Apa itu Apache Kafka di Azure HDInsight
Apache Kafka adalah platform streaming terdistribusi dengan sumber terbuka yang dapat digunakan untuk membangun alur dan aplikasi data streaming real time. Kafka juga menyediakan fungsi broker pesan yang mirip dengan antrean pesan, di mana Anda dapat menerbitkan dan berlangganan aliran data yang disebut.
Berikut ini adalah karakteristik spesifik Kafka di HDInsight:
Ia adalah layanan terkelola yang menyediakan proses konfigurasi yang disederhanakan. Hasilnya adalah konfigurasi yang telah diuji dan didukung oleh Microsoft.
Microsoft memberikan Perjanjian Tingkat Layanan (Service Level Agreement/SLA) setinggi 99,9% pada waktu aktif Kafka. Untuk informasi selengkapnya, lihat dokumen Informasi SLA untuk HDInsight.
Ia menggunakan Azure Managed Disks sebagai penyimpanan cadangan untuk Kafka. Disk terkelola dapat menyediakan penyimpanan hingga 16 TB per broker Kafka. Untuk informasi pengonfigurasian disk terkelola dengan Kafka di HDInsight, lihat Meningkatkan skalabilitas Apache Kafka di HDInsight.
Untuk informasi selengkapnya tentang disk terkelola, lihat Azure Managed Disks.
Kafka dirancang dengan tampilan satu dimensi rak. Azure memisahkan rak menjadi dua dimensi - Update Domain (UD) dan Fault Domain (FD). Microsoft menyediakan alat yang dapat menyeimbangkan kembali partisi dan replika Kafka di seluruh UD dan FD.
Untuk informasi selengkapnya, lihat Ketersediaan tinggi dengan Apache Kafka di HDInsight.
HDInsight memungkinkan Anda untuk mengubah jumlah node pekerja (yang menghosting broker Kafka) setelah pembuatan kluster. Penskalaan ke atas dapat dilakukan dari portal Microsoft Azure, Azure PowerShell, dan antarmuka manajemen Azure lainnya. Untuk Kafka, Anda harus menyeimbangkan kembali replika partisi setelah operasi penskalaan. Penyeimbangan kembali partisi memungkinkan Kafka untuk memanfaatkan sejumlah node pekerja yang baru.
HDInsight Kafka tidak mendukung penskalaan ke bawah atau pengurangan jumlah broker dalam satu kluster. Jika ada upaya untuk mengurangi jumlah node, kesalahan
InvalidKafkaScaleDownRequestErrorCodeakan dikembalikan.Untuk informasi selengkapnya, lihat Ketersediaan tinggi dengan Apache Kafka di HDInsight.
Log Azure Monitor dapat digunakan untuk memantau Kafka di HDInsight. Log Azure Monitor menampilkan informasi di tingkat komputer virtual, seperti metrik disk dan NIC, dan metrik JMX dari Kafka.
Untuk informasi selengkapnya, lihat Menganalisis log untuk Apache Kafka di HDInsight.
Apache Kafka pada arsitektur HDInsight
Diagram berikut menunjukkan konfigurasi khas Kafka yang menggunakan kelompok konsumen, pemartisian, dan replikasi untuk menawarkan pembacaan paralel kejadian dengan toleransi kegagalan:
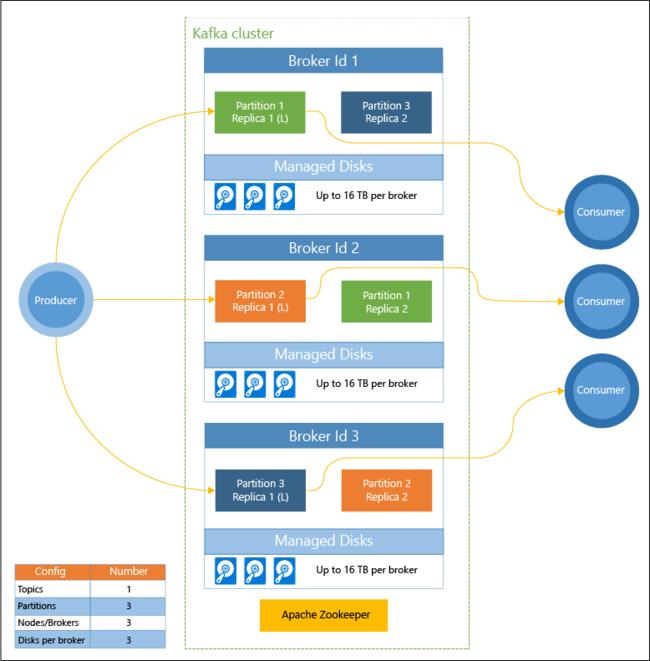
Apache ZooKeeper mengelola status kluster Kafka. Zookeeper dibangun untuk transaksi bersamaan, tangguh, dan latensi rendah.
Kafka menyimpan rekaman (data) dalam topik. Rekaman dibuat oleh produsen, dan digunakan oleh konsumen. Produsen mengirim rekaman ke broker Kafka. Setiap node pekerja di kluster HDInsight Anda adalah broker Kafka.
Topik mempartisi rekaman pada semua broker. Ketika menggunakan rekaman, Anda dapat menggunakan hingga satu konsumen per partisi untuk melakukan pemrosesan paralel data.
Replikasi digunakan untuk menduplikasi partisi di seluruh node, melindungi dari gangguan node (broker). Partisi yang ditandai dengan (L) dalam diagram adalah pemandu untuk partisi yang ditentukan. Lalu lintas produsen dirutekan ke pemimpin dari setiap simpul menggunakan status yang dikelola oleh ZooKeeper.
Mengapa menggunakan Apache Kafka di HDInsight?
Berikut ini adalah tugas dan pola umum yang dapat dilakukan menggunakan Kafka di HDInsight:
| Menggunakan | Deskripsi |
|---|---|
| Replikasi data Apache Kafka | Kafka menyediakan utilitas MirrorMaker, yang mereplikasi data antar kluster Kafka. Untuk informasi tentang penggunaan MirrorMaker, lihat Mereplikasi topik Apache Kafka dengan Apache Kafka di HDInsight. |
| Pola olahpesan terbitkan-langganan | Kafka menyediakan Producer API untuk menerbitkan rekaman ke topik Kafka. Consumer API digunakan ketika berlangganan ke sebuah topik. Untuk informasi selengkapnya, lihat Mulai dengan Apache Kafka di HDInsight. |
| Pemrosesan aliran | Kafka sering digunakan dengan Spark untuk pemrosesan aliran real time. Kafka 2.1.1 dan 2.4.1 (HDInsight versi 4.0 dan 5.0) mendukung API streaming yang memungkinkan Anda membangun solusi streaming tanpa memerlukan Spark. Untuk informasi selengkapnya, lihat Mulai dengan Apache Kafka di HDInsight. |
| Skala horizontal | Partisi Kafka mengalir di seluruh node dalam kluster HDInsight. Proses konsumen dapat dikaitkan dengan partisi individu untuk memberikan keseimbangan beban saat menggunakan rekaman. Untuk informasi selengkapnya, lihat Mulai dengan Apache Kafka di HDInsight. |
| Pengiriman sesuai urutan | Dalam setiap partisi, rekaman disimpan dalam aliran sesuai dengan urutan diterimanya. Dengan mengaitkan satu proses konsumen per partisi, Anda dapat menjamin bahwa rekaman diproses sesuai urutan. Untuk informasi selengkapnya, lihat Mulai dengan Apache Kafka di HDInsight. |
| Olahpesan | Karena ia mendukung pola pesan terbitkan-langganan, Kafka sering digunakan sebagai broker pesan. |
| Pelacakan aktivitas | Karena Kafka menyediakan pengelogan rekaman secara urut, ia dapat digunakan untuk melacak dan membuat kembali aktivitas. Misalnya, tindakan pengguna di situs web atau dalam suatu aplikasi. |
| Agregasi | Dengan menggunakan pemrosesan streaming, Anda dapat mengagregasi informasi dari berbagai aliran untuk menggabungkan dan memusatkan informasi ke dalam data operasional. |
| Transformasi | Dengan menggunakan pemrosesan streaming, Anda dapat menggabungkan dan memperkaya data dari banyak topik input ke dalam satu atau lebih topik output. |
Langkah berikutnya
Gunakan tautan berikut untuk mempelajari cara menggunakan Apache Kafka di HDInsight: