Mi adatfolyamokkal
Ez a cikk bemutatja, hogyan használhat mesterséges intelligenciát (AI) adatfolyamokkal. Ez a cikk a következőket ismerteti:
- Cognitive Services
- Automatizált gépi tanulás
- Azure Machine Tanulás integrációja
Cognitive Services a Power BI-ban
A Cognitive Services a Power BI-ban az Azure Cognitive Services különböző algoritmusaival bővítheti adatait az adatfolyamokhoz készült önkiszolgáló adat-előkészítésben.
A ma támogatott szolgáltatások a hangulatelemzés, a kulcskifejezések kinyerése, a nyelvfelismerés és a képcímkézés. Az átalakítások végrehajtása a Power BI szolgáltatás történik, és nincs szükség Azure Cognitive Services-előfizetésre. Ehhez a funkcióhoz Power BI Premium szükséges.
AI-funkciók engedélyezése
A kognitív szolgáltatások támogatottak az EM2, A2 vagy P1 prémium szintű kapacitáscsomópontokhoz és más, több erőforrással rendelkező csomópontokhoz. A cognitive services premium per user (PPU) licenccel is elérhető. A kapacitáson egy külön AI-számítási feladatot használnak a kognitív szolgáltatások futtatásához. Mielőtt kognitív szolgáltatásokat használ a Power BI-ban, engedélyezni kell az AI-számítási feladatot a Rendszergazda portál kapacitásbeállításaiban. A számítási feladatok szakaszban bekapcsolhatja az AI-számítási feladatot, és meghatározhatja, hogy a számítási feladat mekkora memóriát használjon fel. Az ajánlott memóriakorlát 20%. Ha túllépi ezt a korlátot, a lekérdezés lelassul.

A Cognitive Services használatának első lépései a Power BI-ban
A Cognitive Services-átalakítások az adatfolyamokhoz készült önkiszolgáló adat-előkészítés részét képezik. Az adatok Cognitive Services szolgáltatással való bővítéséhez először szerkessze az adatfolyamot.

Válassza a Power Query-szerkesztő felső menüszalagjának AI-elemzések gombját.

Az előugró ablakban válassza ki a használni kívánt függvényt és az átalakítani kívánt adatokat. Ez a példa egy felülvizsgálati szöveget tartalmazó oszlop hangulatát jelzi.

A LanguageISOCode nem kötelező bemenet a szöveg nyelvének megadásához. Ez az oszlop ISO-kódot vár. Használhat oszlopot a LanguageISOCode bemeneteként, vagy használhat statikus oszlopot is. Ebben a példában a nyelv angol (en) formátumban van megadva az egész oszlophoz. Ha ezt az oszlopot üresen hagyja, a Power BI automatikusan észleli a nyelvet a függvény alkalmazása előtt. Ezután válassza a Meghívás lehetőséget.

A függvény meghívása után az eredmény új oszlopként lesz hozzáadva a táblához. Az átalakítás a lekérdezés alkalmazott lépéseként is hozzáadódik.

Ha a függvény több kimeneti oszlopot ad vissza, a függvény meghívása új oszlopot ad hozzá a több kimeneti oszlop sorával.
A kibontás lehetőséggel oszlopként adhat hozzá egy vagy mindkét értéket az adatokhoz.

Elérhető függvények
Ez a szakasz a Power BI Cognitive Servicesben elérhető funkcióit ismerteti.
Nyelv észlelése
A nyelvészlelési függvény kiértékeli a szövegbevitelt, és minden oszlophoz visszaadja a nyelv nevét és az ISO-azonosítót. Ez a függvény olyan adatoszlopok esetében hasznos, amelyek tetszőleges szöveget gyűjtenek, ahol a nyelv ismeretlen. A függvény szöveges formátumú adatokat vár bemenetként.
A Text Analytics 120 nyelv felismerésére képes. További információ: Mi az a nyelvfelismerés az Azure Cognitive Service for Language szolgáltatásban?
Kulcskifejezések kinyerése
A Kulcskifejezések kinyerése függvény strukturálatlan szöveget értékel ki, és minden egyes szövegoszlophoz visszaadja a kulcskifejezések listáját. A függvény bemenetként szöveges oszlopot igényel, és elfogadja a LanguageISOCode opcionális bemenetét. További információt az Első lépések című témakörben talál.
A kulcskifejezések kinyerése akkor működik a legjobban, ha nagyobb mennyiségű szöveget ad a munkához, ellentétben a hangulatelemzéssel. A hangulatelemzés jobb teljesítményt nyújt a kisebb szövegblokkokon. A legjobb eredmény elérése érdekében célszerű a bemenetet ennek megfelelően átszervezni.
Hangulatpontszámozás
A Score Sentiment függvény kiértékeli a szövegbevitelt, és minden dokumentumhoz egy hangulatpontot ad vissza, amely 0 (negatív) és 1 (pozitív) között van. Ez a funkció hasznos a pozitív és negatív hangulat észleléséhez a közösségi médiában, az ügyfelek véleményeiben és a vitafórumokon.
A Text Analytics gépi tanulási osztályozó algoritmussal generálja a 0 és 1 közötti hangulatpontszámot. Az 1-hez közelebbi pontszámok pozitív hangulatot jeleznek. A 0-hoz közelebbi pontszámok negatív hangulatot jeleznek. A modell előre betanításra kerül egy átfogó szövegtörzsgel, hangulattársításokkal. Jelenleg nem lehet saját betanítási adatokat megadni. A modell a szövegelemzés során több technika kombinációját alkalmazza, beleértve a szövegfeldolgozást, a beszédrészlet elemzést, a szóelhelyezést és szótársításokat. Az algoritmusról további információt a Machine Tanulás és a Text Analytics című témakörben talál.
A hangulatelemzés a teljes bemeneti oszlopon történik, nem pedig egy adott táblázat hangulatának kinyerése a szövegben. A gyakorlatban az a tendencia tapasztalható, hogy a pontozás pontossága javul, ha a dokumentumok egy vagy két mondatot tartalmaznak, nem pedig egy nagy szövegblokkot. Az objektivitás-felmérési fázisban a modell meghatározza, hogy egy bemeneti oszlop egésze objektív vagy hangulatot tartalmaz-e. A többnyire objektív bemeneti oszlop nem halad tovább a hangulatészlelési kifejezésig, ami 0,50-es pontszámot eredményez, további feldolgozás nélkül. A folyamatban folytatódó bemeneti oszlopok esetében a következő fázis 0,50-nél nagyobb vagy kisebb pontszámot hoz létre a bemeneti oszlopban észlelt hangulat mértékétől függően.
A Hangulatelemzés jelenleg az angol, német, spanyol és francia nyelvet támogatja. Más nyelvek előzetes verzióban érhetők el. További információ: Mi az a nyelvfelismerés az Azure Cognitive Service for Language szolgáltatásban?
Képek címkézése
A Címkeképek függvény több mint 2000 felismerhető objektum, élőlény, táj és művelet alapján ad vissza címkéket. Ha a címkék nem egyértelműek vagy nem általánosak, a kimenet "tippeket" ad a címke jelentésének tisztázásához egy ismert beállítás kontextusában. A címkék nincsenek rendszerezve osztályozásként, és nem léteznek öröklési hierarchiák. A tartalomcímkék gyűjteménye képezi a kép ember által olvasható nyelven, teljes mondatokban megformált „leírásának” alapját.
Egy kép feltöltése vagy egy kép URL-címének megadása után a Computer Vision algoritmusok a képen azonosított objektumok, élőlények és műveletek alapján kimenetcímkéket adnak ki. A címkézés nem korlátozódik a kép fő témájára, például az előtérben szereplő személyre, hanem magában foglalja a környezetet (beltér vagy kültér), bútorokat, eszközöket, növényeket, állatokat, kiegészítőket, készülékeket stb.
Ehhez a függvényhez kép URL-cím vagy abase-64 oszlop szükséges bemenetként. A képcímkézés jelenleg az angol, a spanyol, a japán, a portugál és az egyszerűsített kínai nyelvet támogatja. További információ: ComputerVision Interface.
Automatizált gépi tanulás a Power BI-ban
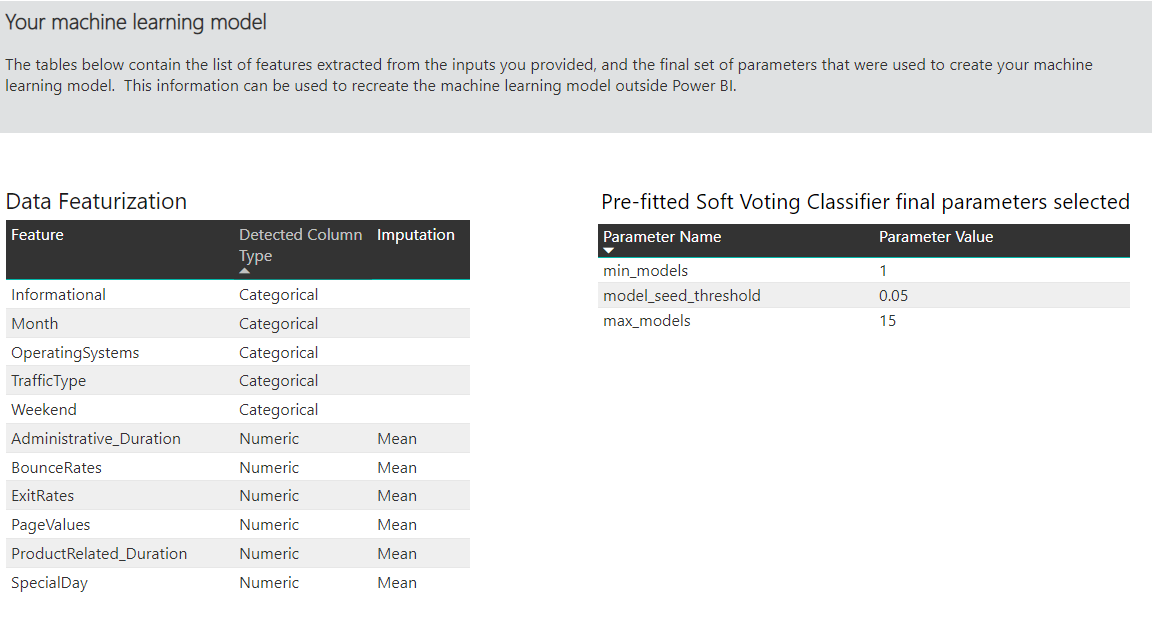
Az adatfolyamokhoz készült automatizált gépi tanulás (AutoML) lehetővé teszi az üzleti elemzők számára, hogy közvetlenül a Power BI-ban betanítsa, érvényesítse és meghívja a gépi tanulási modelleket. Ez egy egyszerű felületet biztosít egy új ML-modell létrehozásához, ahol az elemzők az adatfolyamaik segítségével adhatók meg a bemeneti adatok a modell betanításához. A szolgáltatás automatikusan kinyeri a legrelevánsabb funkciókat, kiválaszt egy megfelelő algoritmust, és hangolja és ellenőrzi az ML-modellt. A modell betanítása után a Power BI automatikusan létrehoz egy teljesítményjelentést, amely tartalmazza az ellenőrzés eredményeit. A modell ezután meghívható minden új vagy frissített adaton az adatfolyamon belül.
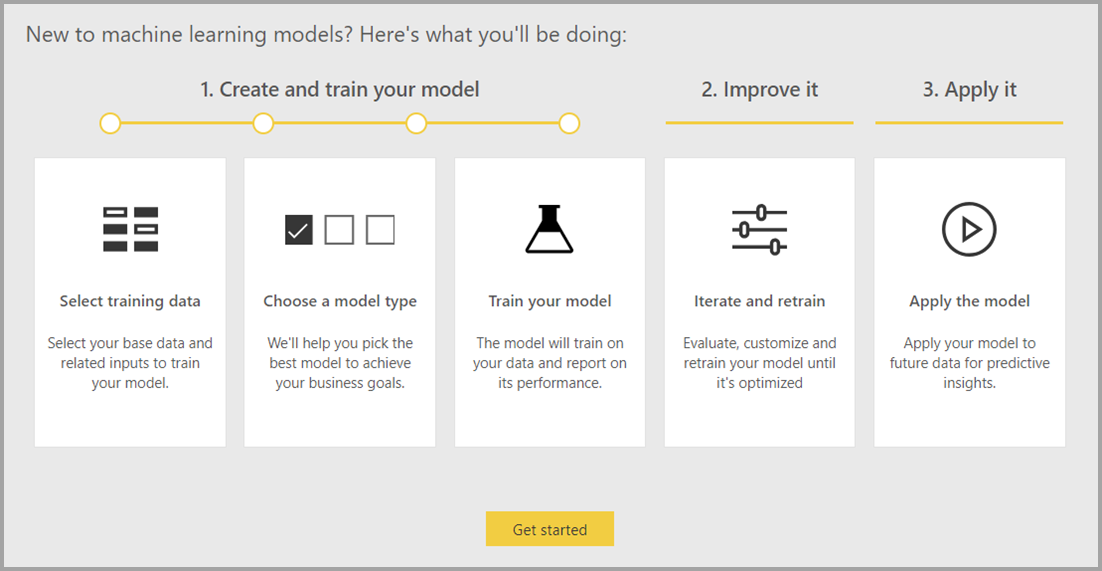
Az automatizált gépi tanulás csak a Power BI Premium- és Embedded-kapacitásokon üzemeltetett adatfolyamokhoz érhető el.
Az AutoML működése
A gépi tanulás és az AI az iparágak és a tudományos kutatási területek népszerűségének példátlan növekedését látja. A vállalkozások azt is keresik, hogyan integrálhatják ezeket az új technológiákat a működésükbe.
Az adatfolyamok önkiszolgáló adat-előkészítést kínálnak big data-adatokhoz. Az AutoML integrálva van az adatfolyamokba, és lehetővé teszi az adat-előkészítési munkát gépi tanulási modellek készítéséhez, közvetlenül a Power BI-ban.
Az AutoML a Power BI-ban lehetővé teszi az adatelemzők számára, hogy adatfolyamok használatával gépi tanulási modelleket építsenek ki egyszerűbben, csak Power BI-készségek használatával. A Power BI automatizálja a legtöbb adatelemzést az ML-modellek létrehozása mögött. Védőkorlátokkal rendelkezik, hogy a létrehozott modell jó minőségű legyen, és betekintést nyújt az ML-modell létrehozásához használt folyamatba.
Az AutoML támogatja a bináris előrejelzési, besorolási és regressziós modellek létrehozását adatfolyamokhoz. Ezek a funkciók a felügyelt gépi tanulási technikák típusai, ami azt jelenti, hogy a múltbeli megfigyelések ismert eredményeiből tanulnak más megfigyelések eredményeinek előrejelzéséhez. Az AutoML-modellek betanításához használt bemeneti szemantikai modell az ismert eredményekkel címkézett sorok halmaza.
Az AutoML a Power BI-ban integrálja az Azure Machine-Tanulás automatizált gépi tanulástaz ML-modellek létrehozásához. Az AutoML Power BI-ban való használatához azonban nincs szüksége Azure-előfizetésre. A Power BI szolgáltatás teljes mértékben kezeli az ML-modellek betanításának és üzemeltetésének folyamatát.
Az ml-modell betanítása után az AutoML automatikusan létrehoz egy Power BI-jelentést, amely elmagyarázza az ML-modell várható teljesítményét. Az AutoML a magyarázhatóságot hangsúlyozza, ha kiemeli a főbb befolyásolókat a bemenetek között, amelyek befolyásolják a modell által visszaadott előrejelzéseket. A jelentés a modell fő mérőszámait is tartalmazza.
A létrehozott jelentés más oldalai a modell statisztikai összegzését és a betanítás részleteit mutatják. A statisztikai összegzés olyan felhasználók számára érdekes, akik szeretnék látni a modellteljesítmény szabványos adatelemzési mérőszámokát. A betanítás részletei összefoglalják a modell létrehozásához futtatott összes iterációt a kapcsolódó modellezési paraméterekkel együtt. Azt is leírja, hogyan használták az egyes bemeneteket az ML-modell létrehozásához.
Ezután az ML-modellt alkalmazhatja az adatokra pontozás céljából. Az adatfolyam frissítésekor az adatok frissülnek az ML-modell előrejelzéseivel. A Power BI emellett személyre szabott magyarázatot is tartalmaz az ML-modell által előállított egyes előrejelzésekhez.
Gépi tanulási modell létrehozása
Ez a szakasz azt ismerteti, hogyan hozhat létre AutoML-modellt.
Adat-előkészítés ml-modell létrehozásához
Ha gépi tanulási modellt szeretne létrehozni a Power BI-ban, először létre kell hoznia egy adatfolyamot az előzményeredmény-adatokat tartalmazó adatokhoz, amelyet az ML-modell betanításához használnak. Számított oszlopokat is hozzá kell adnia minden olyan üzleti mérőszámhoz, amely erős előrejelző lehet az előrejelezni kívánt eredményhez. Az adatfolyam konfigurálásával kapcsolatos részletekért lásd : Adatfolyam konfigurálása és felhasználása.
Az AutoML-nek konkrét adatkövetelményei vannak a gépi tanulási modellek betanításához. Ezeket a követelményeket a következő szakaszok ismertetik a megfelelő modelltípusok alapján.
Az ML-modell bemeneteinek konfigurálása
AutoML-modell létrehozásához válassza az adatfolyamtábla Műveletek oszlopában az ML ikont, majd válassza a Gépi tanulási modell hozzáadása lehetőséget.
Elindul egy egyszerűsített felület, amely egy varázslóból áll, amely végigvezeti az ML-modell létrehozásának folyamatán. A varázsló az alábbi egyszerű lépéseket tartalmazza.
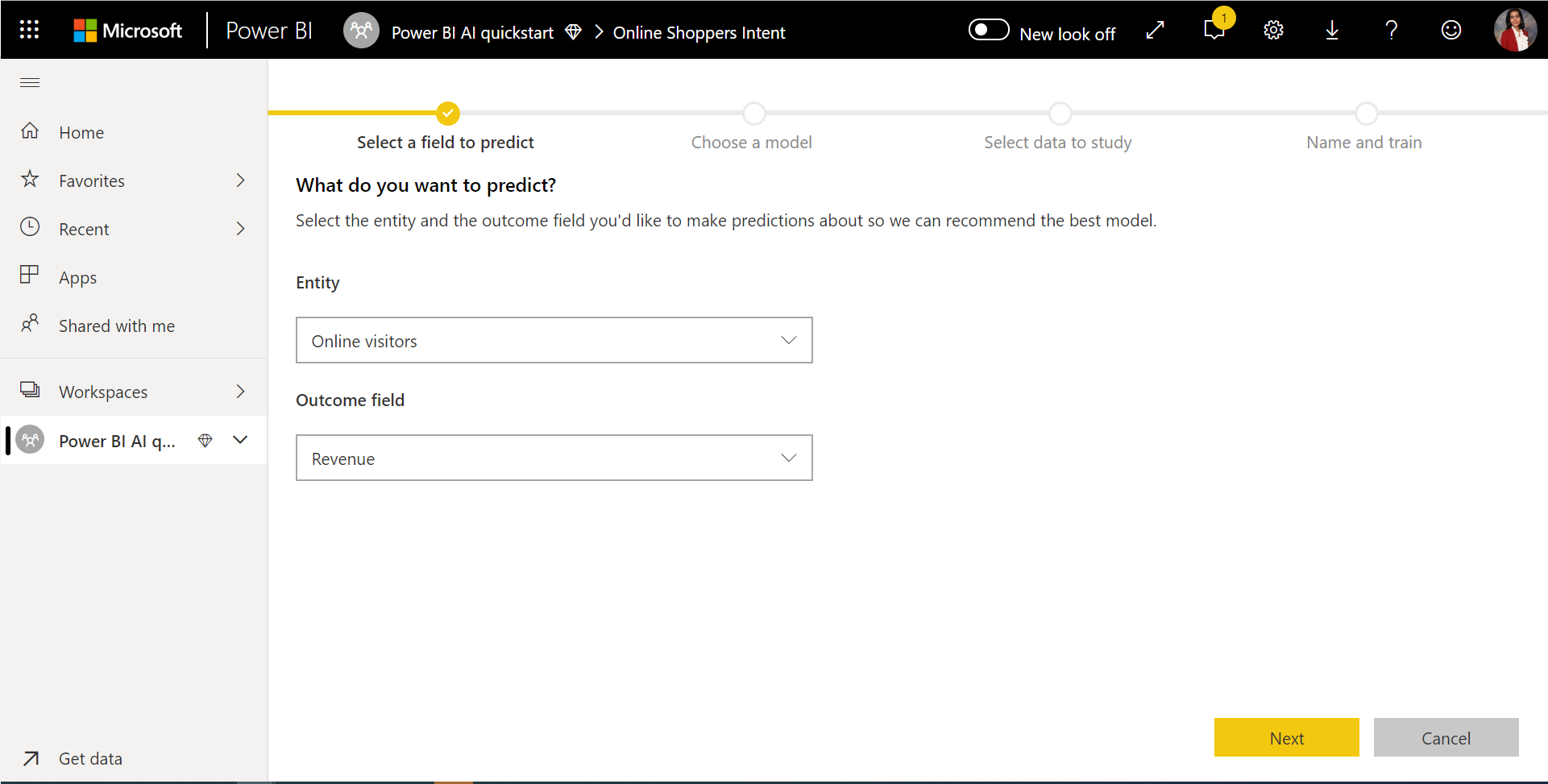
1. Jelölje ki az előzményadatokat tartalmazó táblát, és válassza ki azt az eredményoszlopot, amelyhez előrejelzést szeretne adni
Az eredmény oszlop az ML-modell betanításához használt címkeattribútumot azonosítja, amely az alábbi képen látható.
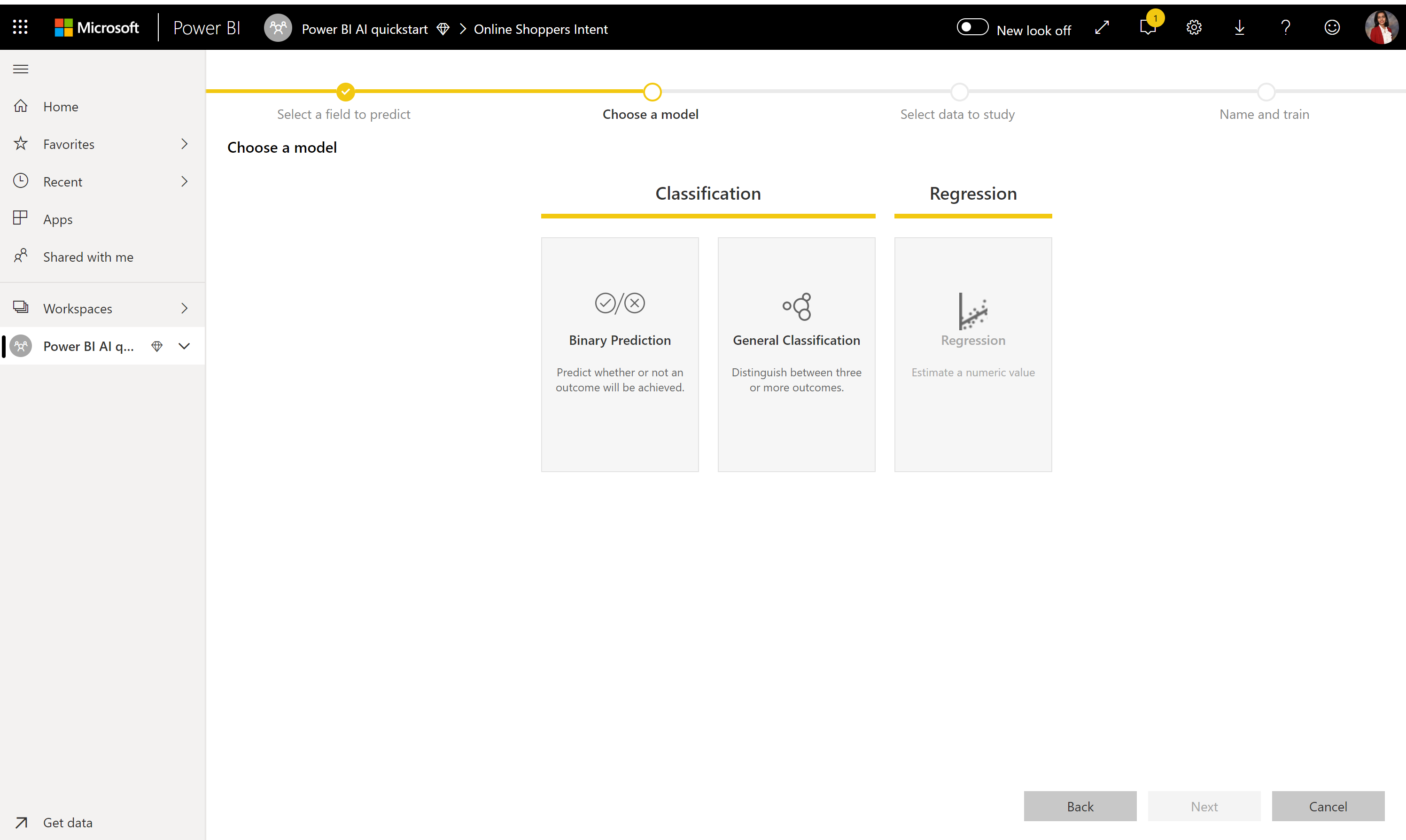
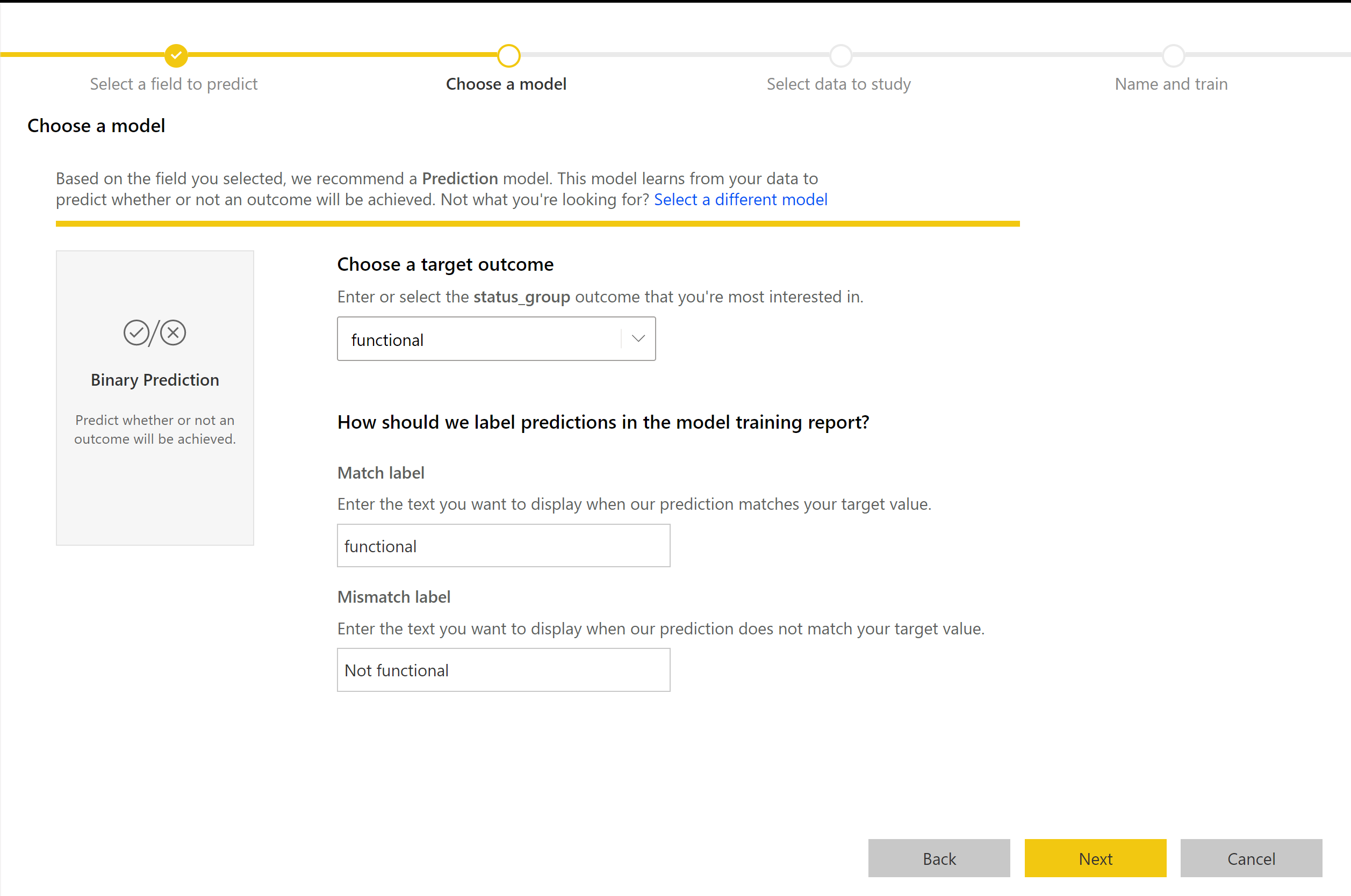
2. Modelltípus kiválasztása
Amikor megadja az eredmény oszlopot, az AutoML elemzi a címkeadatokat, hogy a betanított ml-modelltípust javasolja. Az alábbi képen látható modelltípust a Modell kiválasztása elemre kattintva választhatja ki.
Feljegyzés
Előfordulhat, hogy egyes modelltípusok nem támogatottak a kiválasztott adatok esetében, ezért le lesz tiltva. Az előző példában a Regresszió le van tiltva, mert egy szöveges oszlop van kijelölve eredményoszlopként.
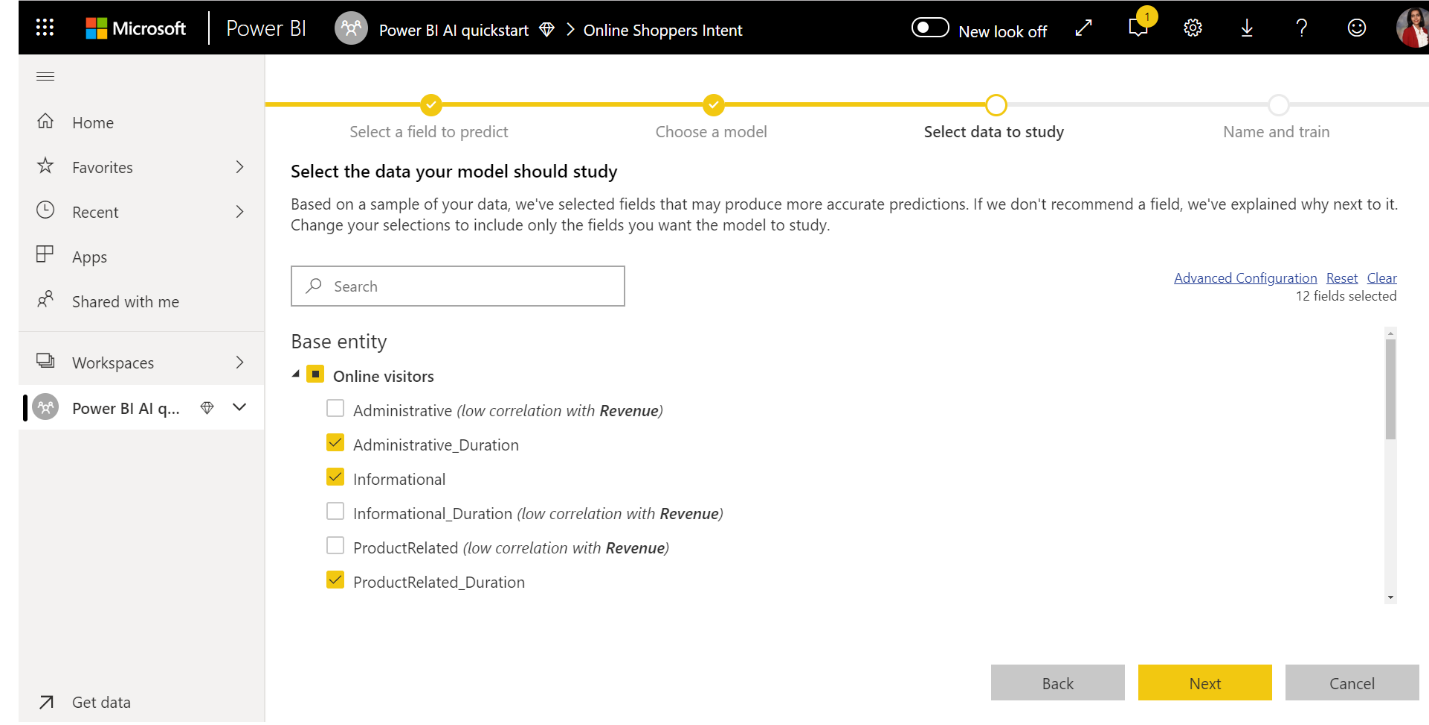
3. Válassza ki azokat a bemeneteket, amelyeket a modell prediktív jelként szeretne használni
Az AutoML a kiválasztott táblázat mintáját elemzi, és javaslatot tesz az ML-modell betanításához használható bemenetekre. A nem kijelölt oszlopok mellett magyarázatok találhatók. Ha egy adott oszlop túl sok különböző értékkel vagy csak egy értékkel rendelkezik, vagy alacsony vagy magas korrelációt mutat a kimeneti oszlopmal, akkor nem ajánlott.
Az eredményoszloptól (vagy a címkeoszloptól) függő bemenetek nem használhatók az ML-modell betanításához, mivel ezek befolyásolják a teljesítményét. Az ilyen oszlopok "gyanúsan magas korrelációt mutatnak a kimeneti oszlopmal". Ha ezeket az oszlopokat beveszi a betanítási adatokba, az címkeszivárgást okoz, ahol a modell jól teljesít az érvényesítési vagy tesztelési adatokon, de nem tud megegyezni a teljesítményével, amikor éles környezetben használják a pontozáshoz. Ha a betanítási modell teljesítménye túl jó ahhoz, hogy igaz legyen, a címkék szivárgása problémát okozhat az AutoML-modellekben.
Ez a funkciójavaslat egy adatmintán alapul, ezért érdemes áttekinteni a felhasznált bemeneteket. A kijelöléseket úgy módosíthatja, hogy csak azokat az oszlopokat tartalmazza, amelyeket a modell tanulmányozni szeretne. Az összes oszlopot a tábla neve melletti jelölőnégyzet bejelölésével is kijelölheti.
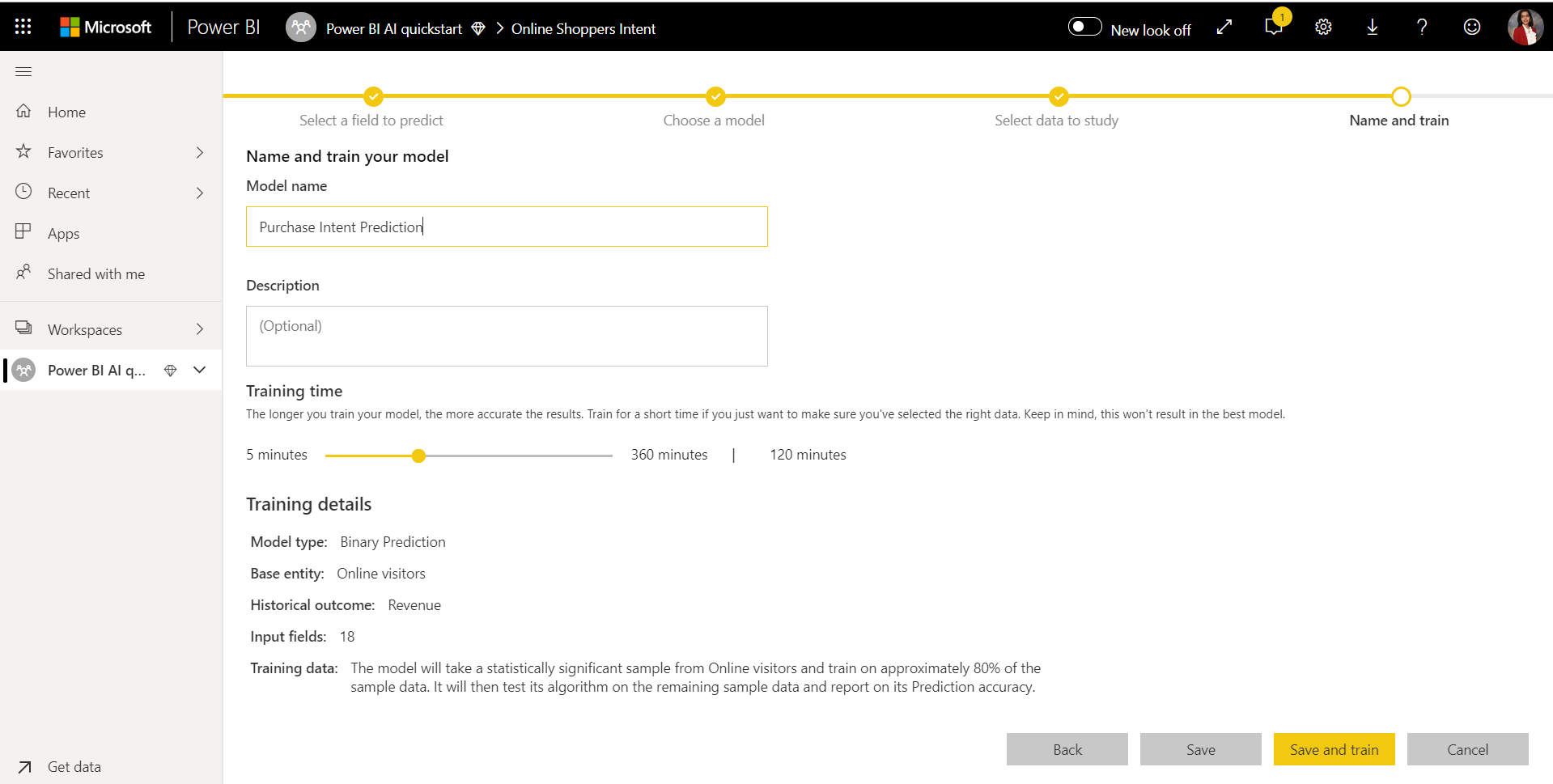
4. Nevezze el a modellt, és mentse a konfigurációt
Az utolsó lépésben elnevezheti a modellt, kiválaszthatja a Mentés lehetőséget, és kiválaszthatja, hogy melyik kezdi betanítását az ML-modellben. A legjobb modell eléréséhez csökkentheti a betanítási időt a gyors eredmények megtekintéséhez, vagy növelheti a betanítással töltött időt.
ML-modell betanítása
Az AutoML-modellek betanítása az adatfolyam frissítésének része. Az AutoML először előkészíti az adatokat a betanításhoz. Az AutoML felosztja a megadott előzményadatokat a szemantikai modellek betanítására és tesztelésére. A teszt szemantikai modell egy visszatartási készlet, amely a modell teljesítményének ellenőrzésére szolgál a betanítás után. Ezek a készletek betanítási és tesztelési táblákként jelennek meg az adatfolyamban. Az AutoML keresztérvényesítést használ a modell érvényesítéséhez.
Ezután a rendszer elemzi az egyes bemeneti oszlopokat, és alkalmazza a számítást, amely a hiányzó értékeket helyettesítő értékekkel helyettesíti. Az AutoML számos különböző számítási stratégiát használ. A numerikus jellemzőkként kezelt bemeneti attribútumok esetében az oszlopértékek középértéket használják a számításhoz. A kategorikus jellemzőkként kezelt bemeneti attribútumok esetében az AutoML az oszlopértékek módját használja a számításhoz. Az AutoML-keretrendszer kiszámítja az értékek középértékét és módját, amelyeket a szubampled betanítási szemantikai modellen történő számításhoz használnak.
Ezután a rendszer szükség szerint alkalmazza a mintavételezést és a normalizálást az adatokra. Besorolási modellek esetén az AutoML rétegzett mintavételezésen keresztül futtatja a bemeneti adatokat, és egyensúlyba hozza az osztályokat annak érdekében, hogy a sorok száma mindenkinél egyenlő legyen.
Az AutoML számos átalakítást alkalmaz az egyes kiválasztott bemeneti oszlopokon az adattípus és a statisztikai tulajdonságok alapján. Az AutoML ezeket az átalakításokat használja az ML-modell betanításához használható funkciók kinyerésére.
Az AutoML-modellek betanítási folyamata legfeljebb 50 iterációból áll, különböző modellezési algoritmusokkal és hiperparaméter-beállításokkal, hogy a modell a legjobb teljesítményt nyújtsa. A betanítás hamarabb befejeződhet kisebb iterációkkal, ha az AutoML azt észleli, hogy nem figyelhető meg teljesítménybeli javulás. Az AutoML a visszatartási teszt szemantikai modelljével ellenőrzi az egyes modellek teljesítményét. Ebben a betanítási lépésben az AutoML számos folyamatot hoz létre ezeknek az iterációknak a betanításához és érvényesítéséhez. A modellek teljesítményének felmérése több perctől akár néhány óráig is eltarthat a varázslóban konfigurált betanítási időig. A szükséges idő a szemantikai modell méretétől és a rendelkezésre álló kapacitáserőforrásoktól függ.
Bizonyos esetekben a létrehozott végső modell együttes tanulást használhat, ahol több modell is használható a jobb prediktív teljesítmény érdekében.
AutoML-modell magyarázata
A modell betanítása után az AutoML elemzi a bemeneti funkciók és a modell kimenete közötti kapcsolatot. Felméri, hogy az egyes bemeneti funkciók esetében milyen mértékű változás történt a modell kimenetében a visszatartott teszt szemantikai modellje esetében. Ezt a kapcsolatot a funkció fontosságaként ismerjük. Ez az elemzés a betanítás befejezése után a frissítés részeként történik. Ezért a frissítés hosszabb időt vehet igénybe, mint a varázslóban konfigurált betanítási idő.
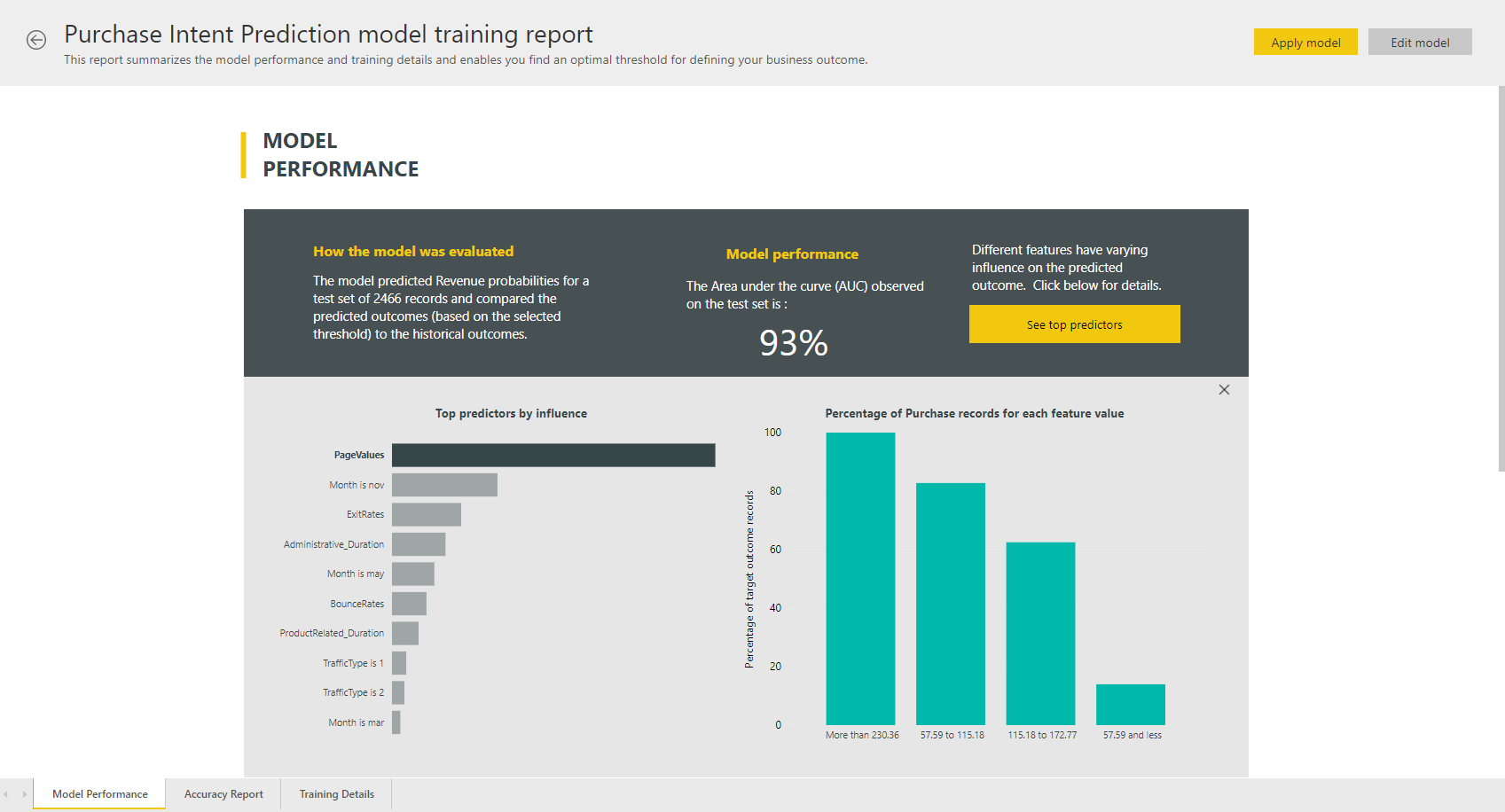
AutoML-modelljelentés
Az AutoML létrehoz egy Power BI-jelentést, amely összefoglalja a modell teljesítményét az ellenőrzés során, valamint a globális funkció fontosságát. Ez a jelentés az adatfolyam sikeres frissítése után a Gép Tanulás Modellek lapon érhető el. A jelentés összefoglalja az ML-modellnek a visszatartási tesztadatokra való alkalmazásából és az előrejelzések és az ismert eredményértékek összehasonlításából származó eredményeket.
A modelljelentést a teljesítmény megértéséhez tekintheti át. Azt is ellenőrizheti, hogy a modell főbb befolyásolói összhangban vannak-e az ismert eredményekkel kapcsolatos üzleti megállapításokkal.
A modell teljesítményének jelentésbeli leírására használt diagramok és mértékek a modell típusától függenek. Ezeket a teljesítménydiagramokat és mértékeket a következő szakaszok ismertetik.
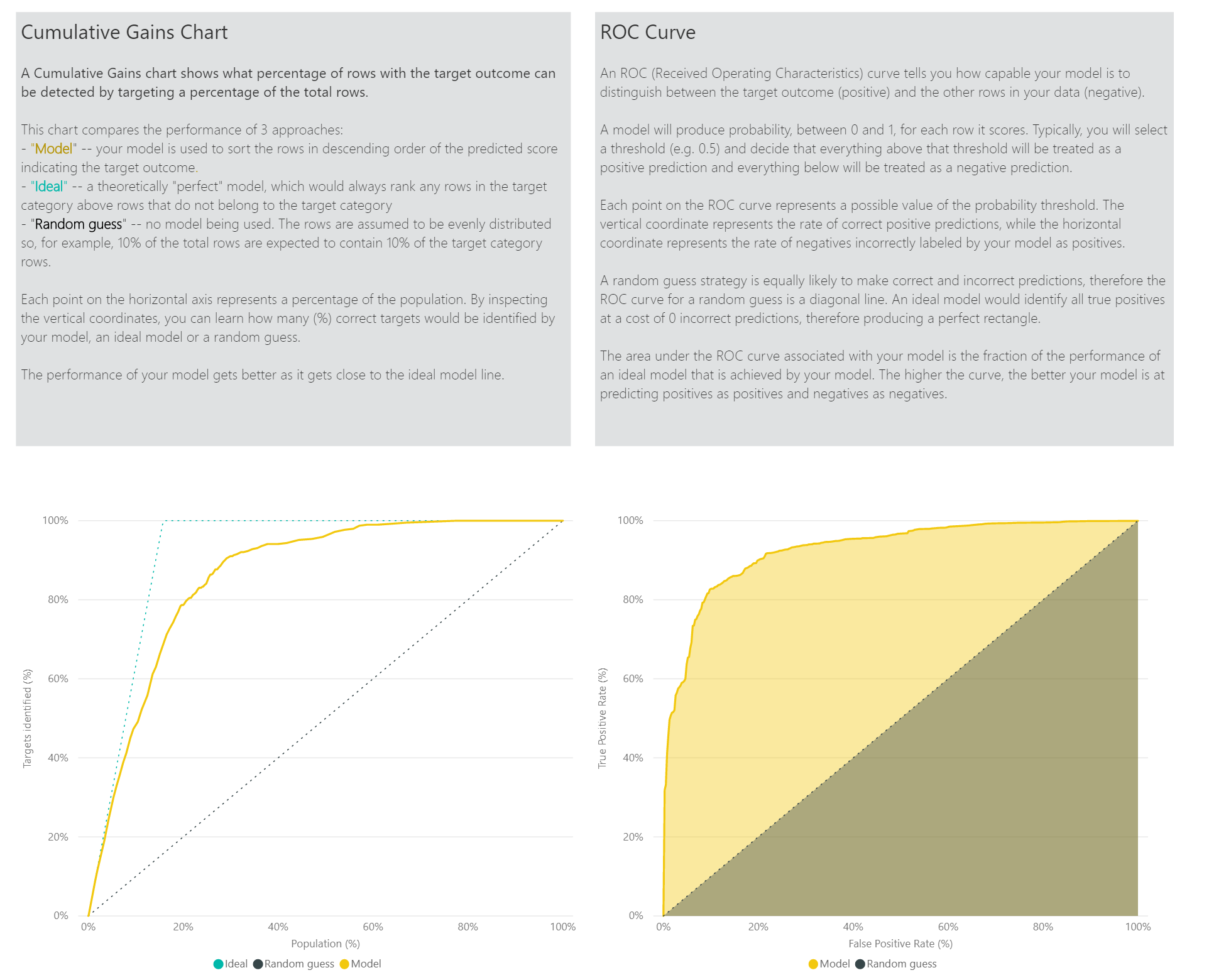
A jelentés más oldalai adatelemzési szempontból is leírhatják a modell statisztikai mérőszámait. A bináris előrejelzési jelentés például tartalmaz egy nyereségdiagramot és a modell ROC-görbét.
A jelentések között szerepel egy Betanítás részletei lap is, amely tartalmazza a modell betanításának leírását, valamint egy diagramot, amely leírja a modell teljesítményét az egyes iterációk futtatása során.
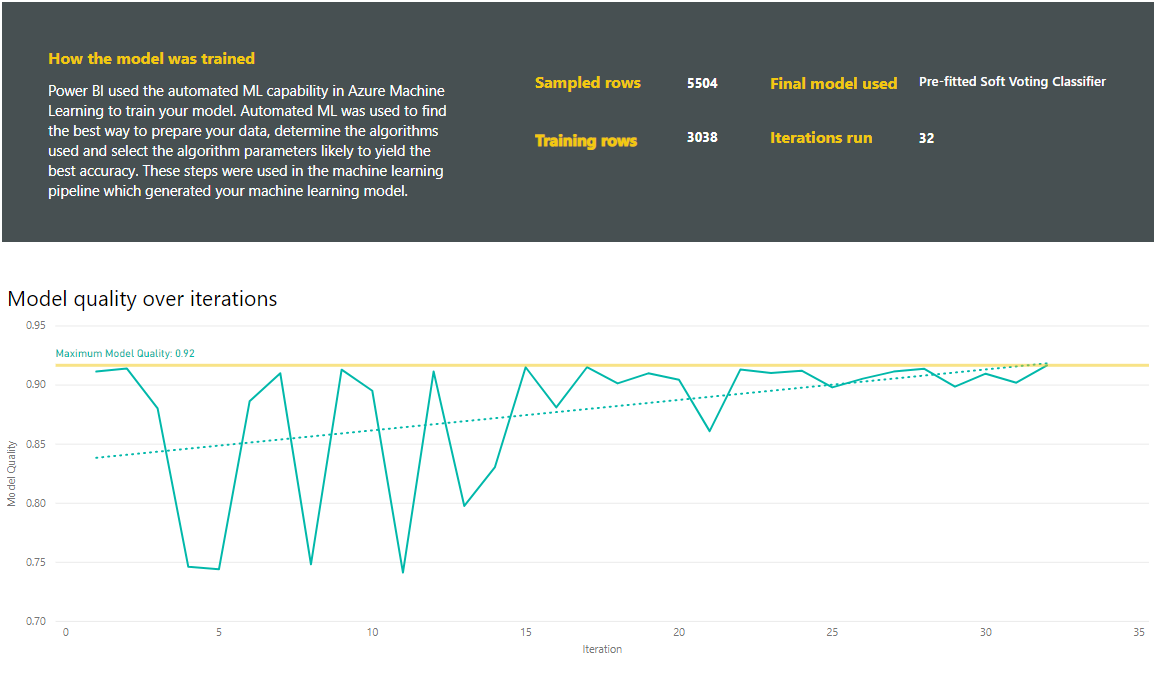
A lap egy másik szakasza a hiányzó értékek kitöltéséhez használt bemeneti oszlop és számítási módszer észlelt típusát ismerteti. A végső modell által használt paramétereket is tartalmazza.
Ha a létrehozott modell együttes tanulást használ, akkor a Betanítás részletei lap egy diagramot is tartalmaz, amely az együttes egyes alkotó modelljeinek súlyát és paramétereit mutatja.

Az AutoML-modell alkalmazása
Ha elégedett a létrehozott ML-modell teljesítményével, az adatfolyam frissítésekor alkalmazhatja azokat az új vagy frissített adatokra. A modelljelentésben válassza az Alkalmaz gombot a jobb felső sarokban, vagy az Ml-modell alkalmazása gombot a Gép Tanulás Modellek lapon található műveletek alatt.
Az ml-modell alkalmazásához meg kell adnia annak a táblának a nevét, amelyre alkalmazni kell, valamint egy előtagot azoknak az oszlopoknak, amelyek a modell kimenetéhez hozzáadva lesznek a táblához. Az oszlopnevek alapértelmezett előtagja a modell neve. Az Alkalmaz függvény további, a modell típusára jellemző paramétereket is tartalmazhat.
Az ML-modell alkalmazása két új adatfolyamtáblát hoz létre, amelyek tartalmazzák a kimeneti táblában pontozott egyes sorok előrejelzéseit és egyéni magyarázatait. Ha például a PurchaseIntent modellt alkalmazza az OnlineShoppers táblára, a kimenet létrehozza az OnlineShoppers dúsított PurchaseIntent és OnlineShoppers bővített PurchaseIntent magyarázattábláit. A bővített táblázat minden egyes sorához a Magyarázatok több sorra van bontva a bővített magyarázatok táblában a bemeneti funkció alapján. A ExplanationIndex segítségével a bővített magyarázattáblából a bővített táblázat soraiba képezhetők le a sorok.
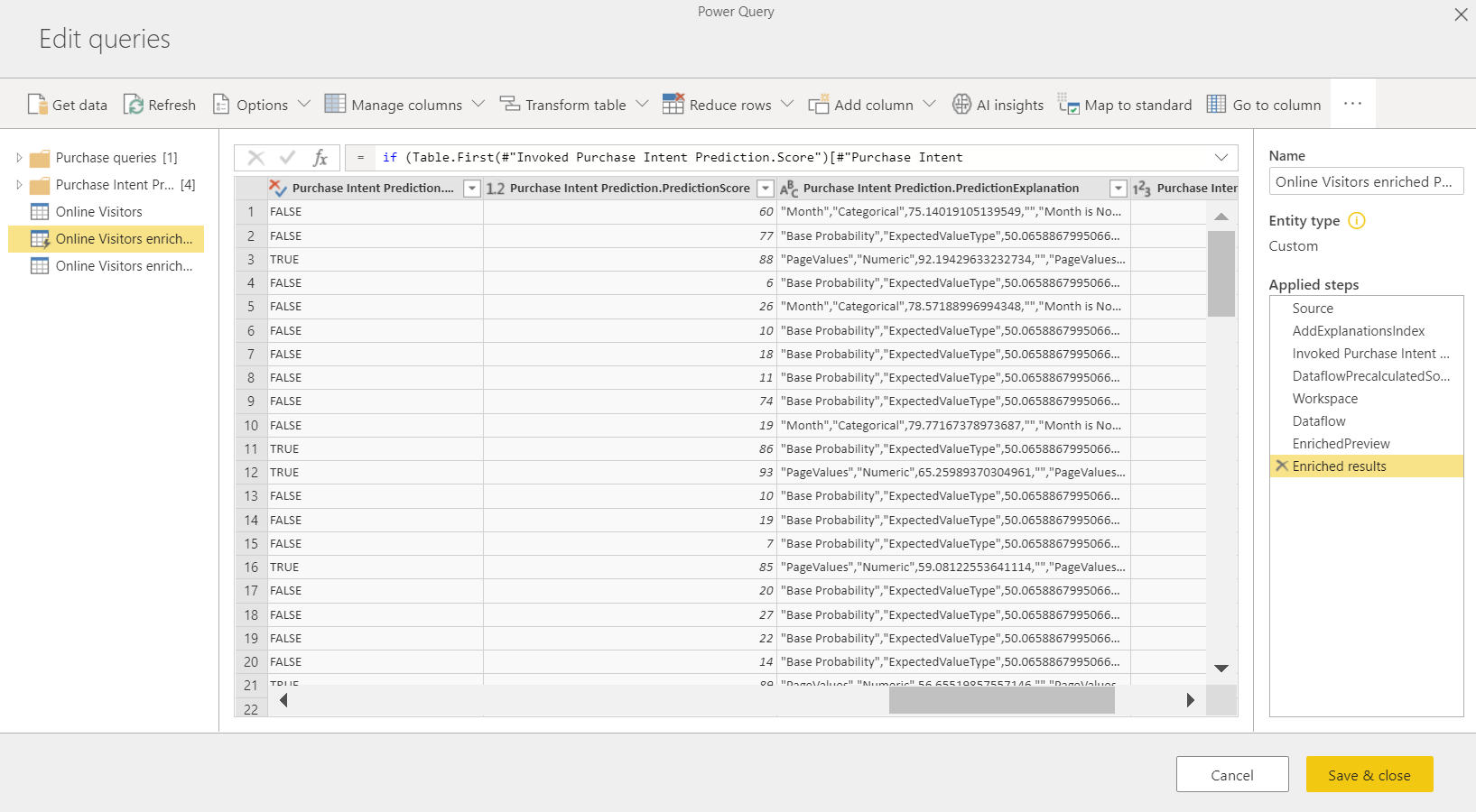
Bármilyen Power BI AutoML-modellt alkalmazhat az ugyanazon munkaterületen lévő adatfolyamok tábláira a PQO függvényböngészőben található AI-elemzések használatával. Ily módon használhatja azokat a modelleket, amelyeket mások hoztak létre ugyanabban a munkaterületen anélkül, hogy feltétlenül a modellel rendelkező adatfolyam tulajdonosának kéne lennie. A Power Query felderíti a munkaterület összes Power BI ML-modellét, és dinamikus Power Query-függvényként teszi elérhetővé őket. Ezeket a függvényeket a Power Query-szerkesztő menüszalagjáról vagy közvetlenül az M függvény meghívásával hívhatja meg. Ez a funkció jelenleg csak a Power BI-adatfolyamok és a Power Query Online esetében támogatott a Power BI szolgáltatás. Ez a folyamat eltér attól, hogy az AutoML varázslóval migrálási modelleket alkalmazzon egy adatfolyamon belül. Ezzel a módszerrel nem hozható létre magyarázattábla. Hacsak nem Ön az adatfolyam tulajdonosa, nem férhet hozzá a modell betanítási jelentéseihez, és nem taníthatja be újra a modellt. Ha a forrásmodellt bemeneti oszlopok hozzáadásával vagy eltávolításával szerkessze, vagy törli a modellt vagy a forrás adatfolyamot, akkor ez a függő adatfolyam megszakadna.

A modell alkalmazása után az AutoML mindig naprakészen tartja az előrejelzéseket az adatfolyam frissítésekor.
Ha egy Power BI-jelentésben szeretné használni az ML-modellből származó elemzéseket és előrejelzéseket, az adatfolyam-összekötővel csatlakozhat a kimeneti táblához a Power BI Desktopból.
Bináris előrejelzési modellek
A bináris előrejelzési modelleket, más néven bináris besorolási modelleket a szemantikai modellek két csoportba való besorolására használják. A bináris kimenetelű események előrejelzésére szolgálnak. Például, hogy egy értékesítési lehetőség konvertálódik-e, hogy egy fiók át fog-e változni, a számla kifizetése időben történik-e, egy tranzakció hamis-e, és így tovább.
A bináris előrejelzési modell kimenete egy valószínűségi pontszám, amely azonosítja a céleredmény elérésének valószínűségét.
Bináris előrejelzési modell betanítása
Előfeltételek:
- Az egyes eredményosztályokhoz legalább 20 sor előzményadat szükséges
A bináris előrejelzési modellek létrehozásának folyamata ugyanazokat a lépéseket követi, mint a többi AutoML-modell, amelyet az előző szakaszban, az ML-modell bemeneteinek konfigurálása című szakaszban ismertetünk. Az egyetlen különbség a Modell kiválasztása lépésben van, ahol kiválaszthatja a leginkább érdeklő céleredmény-értéket. Az automatikusan létrehozott jelentésben használandó eredményekhez rövid címkéket is megadhat, amelyek összegzik a modellérvényesítés eredményeit.
Bináris előrejelzési modell jelentése
A bináris előrejelzési modell kimenetként annak valószínűségét állítja elő, hogy egy sor eléri a céleredményt. A jelentés tartalmaz egy szeletelőt a valószínűségi küszöbértékhez, amely befolyásolja a pontszámok valószínűségi küszöbértéknél nagyobb és kisebb értelmezését.
A jelentés a modell teljesítményét ismerteti igaz pozitívok, hamis pozitívok, igaz negatívok és hamis negatívok szempontjából. A valódi pozitívok és az igaz negatívok helyesen előrejelzett eredmények az eredményadatokban szereplő két osztály esetében. A hamis pozitívok olyan sorok, amelyek a Cél eredményének előrejelzése szerint voltak előre jelezve, de valójában nem. Ezzel szemben a hamis negatívok olyan sorok, amelyeknek céleredményei voltak, de nem azokként lettek előrejelezve.
Az olyan mértékek, mint a pontosság és a visszahívás, a valószínűségi küszöbértéknek az előrejelzett eredményekre gyakorolt hatását írják le. A valószínűségi küszöbértékszeletelővel kiválaszthat egy olyan küszöbértéket, amely kiegyensúlyozott kompromisszumot ér el a pontosság és a visszahívás között.

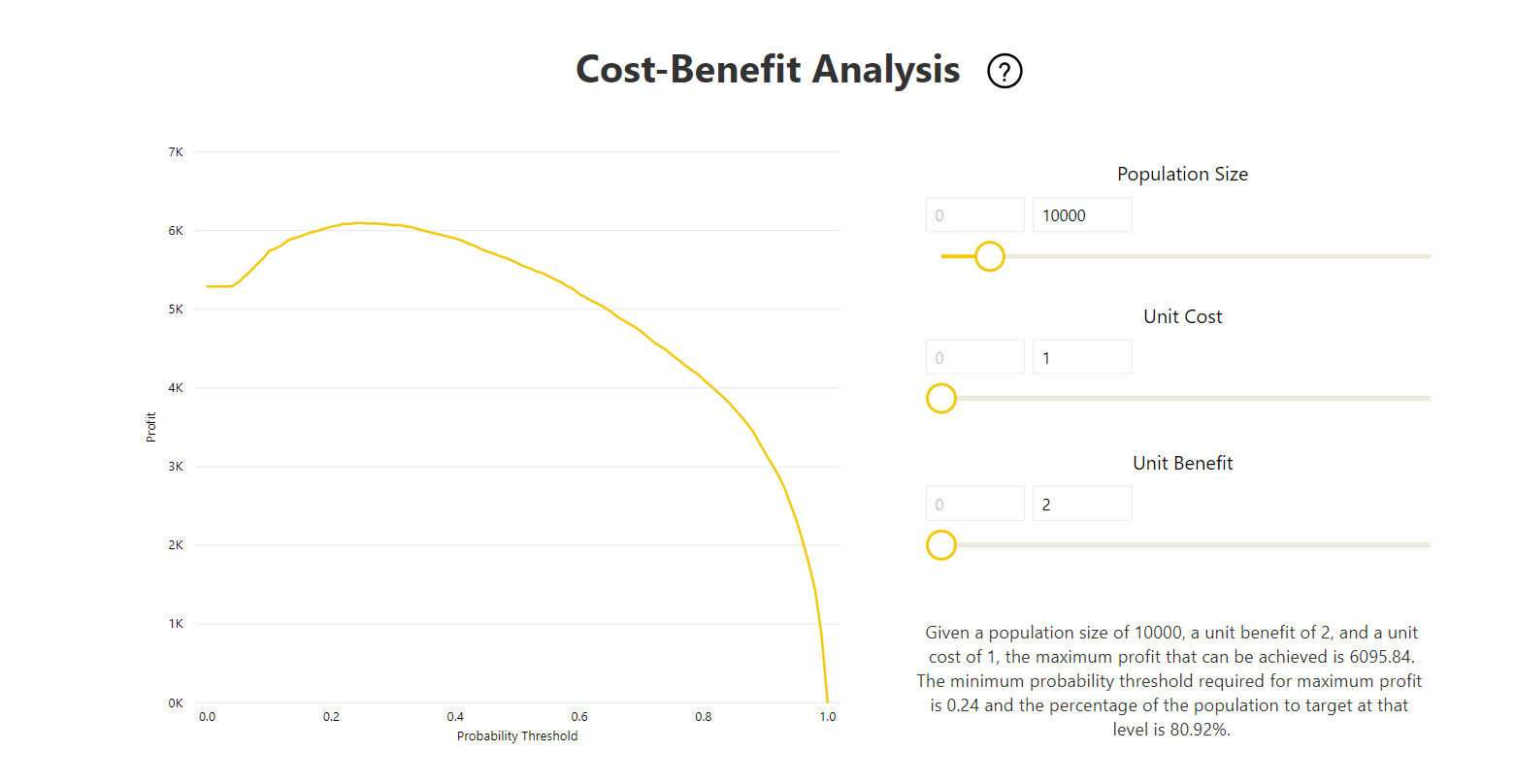
A jelentés tartalmaz egy Cost-Benefit elemzési eszközt is, amely segít azonosítani a sokaság azon részhalmazát, amelyet a legmagasabb nyereség elérése érdekében meg kell célozni. Mivel a célzás becsült egységköltsége és egy egység kihasználja a céleredmény elérését, a Cost-Benefit elemzés megpróbálja maximalizálni a profitot. Ezzel az eszközzel kiválaszthatja a valószínűségi küszöbértéket a gráf maximális pontja alapján a nyereség maximalizálása érdekében. A gráf segítségével kiszámíthatja a valószínűségi küszöbérték kiválasztásához szükséges nyereséget vagy költséget.
A modelljelentés Pontossági jelentés oldala tartalmazza az összegző nyereség diagramot és a modell ROC-görbét. Ezek az adatok statisztikai mértékeket biztosítanak a modell teljesítményéről. A jelentések a megjelenített diagramok leírását tartalmazzák.
Bináris előrejelzési modell alkalmazása
Bináris előrejelzési modell alkalmazásához meg kell adnia a táblát azokkal az adatokkal, amelyekre alkalmazni szeretné az ml-modellből származó előrejelzéseket. Más paraméterek közé tartozik a kimeneti oszlopnév előtagja és az előrejelzett eredmény besorolásának valószínűségi küszöbértéke.
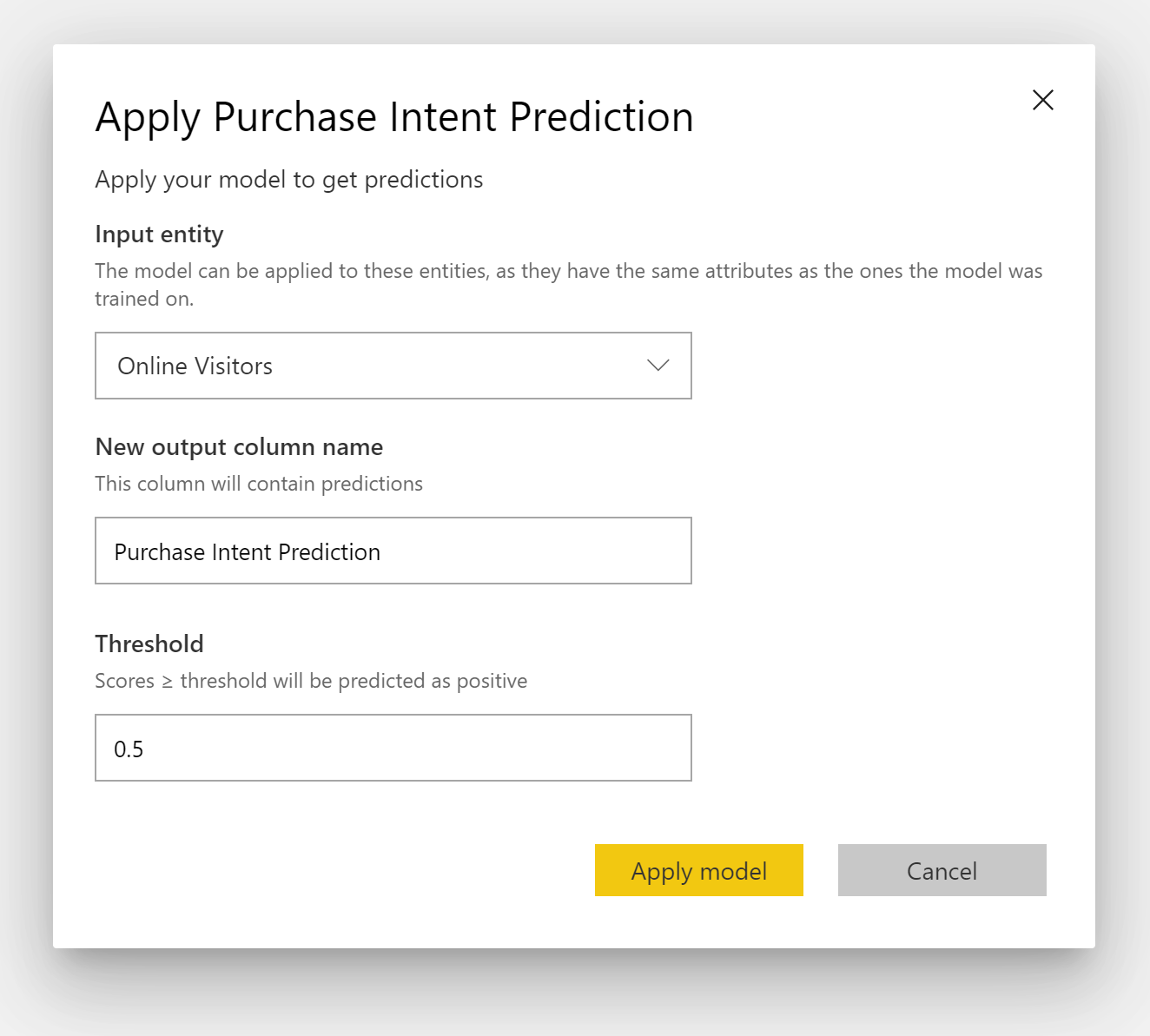
Bináris előrejelzési modell alkalmazásakor négy kimeneti oszlopot ad hozzá a bővített kimeneti táblához: Outcome, PredictionScore, PredictionExplanation és ExplanationIndex. A tábla oszlopnevei a modell alkalmazásakor megadott előtaggal rendelkeznek.
A PredictionScore egy százalékos valószínűség, amely azonosítja a céleredmény elérésének valószínűségét.
Az Eredmény oszlop tartalmazza az előrejelzett eredménycímkét. A küszöbértéket meghaladó valószínűségű rekordok a céleredmény elérésének valószínűségét jelzik előre, és true (Igaz) címkével vannak ellátva. A küszöbértéknél kisebb rekordok várhatóan nem érik el az eredményt, és hamisként vannak megjelölve.
A PredictionExplanation oszlop magyarázattal rendelkezik, amely azt jelzi, hogy a bemeneti funkciók milyen hatással voltak a PredictionScore-ra.
Besorolási modellek
A besorolási modellek egy szemantikai modell több csoportba vagy osztályba való besorolására szolgálnak. Olyan események előrejelzésére szolgálnak, amelyek több lehetséges kimenetel egyikével is járhatnak. Például, hogy egy ügyfél valószínűleg magas, közepes vagy alacsony élettartamú értékkel rendelkezik-e. Azt is előre jelezhetik, hogy az alapértelmezett kockázat magas, közepes, alacsony és így tovább.
A besorolási modell kimenete egy valószínűségi pontszám, amely azonosítja annak valószínűségét, hogy egy sor eléri az adott osztály feltételeit.
Besorolási modell betanítása
A besorolási modell betanítási adatait tartalmazó bemeneti táblának eredményoszlopként egy sztring vagy egész szám oszlopnak kell lennie, amely azonosítja a korábbi ismert eredményeket.
Előfeltételek:
- Az egyes eredményosztályokhoz legalább 20 sor előzményadat szükséges
A besorolási modellek létrehozásának folyamata ugyanazokat a lépéseket követi, mint a többi AutoML-modell, amelyet az előző szakaszban, az ML-modell bemeneteinek konfigurálása című szakaszban ismertetünk.
Besorolási modell jelentése
A Power BI úgy hozza létre a besorolási modell jelentését, hogy az ML-modellt alkalmazza a visszatartási tesztadatokra. Ezután összehasonlítja egy sor előrejelzett osztályát a tényleges ismert osztálysal.
A modelljelentés tartalmaz egy diagramot, amely tartalmazza az egyes ismert osztályok helyesen és helytelenül besorolt sorainak lebontását.
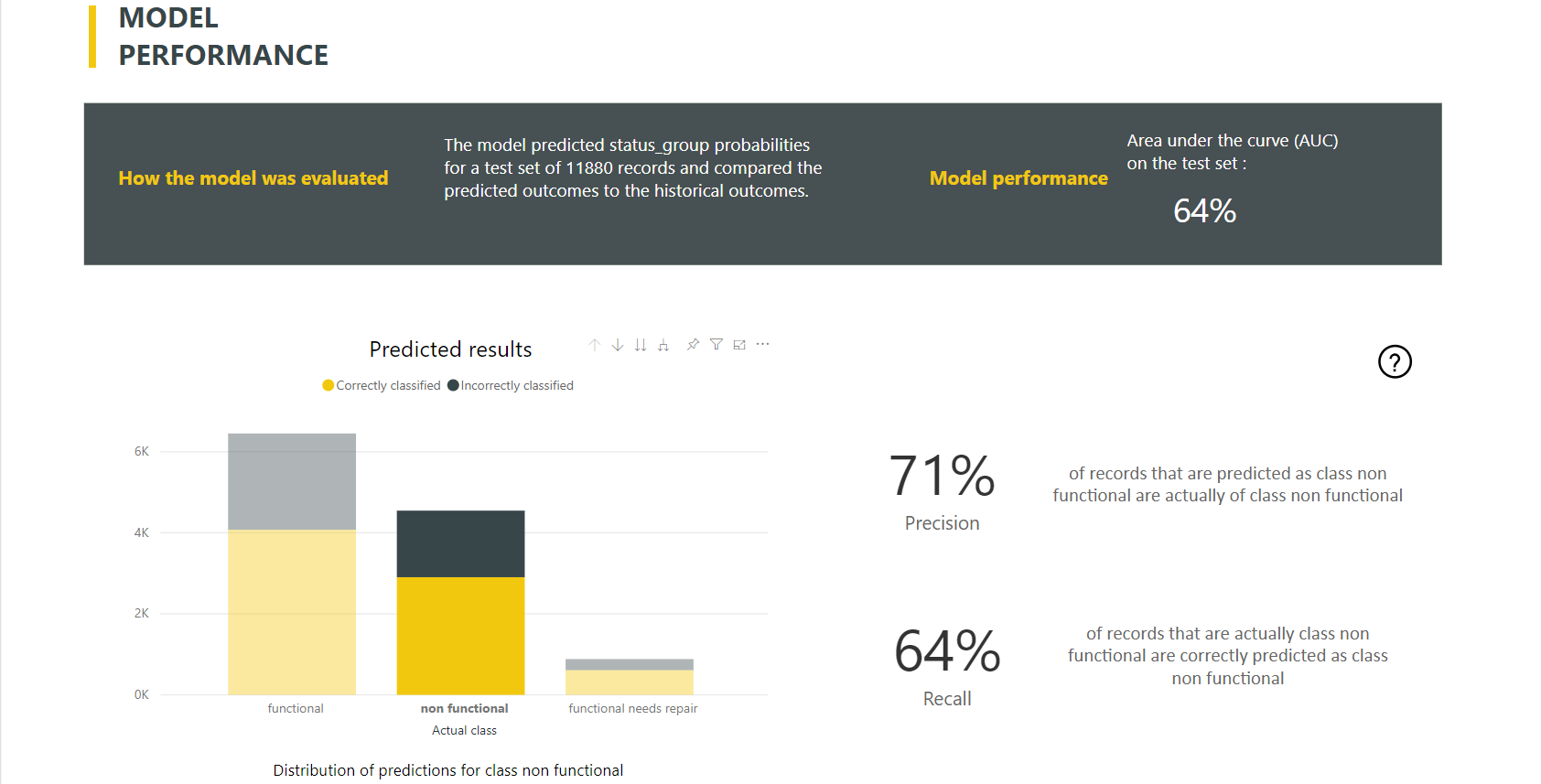
Egy további osztályspecifikus részletezési művelet lehetővé teszi egy ismert osztály előrejelzéseinek elosztásának elemzését. Ez az elemzés azokat a többi osztályt mutatja be, amelyekben az ismert osztály sorai valószínűleg helytelenül lesznek besorolva.
A jelentés modellmagyarázata az egyes osztályokhoz tartozó legfontosabb prediktorokat is tartalmazza.
A besorolási modellről szóló jelentés az AutoML-modelljelentés más modelltípusainak lapjaihoz hasonló Betanítási részletek lapot is tartalmaz.
Besorolási modell alkalmazása
A besorolási ML-modell alkalmazásához meg kell adnia a bemeneti adatokat és a kimeneti oszlopnév előtagot tartalmazó táblát.
Besorolási modell alkalmazásakor öt kimeneti oszlopot ad hozzá a bővített kimeneti táblához: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities és ExplanationIndex. A tábla oszlopnevei a modell alkalmazásakor megadott előtaggal rendelkeznek.
A ClassProbabilities oszlop az egyes lehetséges osztályok sorainak valószínűségi pontszámait tartalmazza.
A ClassificationScore a százalékos valószínűség, amely azt jelzi, hogy egy sor eléri-e az adott osztály feltételeit.
A ClassificationResult oszlop a sor legvalószínűbb előrejelzett osztályát tartalmazza.
A ClassificationExplanation oszlop magyarázattal rendelkezik, amely azt jelzi, hogy a bemeneti funkciók milyen hatással voltak a ClassificationScore-ra.
Regressziós modellek
A regressziós modellek numerikus értékek előrejelzésére szolgálnak, és olyan helyzetekben használhatók, mint a következők meghatározása:
- A bevétel valószínűleg egy értékesítési ügyletből realizálódik.
- Egy fiók élettartamának értéke.
- A várhatóan kifizetendő kinnlevőség-számla összege
- A számla kifizetésének dátuma stb.
A regressziós modell kimenete az előrejelzett érték.
Regressziós modell betanítása
A regressziós modell betanítási adatait tartalmazó bemeneti táblának eredményoszlopként numerikus oszlopot kell tartalmaznia, amely azonosítja az ismert eredményértékeket.
Előfeltételek:
- Egy regressziós modellhez legalább 100 sor előzményadat szükséges.
A regressziós modellek létrehozásának folyamata ugyanazokat a lépéseket követi, mint a többi AutoML-modell, amelyet az előző szakaszban, az ML-modell bemeneteinek konfigurálása című szakaszban ismertetünk.
Regressziós modell jelentése
A többi AutoML-modelljelentéshez hasonlóan a Regressziós jelentés a modellnek a visszatartási tesztadatokra való alkalmazásából származó eredményeken alapul.
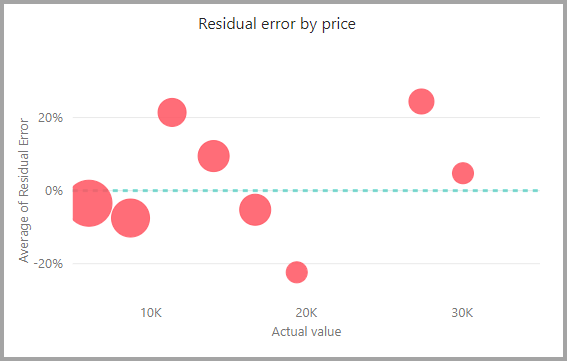
A modelljelentés tartalmaz egy diagramot, amely összehasonlítja az előrejelzett értékeket a tényleges értékekkel. Ebben a diagramban az átlótól való távolság az előrejelzés hibáját jelzi.
A reziduális hibadiagram az átlagos hiba százalékos arányának eloszlását mutatja a kitartásteszt szemantikai modelljében szereplő különböző értékekhez. A vízszintes tengely a csoport tényleges értékének középértéke. A buborék mérete az adott tartomány értékeinek gyakoriságát vagy számát mutatja. A függőleges tengely az átlagos reziduális hiba.
A Regressziós modellről szóló jelentés tartalmaz egy Betanítási részletek lapot is, például a többi modelltípus jelentéseit, az előző, AutoML-modelljelentésben leírtak szerint.
Regressziós modell alkalmazása
Regressziós ML-modell alkalmazásához meg kell adnia a bemeneti adatokat és a kimeneti oszlopnév előtagot tartalmazó táblát.
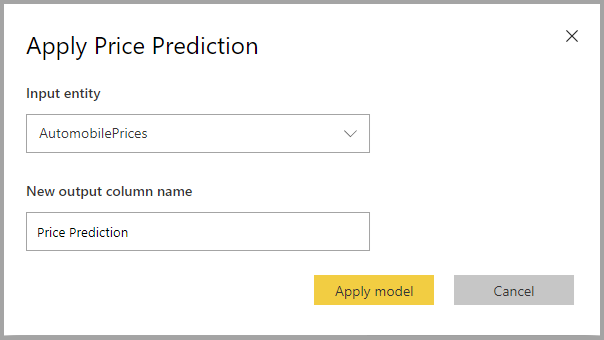
Regressziós modell alkalmazásakor három kimeneti oszlopot ad hozzá a bővített kimeneti táblához: RegressionResult, RegressionExplanation és ExplanationIndex. A tábla oszlopnevei a modell alkalmazásakor megadott előtaggal rendelkeznek.
A RegresszióResult oszlop a bemeneti oszlopok alapján tartalmazza a sor előrejelzett értékét. A RegressionExplanation oszlop egy magyarázatot tartalmaz, amely azt a konkrét hatást tartalmazza, amelyet a bemeneti funkciók befolyásoltak a RegresszióResult esetében.
Azure Machine Tanulás integrációja a Power BI-ban
Számos szervezet gépi tanulási modelleket használ az üzlettel kapcsolatos jobb elemzésekhez és előrejelzésekhez. A gépi tanulással jelentéseket, irányítópultokat és egyéb elemzéseket használhat ezekre az elemzésekre. A modellekből származó megállapítások vizualizációjának és meghívásának lehetősége segíthet ezeknek az elemzéseknek a terjesztésében azoknak az üzleti felhasználóknak, akiknek a leginkább szükségük van rá. A Power BI mostantól egyszerűvé teszi az Azure Machine Tanulás által üzemeltetett modellek megállapításainak beépítése egyszerű pont- és kattintásos kézmozdulatokkal.
Ennek a képességnek a használatához az adatelemző az Azure Portal használatával hozzáférést biztosíthat az Azure Machine Tanulás modellhez a BI-elemző számára. Ezután minden munkamenet elején a Power Query felderíti az összes Azure Machine-Tanulás modellt, amelyhez a felhasználó hozzáfér, és dinamikus Power Query-függvényként teszi elérhetővé őket. A felhasználó ezután meghívhatja ezeket a függvényeket a Power Query-szerkesztő menüszalagjáról vagy közvetlenül az M függvény meghívásával. A Power BI automatikusan kötegeli a hozzáférési kérelmeket is, amikor az Azure Machine Tanulás-modellt invokálásakor sorkészletre kéri a jobb teljesítmény érdekében.
Ez a funkció jelenleg csak a Power BI-adatfolyamok és az online Power Query esetében támogatott a Power BI szolgáltatás.
Az adatfolyamokról további információt az adatfolyamok és az önkiszolgáló adatelőkészítés bemutatása című témakörben talál.
Az Azure Machine Tanulás további információért lásd:
- Áttekintés: Mi az Azure Machine Tanulás?
- Rövid útmutatók és oktatóanyagok az Azure Machine Tanulás: Az Azure Machine Tanulás dokumentációja
Hozzáférés biztosítása az Azure Machine Tanulás-modellhez egy Power BI-felhasználó számára
Az Azure Machine Tanulás-modell Power BI-ból való eléréséhez a felhasználónak olvasási hozzáféréssel kell rendelkeznie az Azure-előfizetéshez és a Machine Tanulás-munkaterülethez.
A cikk lépései azt mutatják be, hogyan adhat hozzáférést a Power BI-felhasználónak az Azure Machine Tanulás szolgáltatásban üzemeltetett modellhez, hogy Power Query-függvényként férhessen hozzá a modellhez. További információ: Azure-szerepkörök hozzárendelése a Azure Portal.
Jelentkezzen be az Azure Portalra.
Nyissa meg az Előfizetések lapot. Az Előfizetések lapot az Összes szolgáltatás listában találja az Azure Portal navigációs panel menüjében.

Válassza ki előfizetését.

Válassza a Hozzáférés-vezérlés (IAM) lehetőséget, majd a Hozzáadás gombot.

Válassza az Olvasó szerepkört. Ezután válassza ki azt a Power BI-felhasználót, akinek hozzáférést szeretne adni az Azure Machine Tanulás-modellhez.

Válassza a Mentés lehetőséget.
Ismételje meg a 3–6. lépést, hogy olvasói hozzáférést biztosítson a felhasználónak a modellt üzemeltető adott gépi tanulási munkaterülethez.




Sémafelderítés gépi tanulási modellekhez
Az adattudósok elsősorban a Pythont használják gépi tanulási modelljeik fejlesztésére és üzembe helyezésére. Az adatelemzőnek explicit módon létre kell hoznia a sémafájlt a Python használatával.
Ezt a sémafájlt fel kell venni a gépi tanulási modellek üzembe helyezett webszolgáltatásába. A webszolgáltatás sémájának automatikus létrehozásához meg kell adnia egy mintát az üzembe helyezett modell bemeneti/kimeneti szkriptjében. További információ: Gépi tanulási modell üzembe helyezése és pontszáma online végpont használatával. A hivatkozás tartalmazza a példabejegyzési szkriptet a sémagenerálás utasításaival.
A beviteli szkript @input_schema és @output_schema függvényei a input_sample és output_sample változók bemeneti és kimeneti mintaformátumára hivatkoznak. A függvények ezeket a mintákat használják a webszolgáltatás OpenAPI (Swagger) specifikációjának létrehozására az üzembe helyezés során.
Ezeket a sémagenerálási utasításokat a belépési szkript frissítésével az Azure Machine Tanulás SDK-val automatizált gépi tanulási kísérletek használatával létrehozott modellekre is alkalmazni kell.
Feljegyzés
Az Azure Machine Tanulás vizuális felülettel létrehozott modellek jelenleg nem támogatják a sémagenerálást, de a későbbi kiadásokban is megjelennek.
Az Azure Machine Tanulás modell meghívása a Power BI-ban
Bármely Olyan Azure Machine-Tanulás modellt meghívhat, amelyhez hozzáférést kapott, közvetlenül az adatfolyam Power Query-szerkesztő. Az Azure Machine Tanulás-modellek eléréséhez válassza annak a táblázatnak a Táblázat szerkesztése gombját, amelyet az Azure Machine Tanulás-modellből származó megállapításokkal szeretne kiegészíteni az alábbi képen látható módon.

A Táblázat szerkesztése gombra kattintva megnyílik az adatfolyam tábláinak Power Query-szerkesztő.

Válassza a menüszalag AI-elemzések gombját, majd a navigációs panel menüjében válassza az Azure Machine Tanulás Models mappát. Az összes Azure Machine-Tanulás modell, amelyhez hozzáféréssel rendelkezik, itt Power Query-függvényekként jelennek meg. Emellett az Azure Machine Tanulás modell bemeneti paraméterei automatikusan a megfelelő Power Query-függvény paramétereiként vannak leképezve.
Egy Azure Machine-Tanulás-modell meghívásához a kiválasztott tábla bármelyik oszlopát megadhatja bemenetként a legördülő menüből. A bemenetként használandó állandó értéket úgy is megadhatja, hogy a beviteli párbeszédpanel bal oldalán lévő oszlopikont egyesítheti.

A Meghívás lehetőséget választva megtekintheti az Azure Machine Tanulás modell kimenetének előnézetét új oszlopként a táblában. A modellhívás a lekérdezés alkalmazott lépéseként jelenik meg.

Ha a modell több kimeneti paramétert ad vissza, azok a kimeneti oszlop soraként vannak csoportosítva. Az oszlop kibontásával külön oszlopokban hozhat létre egyedi kimeneti paramétereket.

Az adatfolyam mentése után a rendszer automatikusan meghívja a modellt az adatfolyam frissítésekor a tábla új vagy frissített soraihoz.
Szempontok és korlátozások
- A Gen2 adatfolyamok jelenleg nem integrálhatók az automatizált gépi tanulással.
- Az AI-elemzések (Cognitive Services és Azure Machine Tanulás modellek) nem támogatottak proxyhitelesítési beállítással rendelkező gépeken.
- Az Azure Machine Tanulás modellek nem támogatottak a vendégfelhasználók számára.
- Az Átjáró autoML-vel és Cognitive Services szolgáltatással való használatával kapcsolatban ismert problémák merülnek fel. Ha átjárót kell használnia, javasoljuk, hogy hozzon létre egy adatfolyamot, amely először az átjárón keresztül importálja a szükséges adatokat. Ezután hozzon létre egy másik adatfolyamot, amely az első adatfolyamra hivatkozva hozza létre vagy alkalmazza ezeket a modelleket és AI-függvényeket.
- Ha az AI nem működik adatfolyamokkal, lehetséges, hogy engedélyeznie kell a gyors összevonást, amikor az AI-t adatfolyamokkal használja. Miután importálta a táblázatot, és mielőtt hozzákezdene az AI-funkciók hozzáadásához, válassza a Beállítások lehetőséget a Kezdőlap menüszalagjáról, és a megjelenő ablakban jelölje be a jelölőnégyzetet a több forrásból származó adatok összekapcsolása a funkció engedélyezéséhez, majd a kijelölés mentéséhez kattintson az OK gombra. Ezután AI-funkciókat vehet fel az adatfolyamba.
Kapcsolódó tartalom
Ez a cikk áttekintést nyújtott a Power BI szolgáltatás adatfolyamokhoz készült automatizált gépi Tanulás. Az alábbi cikkek szintén hasznosak lehetnek.
- Oktatóanyag: Gépi Tanulás-modell létrehozása a Power BI-ban
- Oktatóanyag: A Cognitive Services használata a Power BI-ban
Az alábbi cikkek további információt nyújtanak az adatfolyamokról és a Power BI-ról:
- Bevezetés az adatfolyamok és az önkiszolgáló adat-előkészítés használatába
- Adatfolyam létrehozása
- Adatfolyam konfigurálása és felhasználása
- Adatfolyam-tároló konfigurálása az Azure Data Lake Gen 2 használatára
- Az adatfolyamok prémium funkciói
- Adatfolyamokkal kapcsolatos szempontok és korlátozások
- Adatfolyamok – ajánlott eljárások
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: