Besorolási modellek kiértékelése
A besorolási modellek betanítási pontossága sokkal kevésbé fontos, mint az, hogy a modell milyen jól működjön, ha új, nem látott adatokat ad meg. Végül is betanítottuk a modelleket, hogy felhasználhatók legyenek a valós világban talált új adatokon. A besorolási modell betanítása után tehát kiértékeljük, hogyan működik az új, nem látott adatok halmazán.
Az előző egységekben létrehoztunk egy modellt, amely előrejelezi, hogy egy beteg cukorbeteg-e, vagy sem a vércukorszintje alapján. Most, ha olyan adatokra alkalmazunk, amelyek nem részei a betanítási készletnek, az alábbi előrejelzéseket kapjuk.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 0 | 0 |
| 104 | 0 | 0 |
| 105 | 0 | 0 |
| 86 | 0 | 0 |
| 109 | 0 | 0 |
Ne feledje, hogy az x a vércukorszintre utal, y arra utal, hogy valóban cukorbetegek-e, és ŷ a modell előrejelzésére utal arra, hogy cukorbetegek-e vagy sem.
A helyes előrejelzések számának kiszámítása néha félrevezető vagy túl leegyszerűsítő ahhoz, hogy megértsük, milyen hibákat fog okozni a valóságban. Részletesebb információkért az eredményeket egy keveredési mátrixnak nevezett struktúrában táblázatosíthatjuk, például a következőt:
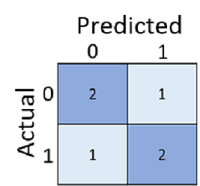
A keveredési mátrix az esetek teljes számát mutatja, ahol:
- A modell 0-t jelzett előre, a tényleges címke pedig 0 (igaz negatívok, bal felső)
- A modell 1-et jósolt, a tényleges címke pedig 1 (igaz pozitív, jobb alsó)
- A modell 0-t jelzett előre, a tényleges címke pedig 1 (hamis negatívok, bal alsó rész)
- A modell 1-et jósolt, a tényleges címke pedig 0 (hamis pozitív, jobb felső)
A keveredési mátrixban lévő cellákat gyakran árnyékolja a rendszer, hogy a magasabb értékek mélyebb árnyalattal rendelkezzenek. Ez megkönnyíti az erős átlós trendek megjelenítését a bal felsőtől a jobb alsó sarokig, kiemelve azokat a cellákat, amelyekben az előrejelzett érték és a tényleges érték megegyezik.
Ezekből az alapvető értékekből kiszámolhat más metrikák tartományát, amelyek segíthetnek a modell teljesítményének kiértékelésében. Példa:
- Pontosság: (TP+TN)/(TP+TN+FP+FN) – az összes előrejelzés közül hány helyes?
- Visszahívás: TP/(TP+FN) – a pozitív esetek közül hányat azonosított a modell?
- Pontosság: TP/(TP+FP) – az összes olyan eset közül, amelyet a modell pozitívnak jelzett, valójában hány pozitív?