Indexek tervezése
Az SQL Server számos indextípussal rendelkezik a különböző típusú számítási feladatok támogatásához. Magas szinten az indexek egy táblához vagy nézethez társított lemezen lévő struktúraként tekinthetők, amely lehetővé teszi, hogy az SQL Server könnyebben megtalálja az indexkulcshoz társított sorokat vagy sorokat (amelyek a táblázat vagy nézet egy vagy több oszlopából állnak), szemben a teljes táblázat vizsgálatával.
Fürtözött indexek
A DBA-állásinterjúval kapcsolatos gyakori kérdés, hogy megkérdezzük a jelölttől a fürtözött és a nemclustered index közötti különbséget, mivel az indexek az SQL Server alapvető adattárolási technológiái. A fürtözött index az alapul szolgáló tábla, amely a kulcsérték alapján rendezett sorrendben van tárolva. Egy adott táblában csak egy fürtözött index lehet, mert a sorok egy sorrendben tárolhatók. A fürtözött index nélküli táblákat halomnak nevezzük, a halomokat pedig általában csak átmeneti táblákként használják. A teljesítménytervezés egyik fontos alapelve, hogy a fürtözött indexkulcs a lehető legszűkebb legyen. Ha figyelembe veszi a fürtözött index kulcsoszlopait, érdemes figyelembe vennie az egyedi vagy sok különböző értéket tartalmazó oszlopokat. A jó fürtözött indexkulcsok másik tulajdonsága a szekvenciálisan elért rekordok, és gyakran használják a táblából lekért adatok rendezésére. A rendezéshez használt oszlop fürtözött indexe megakadályozhatja a rendezés költségeit minden alkalommal, amikor a lekérdezés végrehajtja, mert az adatok már a kívánt sorrendben lesznek tárolva.
Feljegyzés
Amikor azt mondjuk, hogy a tábla egy adott sorrendben van tárolva, akkor a logikai sorrendre hivatkozunk, nem feltétlenül a fizikai, lemezre vonatkozó sorrendre. Az indexek mutatókkal rendelkeznek a lapok között, és a mutatók segítenek létrehozni a logikai sorrendet. Az index "sorrendben" történő vizsgálatakor az SQL Server a lapról lapra mutató mutatókat követi. Közvetlenül az index létrehozása után valószínűleg fizikai sorrendben is tárolva lesz a lemezen, de miután megkezdte az adatok módosítását, és új lapokat kell hozzáadni az indexhez, a mutatók továbbra is a megfelelő logikai sorrendet adják nekünk, de az új lapok a leginkább úgy fognak kinézni, mintha nem lenne fizikai lemez sorrendben.
Nemclustered indexek
A nemclustered indexek az adatsoroktól eltérő struktúrát alkotnak. A nemclustered index tartalmazza az indexhez definiált kulcsértékeket, és egy mutatót a kulcsértéket tartalmazó adatsorhoz. A nemclustered index levélszintje egy másik nem kulcsos oszlopot is felvehet, hogy több oszlopot fedjen le az SQL Server belefoglalt oszlopainak funkciójával. Több nemclustered indexet is létrehozhat egy táblán.
Az alábbiakban látható egy példa arra, amikor indexet kell hozzáadnia vagy oszlopokat kell hozzáadnia egy meglévő nemclustered indexhez:

A lekérdezési terv azt jelzi, hogy az indexkereséssel lekért összes sorhoz több adatot kell lekérni a fürtözött indexből (magából a táblából). Van egy nemclustered index, de csak a termékoszlopot tartalmazza. Ha a lekérdezés többi oszlopát hozzáadja egy nemclustered indexhez az alább látható módon, a végrehajtási terv módosításával kiküszöbölheti a kulcskeresést.

A fent létrehozott index egy példa egy lefedő indexre, ahol a kulcsoszlop mellett további oszlopokat is belefoglal a lekérdezés lefedéséhez, és nem szükséges magát a táblát elérni.
A nemclustered és a fürtözött indexek is meghatározhatók egyediként, ami azt jelenti, hogy a kulcsértékek nem duplikáltak. Az egyedi indexek automatikusan létrejönnek, amikor elsődleges kulcsot vagy EGYEDI korlátozást hoz létre egy táblán.
Ennek a szakasznak a fókusza az SQL Server bfa indexeire összpontosít – ezeket sortároló indexeknek is nevezik. A b-fa általános szerkezete az alábbiakban látható:
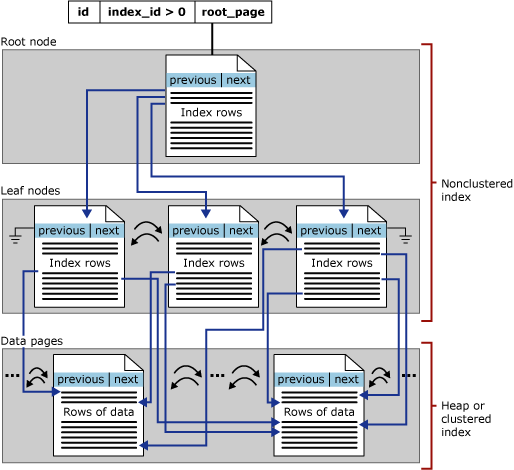
Az index b fájának minden lapja indexcsomópont, a b-fa felső csomópontja pedig gyökércsomópont. Az index alsó csomópontjait levélcsomópontoknak nevezzük, a levélcsomópontok gyűjteménye pedig a levélszint.
Az indextervezés a művészet és a tudomány keveréke. Egy szűk index, amelynek kulcsában néhány oszlop található, kevesebb időt igényel a frissítés, és alacsonyabb karbantartási többletterheléssel jár; azonban nem feltétlenül hasznos annyi lekérdezés esetén, mint egy szélesebb index, amely több oszlopot tartalmaz. Előfordulhat, hogy több indexelési módszerrel kell kísérleteznie az alkalmazás lekérdezései által kiválasztott oszlopok alapján. A lekérdezésoptimalizáló általában azt választja ki, hogy mit tart a lekérdezés legjobb meglévő indexének; Ez azonban nem jelenti azt, hogy nem lehetne jobb indexet létrehozni.
Az adatbázisok megfelelő indexelése összetett feladat. A táblák indexeinek tervezésekor figyelembe kell vennie néhány alapelvet:
- Ismerje meg a rendszer számítási feladatait. A főként beszúrási műveletekhez használt táblák sokkal kevésbé lesznek extra indexek, mint az adatraktár-műveletekhez használt táblák, amelyek 90%-os olvasási tevékenységet végeznek.
- Megismerheti a leggyakrabban futtatott lekérdezéseket, és optimalizálhatja az indexeket a lekérdezések köré.
- Ismerje meg a lekérdezésekben használt oszlopok adattípusait. Az indexek ideálisak egész adattípusokhoz, egyedi vagy nem null oszlopokhoz.
- Hozzon létre nemclustered indexeket az oszlopokon, amelyeket gyakran használnak predikátumokban és illesztési záradékokban, és tartsa ezeket az indexeket a lehető legszűkebbre a többletterhelés elkerülése érdekében.
- Az adatméret/kötet megismerése – Egy kis táblán végzett táblavizsgálat viszonylag olcsó művelet lesz, és az SQL Server dönthet úgy, hogy egyszerűen végez táblázatvizsgálatot, egyszerűen azért, mert egyszerű (triviális) feladat. Egy nagy táblán végzett táblavizsgálat költséges lenne.
Az SQL Server egy másik lehetősége a szűrt indexek létrehozása. A szűrt indexek leginkább olyan nagyméretű táblák oszlopaihoz ideálisak, ahol a sorok nagy százaléka ugyanazt az értéket tartalmazza az oszlopban. Gyakorlati példa lehet egy alkalmazotti tábla, ahogy az alább látható, amely az összes alkalmazott rekordját tárolta, beleértve azokat is, akik távoztak vagy kivezették őket.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
Ebben a táblázatban található egy CurrentFlag nevű oszlop, amely azt jelzi, hogy jelenleg alkalmazott dolgozik-e. Ez a példa a bit adattípust használja, amely csak két értéket jelez, egyet a jelenleg alkalmazotthoz, egyet pedig a jelenleg nem alkalmazottakhoz. A CurrentFlag oszlopban lévő szűrt index WHERE CurrentFlag = 1lehetővé tenné az aktuális alkalmazottak hatékony lekérdezését.
A nézeteken indexeket is létrehozhat, amelyek jelentős teljesítménynövekedést biztosíthatnak, ha a nézetek lekérdezési elemeket, például összesítéseket és/vagy táblacsatlakozásokat tartalmaznak.
Oszlopcentrikus indexek
A Columnstore jobb teljesítményt nyújt a nagy összesítési számítási feladatokat futtató lekérdezésekhez. Ezt az indextípust eredetileg adattárházakra célozták, de idővel az oszlopcentrikus indexeket számos más számítási feladatban használták a nagy táblák lekérdezési teljesítményével kapcsolatos problémák megoldásához. Az SQL Server 2014-hez hasonlóan vannak nemclustered és fürtözött oszlopcentrikus indexek is. A bfa indexekhez hasonlóan a fürtözött oszlopcentrikus index maga a tábla, amely speciális módon van tárolva, a nem rendezett oszlopcentrikus indexek pedig a táblától függetlenül vannak tárolva. A fürtözött oszlopcentrikus indexek magukban foglalják az adott tábla összes oszlopát. A sorcentrikus fürtözött indexekkel ellentétben azonban a fürtözött oszlopcentrikus indexek NEM vannak rendezve.
A nemclustered oszlopcentrikus indexeket általában két forgatókönyvben használják, az első az, amikor a tábla egyik oszlopa olyan adattípussal rendelkezik, amely nem támogatott egy oszlopcentrikus indexben. A legtöbb adattípus támogatott, de az XML, a CLR, a sql_variant, az ntext, a szöveg és a kép nem támogatott az oszlopcentrikus indexekben. Mivel a fürtözött oszloptárak mindig tartalmazzák a tábla összes oszlopát (mivel ez a tábla), a nem teljes oszlop az egyetlen lehetőség. A második forgatókönyv egy szűrt index – ezt a forgatókönyvet egy hibrid tranzakciós elemzési feldolgozásnak (HTAP) nevezett architektúrában használják, ahol az adatok betöltődnek az alapul szolgáló táblába, és ezzel egyidejűleg a jelentések is futnak a táblán. Az index szűrésével (általában dátummezőn) ez a kialakítás jó beszúrási és jelentéskészítési teljesítményt tesz lehetővé.
Az oszlopcentrikus indexek a tárolási mechanizmusukban egyediek, mivel az index minden oszlopa egymástól függetlenül van tárolva. Kétrészes előnyt kínál. Az oszlopcentrikus indexet használó lekérdezéseknek csak a lekérdezés teljesítéséhez szükséges oszlopokat kell megvizsgálniuk, csökkentve az elvégzett teljes I/O-t, és lehetővé teszi a nagyobb tömörítést, mivel az ugyanabban az oszlopban lévő adatok valószínűleg hasonló jellegűek lesznek.
Az oszlopcentrikus indexek a legjobban olyan elemzési lekérdezéseken teljesítenek, amelyek nagy mennyiségű adatot vizsgálnak, például egy adattárházban lévő ténytáblákat. Az SQL Server 2016-tól kezdve egy oszlopcentrikus indexet egy másik bfa nemclustered indexkel bővíthet, ami akkor lehet hasznos, ha egyes lekérdezések egyetlentonos értékeket keresnek.
Az oszlopcentrikus indexek kihasználják a kötegvégrehajtási módot is, amely egy sorkészlet (általában 900 körüli) feldolgozására utal, szemben az adatbázismotorral, amely egyenként dolgozza fel ezeket a sorokat. Az egyes rekordok egymástól függetlenül való betöltése és feldolgozása helyett a lekérdezési motor kiszámítja a számítást abban a 900 rekordból álló csoportban. Ez a feldolgozási modell jelentősen csökkenti a processzorutasítások számát.
SELECT SUM(Sales) FROM SalesAmount;
A Batch mód jelentős teljesítménynövekedést biztosíthat a hagyományos sorfeldolgozáshoz. Az SQL Server 2019 kötegelt módot is tartalmaz a sortáradatokhoz. Bár a sortár kötegmódja nem rendelkezik ugyanolyan olvasási teljesítménnyel, mint egy oszlopcentrikus index, az elemzési lekérdezések akár ötször jobb teljesítményt is láthatnak.
Az adatraktár-számítási feladatokhoz kínált egyéb juttatási oszlopcentrikus indexek optimalizált terhelési útvonalként szolgálnak 102 400 sor vagy több sor tömeges beszúrására. Míg a 102 400 a minimális érték, amelyet közvetlenül az oszloptárba kell betölteni, minden sorcsoport, úgynevezett sorcsoport akár 1 024 000 sort is tartalmazhat. Ha kevesebb, de teljesebb sorcsoporttal rendelkezik, az Standard kiadás LECT-lekérdezések hatékonyabbak, mivel kevesebb sorcsoportot kell beolvasni a kért rekordok lekéréséhez. Ezek a terhelések a memóriában történnek, és közvetlenül az indexbe vannak betöltve. Kisebb kötetek esetén az adatok egy deltatárolónak nevezett b-fastruktúrába lesznek beírva, és aszinkron módon betöltve az indexbe.
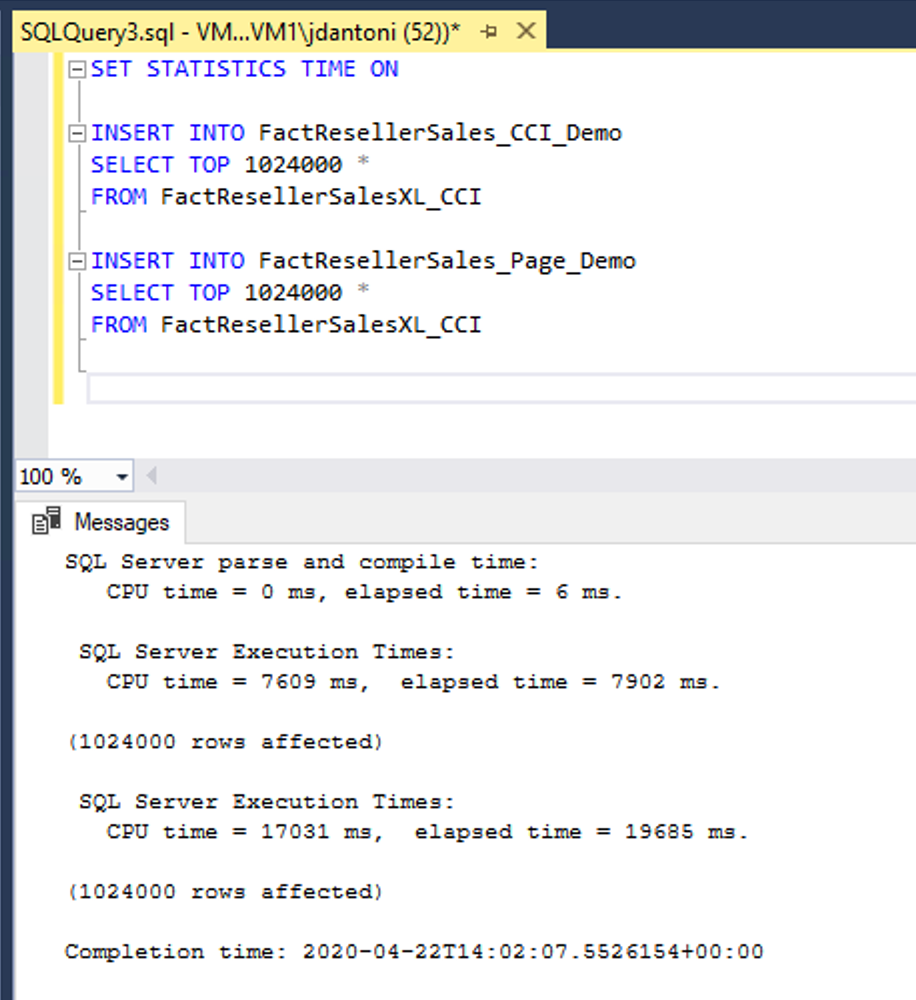
Ebben a példában ugyanazokat az adatokat tölti be két táblába, FactResellerSales_CCI_Demo és FactResellerSales_Page_Demo. A FactResellerSales_CCI_Demo egy fürtözött oszlopcentrikus indexkel rendelkezik, a FactResellerSales_Page_Demo pedig két oszlopból áll, és laptömörítve van. Mint látható, minden tábla 1 024 000 sort tölt be a FactResellerSalesXL_CCI táblából. Ha SET STATISTICS TIME igen, az ONSQL Server nyomon követi a lekérdezés végrehajtásának eltelt idejét. Az adatok oszlopcentrikus táblába való betöltése körülbelül 8 másodpercet vett igénybe, ahol a tömörített lapra való betöltés közel 20 másodpercet vett igénybe. Ebben a példában az oszlopcentrikus indexbe tartozó összes sor egyetlen sorcsoportba lesz betöltve.
Ha egy műveletben kevesebb mint 102 400 sornyi adatot tölt be egy oszlopcentrikus indexbe, az egy bfa szerkezetbe, más néven deltatárolóba lesz betöltve. Az adatbázismotor ezeket az adatokat egy aszinkron folyamat, az úgynevezett tuple-mozgatás segítségével helyezi át az oszlopcentrikus indexbe. A nyitott delta-tárolók hatással lehetnek a lekérdezések teljesítményére, mivel a rekordok olvasása kevésbé hatékony, mint az oszloptárból való olvasás. Az indexet úgy is átrendezheti, COMPRESS_ALL_ROW_GROUPS hogy kényszerítse a deltatárolók hozzáadását és tömörítését az oszlopcentrikus indexekbe.