Pasang Jupyter Notebook di komputer Anda dan sambungkan ke Apache Spark di Microsoft Azure HDInsight
Dalam artikel ini, Anda belajar cara memasang Jupyter Notebook dengan kernel PySpark (untuk Python) dan Apache Spark (untuk Scala) kustom dengan Spark magic. Anda kemudian menyambungkan buku catatan ke kluster Microsoft Azure HDInsight.
Ada empat langkah utama yang terlibat dalam memasang Jupyter dan menghubungkan ke Apache Spark di Microsoft Azure HDInsight.
- Mengonfigurasi kluster Spark.
- Pasang Jupyter Notebook.
- Pasang kernel PySpark dan Spark dengan Spark magic.
- Konfigurasikan Spark magic untuk mengakses klaster Spark di Microsoft Azure HDInsight.
Untuk informasi selengkapnya tentang kernel kustom dan Spark magic, lihat Kernel yang tersedia untuk Jupyter Notebooks dengan kluster Linux Apache Spark di Microsoft Azure HDInsight.
Prasyarat
Klaster Apache Spark pada HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight. Notebook lokal tersambung ke kluster Microsoft Azure HDInsight.
Terbiasa menggunakan Jupyter Notebook dengan Spark di Microsoft Azure HDInsight.
Pasang Jupyter Notebook di komputer Anda
Pasang Python sebelum Anda memasang Jupyter Notebooks. Distribusi Anaconda akan memasang keduanya, Python, dan Jupyter Notebook.
Unduh alat penginstal Anaconda untuk platform Anda dan jalankan penyetelan. Saat menjalankan panduan penyetelan, pastikan Anda memilih opsi untuk menambahkan Anaconda ke variabel PATH Anda. Lihat juga, Memasang Jupyter menggunakan Anaconda.
Pasang Spark magic
Masukkan perintah
pip install sparkmagic==0.13.1untuk menginstal Spark magic untuk kluster Microsoft Azure HDInsight versi 3.6 dan 4.0. Lihat juga, dokumentasi sparkmagic.Pastikan
ipywidgetsdipasang dengan benar dengan menjalankan perintah berikut:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Pasang kernel PySpark dan Spark
Identifikasi di mana
sparkmagicdiinstal dengan memasukkan perintah berikut:pip show sparkmagicKemudian ubah direktori kerja Anda ke lokasi yang diidentifikasi dengan perintah di atas.
Dari direktori kerja baru Anda, masukkan satu atau beberapa perintah di bawah ini untuk memasang kernel yang diinginkan:
Kernel Perintah Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelOpsional. Masukkan perintah di bawah ini untuk memfungsikan ekstensi server:
jupyter serverextension enable --py sparkmagic
Konfigurasikan Spark magic untuk terhubung ke kluster Microsoft Azure HDInsight Spark
Di bagian ini, Anda mengonfigurasi Spark magic yang Anda pasang sebelumnya untuk terhubung ke kluster Apache Spark.
Mulai shell Python dengan perintah berikut:
pythonInformasi konfigurasi Jupyter biasanya disimpan di direktori rumah pengguna. Masukkan perintah berikut untuk mengidentifikasi direktori utama, dan buat folder yang disebut .sparkmagic. Jalur lengkap akan di-output.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Di dalam folder
.sparkmagic, buat file bernama config.json dan tambahkan cuplikan JSON berikut di dalamnya.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Lakukan edit berikut ke file:
Nilai templat Nilai baru {USERNAME} Login kluster, defaultnya adalah admin.{CLUSTERDNSNAME} Nama kluster {BASE64ENCODEDPASSWORD} Kata sandi yang dikodekan base64 untuk kata sandi Anda yang sebenarnya. Anda dapat menghasilkan kata sandi base64 di https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Simpan jika menggunakan sparkmagic 0.12.7(kluster v3.5 dan v3.6). Jika menggunakansparkmagic 0.2.3(kluster v3.4), ganti dengan"should_heartbeat": true.Anda dapat melihat contoh file lengkap pada contoh config.jsdi.
Tip
Heartbeat dikirim untuk memastikan bahwa sesi tidak bocor. Ketika komputer tertidur atau dimatikan, detak jantung tidak dikirim, mengakibatkan sesi dibersihkan. Untuk kluster v3.4, jika Anda ingin menonaktifkan perilaku ini, Anda dapat mengatur konfigurasi Livy
livy.server.interactive.heartbeat.timeoutke0dari UI Ambari. Untuk kluster v3.5, jika Anda tidak mengatur konfigurasi 3.5 di atas, sesi tidak akan dihapus.Mulai Jupyter. Pada prompt perintah, jalankan perintah berikut ini.
jupyter notebookVerifikasi bahwa Anda dapat menggunakan Spark magic yang tersedia dengan kernel. Selesaikan langkah-langkah berikut.
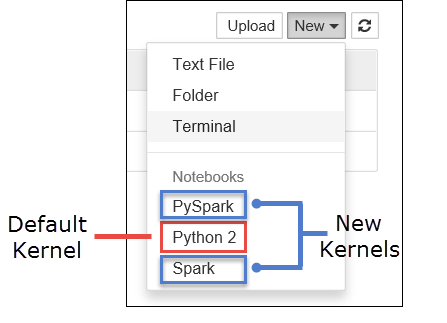
a. Buat notebook baru. Dari sudut kanan, pilih Baru. Anda akan melihat kernel default Python 2 atau Python 3 dan kernel yang Anda pasang. Nilai aktual dapat bervariasi tergantung pada pilihan instalasi Anda. Pilih PySpark.
Penting
Setelah memilih Baru, tinjau shell Anda untuk kesalahan apa pun. Jika Anda melihat
TypeError: __init__() got an unexpected keyword argument 'io_loop'kesalahan, Anda mungkin mengalami masalah yang diketahui dengan versi Tornado tertentu. Jika demikian, hentikan kernel dan kemudian turunkan pasang Tornado Anda dengan perintah berikut:pip install tornado==4.5.3.b. Cuplikan kode berikut.
%%sql SELECT * FROM hivesampletable LIMIT 5Jika Anda berhasil mengambil output, koneksi Anda ke kluster Microsoft Azure HDInsight diuji.
Jika Anda ingin memperbarui konfigurasi buku catatan untuk menyambungkan ke kluster lain, perbarui config.js dengan kumpulan nilai baru, seperti yang diperlihatkan pada Langkah 3, di atas.
Mengapa saya harus memasang Jupyter di komputer saya?
Alasan untuk menginstal Jupyter di komputer Anda dan kemudian menghubungkannya ke kluster Apache Spark di Microsoft Azure HDInsight:
- Memberi Anda opsi untuk membuat buku catatan Anda secara lokal, menguji aplikasi Anda terhadap kluster yang sedang berjalan, lalu unggah buku catatan ke kluster. Untuk mengunggah buku catatan ke klaster, Anda bisa mengunggahnya menggunakan Jupyter Notebook yang sedang berjalan atau kluster, atau menyimpannya ke
/HdiNotebooksfolder di akun penyimpanan yang terkait dengan kluster. Untuk informasi selengkapnya tentang bagaimana buku catatan disimpan di kluster, lihat Di mana Notebooks Jupyter disimpan? - Dengan buku catatan tersedia secara lokal, Anda bisa menyambungkan ke kluster Spark yang berbeda berdasarkan persyaratan aplikasi Anda.
- Anda dapat menggunakan GitHub untuk menerapkan sistem kontrol sumber dan memiliki kontrol versi untuk buku catatan. Anda juga bisa memiliki lingkungan kolaboratif di mana beberapa pengguna bisa bekerja dengan buku catatan yang sama.
- Anda dapat bekerja dengan buku catatan secara lokal tanpa memiliki kluster. Anda hanya perlu klaster untuk menguji buku catatan Anda, bukan mengelola buku catatan atau lingkungan pengembangan Anda secara manual.
- Mungkin lebih mudah untuk mengkonfigurasi lingkungan pengembangan lokal Anda sendiri daripada mengonfigurasi instalasi Jupyter pada kluster. Anda dapat memanfaatkan semua perangkat lunak yang telah Anda pasang secara lokal tanpa mengonfigurasi satu atau beberapa kluster jarak jauh.
Peringatan
Dengan Jupyter terinstal di komputer lokal Anda, beberapa pengguna dapat menjalankan buku catatan yang sama pada kluster Spark yang sama secara bersamaan. Dalam situasi seperti itu, beberapa sesi Livy dibuat. Jika Anda mengalami masalah dan ingin men-debug itu, itu akan menjadi tugas yang kompleks untuk melacak sesi Livy mana yang termasuk dalam pengguna mana.