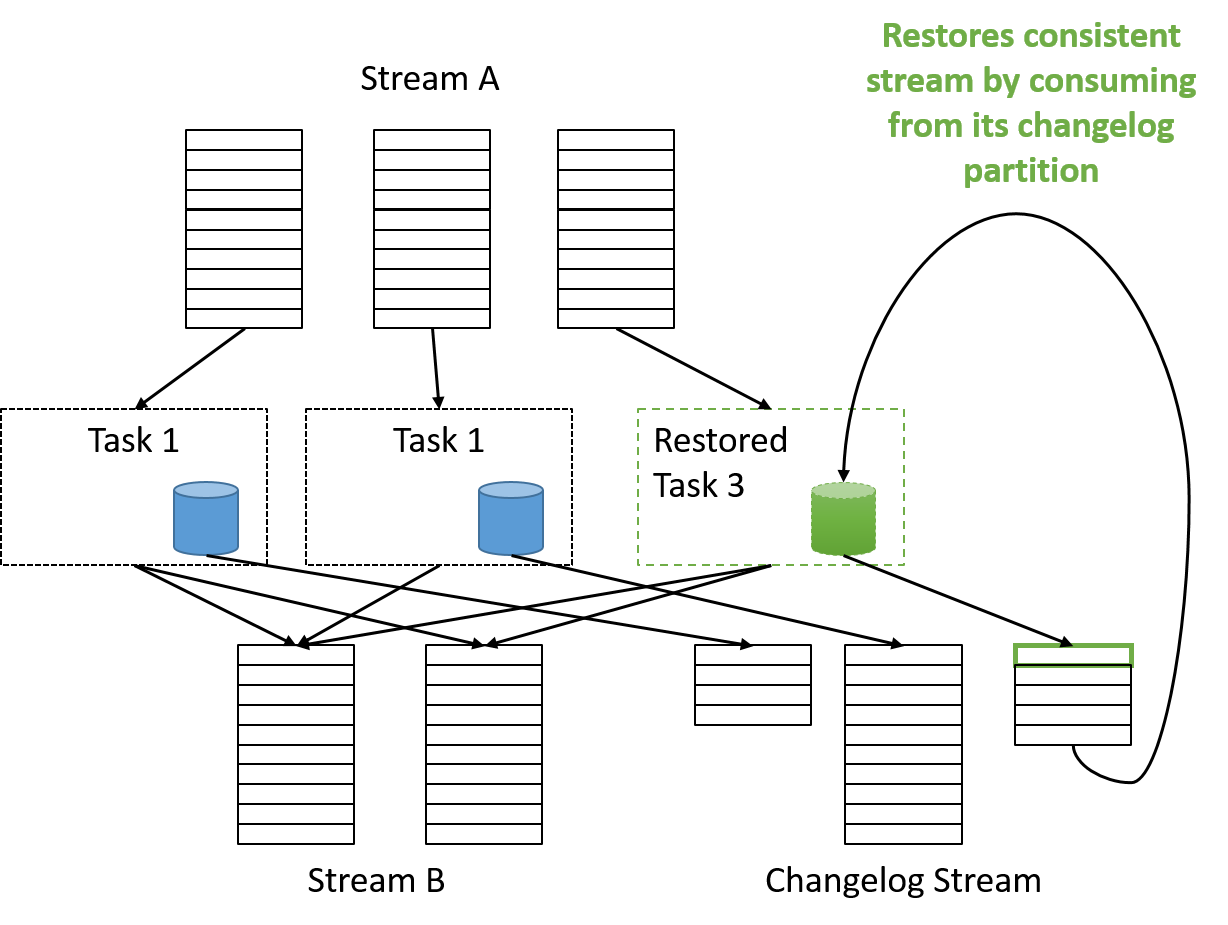
15. ábra: A Samza hibahelyreállítása