Valós idejű architektúrák a gyakorlatban
Számos webes vállalat már elkezdte az üzenetsorok és a streamfeldolgozó keretrendszerek használatát az alkalmazásaikban. Ennek oka elsősorban az, hogy ezek a vállalatok jelentős értékre tettek szert a friss adatok használatából. Most, hogy megismertük az üzenetsorok, a streamfeldolgozás és a Lambda-architektúrák alapvető fogalmait, érdemes lehet megtekinteni egy valós példát arra, hogy a kis késésű, adatigényes architektúra milyen módon biztosít értéket egy nagyvállalat számára. Bemutatjuk, hogy a Kafka és a Samza használata hogyan tette lehetővé a LinkedIn számára számos valós idejű rendszer becsatolását.
Kafka és Samza használatának bevezetése a LinkedInnél
Fiatal technológiai vállalatként a LinkedIn gyakran hozott létre és vezetett be egyetlen konkrét követelményt teljesítő, forradalmi technológiákat. A LinkedIn szolgáltatásai egy egyéni háttérrendszeren futottak, amely a LinkedIn saját, kis késésű elosztott kulcs-érték tárolóját (Voldemort), valamint egy elosztott dokumentumtárolót (Espresso) és egy Oracle RDBMS-t használt. Az előtér-webszolgáltatásokat, az elemzéseket, az e-maileket és az értesítéseket különböző összetettségű tevékenységek vezérelték. Ezek közé tartozott a kötegelt feladatok Hadooppal való végrehajtása, a nagy méretű adattárházakon végzett lekérdezések, illetve a keresés külön infrastruktúrája. Ezekhez naplózási, monitorozási, valamint felhasználó- és metrikakövetési rétegek adták a hátteret.
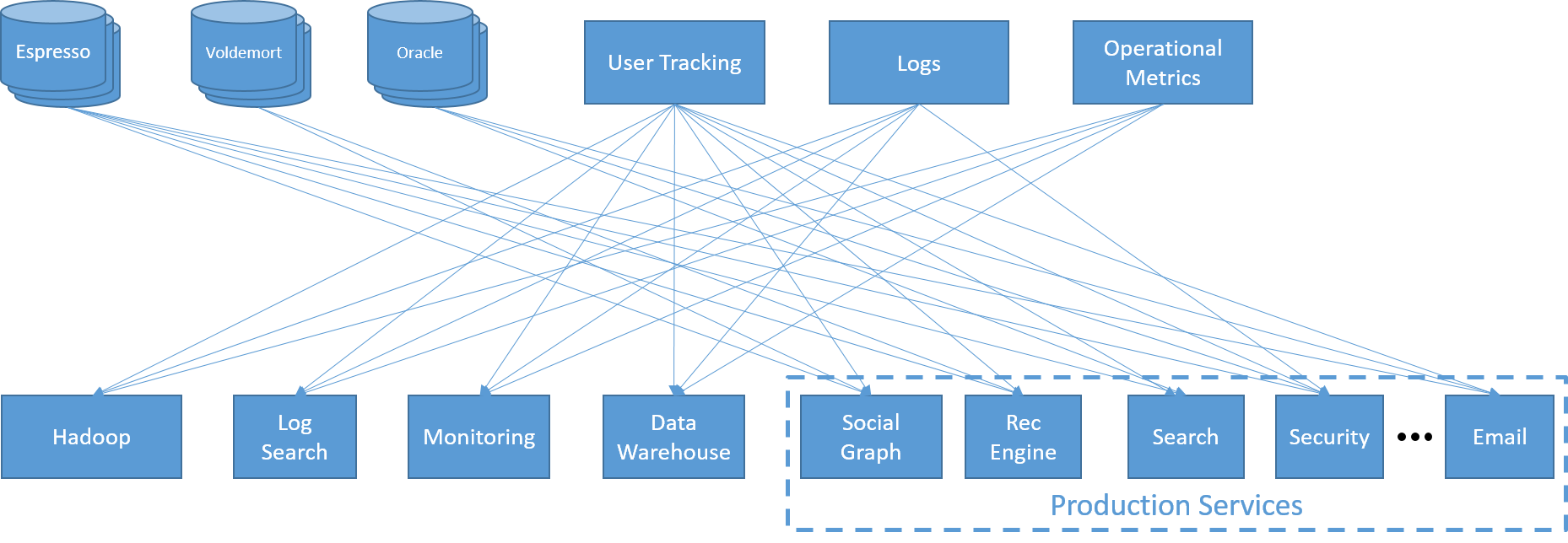
19. ábra: Adatintegrációs katasztrófa a LinkedInben
Néhány évvel ezelőtt a LinkedIn mérnökei rájöttek, hogy a rendszerük túl bonyolulttá vált. A szolgáltatások, az előterek és a háttérrendszerek között teljes körű kommunikáció volt, mivel minden összetevő saját késési és átviteli sebességi követelményekkel rendelkezett. Egyetlen új szolgáltatás bevezetéséhez sok összetevőhöz kellet csatlakozni, ami nagyon törékeny végpontokhoz vezetett. Ez silókat is eredményezett, mivel nem volt egyszerű rávenni az egyes szolgáltatások tulajdonosait az adataik megosztására.
Az első változás a LinkedInnél az volt, hogy központosított, a Kafka által vezérelt adatfolyamat használata felé mozdultak el. Ez lehetővé tette az egyes szolgáltatásoknak, hogy adatokat hozzanak létre, és egy adott témakör használatával adják közre őket. Az adatok egy másik szolgáltatásból való elérése egyszerűvé vált, hiszen csak az adott témakörre kellett feliratkozni. Mivel a folyamat belsőleg futott egy elosztott fürtön, ezért arra számítottak, hogy eredendően skálázható lesz.
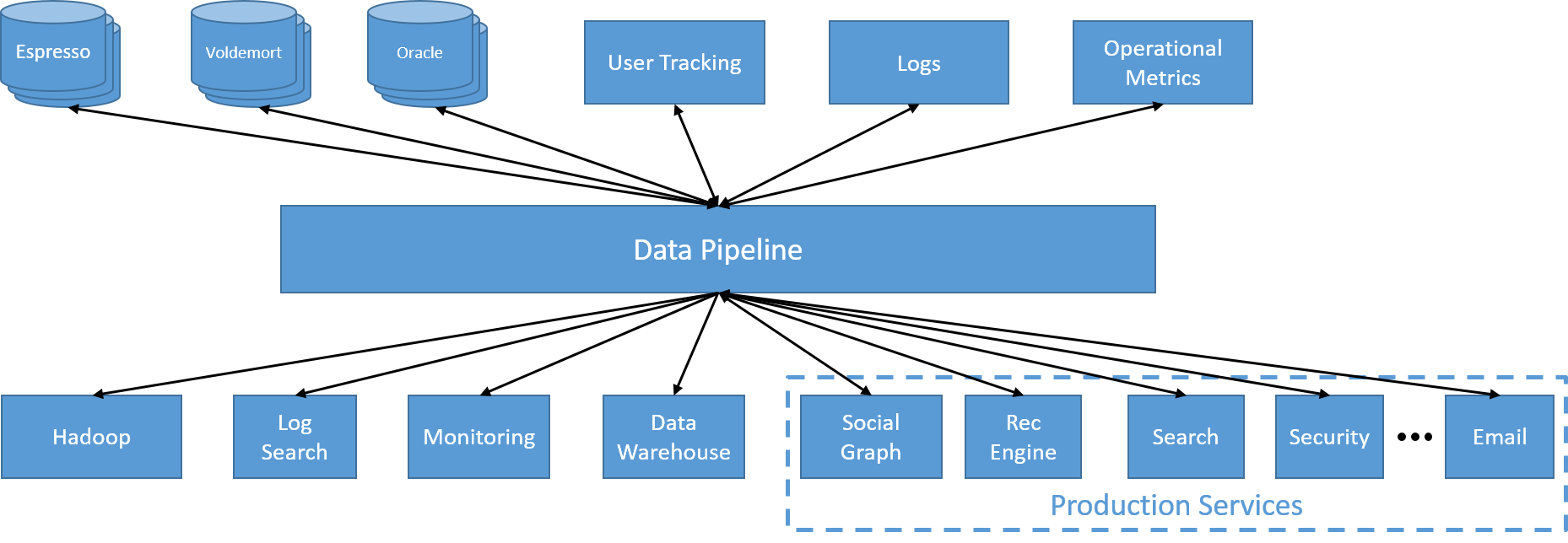
20. ábra: Egyetlen, elosztott, aszinkron adatfolyam
Szükség volt egy másik szolgáltatásra az adatközpontban lévő csomópontok tagságának kezeléséhez. Mivel a fel- és leskálázás egyszerűen csomópontok hozzáadását és eltávolítását jelentette a rendszerben, a ZooKeeper nevű új szolgáltatás a fürtön belüli tagság kezelésére, a partíciók és témakörök tulajdonjogának közvetítői szinten való elosztására, valamint az eltolások fogyasztói szinten történő megfelelő kezelésére szolgált.
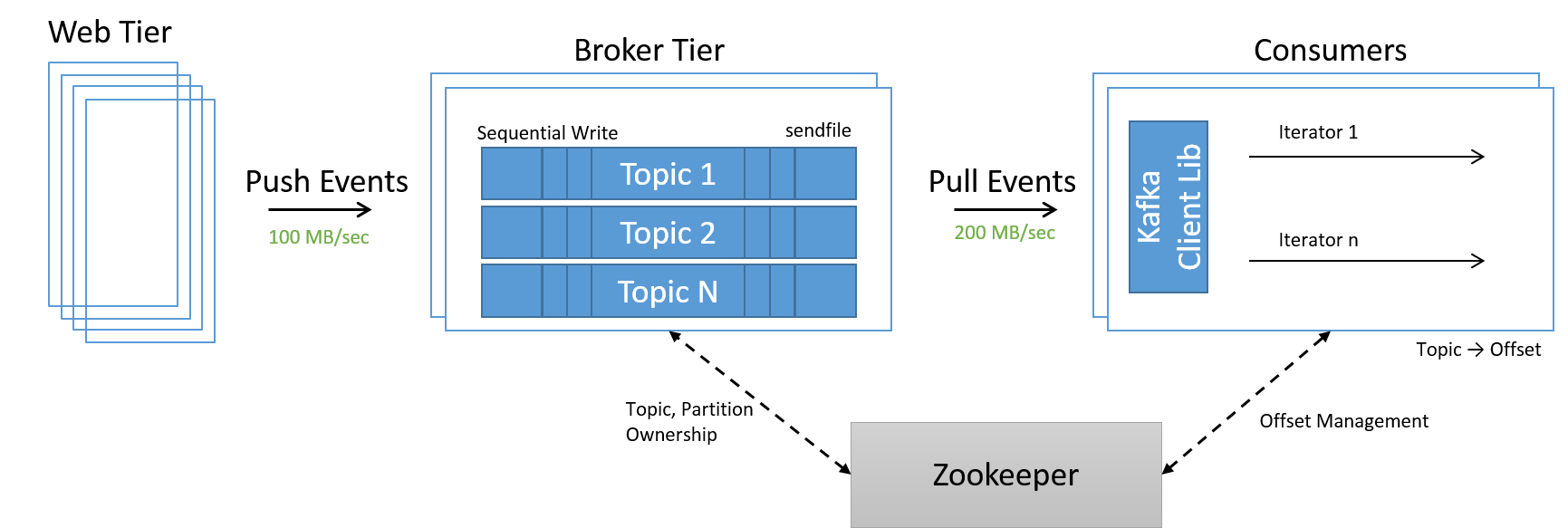
21. ábra: Nagy sebességű adatfeldolgozás Kafka-témakörök használatával
A LinkedIn architektúrájának változásait a reaktívabb rendszerek felé való elmozdulás is vezérelte. Az eredeti architektúrában (2010 körül) az összes felhasználói tevékenységnaplót egy kötegelt folyamat néhány óránként összegyűjtötte, és ezt új diagramok és irányítópultok létrehozására használták az előtérben. Ez az architektúra lehetővé tette, hogy a LinkedIn óránként vagy naponta friss információkat kapjon a megtekintések számáról, a felhasználói javaslatokról és a népszerű témakörökről.
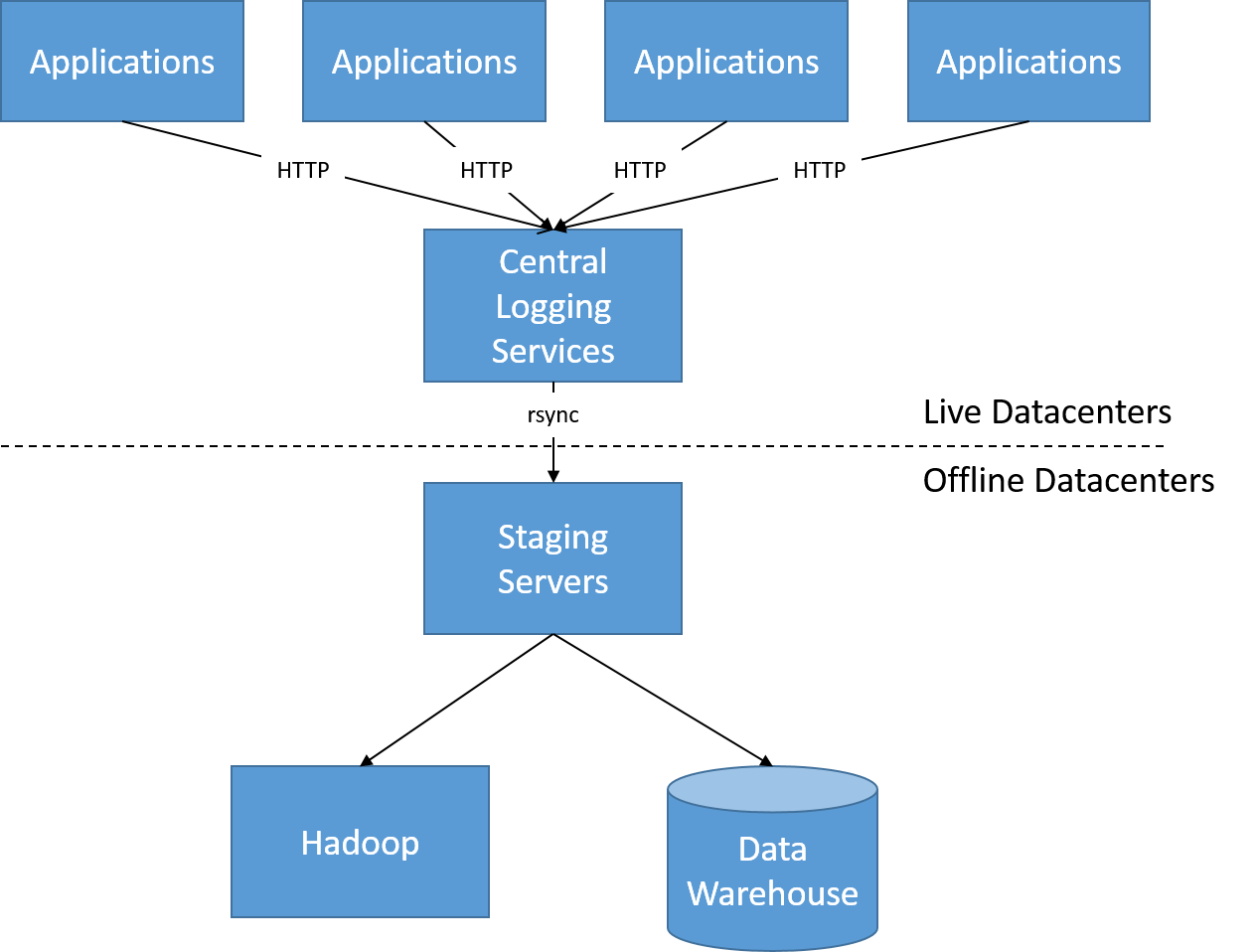
22. ábra: A felhasználói tevékenységnaplók offline feldolgozása előtt
Néhány órás késés azonban már nem volt elfogadható. Sem azon végfelhasználók számára, akik szerették volna megtudni az oldal megtekintési statisztikáit és tendenciáit az elmúlt öt percből, sem azon hirdetők és adatelemzők számára, akiknek valós időben kellett megjeleníteniük a releváns információkat. A hirdetések már nem kizárólag az adattárházak kattintássorozatainak offline elemzésén alapulnak, hanem egyre nagyobb hatással vannak rájuk az online frissítésű valós idejű modellek.
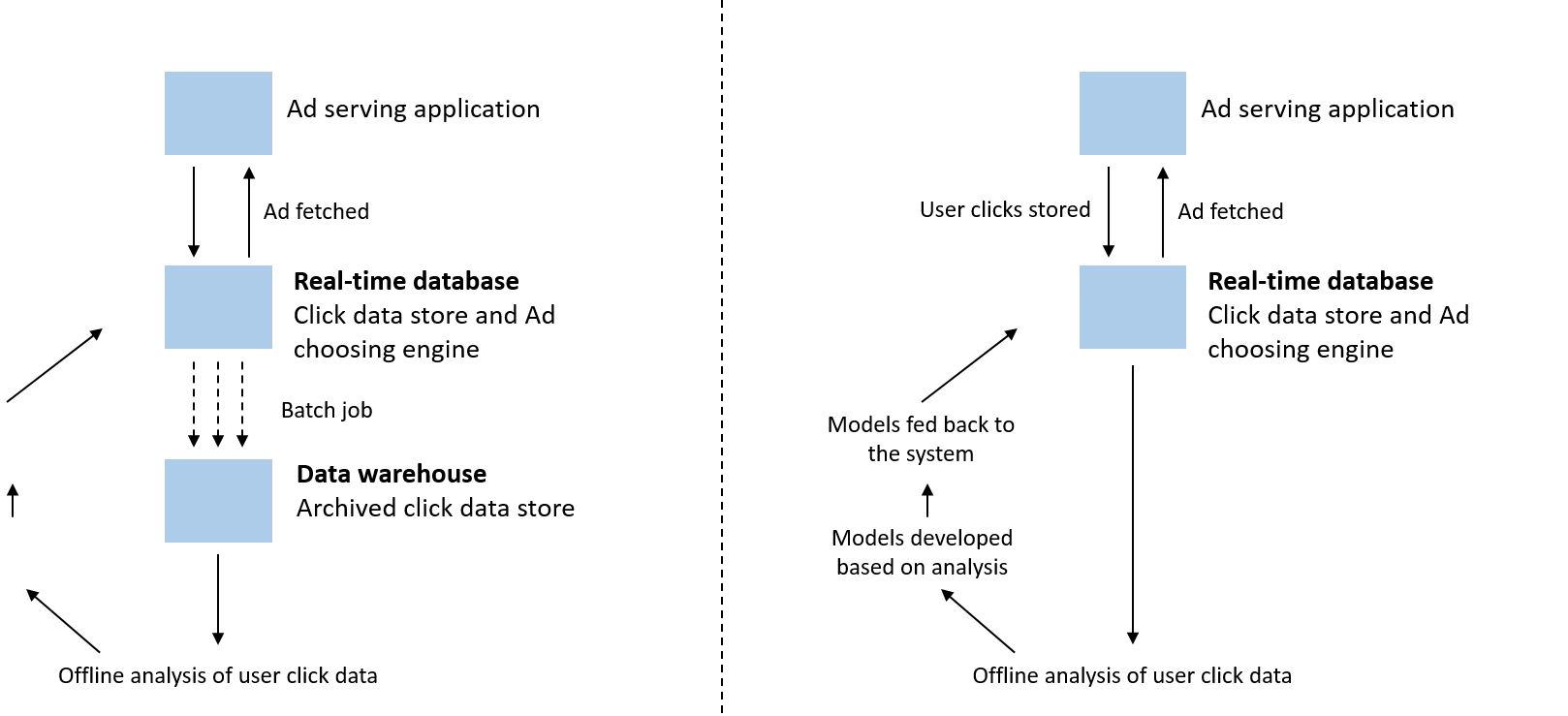
23. ábra: Balra: Hagyományos hirdetésmegjelenítés. Jobbra: A hirdetés kiszolgálásának modellezése.
A Samzával történő állapotalapú streamelés ezt teszi lehetővé. A hiteles adatok forrása általában az egyik központi adattár. Az adatbázisok azonban nem tudnak ilyen nagy mennyiségű egyidejű kérést kiszolgálni, hogy azok megfeleljenek az ajánlások és az összetett elemzési rendszerek valós idejű és összetett lekérdezéseinek. Emiatt nagy igény mutatkozott az adatközpont kétszakaszos sávszélességére is. Ehelyett a LinkedIn módszere az volt, hogy ugyanazt az adatstreamet használta több háttérrendszer frissítéséhez. Mivel tehát minden egyes fogyasztói csomópontnak helyi beágyazott adatbázisa volt, egyetlen frissítési esemény valós időben indította el a kapcsolódó frissítéseket ezen a helyi adatbázison.
Egy felhasználói profil frissítési eseményének egyszerű példája látható az alábbiakban. A profil a frissítésekor egy adott UserProfileUpdate témakörbe ír, amelyet felhasznál a hírcsatorna (így valós időben mutathatja meg, hogy a felhasználó egy új vállalathoz ment át) és a keresési adattár (így nem ad vissza elavult adatokat). Ezt az adatok offline feldolgozásához is felhasználja a rendszer (például egy adott vállalathoz csatlakozó szoftvermérnökök napi számának tendenciáit rögzíti).
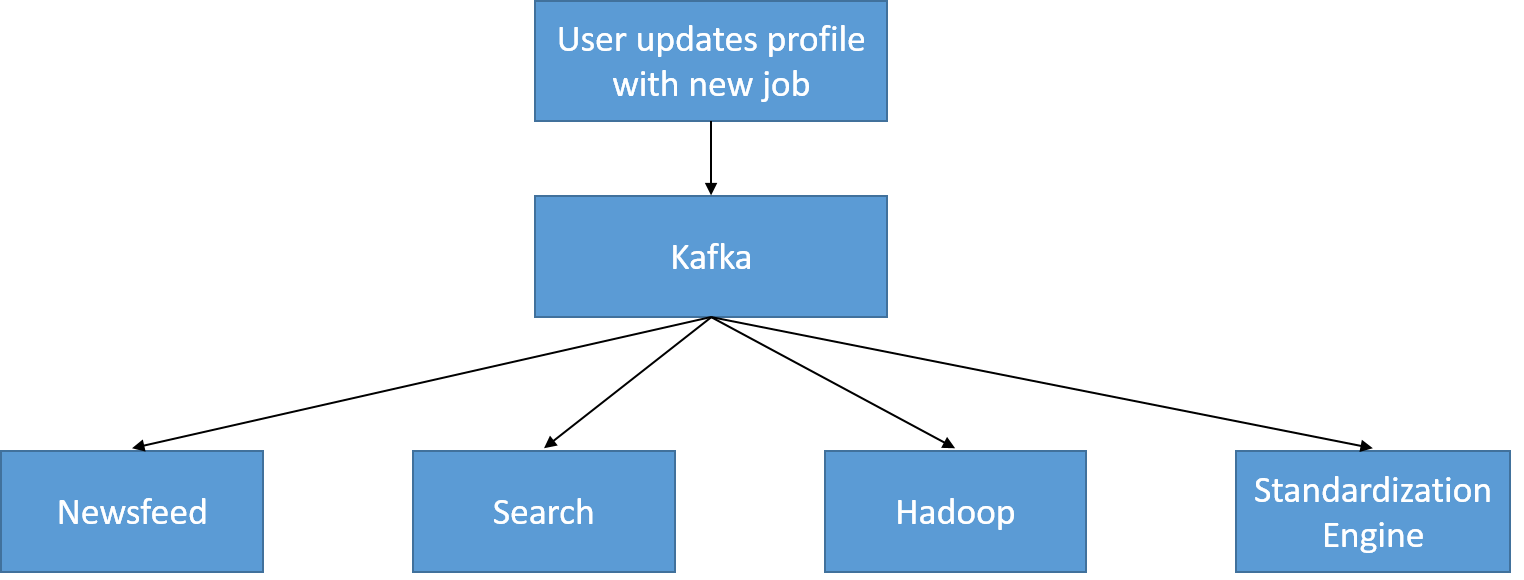
24. ábra: A UserProfileUpdate témakört a LinkedIn használja
Amikor számos technológiai nagyvállalathoz hasonló, nagy méretű webes, elosztott rendszereket futtat, a tervezés terén meghozott döntések között ellentmondás van. E vállalatok számos speciális rendszert hoztak létre, például adattárakat, hálózati összekötőket, kötegeket, interaktív és streamfeldolgozó keretrendszereket. Ennek az az oka, hogy a régi, univerzális megoldások már nem felelnek meg a mai felhasználók adott, szigorú követelményeinek. Ennek a megközelítésnek a hátránya azonban, hogy jelentős mennyiségű új, egyéni megoldást kell létrehozni az olyan problémákra, mint a hibák észlelése, a helyreállítás és a fürtkezelés. Az ilyen rendszerek irányába való elmozdulás legfőképpen a rugalmasság, a könnyű kezelhetőség és a skálázhatóság igényein alapul.
Itt láthatjuk azokat az előnyöket, amelyekre a LinkedIn tett szert a naplóorientált rendszer felé történő elmozdulással. Ez megkönnyítette a séma nélküli használatot, és egyszerűbb adatintegrációt tett lehetővé. Azáltal, hogy a skálázható naplóüzenetek első osztályú értékeket továbbítottak az adatközpontba, a LinkedIn nagy mértékben moduláris és rugalmas rendszer hozott létre.