Mulai cepat: Membuat kluster Apache Kafka di Microsoft Azure HDInsight menggunakan portal Microsoft Azure
Apache Kafka adalah platform streaming sumber terbuka yang didistribusikan. Platform ini sering digunakan sebagai perantara pesan, karena menyediakan fungsionalitas yang mirip dengan antrian pesan terbitkan-berlangganan.
Dalam mulai cepat ini, Anda akan belajar cara membuat kluster Apache Kafka menggunakan portal Microsoft Azure. Anda juga akan belajar cara menggunakan utilitas yang disertakan untuk mengirim dan menerima pesan menggunakan Apache Kafka. Untuk penjelasan mendalam tentang konfigurasi yang tersedia, lihat Menyiapkan kluster di HDInsight. Untuk informasi tambahan mengenai penggunaan portal untuk membuat kluster, lihat Membuat kluster di portal.
Peringatan
Tagihan untuk kluster HDInsight dirata-rata per menit, baik Anda menggunakannya maupun tidak. Pastikan untuk menghapus kluster Anda setelah selesai menggunakannya. Lihat cara menghapus kluster HDInsight.
API Apache Kafka hanya dapat diakses oleh sumber daya di dalam jaringan virtual yang sama. Dalam Mulai cepat ini, Anda mengakses kluster secara langsung menggunakan SSH. Untuk menghubungkan layanan, jaringan, atau komputer virtual lainnya ke Apache Kafka, Anda harus terlebih dahulu membuat jaringan virtual dan kemudian membuat sumber daya dalam jaringan. Untuk informasi selengkapnya, lihat dokumen Menyambungkan ke Apache Kafka menggunakan jaringan virtual. Untuk informasi umum selengkapnya tentang merencanakan jaringan virtual untuk HDInsight, lihat Merencanakan jaringan virtual untuk Azure HDInsight.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prasyarat
Klien SSH. Untuk informasi selengkapnya, lihat Menyambungkan ke HDInsight (Apache Hadoop) menggunakan SSH.
Membuat kluster Apache Kafka
Untuk membuat kluster Apache Kafka di HDInsight, gunakan langkah-langkah berikut:
Masuk ke portal Azure.
Dari menu di bagian atas, pilih + Buat sumber daya.
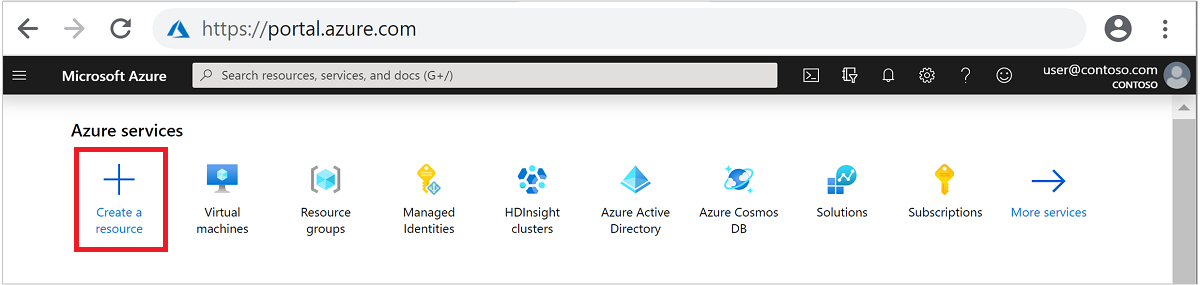
Pilih Analitik>Azure HDInsight untuk masuk ke halaman Buat kluster HDInsight.
Pada tab Dasar, berikan informasi berikut ini:
Properti Deskripsi Langganan Dari daftar dropdown, pilih langganan Azure yang digunakan untuk kluster. Grup sumber daya Buat grup sumber daya atau pilih grup sumber daya yang sudah ada. Grup sumber daya adalah kontainer komponen Azure. Dalam hal ini, grup sumber daya berisi kluster HDInsight dan akun Azure Storage dependen. Nama kluster Masukkan nama yang unik secara global. Nama ini dapat terdiri hingga 59 karakter termasuk huruf, angka, dan tanda hubung. Karakter pertama dan terakhir dari nama tersebut tidak boleh berupa tanda hubung. Wilayah Dari daftar drop-down, pilih wilayah tempat kluster dibuat. Pilih wilayah yang lebih dekat dengan Anda untuk kinerja yang lebih baik. Jenis kluster Pilih Pilih jenis kluster untuk membuka daftar. Dari daftar, pilih Kafka sebagai jenis klaster. Versi Versi default untuk tipe kluster akan ditentukan. Pilih dari daftar drop-down jika Anda ingin menentukan versi yang berbeda. Nama pengguna dan kata sandi untuk masuk kluster Nama login default adalah admin. Panjang kata sandi harus minimal 10 karakter dan harus berisi setidaknya satu digit, satu huruf besar, dan satu huruf kecil, satu karakter non-alfanumerik (kecuali karakter' ` "). Pastikan Anda tidak memberikan kata sandi umum sepertiPass@word1.Nama pengguna Secure Shell (SSH) Nama pengguna default adalah sshuser. Anda dapat memberikan nama lain untuk nama pengguna SSH.Menggunakan sandi login kluster untuk SSH Pilih kotak centang ini untuk menggunakan kata sandi yang sama untuk pengguna SSH seperti yang Anda sediakan untuk pengguna masuk kluster. 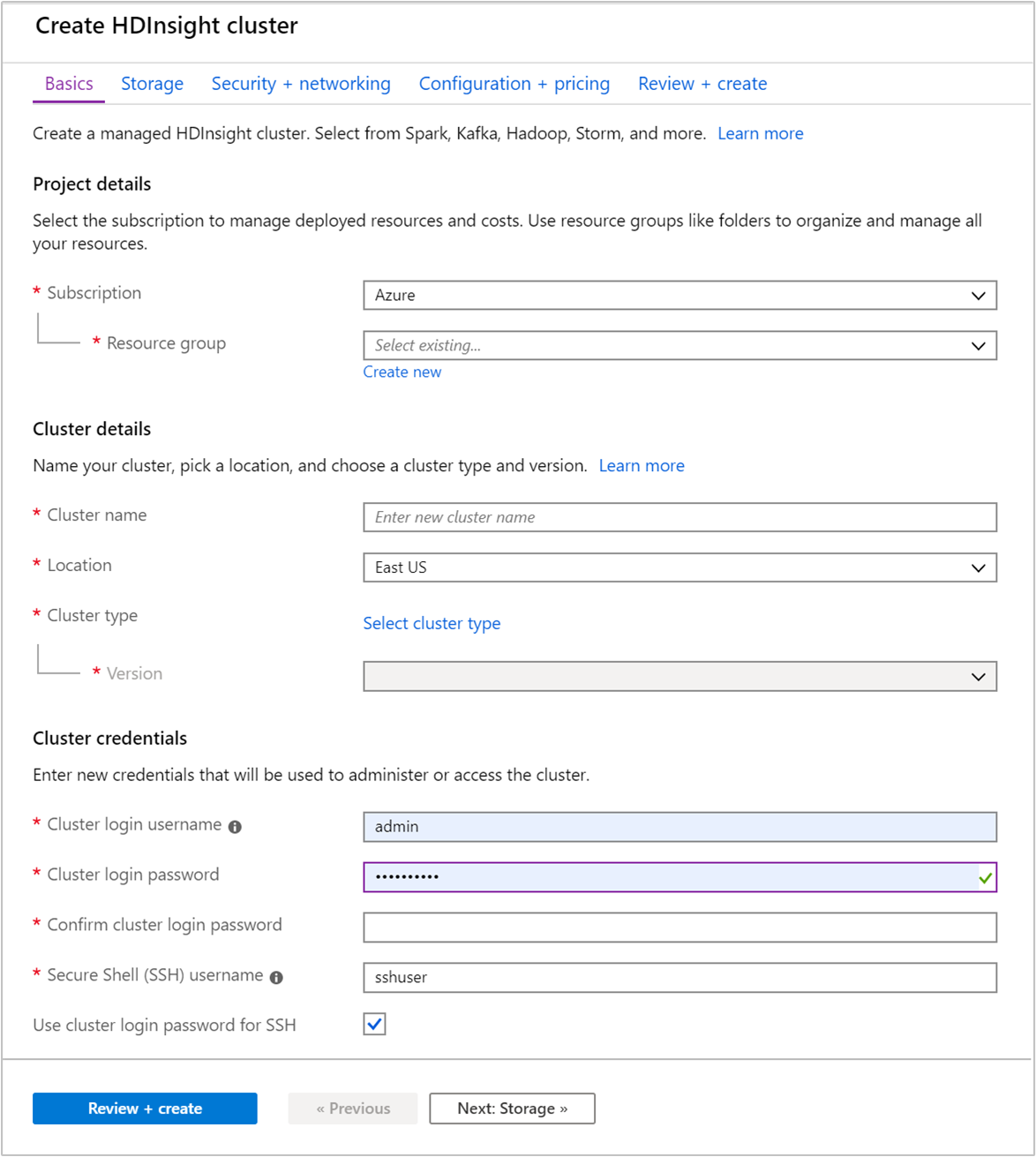
Setiap wilayah (lokasi) Azure menyediakan domain kesalahan. Domain kesalahan adalah pengelompokan logis perangkat keras yang mendasarinya di pusat data Azure. Setiap domain penyimpanan berbagi sumber tenaga dan sakelar jaringan yang sama. Komputer virtual dan disk terkelola yang mengimplementasikan simpul dalam kluster HDInsight didistribusikan melintasi domain kesalahan ini. Arsitektur ini membatasi dampak potensial dari kegagalan perangkat keras fisik.
Untuk ketersediaan data yang tinggi, pilih wilayah (lokasi) yang berisi tiga domain kesalahan. Untuk informasi tentang jumlah domain kesalahan di suatu wilayah, lihat dokumen Ketersediaan komputer virtual Linux.
Pilih tab Berikutnya: Penyimpanan >> untuk melanjutkan ke pengaturan penyimpanan.
Dari tab Penyimpanan, berikan nilai berikut ini:
Properti Deskripsi Jenis penyimpanan utama Gunakan nilai default Azure Storage. Metode pemilihan Gunakan nilai default Pilih dari daftar. Akun penyimpanan primer Gunakan daftar drop-down untuk memilih akun penyimpanan yang sudah ada, atau pilih Buat baru. Jika Anda membuat akun baru, namanya harus terdiri dari 3 sampai 24 karakter, dan hanya bisa menyertakan angka serta huruf kecil Kontainer Gunakan nilai yang diisi otomatis. 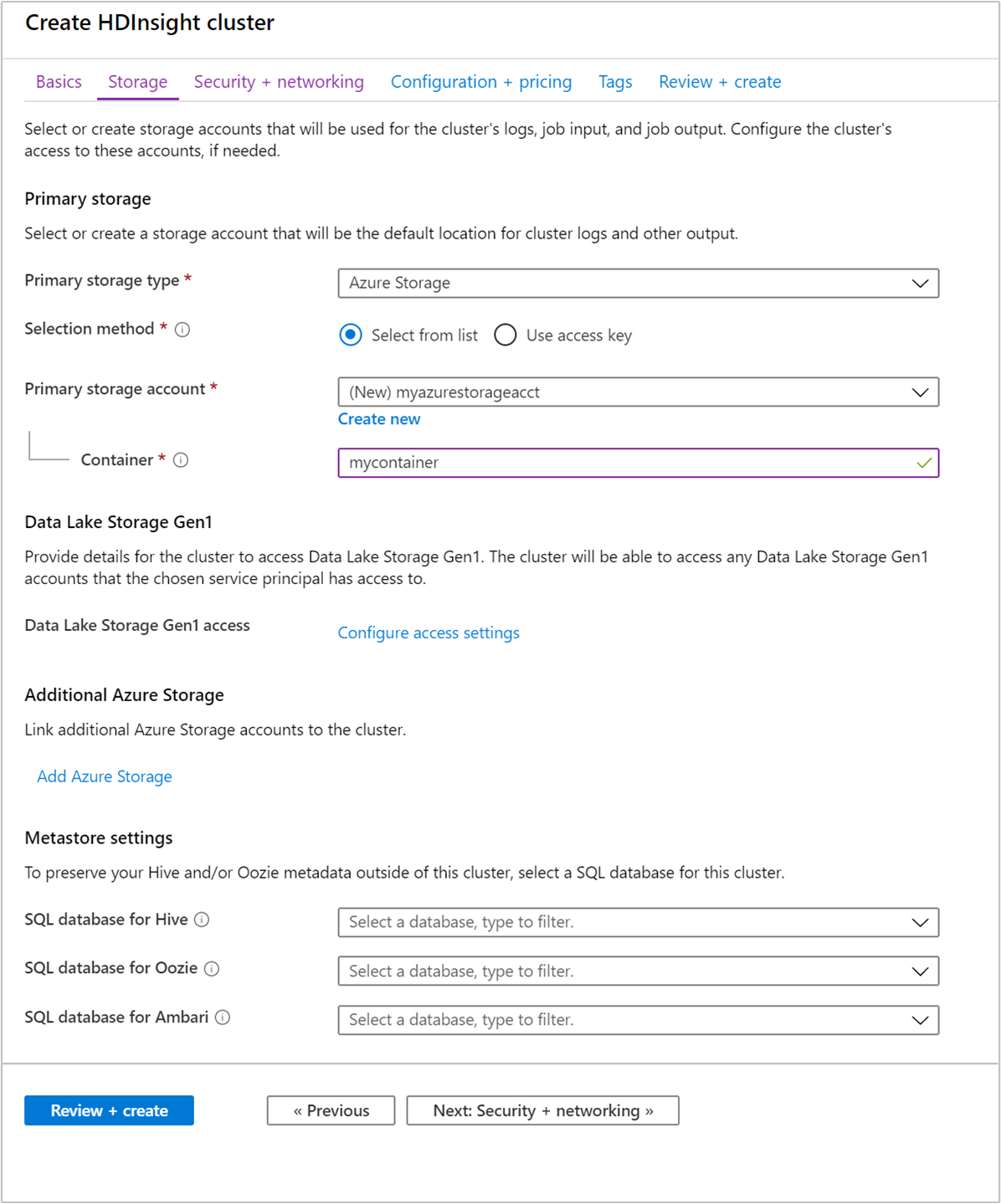
Pilih tab Keamanan + jaringan.
Untuk mulai cepat ini, biarkan pengaturan keamanan tetap default. Untuk mempelajari selengkapnya tentang paket Keamanan Perusahaan, kunjungi Mengonfigurasi kluster HDInsight dengan Paket Keamanan Perusahaan dengan menggunakan Microsoft Entra Domain Services. Untuk mempelajari cara menggunakan kunci Anda sendiri untuk Enkripsi Disk Apache Kafka, kunjungi Enkripsi disk kunci yang dikelola pelanggan
Jika Anda ingin menyambungkan kluster Anda ke jaringan virtual, pilih jaringan virtual dari dropdown Jaringan virtual.
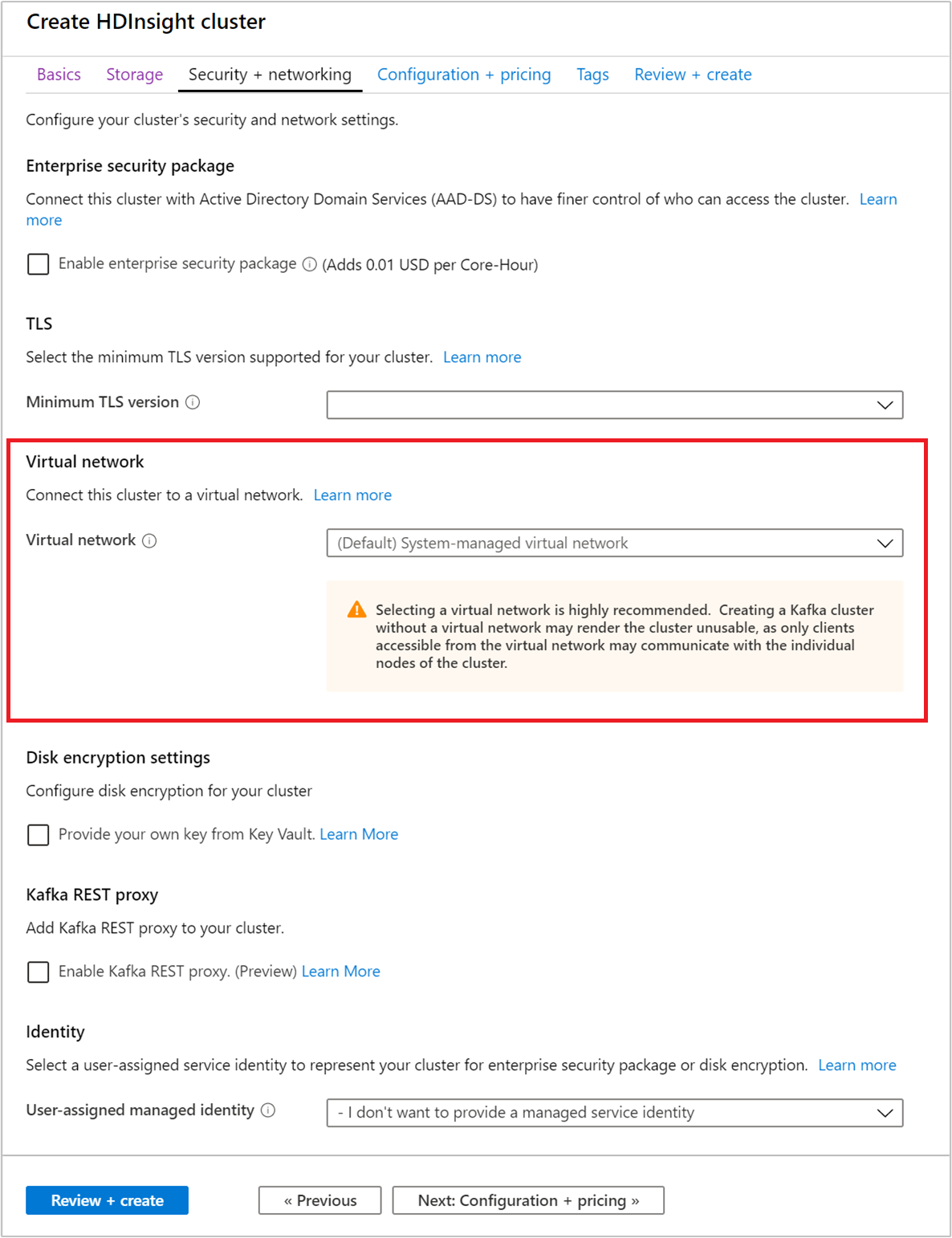
Pilih tab Konfigurasi + harga.
Untuk menjamin ketersediaan Apache Kafka pada HDInsight, jumlah entri node untuk node Worker harus diatur ke 3 atau lebih besar. Nilai defaultnya adalah 4.
Entri Node disk standar per worker mengonfigurasi skalabilitas Apache Kafka pada HDInsight. Apache Kafka di HDInsight menggunakan disk lokal komputer virtual pada kluster untuk menyimpan data. Apache Kafka memiliki banyak I/O, sehingga Disk Terkelola Azure digunakan untuk menyediakan throughput tinggi dan lebih banyak penyimpanan per node. Jenis disk yang dikelola dapat berupa Standar (HDD) atau Premium (SSD). Jenis disk tergantung pada ukuran komputer virtual yang digunakan oleh node worker (broker Apache Kafka). Disk premium digunakan secara otomatis dengan komputer virtual seri DS dan GS. Semua jenis VM lainnya menggunakan disk standar.
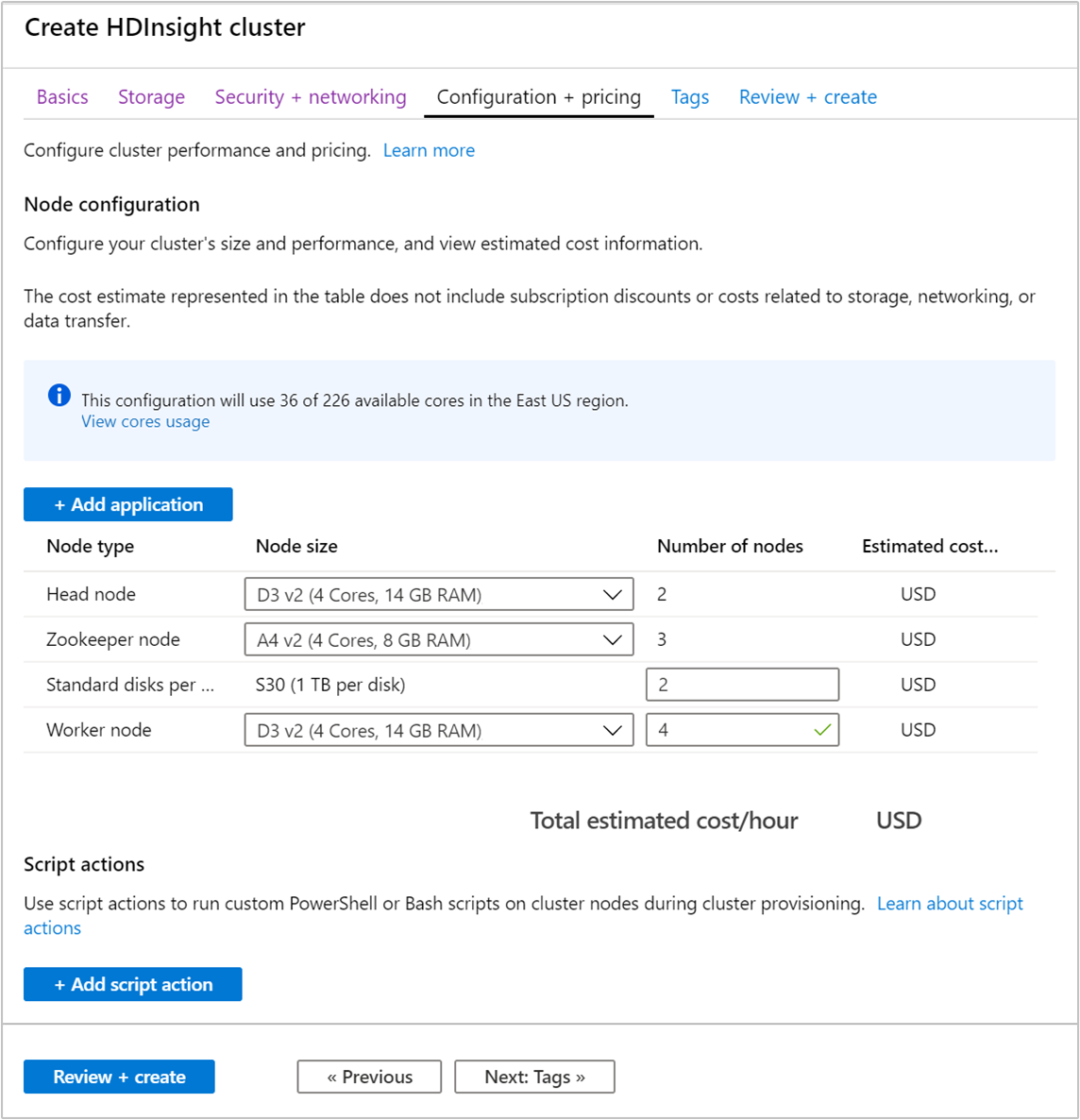
Pilih tab Tinjau + buat.
Tinjau ulang konfigurasi untuk kluster. Ubah setelan yang keliru. Terakhir, pilih Buat untuk membuat kluster.

Pembuatan kluster dapat memakan waktu hingga 20 menit.
Menyambungkan ke kluster
Gunakan perintah ssh untuk menyambungkan ke kluster Anda. Edit perintah di bawah ini dengan mengganti CLUSTERNAME dengan nama klaster Anda, lalu masukkan perintah:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netJika diminta, masukkan kata sandi untuk pengguna SSH.
Setelah tersambung, Anda akan melihat informasi yang mirip dengan teks berikut:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Dapatkan informasi host Apache Zookeeper dan Broker
Ketika bekerja dengan Kafka, Anda harus tahu host Apache Zookeeper dan Broker. Host ini digunakan dengan API Apache Kafka dan sejumlah utilitas yang disertakan dengan Kafka.
Di bagian ini, Anda mendapatkan informasi host dari REST API Apache Ambari pada kluster.
Instal jq, prosesor JSON baris perintah. Utilitas ini digunakan untuk memilah dokumen JSON, dan berguna dalam memilah informasi host. Dari koneksi SSH yang terbuka, masukkan perintah berikut untuk memasang
jq:sudo apt -y install jqSiapkan variabel sandi. Ganti
PASSWORDdengan kata sandi masuk kluster, lalu masukkan perintah:export PASSWORD='PASSWORD'Ekstrak nama kluster dengan penulisan yang benar. Penulisan sebenarnya dari nama kluster mungkin berbeda dari yang Anda duga, tergantung pada cara kluster dibuat. Perintah ini akan mendapatkan penulisan yang aktual, dan kemudian menyimpannya dalam variabel. Masukkan perintah berikut:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Catatan
Jika Anda melakukan proses ini dari luar kluster, ada prosedur yang berbeda untuk menyimpan nama kluster. Pastikan nama kluster dalam huruf kecil dari portal Microsoft Azure. Kemudian, ganti nama kluster menjadi
<clustername>dalam perintah berikut dan jalankan:export clusterName='<clustername>'.Untuk mengatur variabel lingkungan dengan informasi host Zookeeper, gunakan perintah di bawah ini. Perintah mengambil semua host Zookeeper, lalu hanya mengembalikan dua entri pertama. Hal ini dilakukan karena Anda ingin memiliki beberapa redundansi kalau-kalau satu host tidak dapat dijangkau.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Catatan
Perintah ini memerlukan akses Ambari. Jika kluster Anda berada di belakang NSG, jalankan perintah ini dari komputer yang dapat mengakses Ambari.
Untuk memverifikasi bahwa variabel lingkungan di set dengan benar, gunakan perintah berikut:
echo $KAFKAZKHOSTSPerintah ini mengembalikan informasi yang mirip dengan teks berikut:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Untuk mengatur variabel lingkungan dengan informasi host broker Apache Kafka, gunakan perintah berikut:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Catatan
Perintah ini memerlukan akses Ambari. Jika kluster Anda berada di belakang NSG, jalankan perintah ini dari komputer yang dapat mengakses Ambari.
Untuk memverifikasi bahwa variabel lingkungan di set dengan benar, gunakan perintah berikut:
echo $KAFKABROKERSPerintah ini mengembalikan informasi yang mirip dengan teks berikut:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Kelola topik Apache Kafka
Kafka menyimpan aliran data dalam topik. Anda dapat menggunakan kafka-topics.sh utilitas untuk mengelola topik.
Untuk membuat topik, gunakan perintah berikut ini di sambungan SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --zookeeper $KAFKAZKHOSTSPerintah ini terhubung ke Zookeeper menggunakan informasi host yang disimpan di
$KAFKAZKHOSTS. Kemudian membuat topik Apache Kafka bernama test.Data yang disimpan dalam topik ini dipartisi di delapan partisi.
Setiap partisi direplikasi di tiga simpul pekerja dalam kluster.
Jika Anda membuat kluster di wilayah Azure yang menyediakan tiga domain kesalahan, gunakan faktor replikasi 3. Jika tidak, gunakan faktor replikasi 4.
Di wilayah dengan tiga domain kesalahan, faktor replikasi 3 memungkinkan replika tersebar di seluruh domain kesalahan. Di wilayah dengan dua domain kesalahan, faktor replikasi empat menyebarkan replika secara merata di seluruh domain.
Untuk informasi tentang jumlah domain kesalahan di suatu wilayah, lihat dokumen Ketersediaan komputer virtual Linux.
Apache Kafka tidak mengetahui domain kesalahan Azure. Saat membuat replika partisi untuk topik, Kafka mungkin tidak mendistribusikan replika dengan benar untuk ketersediaan tinggi.
Untuk memastikan ketersediaan tinggi, gunakan alat penyeimbangan kembali partisi Apache Kafka. Alat ini harus dijalankan dari koneksi SSH ke node kepala kluster Apache Kafka Anda.
Untuk ketersediaan tertinggi data Apache Kafka Anda, Anda harus menyeimbangkan kembali replika partisi untuk topik Anda ketika:
Anda membuat topik atau partisi baru
Anda menaikkan skala kluster
Untuk membuat daftar topik, gunakan perintah berikut:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $KAFKAZKHOSTSPerintah ini membuat daftar topik yang tersedia di kluster Apache Kafka.
Untuk menghapus topik, gunakan perintah berikut:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --zookeeper $KAFKAZKHOSTSPerintah ini menghapus topik bernama
topicname.Peringatan
Jika Anda menghapus
testtopik yang dibuat sebelumnya, maka Anda harus membuatnya kembali. Topik ini digunakan pada langkah-langkah berikutnya dalam dokumen ini.
Untuk informasi selengkapnya tentang perintah yang tersedia dengan kafka-topics.sh utilitas, gunakan perintah berikut:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Menghasilkan dan menggunakan rekaman
Kafka menyimpan rekaman dalam topik. Rekaman dibuat oleh produsen, dan digunakan oleh konsumen. Produsen dan konsumen berkomunikasi dengan layanan broker Kafka. Setiap node pekerja di kluster HDInsight Anda adalah host broker Apache Kafka.
Untuk menyimpan rekaman ke dalam topik pengujian yang Anda buat sebelumnya, dan kemudian membacanya menggunakan konsumen, gunakan langkah-langkah berikut:
Untuk menulis rekaman ke topik ini, gunakan
kafka-console-producer.shutilitas dari sambungan SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testSetelah perintah ini, Anda tiba di garis kosong.
Ketik pesan teks pada baris kosong dan tekan masukkan. Masukkan beberapa pesan dengan cara ini, lalu gunakan Ctrl + C untuk kembali ke prompt normal. Setiap baris dikirim sebagai rekaman terpisah ke topik Apache Kafka.
Untuk membaca rekaman dari topik, gunakan
kafka-console-consumer.shutilitas dari sambungan SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningPerintah ini mengambil rekaman dari topik dan menampilkannya. Menggunakan
--from-beginningakan memberitahu konsumen untuk memulai dari awal aliran, sehingga semua rekaman terambil.Jika Anda menggunakan Kafka versi lama, ganti
--bootstrap-server $KAFKABROKERSdengan--zookeeper $KAFKAZKHOSTS.Gunakan Ctrl + C untuk menghentikan konsumen.
Anda juga dapat secara terprogram membuat produsen dan konsumen. Untuk contoh penggunaan API ini, lihat dokumen API Produsen dan Konsumen Apache Kafka dengan HDInsight.
Membersihkan sumber daya
Untuk membersihkan sumber daya yang dibuat oleh mulai cepat ini, Anda bisa menghapus grup sumber daya. Menghapus grup sumber daya juga menghapus kluster HDInsight terkait, dan sumber daya lain yang terkait dengan grup sumber daya.
Menghapus grup sumber daya menggunakan portal Microsoft Azure:
- Di portal Microsoft Azure, luaskan menu di sebelah kiri untuk membuka menu layanan, lalu pilihGrup Sumber Daya untuk menampilkan daftar grup sumber daya Anda.
- Cari grup sumber daya yang ingin dihapus, lalu klik kanan tombol Lainnya (...) di sisi kanan daftar.
- Pilih Hapus grup sumber daya, lalu konfirmasi.
Peringatan
Menghapus kluster Apache Kafka di HDInsight menghapus data apa pun yang disimpan di Kafka.