Gunakan Apache Ambari Hive View dengan Apache Hadoop di HDInsight
Pelajari cara menjalankan kueri Hive dengan menggunakan Apache Ambari Hive View. Hive View memungkinkan Anda untuk menulis, mengoptimalkan, dan menjalankan kueri Hive dari browser web Anda.
Prasyarat
Klaster Hadoop pada HDInsight. Lihat Mulai menggunakan Microsoft Azure HDInsight di Linux.
Menjalankan kueri Apache Hive
Dari portal Microsoft Azure, pilih kluster Anda. Lihat Mencantumkan dan menampilkan kluster untuk mendapatkan petunjuk. Kluster ini dibuka di tampilan portal baru.
Dari Dasbor Kluster, pilih Tampilan Ambari. Saat diminta untuk mengautentikasi, gunakan nama akun dan kata sandi masuk kluster (default
admin) yang Anda berikan saat membuat kluster. Anda juga dapat menavigasi kehttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsdi browser Anda denganCLUSTERNAMEadalah nama kluster Anda.Dari daftar tampilan, pilih Hive View.
Halaman tampilan Hive mirip dengan gambar berikut:
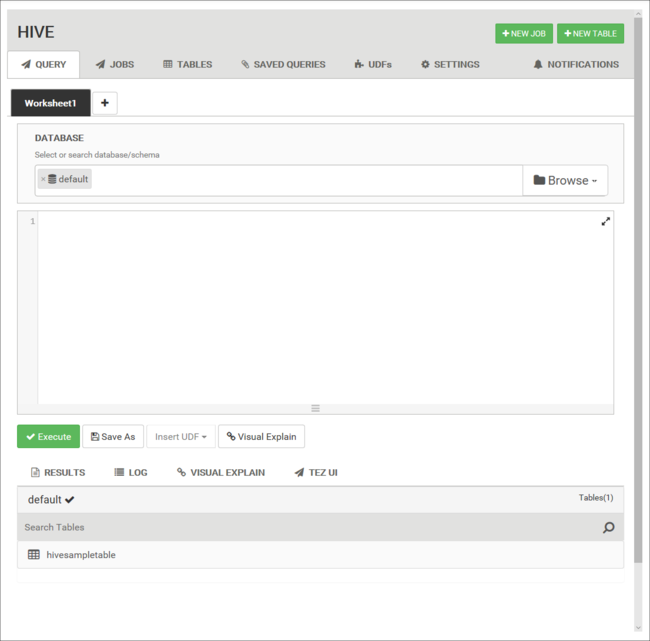
Dari tab Kueri, tempelkan pernyataan HiveQL berikut ke dalam lembar kerja:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Pernyataan ini melakukan tindakan berikut:
Pernyataan Deskripsi DROP TABLE Menghapus tabel dan file data, jika tabel sudah ada. CREATE EXTERNAL TABLE Membuat tabel "eksternal" baru di Hive. Tabel eksternal hanya menyimpan definisi tabel di Hive. Data tetap di lokasi asli. ROW FORMAT Menampilkan cara data diformat. Dalam hal ini, bidang di setiap log dipisahkan oleh spasi. STORED AS TEXTFILE LOCATION Menampilkan lokasi data disimpan, dan data disimpan sebagai teks. SELECT Memilih jumlah semua baris tempat kolom t4 berisi nilai [ERROR]. Penting
Biarkan pilihan Database secara default. Contoh dalam dokumen ini menggunakan database default yang disertakan dengan HDInsight.
Untuk memulai kueri, pilih Jalankan di bawah lembar kerja. Tombol berubah menjadi oranye dan teks berubah menjadi Berhenti.
Setelah kueri selesai, tab Hasil akan menampilkan hasil operasi. Teks berikut adalah hasil kueri:
loglevel count [ERROR] 3Anda dapat menggunakan tab LOG untuk menampilkan informasi pembuatan log yang dibuat oleh pekerjaan tersebut.
Tip
Unduh atau simpan hasil dari kotak dialog drop-down Tindakan di bawah tab Hasil.
Penjelasan visual
Untuk menampilkan visualisasi rencana kueri, pilih tab Penjelasan Visual di bawah lembar kerja.
Tampilan Penjelasan Visual kueri dapat membantu dalam memahami alur kueri yang kompleks.
Tez UI
Untuk menampilkan UI Tez untuk kueri, pilih tab Tez UI di bawah lembar kerja.
Penting
Tez tidak digunakan untuk menyelesaikan semua kueri. Anda dapat menyelesaikan banyak kueri tanpa menggunakan Tez.
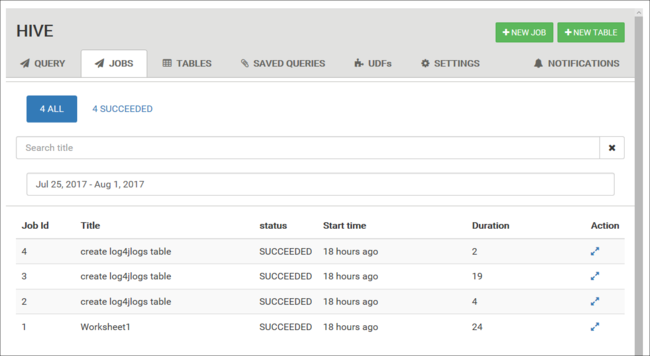
Menampilkan riwayat pekerjaan
Tab Pekerjaan menampilkan riwayat kueri Hive.
Tabel database
Anda dapat menggunakan tab Tabel untuk bekerja dengan tabel dalam database Hive.

Kueri tersimpan
Dari tab Kueri, Anda dapat menyimpan kueri secara opsional. Setelah menyimpan kueri, Anda dapat menggunakannya kembali dari tab Kueri yang Disimpan.
Tip
Kueri tersimpan disimpan di penyimpanan kluster default. Anda dapat menemukan kueri tersimpan di bawah jalur /user/<username>/hive/scripts. Ini disimpan sebagai file teks biasa .hql.
Jika Anda menghapus kluster, tetapi mempertahankan penyimpanan, Anda dapat menggunakan utilitas seperti Azure Storage Explorer atau Data Lake Storage Explorer (dari Portal Microsoft Azure)untuk mengambil kueri.
Fungsi yang ditentukan pengguna
Anda dapat memperluas Hive melalui fungsi yang ditentukan pengguna (UDF). Gunakan UDF untuk menerapkan fungsionalitas atau logika yang tidak mudah dimodelkan di HiveQL.
Deklarasikan dan simpan sekumpulan UDF dengan menggunakan tab UDF di bagian atas Hive View. UDF ini dapat digunakan dengan Editor Kueri.

Tombol Sisipkan udfs muncul di bagian bawah Editor Kueri. Entri ini menampilkan daftar drop-down UDF yang ditentukan dalam Hive View. Memilih UDF menambahkan pernyataan HiveQL ke kueri Anda untuk mengaktifkan UDF.
Misalnya, jika Anda telah menentukan UDF dengan properti berikut:
Nama sumber daya: myudfs
Jalur sumber daya: /myudfs.jar
Nama UDF: myawesomeudf
Nama kelas UDF: com.myudfs.Awesome
Menggunakan tombol Sisipkan udfs menampilkan entri bernama myudfs, dengan daftar drop-down lain untuk setiap UDF yang ditentukan untuk sumber daya tersebut. Dalam hal ini, myawesomeudf. Memilih entri ini menambahkan hal berikut ke awal kueri:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Kemudian, Anda dapat menggunakan UDF dalam kueri Anda. Contohnya,SELECT myawesomeudf(name) FROM people;.
Untuk mengetahui informasi selengkapnya tentang menggunakan UDF dengan Hive di HDInsight, lihat artikel berikut:
- Menggunakan Python dengan Apache Hive dan Apache Pig di HDInsight
- Menggunakan Java UDF dengan Apache Hive di HDInsight
Pengaturan Apache Hive
Anda dapat mengubah berbagai pengaturan Hive, seperti mengubah mesin eksekusi untuk Hive dari Tez (default) ke MapReduce.
Langkah berikutnya
Untuk mengetahui informasi umum tentang Hive di HDInsight: